The following tutorials provide an example of an organization moving from experimentation to deployment in production using Jupyter Notebooks as the basis for code research and use. For this example, we can assume to main actors performing the following tasks.
Number
Notebook Sample
Task
Actor
Description
01
01_explore_and_train.ipynb
Data Exploration and Model Selection
Data Scientist
The data scientist evaluates the data and determines the best model to use to solve the proposed problems.
02
02_automated_training_process.ipynd
Training Process Automation Setup
Data Scientist
The data scientist has selected the model and tested how to train it. In this phase, the data scientist tests automating the training process based on a data store.
03
03_deploy_model.ipynb
Deploy the Model in Wallaroo
MLOps Engineer
The MLOps takes the trained model and deploys a Wallaroo pipeline with it to perform inferences on by feeding it data from a data store.
04
04_regular_batch_inferences.ipynb
Regular Batch Inference
MLOps Engineer
With the pipeline deployed, regular inferences can be made and the results reported to a data store.
Each Jupyter Notebook is arranged to demonstrate each step of the process.
Resources
The following resources are provided as part of this tutorial:
data
data/seattle_housing_col_description.txt: Describes the columns used as part data analysis.
data/seattle_housing.csv: Sample data of the Seattle, Washington housing market between 2014 and 2015.
code
simdb.py: A simulated database to demonstrate sending and receiving queries.
preprocess.py and postprocess.py: Processes the data into a format the model accepts, and formats the model outputs for database use.
models
housing_model_xgb.onnx: Model created in Stage 2: Training Process Automation Setup.
./models/preprocess_byop.zip.: Formats the incoming data for the model.
./models/postprocess_byop.zip: Formats the outgoing data for the model.
When starting a project, the data scientist focuses on exploration and experimentation, rather than turning the process into an immediate production system. This notebook presents a simplified view of this stage.
Resources
The following resources are used as part of this tutorial:
data
data/seattle_housing_col_description.txt: Describes the columns used as part data analysis.
data/seattle_housing.csv: Sample data of the Seattle, Washington housing market between 2014 and 2015.
code
postprocess.py: Formats the data after inference by the model is complete.
preprocess.py: Formats the incoming data for the model.
simdb.py: A simulated database to demonstrate sending and receiving queries.
wallaroo_client.py: Additional methods used with the Wallaroo instance to create workspaces, etc.
Model Testing: Evaluate different models and determine which is best suited for the problem.
Import Libraries
First we’ll import the libraries we’ll be using to evaluate the data and test different models.
importnumpyasnpimportpandasaspdimportsklearnimportsklearn.ensembleimportxgboostasxgbimportseabornimportmatplotlibimportmatplotlib.pyplotaspltimportsimdb# module for the purpose of this demo to simulate pulling data from a databasematplotlib.rcParams["figure.figsize"] = (12,6)
# ignoring warnings for demonstrationimportwarningswarnings.filterwarnings('ignore')
Retrieve Training Data
For training, we will use the data on all houses sold in this market with the last two years. As a reminder, this data pulled from a simulated database as an example of how to pull from an existing data store.
Only a few columns will be shown for display purposes.
conn=simdb.simulate_db_connection()
tablename=simdb.tablenamequery=f"select * from {tablename} where date > DATE(DATE(), '-24 month') AND sale_price is not NULL"print(query)
# read in the datahousing_data=pd.read_sql_query(query, conn)
conn.close()
housing_data.loc[:, ["id", "date", "list_price", "bedrooms", "bathrooms", "sqft_living", "sqft_lot"]]
select * from house_listings where date > DATE(DATE(), '-24 month') AND sale_price is not NULL
id
date
list_price
bedrooms
bathrooms
sqft_living
sqft_lot
0
7129300520
2023-07-31
221900.0
3
1.00
1180
5650
1
6414100192
2023-09-26
538000.0
3
2.25
2570
7242
2
5631500400
2023-12-13
180000.0
2
1.00
770
10000
3
2487200875
2023-09-26
604000.0
4
3.00
1960
5000
4
1954400510
2023-12-06
510000.0
3
2.00
1680
8080
...
...
...
...
...
...
...
...
20518
263000018
2023-03-08
360000.0
3
2.50
1530
1131
20519
6600060120
2023-12-11
400000.0
4
2.50
2310
5813
20520
1523300141
2023-04-10
402101.0
2
0.75
1020
1350
20521
291310100
2023-11-03
400000.0
3
2.50
1600
2388
20522
1523300157
2023-08-02
325000.0
2
0.75
1020
1076
20523 rows × 7 columns
Data transformations
To improve relative error performance, we will predict on log10 of the sale price.
Predict on log10 price to try to improve relative error performance
Now we pick variables and split training data into training and holdout (test).
vars= ['bedrooms', 'bathrooms', 'sqft_living', 'sqft_lot', 'floors', 'waterfront', 'view',
'condition', 'grade', 'sqft_above', 'sqft_basement', 'lat', 'long', 'sqft_living15', 'sqft_lot15', 'house_age', 'renovated', 'yrs_since_reno']
outcome='logprice'runif=np.random.default_rng(2206222).uniform(0, 1, housing_data.shape[0])
gp=np.where(runif<0.2, 'test', 'training')
hd_train=housing_data.loc[gp=='training', :].reset_index(drop=True, inplace=False)
hd_test=housing_data.loc[gp=='test', :].reset_index(drop=True, inplace=False)
# split the training into training and val for xgboostrunif=np.random.default_rng(123).uniform(0, 1, hd_train.shape[0])
xgb_gp=np.where(runif<0.2, 'val', 'train')
# for xgboost, further split into train and valtrain_features=np.array(hd_train.loc[xgb_gp=='train', vars])
train_labels=np.array(hd_train.loc[xgb_gp=='train', outcome])
val_features=np.array(hd_train.loc[xgb_gp=='val', vars])
val_labels=np.array(hd_train.loc[xgb_gp=='val', outcome])
Postprocessing
Since we are fitting a model to predict log10 price, we need to convert predictions back into price units. We also want to round to the nearest dollar.
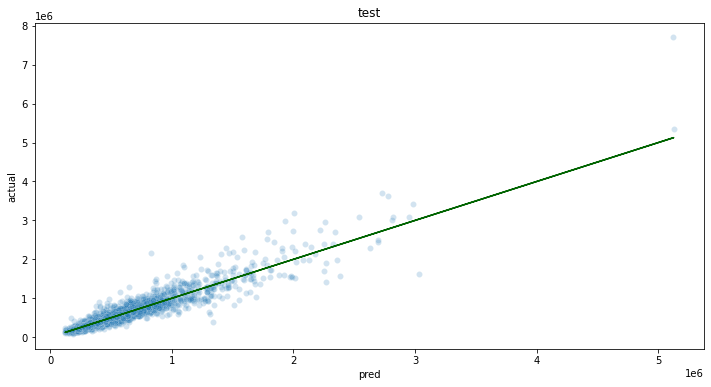
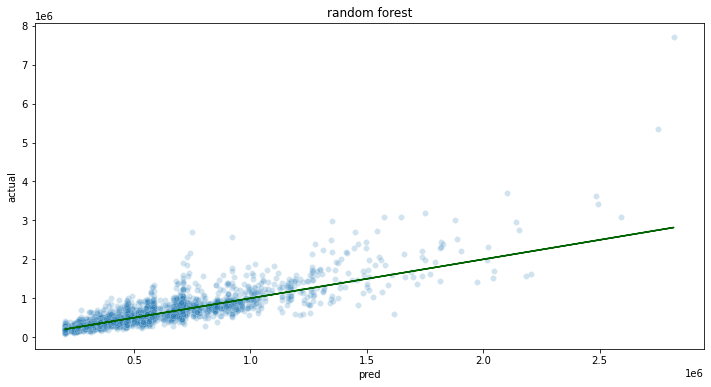
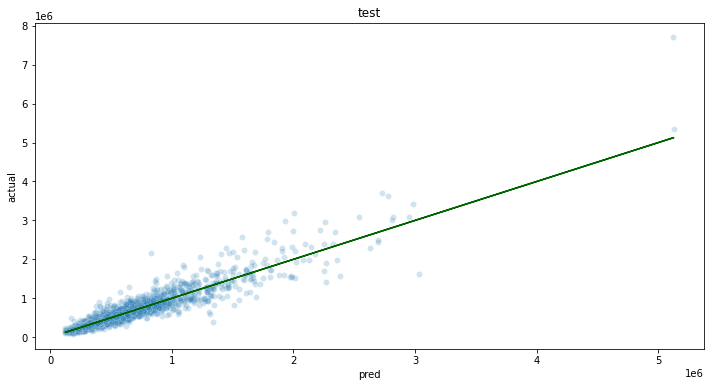
For the purposes of this demo, let’s say that we require a mean absolute percent error (MAPE) of 15% or less, and the we want to try a few models to decide which model we want to use.
One could also hyperparameter tune at this stage; for brevity, we’ll omit that in this demo.
In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
Now that we have decided on the type and structure of the model from Stage 1: Data Exploration And Model Selection, this notebook modularizes the various steps of the process in a structure that is compatible with production and with Wallaroo.
We have pulled the preprocessing and postprocessing steps out of the training notebook into individual scripts that can also be used when the model is deployed.
Assuming no changes are made to the structure of the model, this notebook, or a script based on this notebook, can then be scheduled to run on a regular basis, to refresh the model with more recent training data. We’d expect to run this notebook in conjunction with the Stage 3 notebook, 03_deploy_model.ipynb. For clarity in this demo, we have split the training/upload task into two notebooks, 02_automated_training_process.ipynb and 03_deploy_model.ipynb.
Resources
The following resources are used as part of this tutorial:
data
data/seattle_housing_col_description.txt: Describes the columns used as part data analysis.
data/seattle_housing.csv: Sample data of the Seattle, Washington housing market between 2014 and 2015.
code
postprocess.py: Formats the data after inference by the model is complete.
preprocess.py: Formats the incoming data for the model.
simdb.py: A simulated database to demonstrate sending and receiving queries.
wallaroo_client.py: Additional methods used with the Wallaroo instance to create workspaces, etc.
Note that this connection is simulated to demonstrate how data would be retrieved from an existing data store. For training, we will use the data on all houses sold in this market with the last two years.
importnumpyasnpimportpandasaspdimportsklearnimportxgboostasxgbimportseabornimportmatplotlibimportmatplotlib.pyplotaspltimportpickleimportsimdb# module for the purpose of this demo to simulate pulling data from a databasefrompreprocessimportcreate_features# our custom preprocessingfrompostprocessimportpostprocess# our custom postprocessingmatplotlib.rcParams["figure.figsize"] = (12,6)
# ignoring warnings for demonstrationimportwarningswarnings.filterwarnings('ignore')
conn=simdb.simulate_db_connection()
tablename=simdb.tablenamequery=f"select * from {tablename} where date > DATE(DATE(), '-24 month') AND sale_price is not NULL"print(query)
# read in the datahousing_data=pd.read_sql_query(query, conn)
conn.close()
housing_data.loc[:, ["id", "date", "list_price", "bedrooms", "bathrooms", "sqft_living", "sqft_lot"]]
select * from house_listings where date > DATE(DATE(), '-24 month') AND sale_price is not NULL
id
date
list_price
bedrooms
bathrooms
sqft_living
sqft_lot
0
7129300520
2023-07-31
221900.0
3
1.00
1180
5650
1
6414100192
2023-09-26
538000.0
3
2.25
2570
7242
2
5631500400
2023-12-13
180000.0
2
1.00
770
10000
3
2487200875
2023-09-26
604000.0
4
3.00
1960
5000
4
1954400510
2023-12-06
510000.0
3
2.00
1680
8080
...
...
...
...
...
...
...
...
20518
263000018
2023-03-08
360000.0
3
2.50
1530
1131
20519
6600060120
2023-12-11
400000.0
4
2.50
2310
5813
20520
1523300141
2023-04-10
402101.0
2
0.75
1020
1350
20521
291310100
2023-11-03
400000.0
3
2.50
1600
2388
20522
1523300157
2023-08-02
325000.0
2
0.75
1020
1076
20523 rows × 7 columns
Data transformations
To improve relative error performance, we will predict on log10 of the sale price.
Predict on log10 price to try to improve relative error performance
# split data into training and testoutcome='logprice'runif=np.random.default_rng(2206222).uniform(0, 1, housing_data.shape[0])
gp=np.where(runif<0.2, 'test', 'training')
hd_train=housing_data.loc[gp=='training', :].reset_index(drop=True, inplace=False)
hd_test=housing_data.loc[gp=='test', :].reset_index(drop=True, inplace=False)
# split the training into training and val for xgboostrunif=np.random.default_rng(123).uniform(0, 1, hd_train.shape[0])
xgb_gp=np.where(runif<0.2, 'val', 'train')
Based on the experimentation and testing performed in Stage 1: Data Exploration And Model Selection, XGBoost was selected as the ML model and the variables for training were selected. The model will be generated and tested against sample data.
In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
This step converts the model to onnx for easy import into Wallaroo.
importonnxfromonnxmltools.convertimportconvert_xgboostfromskl2onnx.common.data_typesimportFloatTensorType, DoubleTensorTypeimportpreprocess# set the number of columnsncols=len(preprocess._vars)
# derive the opset valuefromonnx.defsimportonnx_opset_versionfromonnxconverter_common.onnx_eximportDEFAULT_OPSET_NUMBERTARGET_OPSET=min(DEFAULT_OPSET_NUMBER, onnx_opset_version())
# Convert the model to onnxonnx_model_converted=convert_xgboost(xgb_model, 'tree-based classifier',
[('input', FloatTensorType([None, ncols]))],
target_opset=TARGET_OPSET)
# Save the modelonnx.save_model(onnx_model_converted, "housing_model_xgb.onnx")
With the model trained and ready, we can now go to Stage 3: Deploy the Model in Wallaroo.
In this stage, we upload the trained model and the processing steps to Wallaroo, then set up and deploy the inference pipeline.
Once deployed we can feed the newest batch of data to the pipeline, do the inferences and write the results to a results table.
For clarity in this demo, we have split the training/upload task into two notebooks:
02_automated_training_process.ipynb: Train and pickle ML model.
03_deploy_model.ipynb: Upload the model to Wallaroo and deploy into a pipeline.
Assuming no changes are made to the structure of the model, these two notebooks, or a script based on them, can then be scheduled to run on a regular basis, to refresh the model with more recent training data and update the inference pipeline.
This notebook is expected to run within the Wallaroo instance’s Jupyter Hub service to provide access to all required Wallaroo libraries and functionality.
Resources
The following resources are used as part of this tutorial:
data
data/seattle_housing_col_description.txt: Describes the columns used as part data analysis.
data/seattle_housing.csv: Sample data of the Seattle, Washington housing market between 2014 and 2015.
code
simdb.py: A simulated database to demonstrate sending and receiving queries.
models
housing_model_xgb.onnx: Model created in Stage 2: Training Process Automation Setup.
./models/preprocess_byop.zip.: Formats the incoming data for the model.
./models/postprocess_byop.zip: Formats the outgoing data for the model.
Steps
The process of uploading the model to Wallaroo follows these steps:
Connect to Wallaroo: Connect to the Wallaroo instance and set up the workspace.
Upload The Model: Upload the model and autoconvert for use in the Wallaroo engine.
Test the Pipeline: Verify that the pipeline works with the sample data.
Connect to Wallaroo
First we import the required libraries to connect to the Wallaroo instance, then connect to the Wallaroo instance.
importjsonimportpickleimportpandasaspdimportnumpyasnpimportpyarrowaspaimportsimdb# module for the purpose of this demo to simulate pulling data from a database# from wallaroo.ModelConversion import ConvertXGBoostArgs, ModelConversionSource, ModelConversionInputTypeimportwallaroofromwallaroo.objectimportEntityNotFoundError# used to display dataframe information without truncatingfromIPython.displayimportdisplayimportpandasaspdpd.set_option('display.max_colwidth', None)
importdatetime
Connect to the Wallaroo Instance
The first step is to connect to Wallaroo through the Wallaroo client. The Python library is included in the Wallaroo install and available through the Jupyter Hub interface provided with your Wallaroo environment.
This is accomplished using the wallaroo.Client() command, which provides a URL to grant the SDK permission to your specific Wallaroo environment. When displayed, enter the URL into a browser and confirm permissions. Store the connection into a variable that can be referenced later.
If logging into the Wallaroo instance through the internal JupyterHub service, use wl = wallaroo.Client(). For more information on Wallaroo Client settings, see the Client Connection guide.
# Login through local Wallaroo instancewl=wallaroo.Client()
With the connection set and workspace prepared, upload the model created in 02_automated_training_process.ipynb into the current workspace.
To ensure the model input contract matches the provided input, the configuration tensor_fields=["tensor"] is used so regardless of what the model input type is, Wallaroo will ensure inputs of type tensor are accepted.
Waiting for model loading - this will take up to 10.0min.
Model is pending loading to a container runtime..
Model is attempting loading to a container runtime........successful
Waiting for model loading - this will take up to 10.0min.
Model is pending loading to a container runtime..
Model is attempting loading to a container runtime........successful
Ready
Create and Deploy the Pipeline
Create the pipeline with the preprocess module, housing model, and postprocess module as pipeline steps, then deploy the newpipeline.
pipeline=get_pipeline(pipeline_name)
# clear if the tutorial was run beforepipeline.clear()
pipeline.add_model_step(preprocess_model)
pipeline.add_model_step(hpmodel)
pipeline.add_model_step(postprocess_model)
deploy_config=wallaroo.DeploymentConfigBuilder().replica_count(1).cpus(0.5).memory("1Gi").build()
pipeline.deploy(deployment_config=deploy_config)
We will use a single query from the simulated housing_price table and infer. When successful, we will undeploy the pipeline to restore the resources back to the Kubernetes environment.
conn=simdb.simulate_db_connection()
# create the queryquery=f"select * from {simdb.tablename} limit 1"print(query)
# read in the datasingleton=pd.read_sql_query(query, conn)
conn.close()
display(singleton.loc[:, ["id", "date", "list_price", "bedrooms", "bathrooms", "sqft_living", "sqft_lot"]])
In Stage 3: Deploy the Model in Wallaroo, the housing model created and tested in Stage 2: Training Process Automation Setup was uploaded to a Wallaroo instance and added to the pipeline housing-pipe in the workspace housepricing. This pipeline can be deployed at any point and time and used with new inferences.
For the purposes of this demo, let’s say that every month we find the newly entered and still-unsold houses and predict their sale price.
The predictions are entered into a staging table, for further inspection before being joined to the primary housing data table.
We show this as a notebook, but this can also be scripted and scheduled, using CRON or some other process.
Resources
The following resources are used as part of this tutorial:
data
data/seattle_housing_col_description.txt: Describes the columns used as part data analysis.
data/seattle_housing.csv: Sample data of the Seattle, Washington housing market between 2014 and 2015.
code
simdb.py: A simulated database to demonstrate sending and receiving queries.
models
housing_model_xgb.onnx: Model created in Stage 2: Training Process Automation Setup.
./models/preprocess_byop.zip.: Formats the incoming data for the model.
./models/postprocess_byop.zip: Formats the outgoing data for the model.
Steps
This process will use the following steps:
Connect to Wallaroo: Connect to the Wallaroo instance and the housepricing workspace.
Connect to the Wallaroo instance and set the housepricing workspace as the current workspace.
importjsonimportpickleimportwallarooimportpandasaspdimportnumpyasnpimportpyarrowaspaimportdatetimeimportsimdb# module for the purpose of this demo to simulate pulling data from a databasefromwallaroo_clientimportget_workspace# used to display dataframe information without truncatingfromIPython.displayimportdisplaypd.set_option('display.max_colwidth', None)
Connect to the Wallaroo Instance
The first step is to connect to Wallaroo through the Wallaroo client. The Python library is included in the Wallaroo install and available through the Jupyter Hub interface provided with your Wallaroo environment.
This is accomplished using the wallaroo.Client() command, which provides a URL to grant the SDK permission to your specific Wallaroo environment. When displayed, enter the URL into a browser and confirm permissions. Store the connection into a variable that can be referenced later.
If logging into the Wallaroo instance through the internal JupyterHub service, use wl = wallaroo.Client(). For more information on Wallaroo Client settings, see the Client Connection guide.
# Login through local Wallaroo instancewl=wallaroo.Client()
From the data store, load the previous month’s house listing, prepare it as a DataFrame, then submit it for inferencing.
conn=simdb.simulate_db_connection()
# create the queryquery=f"select * from {simdb.tablename} where date > DATE(DATE(), '-1 month') AND sale_price is NULL"print(query)
# read in the data# can't have null values - turn them into 0newbatch=pd.read_sql_query(query, conn)
newbatch['sale_price'] =newbatch.sale_price.apply(lambdax: 0)
display(newbatch.shape)
display(newbatch.head(10).loc[:, ["id", "date", "list_price", "bedrooms", "bathrooms", "sqft_living", "sqft_lot"]])
select * from house_listings where date > DATE(DATE(), '-1 month') AND sale_price is NULL
From here, organizations can automate this process. Other features could be used such as data analysis using Wallaroo assays, or other features such as shadow deployments to test champion and challenger models to find which models provide the best results.