Pipelines represent how data is submitted to your uploaded Machine Learning (ML) models. Pipelines allow you to:
Submit information through an uploaded file or through the Pipeline’s Deployment URL.
Have the Pipeline submit the information to one or more models in sequence.
Once complete, output the result from the model(s).
Pipeline Naming Requirements
Pipeline names map onto Kubernetes objects, and must be DNS compliant. Pipeline names must be ASCII alpha-numeric characters or dash (-) only. . and _ are not allowed.
How to Create a Pipeline and Use a Pipeline
Pipelines can be created through the Wallaroo Dashboard and the Wallaroo SDK. For specifics on using the SDK, see the Wallaroo SDK Guide. For more detailed instructions and step-by-step examples with real models and data, see the Wallaroo Tutorials.
The following instructions are focused on how to use the Wallaroo Dashboard for creating, deploying, and undeploying pipelines.
How to Create a Pipeline using the Wallaroo Dashboard
Prerequisites
Before creating a pipeline through the Wallaroo Dashboard, a model must be uploaded into the workspace through the SDK. For more information, see the Wallaroo SDK Essentials Guide.
IMPORTANT NOTICE
Pipeline names are not forced to be unique. You can have 50 pipelines all named my-pipeline, which can cause confusion in determining which pipeline to use.
It is recommended that organizations agree on a naming convention and select pipeline to use rather than creating a new one each time. See the SDK guides for more information on how to select an existing pipeline.
To create a pipeline:
From the Wallaroo Dashboard, set the current workspace from the top left dropdown list.
Select View Pipelines from the pipeline’s row.
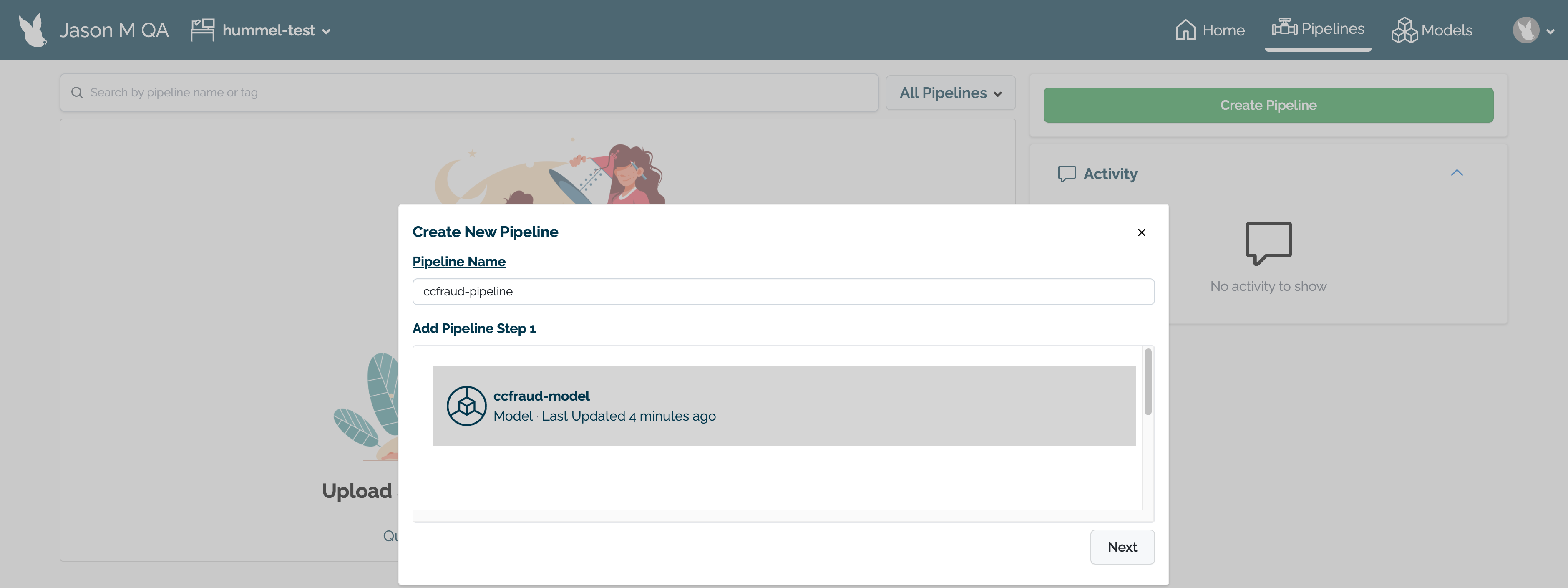
From the upper right hand corner, select Create Pipeline.
Enter the following:
Pipeline Name: The name of the new pipeline. Pipeline names should be unique across the Wallaroo instance.
Add Pipeline Step: Select the models to be used as the pipeline steps.
When finished, select Next.
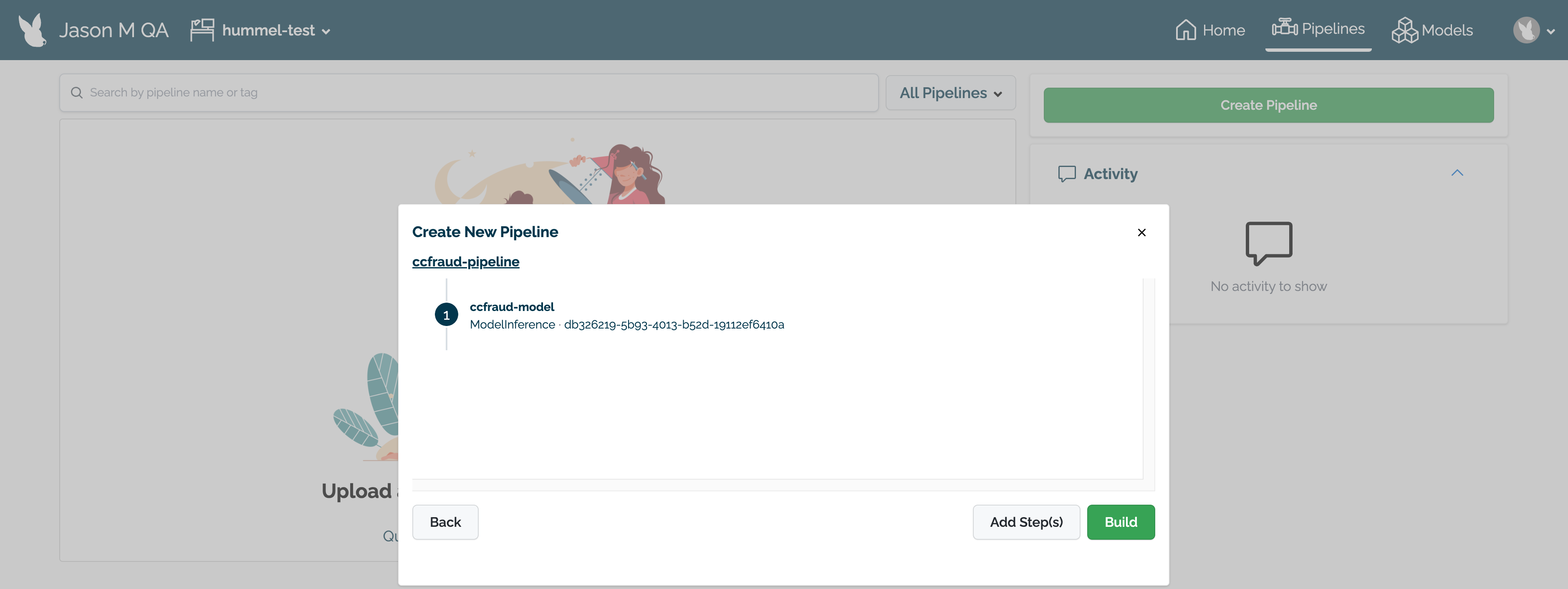
Review the name of the pipeline and the steps. If any adjustments need to be made, select either Back to rename the pipeline or Add Step(s) to change the pipeline’s steps.
When finished, select Build to create the pipeline in this workspace. The pipeline will be built and be ready for deployment within a minute.
How to Deploy and Undeploy a Pipeline using the Wallaroo Dashboard
Deployed pipelines create new namespaces in the Kubernetes environment where the Wallaroo instance is deployed, and allocate resources from the Kubernetes environment to run the pipeline and its steps.
To deploy a pipeline:
From the Wallaroo Dashboard, set the current workspace from the top left dropdown list.
Select View Pipelines from the pipeline’s row.
Select the pipeline to deploy.
From the right navigation panel, select Deploy.
A popup module will request verification to deploy the pipeline. Select Deploy again to deploy the pipeline.
Undeploying a pipeline returns resources back to the Kubernetes environment and removes the namespaces created when the pipeline was deployed.
To undeploy a pipeline:
From the Wallaroo Dashboard, set the current workspace from the top left dropdown list.
Select View Pipelines from the pipeline’s row.
Select the pipeline to deploy.
From the right navigation panel, select Undeploy.
A popup module will request verification to undeploy the pipeline. Select Undeploy again to undeploy the pipeline.
How to View a Pipeline Details and Metrics
To view a pipeline’s details:
From the Wallaroo Dashboard, set the current workspace from the top left dropdown list.
Select View Pipelines from the pipeline’s row.
To view details on the pipeline, select the name of the pipeline.
A list of the pipeline’s details will be displayed.
To view a pipeline’s metrics:
From the Wallaroo Dashboard, set the current workspace from the top left dropdown list.
Select View Pipelines from the pipeline’s row.
To view details on the pipeline, select the name of the pipeline.
A list of the pipeline’s details will be displayed.
Select Metrics to view the following information. From here you can select the time period to display metrics from through the drop down to display the following:
Requests per second
Cluster inference rate
Inference latency
The Audit Log and Anomaly Log are available to view further details of the pipeline’s activities.
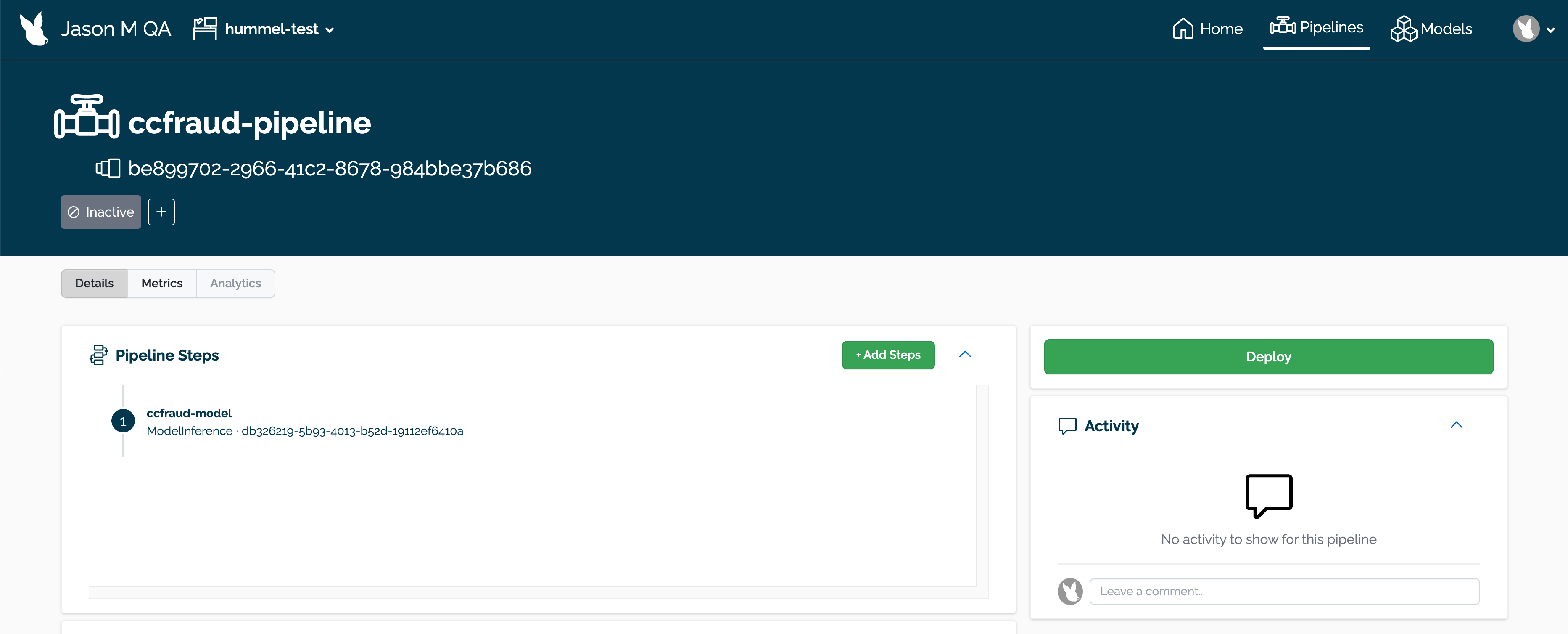
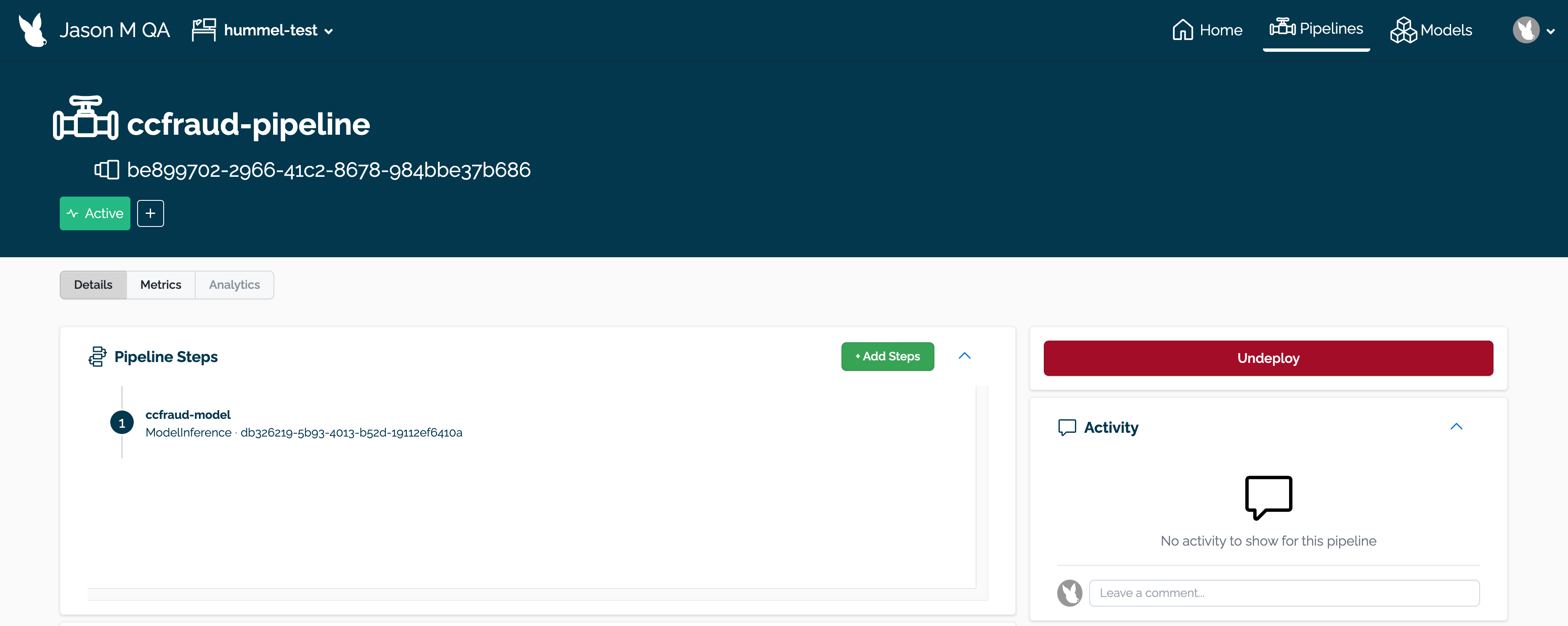
Pipeline Details
The following is available from the Pipeline Details page:
The name of the pipeline.
The pipeline ID: This is in UUID format.
Pipeline steps: The steps and the models in each pipeline step.
Version History: how the pipeline has been updated over time.
1 - Wallaroo Pipeline Edge Publication Management
How to manage pipeline publications
Wallaroo Pipelines are deployed to edge devices by publishing them to Open Container Initiative (OCI) registries. This is managed through the Wallaroo MLOps API, the Wallaroo SDK, and through the Wallaroo Dashboard.
The following describes how to use the Wallaroo Dashboard to:
View published pipeline information
Publish a pipeline to an OCI Registry
Deploy a pipeline to an edge device from an OCI Registry
Wallaroo Dashboard Pipeline Publish Management
Wallaroo pipeline publications are managed through the Wallaroo Dashboard Pipeline pages. This requires that Edge Deployment Registry is enabled.
Wallaroo pipelines are published as containers to OCI registries, and are referred to as publishes.
Access Wallaroo Pipeline Publishes
To view the publishes for a specific pipeline through the Wallaroo Dashboard:
Login to the Wallaroo Dashboard through your browser.
From the Workspace select menu on the upper left, select the workspace the pipeline is associated in.
Select the pipeline to view the Pipeline Versions, which contain the Pipeline Publishes for each Pipeline Versions.
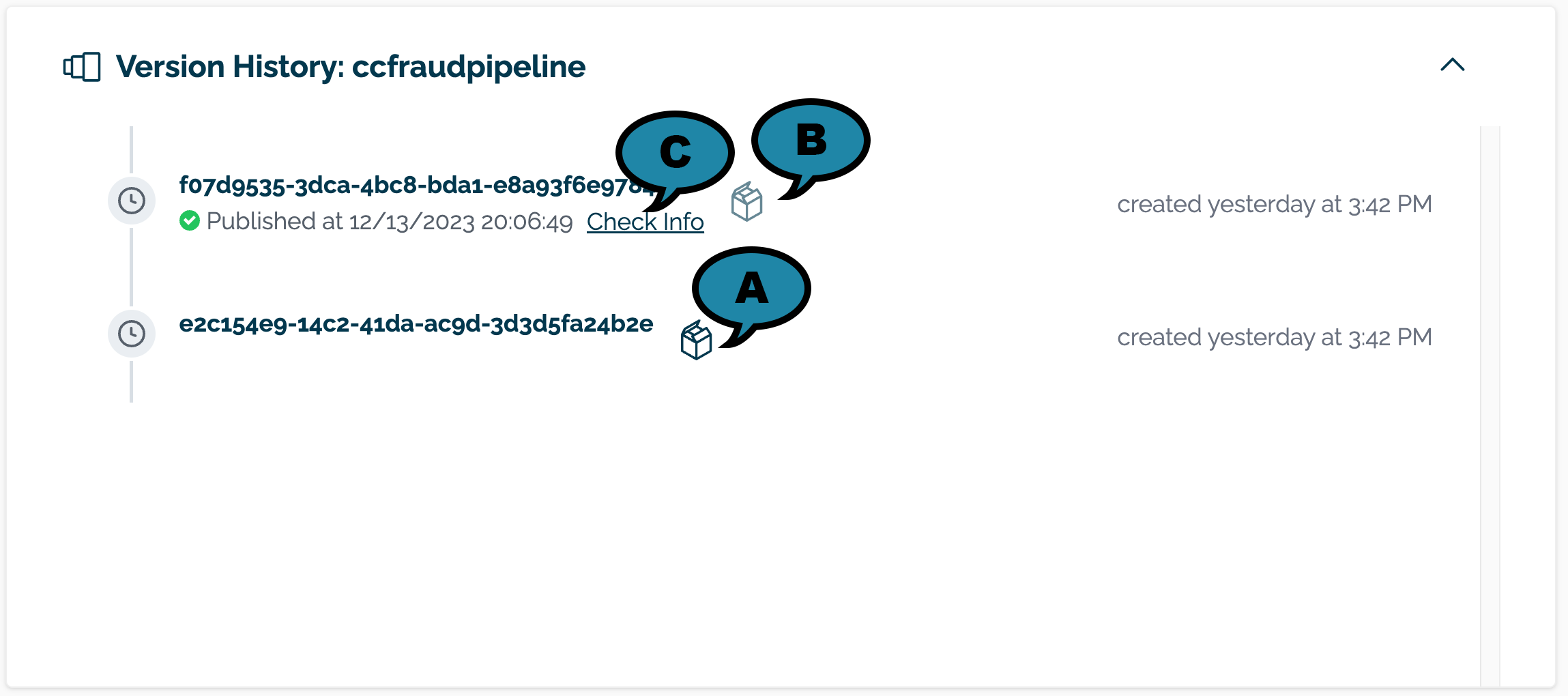
The list of pipeline versions are available in the Version History section.
Unpublished versions are indicated with a black box (A) to the right of the pipeline version. Published pipelines are indicated with a gray box. (B). Publish details are visible by selecting Check Info (C).
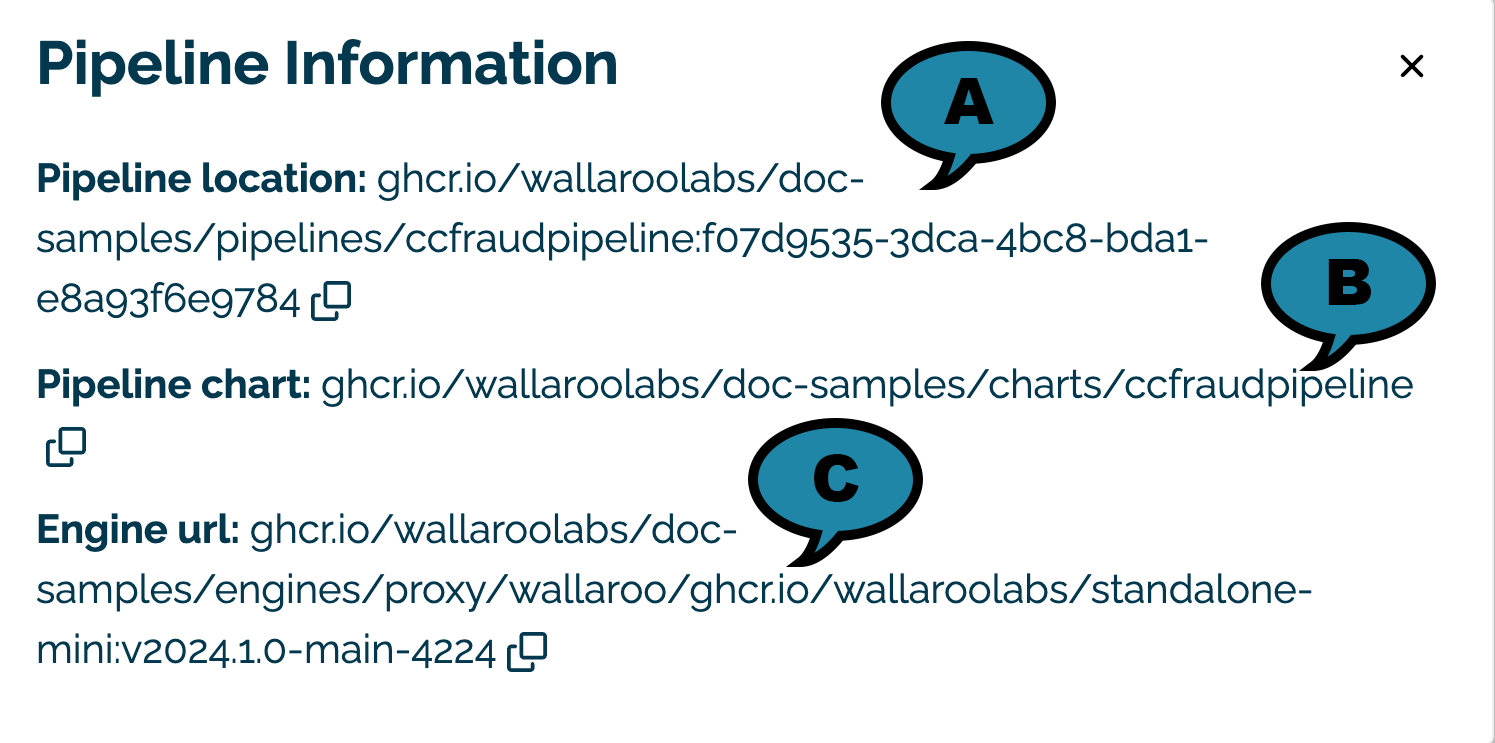
Select Check Info to view pipeline details.
Pipeline location (A): The URL for the containerized pipeline.
PIpeline Chart (B): The URL for the Helm chart of the published pipeline and engine.
Engine url (B): The URL for the Wallaroo Engine required to deploy the pipeline and perform inference requests.
Publish a Wallaroo Pipeline Version
To publish a version of the Wallaroo pipeline:
From the Pipeline Versions view:
Select the black box to the right of a Pipeline Version identifier. Grey boxes indicate that the pipeline version is already published.
Wait for the publish to complete. Depending on the number and size of the pipeline steps in the pipeline version, this may take anywhere from 1 to 10 minutes.
DevOps - Pipeline Edge Deployment
Once a pipeline is deployed to the Edge Registry service, it can be deployed in environments such as Docker, Kubernetes, or similar container running services by a DevOps engineer.
Docker Deployment
First, the DevOps engineer must authenticate to the same OCI Registry service used for the Wallaroo Edge Deployment registry.
For more details, check with the documentation on your artifact service. The following are provided for the three major cloud services:
For the deployment, the engine URL is specified with the following environmental variables:
DEBUG (true|false): Whether to include debug output.
OCI_REGISTRY: The URL of the registry service.
CONFIG_CPUS: The number of CPUs to use.
OCI_USERNAME: The edge registry username.
OCI_PASSWORD: The edge registry password or token.
PIPELINE_URL: The published pipeline URL.
EDGE_BUNDLE (Optional): The base64 encoded edge token and other values to connect to the Wallaroo Ops instance. This is used for edge management and transmitting inference results for observability. IMPORTANT NOTE: The token for EDGE_BUNDLE is valid for one deployment. For subsequent deployments, generate a new edge location with its own EDGE_BUNDLE.
Login through docker to confirm access to the registry service. First, docker login. For example, logging into the artifact registry with the token stored in the variable tok:
Then deploy the Wallaroo published pipeline with an edge added to the pipeline publish through docker run.
IMPORTANT NOTE: Edge deployments with Edge Observability enabled with the EDGE_BUNDLE option include an authentication token that only authenticates once. To store the token long term, include the persistent volume flag -v {path to storage} setting.
For users who prefer to use docker compose, the following sample compose.yaml file is used to launch the Wallaroo Edge pipeline. This is the same used in the Wallaroo Use Case Tutorials Computer Vision: Retail tutorials. The volumes tag is used to preserve the login session from the one-time token generated as part of the EDGE_BUNDLE.
EDGE_BUNDLE is only required when adding an edge to a Wallaroo publish for observability. The following is deployed without observability.
Login through docker to confirm access to the registry service. First, docker login. For example, logging into the artifact registry with the token stored in the variable tok to the registry us-west1-docker.pkg.dev:
IMPORTANT NOTE: Edge deployments with Edge Observability enabled with the EDGE_BUNDLE option include an authentication token that only authenticates once. To store the token long term, include the persistent volume with the volumes: tag.
The deployment and undeployment is then just a simple docker compose up and docker compose down. The following shows an example of deploying the Wallaroo edge pipeline using docker compose.
docker compose up
[+] Running 1/1
✔ Container cv_data-engine-1 Recreated 0.5s
Attaching to cv_data-engine-1
cv_data-engine-1 | Wallaroo Engine - Standalone mode
cv_data-engine-1 | Login Succeeded
cv_data-engine-1 | Fetching manifest and config for pipeline: sample-registry.com/pipelines/edge-cv-retail:bf70eaf7-8c11-4b46-b751-916a43b1a555
cv_data-engine-1 | Fetching model layers
cv_data-engine-1 | digest: sha256:c6c8869645962e7711132a7e17aced2ac0f60dcdc2c7faa79b2de73847a87984
cv_data-engine-1 | filename: c6c8869645962e7711132a7e17aced2ac0f60dcdc2c7faa79b2de73847a87984
cv_data-engine-1 | name: resnet-50
cv_data-engine-1 | type: model
cv_data-engine-1 | runtime: onnx
cv_data-engine-1 | version: 693e19b5-0dc7-4afb-9922-e3f7feefe66d
cv_data-engine-1 |
cv_data-engine-1 | Fetched
cv_data-engine-1 | Starting engine
cv_data-engine-1 | Looking for preexisting `yaml` files in //modelconfigs
cv_data-engine-1 | Looking for preexisting `yaml` files in //pipelines
Helm Deployment
Published pipelines can be deployed through the use of helm charts.
Helm deployments take up to two steps - the first step is in retrieving the required values.yaml and making updates to override.
IMPORTANT NOTE: Edge deployments with Edge Observability enabled with the EDGE_BUNDLE option include an authentication token that only authenticates once. Helm chart installations automatically add a persistent volume during deployment to store the authentication session data for future deployments.
Login to the registry service with helm registry login. For example, if the token is stored in the variable tok:
Pull the helm charts from the published pipeline. The two fields are the Helm Chart URL and the Helm Chart version to specify the OCI . This typically takes the format of:
Extract the tgz file and copy the values.yaml and copy the values used to edit engine allocations, etc. The following are required for the deployment to run:
Once deployed, the DevOps engineer will have to forward the appropriate ports to the svc/engine-svc service in the specific pipeline. For example, using kubectl port-forward to the namespace ccfraud that would be:
elapsed (List[Integer]): A list of time in nanoseconds for:
[0] The time to serialize the input.
[1…n] How long each step took.
model_name (String): The name of the model used.
model_version (String): The version of the model in UUID format.
original_data: The original input data. Returns null if the input may be too long for a proper return.
outputs (List): The outputs of the inference result separated by data type, where each data type includes:
data: The returned values.
dim (List[Integer]): The dimension shape returned.
v (Integer): The vector shape of the data.
pipeline_name (String): The name of the pipeline.
shadow_data: Any shadow deployed data inferences in the same format as outputs.
time (Integer): The time since UNIX epoch.
Edge Inference Endpoint Example
The following example demonstrates sending an Apache Arrow table to the Edge deployed pipeline, requesting the inference results back in a pandas DataFrame records format.
When an edge is added to a pipeline publish, the field docker_run_variables contains a JSON value for edge devices to connect to the Wallaroo Ops instance.
The settings are stored in the key EDGE_BUNDLE as a base64 encoded value that include the following:
BUNDLE_VERSION: The current version of the bundled Wallaroo pipeline.
EDGE_NAME: The edge name as defined when created and added to the pipeline publish.
JOIN_TOKEN_: The one time authentication token for authenticating to the Wallaroo Ops instance.
OPSCENTER_HOST: The hostname of the Wallaroo Ops edge service. See Edge Deployment Registry Guide for full details on enabling pipeline publishing and edge observability to Wallaroo.
PIPELINE_URL: The OCI registry URL to the containerized pipeline.
The JOIN_TOKEN is a one time access token. Once used, a JOIN_TOKEN expires. The authentication session data is stored in persistent volumes. Persistent volumes must be specified for docker and docker compose based deployments of Wallaroo pipelines; helm based deployments automatically provide persistent volumes to store authentication credentials.
The JOIN_TOKEN has the following time to live (TTL) parameters.
Once created, the JOIN_TOKEN is valid for 24 hours. After it expires the edge will not be allowed to contact the OpsCenter the first time and a new edge bundle will have to be created.
After an Edge joins to Wallaroo Ops for the first time with persistent storage, the edge must contact the Wallaroo Ops instance at least onceevery 7 days.
If this period is exceeded, the authentication credentials will expire and a new edge bundle must be created with a new and valid JOIN_TOKEN.
Wallaroo edges require unique names. To create a new edge bundle with the same name:
Use Add Edge to add the edge with the same name. A new EDGE_BUNDLE is generated with a new JOIN_TOKEN.
2 - Wallaroo Pipeline Tag Management
How to manage tags and pipelines.
Tags can be used to label, search, and track pipelines across a Wallaroo instance. The following guide will demonstrate how to:
Create a tag for a specific pipeline.
Remove a tag for a specific pipeline.
The example shown uses the pipeline ccfraudpipeline.
Steps
Add a New Tag to a Pipeline
To set a tag to pipeline using the Wallaroo Dashboard:
Log into your Wallaroo instance.
Select the workspace the pipelines are associated with.
Select View Pipelines.
From the Pipeline Select Dashboard page, select the pipeline to update.
From the Pipeline Dashboard page, select the + icon under the name of the pipeline and it’s hash value.
Enter the name of the new tag. When complete, select Enter. The tag will be set for this pipeline.
Remove a Tag from a Pipeline
To remove a tag from a pipeline:
IMPORTANT NOTE
Once a tag is deleted from a pipeline, it can not be undeleted.
Log into your Wallaroo instance.
Select the workspace the pipelines are associated with.
Select View Pipelines.
From the Pipeline Select Dashboard page, select the pipeline to update.
From the Pipeline Dashboard page, select the select the X for the tag to delete. The tag will be removed from the pipeline.
Wallaroo SDK Tag Management
Tags are applied to either model versions or pipelines. This allows organizations to track different versions of models, and search for what pipelines have been used for specific purposes such as testing versus production use.
Create Tag
Tags are created with the Wallaroo client command create_tag(String tagname). This creates the tag and makes it available for use.
The tag will be saved to the variable currentTag to be used in the rest of these examples.
# Now we create our tagcurrentTag=wl.create_tag("My Great Tag")
List Tags
Tags are listed with the Wallaroo client command list_tags(), which shows all tags and what models and pipelines they have been assigned to.
Tags are used with pipelines to track different pipelines that are built or deployed with different features or functions.
Add Tag to Pipeline
Tags are added to a pipeline through the Wallaroo Tag add_to_pipeline(pipeline_id) method, where pipeline_id is the pipeline’s integer id.
For this example, we will add currentTag to testtest_pipeline, then verify it has been added through the list_tags command and list_pipelines command.
# add this tag to the pipelinecurrentTag.add_to_pipeline(tagtest_pipeline.id())
{'pipeline_pk_id': 1, 'tag_pk_id': 1}
Search Pipelines by Tag
Pipelines can be searched through the Wallaroo Client search_pipelines(search_term) method, where search_term is a string value for tags assigned to the pipelines.
In this example, the text “My Great Tag” that corresponds to currentTag will be searched for and displayed.
wl.search_pipelines('My Great Tag')
name
version
creation_time
last_updated_time
deployed
tags
steps
tagtestpipeline
5a4ff3c7-1a2d-4b0a-ad9f-78941e6f5677
2022-29-Nov 17:15:21
2022-29-Nov 17:15:21
(unknown)
My Great Tag
Remove Tag from Pipeline
Tags are removed from a pipeline with the Wallaroo Tag remove_from_pipeline(pipeline_id) command, where pipeline_id is the integer value of the pipeline’s id.
For this example, currentTag will be removed from tagtest_pipeline. This will be verified through the list_tags and search_pipelines command.
## remove from pipelinecurrentTag.remove_from_pipeline(tagtest_pipeline.id())
{'pipeline_pk_id': 1, 'tag_pk_id': 1}
3 - Wallaroo Anomaly Detection
How to use validations to detect data anomalies in data inputs or outputs.
Viewing Detected Anomalies via the Wallaroo Dashboard
Wallaroo provides validations: user defined expressions on model inference input and outputs that determine if data falls outside expected norms. For more details on adding validations to a Wallaroo pipeline, see Detecting Anomalies with Validations via the Wallaroo SDK.
Detected anomaly analytics are available through the Wallaroo Dashboard user interface for each pipeline.
Access the Pipeline Analytics Page
To access a pipeline’s analytics page:
From the Wallaroo Dashboard, select the workspace, then the View Pipelines to view.
Select the pipeline to view.
From the pipeline page, select Analytics.
The following analytics options are available.
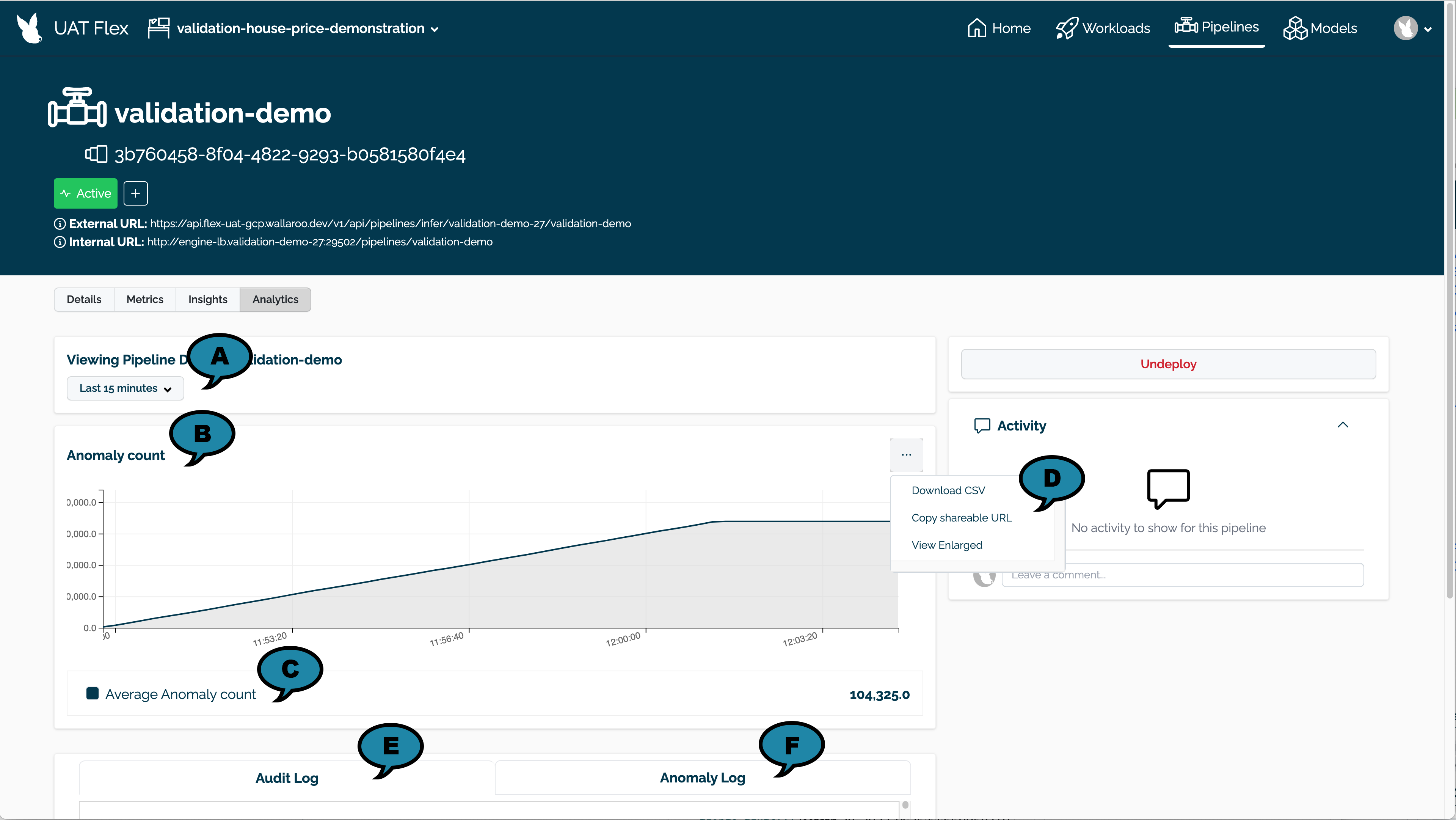
(A) Time Filter: Select the time range of inference requests to filter.
(B) Anomaly Count: A chart of the count of anomalies detected from inference requests over time.
(C) Average Anomaly Count: The average number of anomaly’s detected over the filtered time range.
(D) Actions: The following actions are available:
Download CSV: Download a CSV of the anomaly counts shown in the chart.
Copy sharable URL: Copy a URL of the anomaly count data shared with other registered Wallaroo instance users.
View Enlarged: View an enlarged version of the anomaly count chart..
(E) Audit Log: Logs of all inference requests over the filtered time period.
(F) Anomaly Log: Logs of inference requests with a detected anomaly over the filtered time period.
Detecting Anomalies with Validations via the Wallaroo SDK
Wallaroo provides validations to detect anomalous data from inference inputs and outputs.
Validations are added to a Wallaroo pipeline with the wallaroo.pipeline.add_validations method.
IMPORTANT NOTE: Validation names must be unique per pipeline. If a validation of the same name is added, both are included in the pipeline validations, but only most recent validation with the same name is displayed with the inference results. Anomalies detected by multiple validations of the same name are added to the anomaly.count inference result field.
Adding validations to a pipeline takes the format:
validation_name: The user provided name of the validation. The names must match Python variable naming requirements.
IMPORTANT NOTE: Using the name count as a validation name returns an error. Any validation rules named count are dropped upon request and a warning returned.
polars.col(in|out.{column_name}): Specifies the input or output for a specific field aka “column” in an inference result. Wallaroo inference requests are in the format in.{field_name} for inputs, and out.{field_name} for outputs.
EXPRESSION: The expression to validate. When the expression returns True, that indicates an anomaly detected.
The polars library version 0.18.5 is used to create the validation rule. This is installed by default with the Wallaroo SDK. This provides a powerful range of comparisons to organizations tracking anomalous data from their ML models.
When validations are added to a pipeline, inference request outputs return the following fields:
Field
Type
Description
anomaly.count
Integer
The total of all validations that returned True.
anomaly.{validation name}
Bool
The output of the validation {validation_name}.
When validation returns True, an anomaly is detected.
For example, adding the validation fraud to the following pipeline returns anomaly.count of 1 when the validation fraud returns True. The validation fraud returns True when the output field dense_1 at index 0 is greater than 0.9.
sample_pipeline=wallaroo.client.build_pipeline("sample-pipeline")
sample_pipeline.add_model_step(ccfraud_model)
# add the validationsample_pipeline.add_validations(
fraud=pl.col("out.dense_1").list.get(0) >0.9,
)
# deploy the pipelinesample_pipeline.deploy()
# sample inferencedisplay(sample_pipeline.infer_from_file("dev_high_fraud.json", data_format='pandas-records'))
time
in.tensor
out.dense_1
anomaly.count
anomaly.fraud
0
2024-02-02 16:05:42.152
[1.0678324729, 18.1555563975, -1.6589551058, 5…]
[0.981199]
1
True
Detecting Anomalies from Inference Request Results
When an inference request is submitted to a Wallaroo pipeline with validations, the following fields are output:
Field
Type
Description
anomaly.count
Integer
The total of all validations that returned True.
anomaly.{validation name}
Bool
The output of each pipeline validation {validation_name}.
For example, adding the validation fraud to the following pipeline returns anomaly.count of 1 when the validation fraud returns True.
sample_pipeline=wallaroo.client.build_pipeline("sample-pipeline")
sample_pipeline.add_model_step(ccfraud_model)
# add the validationsample_pipeline.add_validations(
fraud=pl.col("out.dense_1").list.get(0) >0.9,
)
# deploy the pipelinesample_pipeline.deploy()
# sample inferencedisplay(sample_pipeline.infer_from_file("dev_high_fraud.json", data_format='pandas-records'))
time
in.tensor
out.dense_1
anomaly.count
anomaly.fraud
0
2024-02-02 16:05:42.152
[1.0678324729, 18.1555563975, -1.6589551058, 5…]
[0.981199]
1
True
Validation Examples
Common Data Selection Expressions
The following sample expressions demonstrate different methods of selecting which model input or output data to validate.
polars.col(in|out.{column_name}).list.get(index): Returns the index of a specific field. For example, pl.col("out.dense_1") returns from the inference the output the field dense_1, and list.get(0) returns the first value in that list. Most output values from a Wallaroo inference result are a List of at least length 1, making this a common validation expression.
polars.col(in.price_ranges).list.max(): Returns from the inference request the input field price_ranges the maximum value from a list of values.
polars.col(out.price_ranges).mean() returns the mean for all values from the output field price_ranges.
For example, to the following validation fraud detects values for the output of an inference request for the field dense_1 that are greater than 0.9, indicating a transaction has a high likelihood of fraud:
For the input provided, the minimum_sales validation would return True, indicating an anomaly.
time
out.predicted_sales
anomaly.count
anomaly.minimum_sales
0
2023-10-31 16:57:13.771
[1527]
1
True
Detecting Output Anomalies
The following validation detects an anomaly from a output.
fraud: Detects when an inference output for the field dense_1 at index 0 is greater than 0.9, indicating fraud.
# create the pipelinesample_pipeline=wallaroo.client.build_pipeline("sample-pipeline")
# add a model stepsample_pipeline.add_model_step(ccfraud_model)
# add validations to the pipelinesample_pipeline.add_validations(
fraud=pl.col("out.dense_1").list.get(0) >0.9 )
sample_pipeline.deploy()
sample_pipeline.infer_from_file("dev_high_fraud.json")
time
in.tensor
out.dense_1
anomaly.count
anomaly.fraud
0
2024-02-02 16:05:42.152
[1.0678324729, 18.1555563975, -1.6589551058, 5...
[0.981199]
1
True
Multiple Validations
The following demonstrates multiple validations added to a pipeline at once and their results from inference requests. Two validations that track the same output field and index are applied to a pipeline:
fraud: Detects an anomaly when the inference output field dense_1 at index 0 value is greater than 0.9.
too_low: Detects an anomaly when the inference output field dense_1 at the index 0 value is lower than 0.05.
The following example tracks two validations for a model that takes the previous week’s sales and projects the next week’s average sales with the field predicted_sales.
minimum_sales=pl.col("in.sales_count").list.min() < 500: The input field sales_count with a range of values has any minimum value under 500.
average_sales_too_low=pl.col("out.predicted_sales").list.get(0) < 500: The output field predicted_sales is less than 500.
The following inputs return the following values. Note how the anomaly.count value changes by the number of validations that detect an anomaly.
Input 1:
In this example, one day had sales under 500, which triggers the minimum_sales validation to return True. The predicted sales are above 500, causing the average_sales_too_low validation to return False.
week
site_id
sales_count
0
[28]
[site0001]
[1357, 1247, 350, 1437, 952, 757, 1831]
Output 1:
time
out.predicted_sales
anomaly.count
anomaly.minimum_sales
anomaly.average_sales_too_low
0
2023-10-31 16:57:13.771
[1527]
1
True
False
Input 2:
In this example, multiple days have sales under 500, which triggers the minimum_sales validation to return True. The predicted average sales for the next week are above 500, causing the average_sales_too_low validation to return True.
week
site_id
sales_count
0
[29]
[site0001]
[497, 617, 350, 200, 150, 400, 110]
Output 2:
time
out.predicted_sales
anomaly.count
anomaly.minimum_sales
anomaly.average_sales_too_low
0
2023-10-31 16:57:13.771
[325]
2
True
True
Input 3:
In this example, no sales day figures are below 500, which triggers the minimum_sales validation to return False. The predicted sales for the next week is below 500, causing the average_sales_too_low validation to return True.
week
site_id
sales_count
0
[30]
[site0001]
[617, 525, 513, 517, 622, 757, 508]
Output 3:
time
out.predicted_sales
anomaly.count
anomaly.minimum_sales
anomaly.average_sales_too_low
0
2023-10-31 16:57:13.771
[497]
1
False
True
Compound Validations
The following combines multiple field checks into a single validation. For this, we will check for values of out.dense_1 that are between 0.05 and 0.9.
How to create and use assays to monitor model inputs and outputs.
Model Insights and Interactive Analysis Introduction
Wallaroo provides the ability to perform interactive analysis so organizations can explore the data from a pipeline and learn how the data is behaving. With this information and the knowledge of your particular business use case you can then choose appropriate thresholds for persistent automatic assays as desired.
IMPORTANT NOTE
Model insights operates over time and is difficult to demo in a notebook without pre-canned data. We assume you have an active pipeline that has been running and making predictions over time and show you the code you may use to analyze your pipeline.
Monitoring tasks called assays monitors a model’s predictions or the data coming into the model against an established baseline. Changes in the distribution of this data can be an indication of model drift, or of a change in the environment that the model trained for. This can provide tips on whether a model needs to be retrained or the environment data analyzed for accuracy or other needs.
Assay Details
Assays contain the following attributes:
Attribute
Default
Description
Name
The name of the assay. Assay names must be unique.
Baseline Data
Data that is known to be “typical” (typically distributed) and can be used to determine whether the distribution of new data has changed.
Schedule
Every 24 hours at 1 AM
Configure the start time and frequency of when the new analysis will run. New assays are configured to run a new analysis for every 24 hours starting at the end of the baseline period. This period can be configured through the SDK.
Group Results
Daily
How the results are grouped: Daily (Default), Every Minute, Weekly, or Monthly.
Metric
PSI
Population Stability Index (PSI) is an entropy-based measure of the difference between distributions. Maximum Difference of Bins measures the maximum difference between the baseline and current distributions (as estimated using the bins). Sum of the difference of bins sums up the difference of occurrences in each bin between the baseline and current distributions.
Threshold
0.1
Threshold for deciding the difference between distributions is similar(small) or different(large), as evaluated by the metric. The default of 0.1 is generally a good threshold when using PSI as the metric.
Number of Bins
5
Number of bins used to partition the baseline data. By default, the binning scheme is percentile (quantile) based. The binning scheme can be configured (see Bin Mode, below). Note that the total number of bins will include the set number plus the left_outlier and the right_outlier, so the total number of bins will be the total set + 2.
Bin Mode
Quantile
Specify the Binning Scheme. Available options are: Quantile binning defines the bins using percentile ranges (each bin holds the same percentage of the baseline data). Equal binning defines the bins using equally spaced data value ranges, like a histogram. Custom allows users to set the range of values for each bin, with the Left Outlier always starting at Min (below the minimum values detected from the baseline) and the Right Outlier always ending at Max (above the maximum values detected from the baseline).
Bin Weight
Equally Weighted
The weight applied to each bin. The bin weights can be either set to Equally Weighted (the default) where each bin is weighted equally, or Custom where the bin weights can be adjusted depending on which are considered more important for detecting model drift.
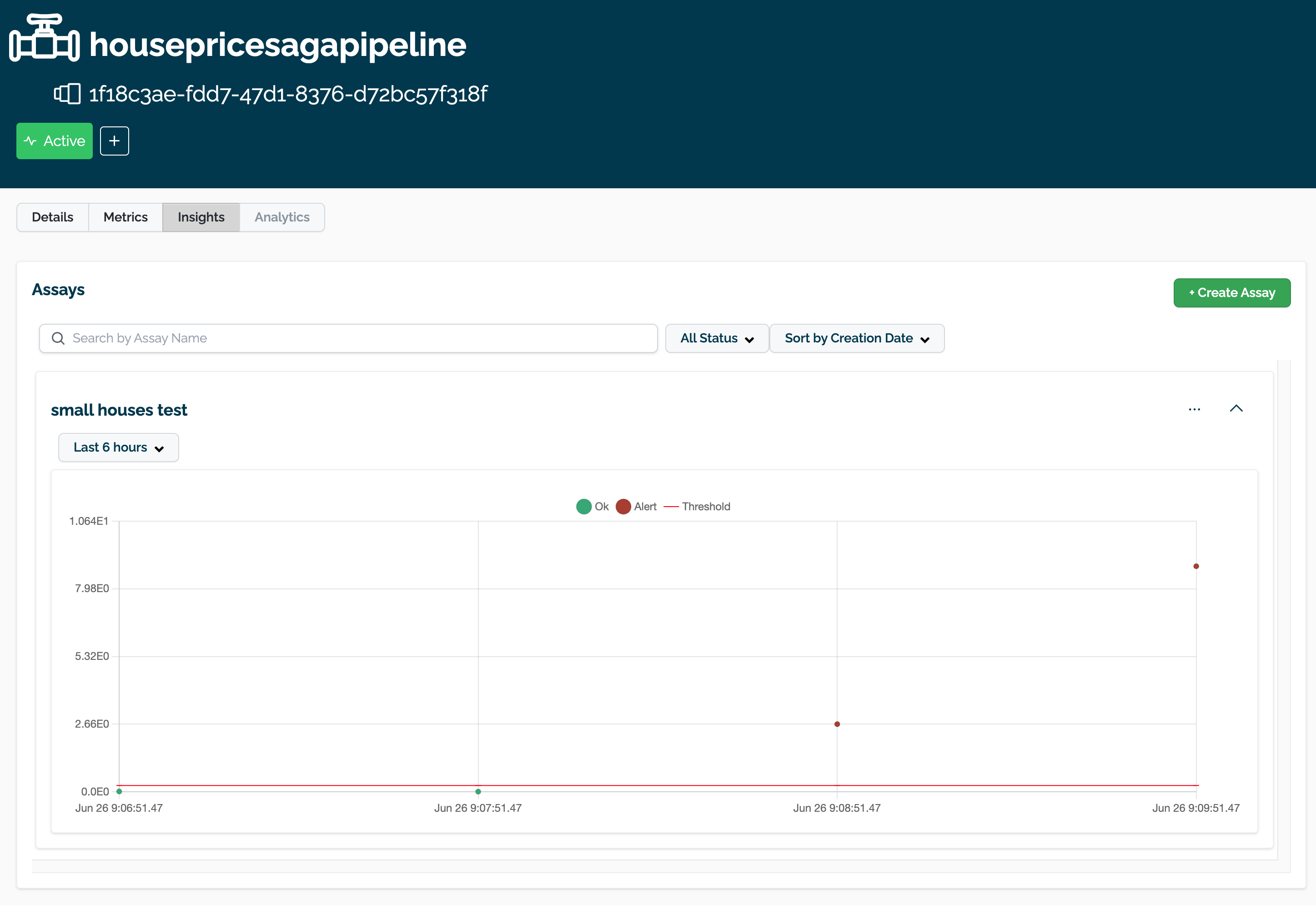
Manage Assays via the Wallaroo Dashboard
Assays can be created and used via the Wallaroo Dashboard.
Accessing Assays Through the Pipeline Dashboard
Assays created through the Wallaroo Dashboard are accessed through the Pipeline Dashboard through the following process.
Log into the Wallaroo Dashboard.
Select the workspace containing the pipeline with the models being monitored from the Change Current Workspace and Workspace Management drop down.
Select View Pipelines.
Select the pipeline containing the models being monitored.
Select Insights.
The Wallaroo Assay Dashboard contains the following elements. For more details of each configuration type, see the Model Insights and Assays Introduction.
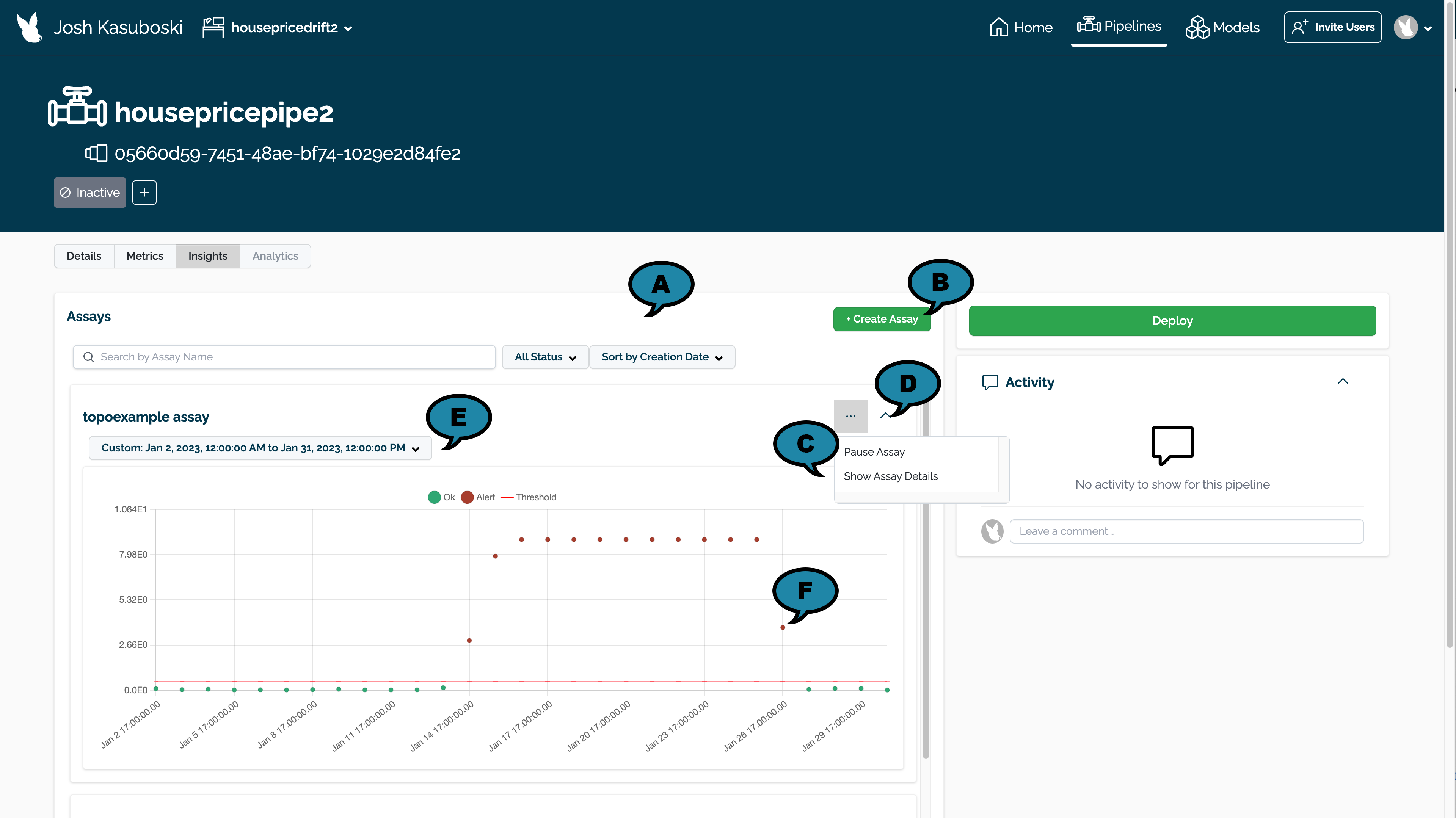
(A) Filter Assays: Filter assays by the following:
Name
Status:
Active: The assay is currently running.
Paused: The assay is paused until restarted.
Drift Detected: One or more drifts have been detected.
Sort By
Sort by Creation Date: Sort by the most recent Assays first.
Last Assay Run: Sort by the most recent Assay Last Run date.
(B) Create Assay: Create a new assay.
(C) Assay Controls:
Pause/Start Assay: Pause a running assay, or start one that was paused.
Show Assay Details: View assay details. See Assay Details View for more details.
(D) Collapse Assay: Collapse or Expand the assay for view.
(E) Time Period for Assay Data: Set the time period for data to be used in displaying the assay results.
(F) Assay Events: Select an individual assay event to see more details. See View Assay Alert Details for more information.
Assay Details View
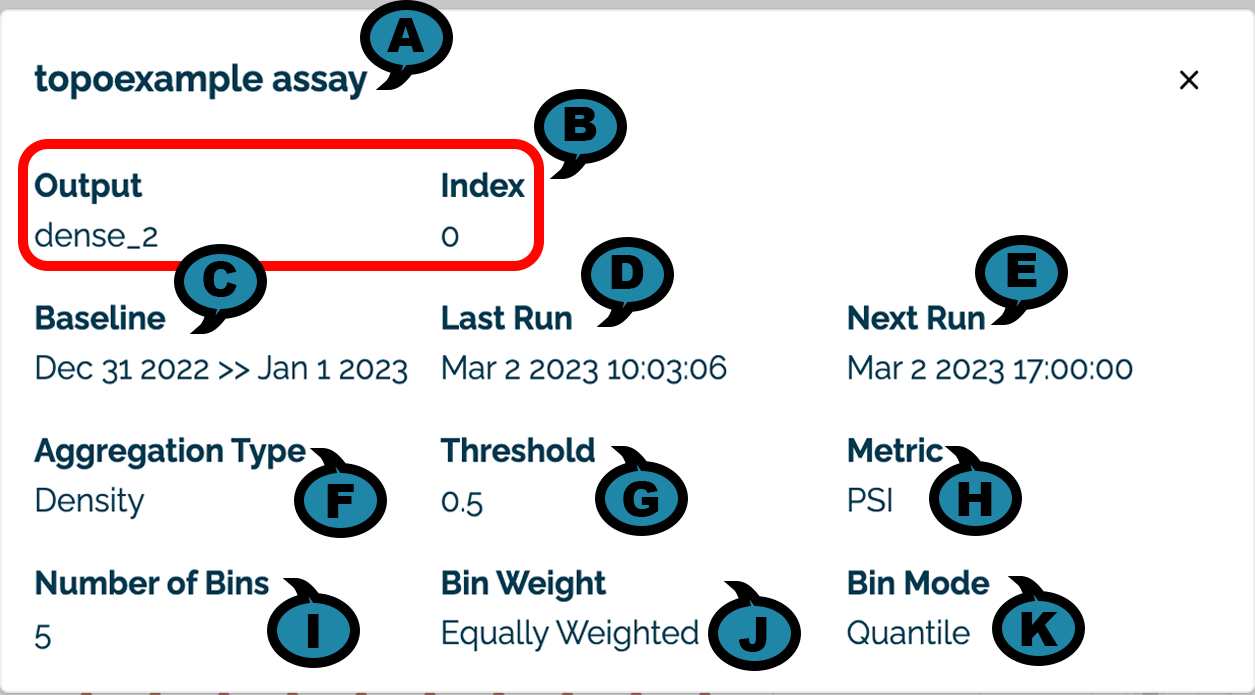
The following details are visible by selecting the Assay View Details icon:
(A) Assay Name: The name of the assay displayed.
(B) Input / Output: The input or output and the index of the element being monitored.
(C) Baseline: The time period used to generate the baseline. For baselines generated from a file, the baseline displayed Uploaded File.
(D) Last Run: The date and time the assay was last run.
(E) Next Run: The future date and time the assay will be run again. NOTE: If the assay is paused, then it will not run at the scheduled time. When unpaused, the date will be updated to the next date and time that the assay will be run.
(F) Aggregation Type: The aggregation type used with the assay.
(G) Threshold: The threshold value used for the assay.
(H) Metric: The metric type used for the assay.
(I) Number of Bins: The number of bins used for the assay.
(J) Bin Weight: The weight applied to each bin.
(K) Bin Mode: The type of bin node applied to each bin.
View Assay Alert Details
To view details on an assay alert:
Select the data with available alert data.
Mouse hover of a specific Assay Event Alert to view the data and time of the event and the alert value.
Select the Assay Event Alert to view the Baseline and Window details of the alert including the left_outlier and right_outlier.
Hover over a bar chart graph to view additional details.
Select the ⊗ symbol to exit the Assay Event Alert details and return to the Assay View.
Build an Assay Through the Pipeline Dashboard
To create a new assay through the Wallaroo Pipeline Dashboard:
Log into the Wallaroo Dashboard.
Select the workspace containing the pipeline with the models being monitored from the Change Current Workspace and Workspace Management drop down.
Select View Pipelines.
Select the pipeline containing the models being monitored.
Select Insights.
Select +Create Assay.
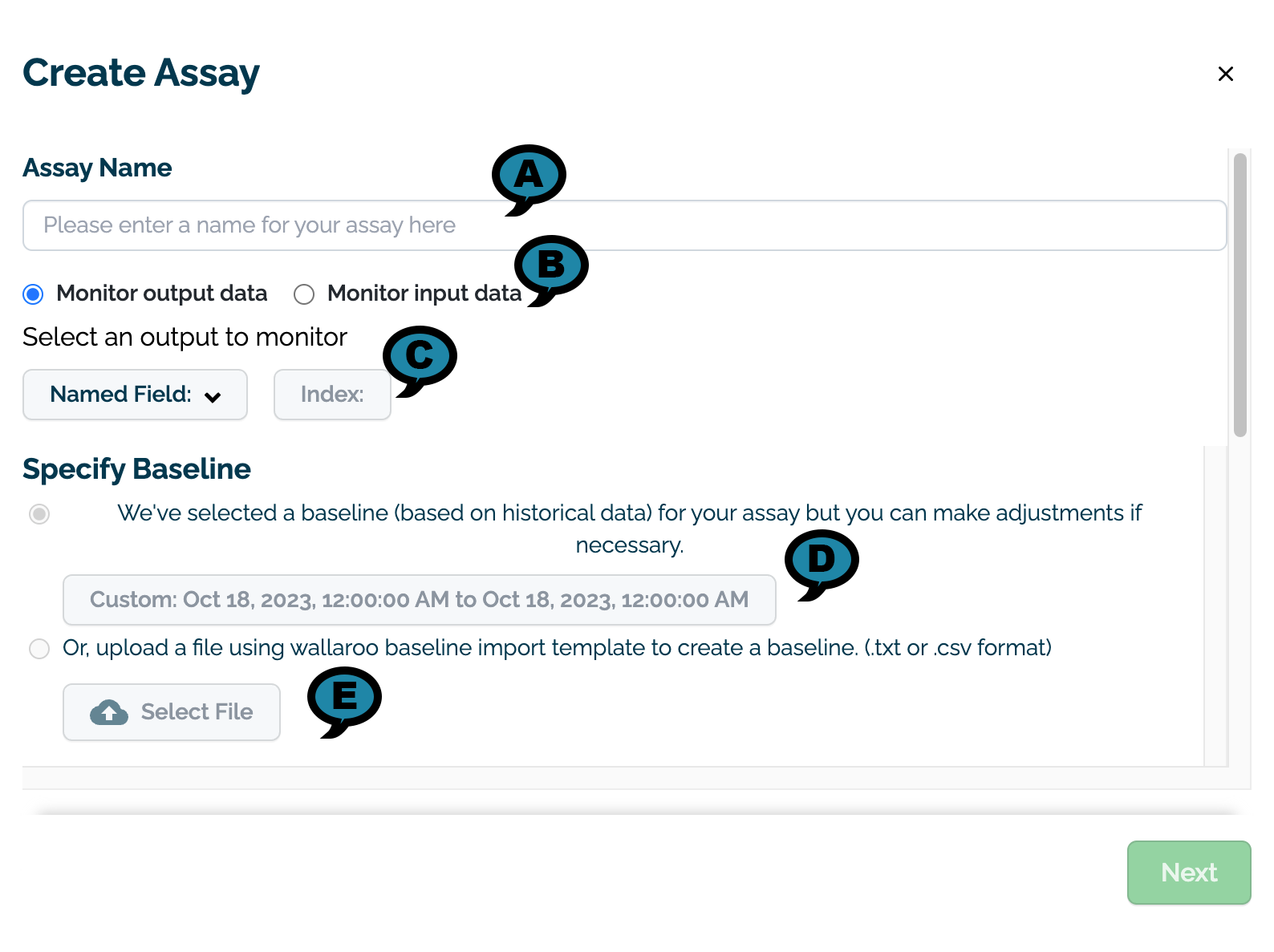
On the Create Assay module, enter the following:
On the Assay Name section, enter the following:
Assay Name(A): The name of the new assay.
Monitor output data or Monitor input data(B): Select whether to monitor input or output data.
Select an output/input to monitor(C): Select the input or output to monitor.
Named Field: The name of the field to monitor.
Index: The index of the monitored field.
On the Specify Baseline section, select one of the following options:
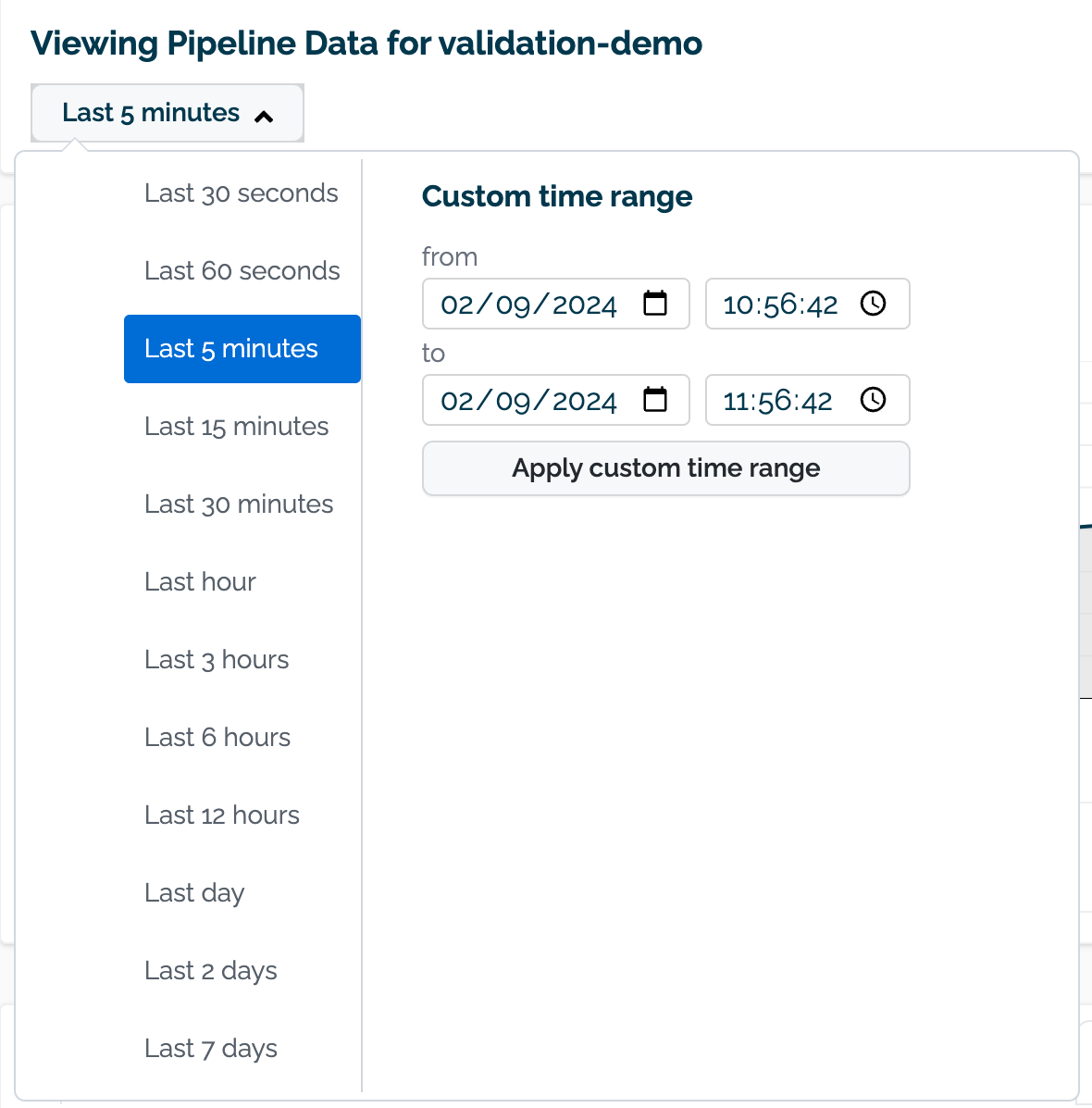
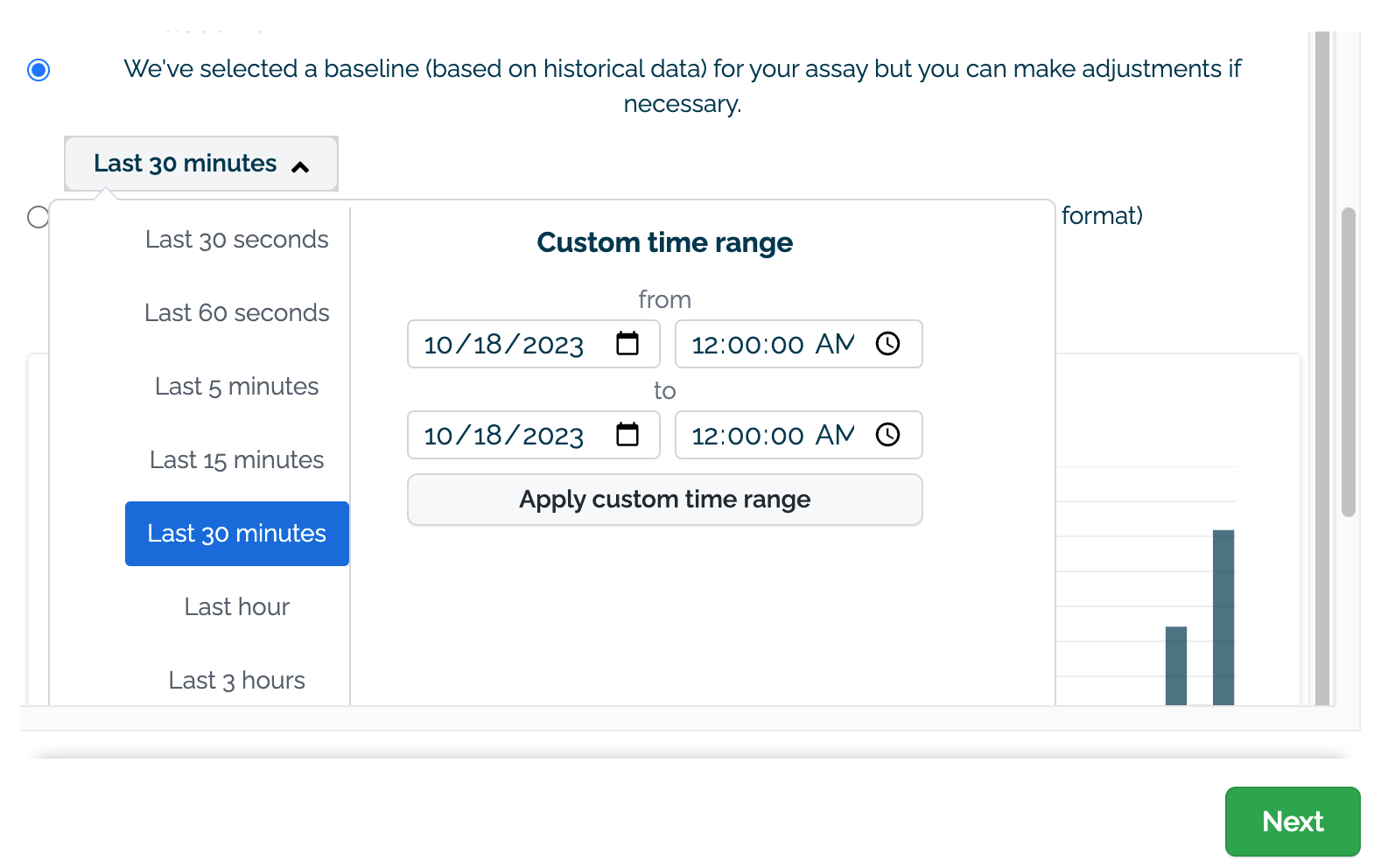
(D) Select the data to use for the baseline. This can either be set with a preset recent time period (last 30 seconds, last 60 seconds, etc) or with a custom date range.
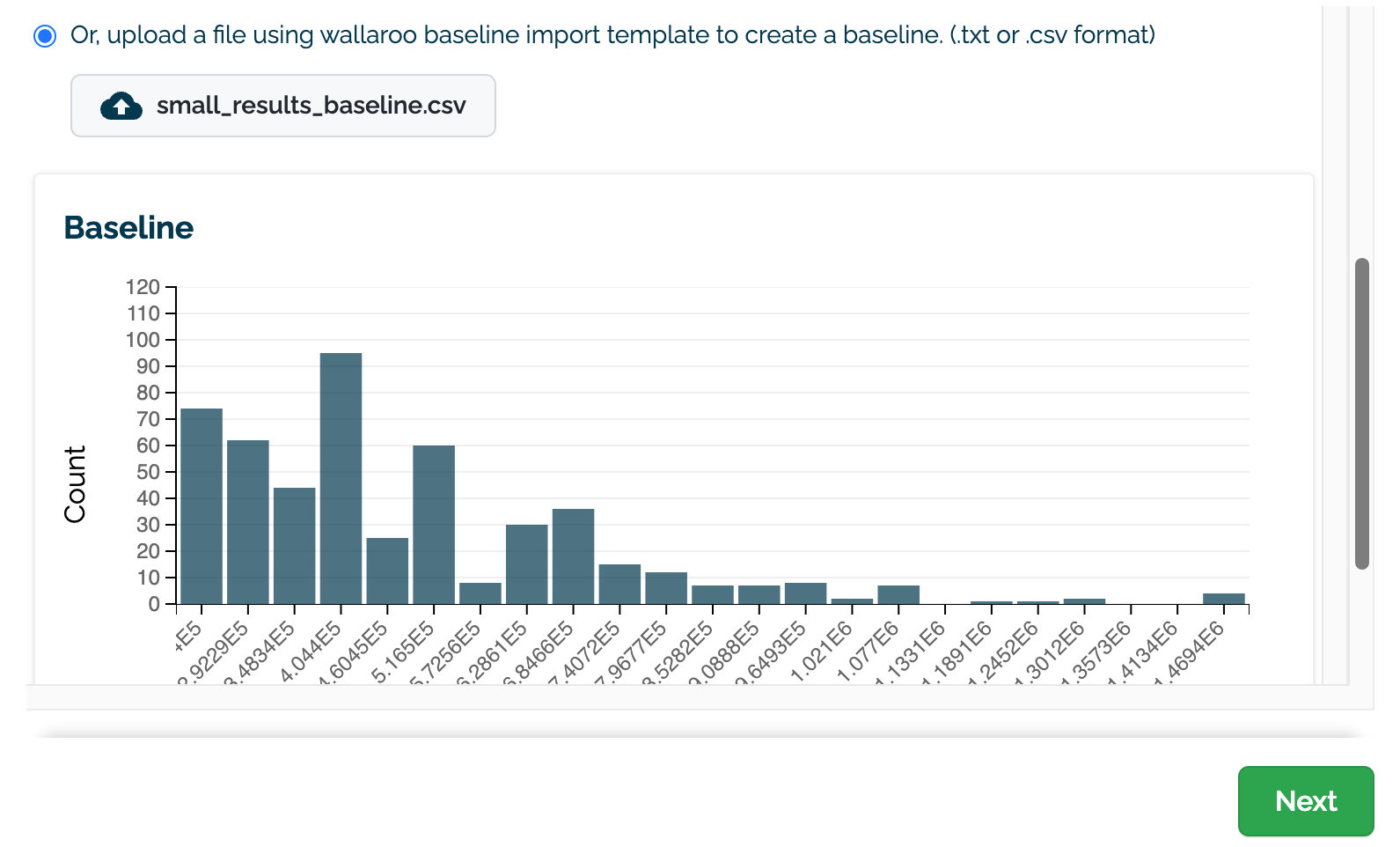
(E) Upload an assay baseline file as either a CSV or TXT file. These assay baselines must be a list of numpy (aka float) values that are comma and newline separated, terminating at the last record with no additional commas or returns.
Once selected, a preview graph of the baseline values will be displayed (C). Note that this may take a few seconds to generate.
Select Next to continue.
On the Settings Module:
Set the date and time range to view values generated by the assay. This can either be set with a preset recent time period (last 30 seconds, last 60 seconds, etc) or with a custom date range.
New assays are configured to run a new analysis for every 24 hours starting at the end of the baseline period. For information on how to adjust the scheduling period and other settings for the assay scheduling window, see the SDK section on how to Schedule Assay.
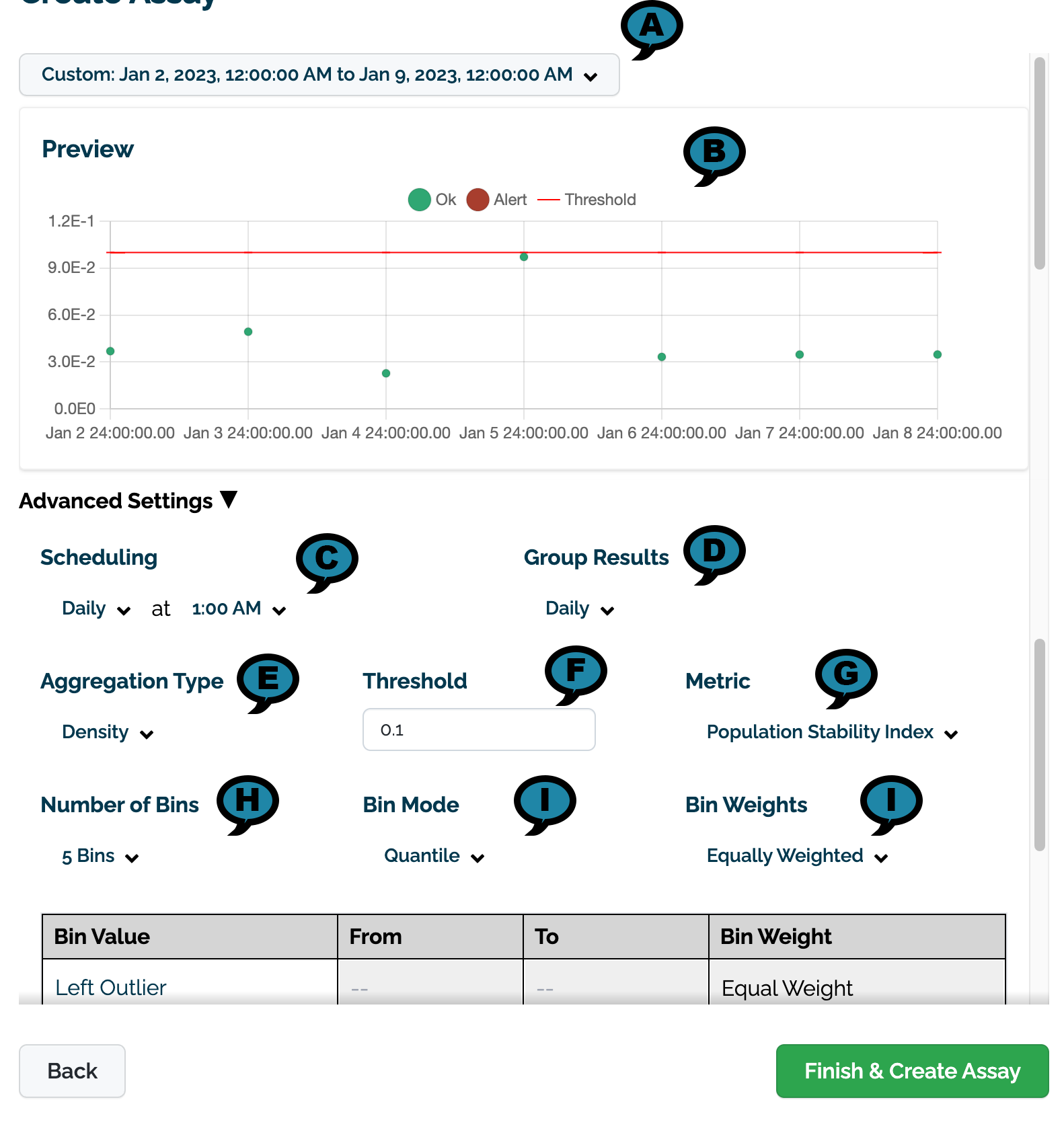
Set the following Advanced Settings.
(A) Preview Date Range: The date and times to for the preview chart.
(B) Preview: A preview of the assay results will be displayed based on the settings below.
(C) Scheduling: Set the Frequency (Daily, Every Minute, Hourly, Weekly, Default: Daily) and the Time (increments of one hour Default: 1:00 AM).
(D) Group Results: How the results are grouped: Daily (Default), Every Minute, Weekly, or Monthly.
(E) Aggregation Type: Density or Cumulative.
(F) Threshold:
Default: 0.1
(G) Metric:
Default: Population Stability Index
Maximum Difference of Bins
Sum of the Difference of Bins
(H) Number of Bins: From 5 to 14. Default: 5
(F) Bin Mode:
Equally Spaced
Default: Quantile
(I) Bin Weights: The bin weights:
Equally Weighted (Default)
Custom: Users can assign their own bin weights as required.
Review the preview chart to verify the settings are correct.
Select Build to complete the process and build the new assay.
Once created, it may take a few minutes for the assay to complete compiling data. If needed, reload the Pipeline Dashboard to view changes.
Model Insights via the Wallaroo Dashboard SDK
Assays generated through the Wallaroo SDK can be previewed, configured, and uploaded to the Wallaroo Ops instance. The following is a condensed version of this process. For full details see the Wallaroo SDK Essentials Guide: Assays Management guide.
Model drift detection with assays using the Wallaroo SDK follows this general process.
Define the Baseline: From either historical inference data for a specific model in a pipeline, or from a pre-determine array of data, a baseline is formed.
Assay Preview: Once the baseline is formed, we preview the assay and configure the different options until we have the the best method of detecting environment or model drift.
Create Assay: With the previews and configuration complete, we upload the assay. The assay will perform an analysis on a regular scheduled based on the configuration.
Get Assay Results: Retrieve the analyses and use them to detect model drift and possible sources.
Pause/Resume Assay: Pause or restart an assay as needed.
Define the Baseline
Assay baselines are defined with the wallaroo.client.build_assay method. Through this process we define the baseline from either a range of dates or pre-generated values.
wallaroo.client.build_assay take the following parameters:
Parameter
Type
Description
assay_name
String (Required) - required
The name of the assay. Assay names must be unique across the Wallaroo instance.
pipeline
wallaroo.pipeline.Pipeline (Required)
The pipeline the assay is monitoring.
model_name
String (Required)
The name of the model to monitor.
iopath
String (Required)
The input/output data for the model being tracked in the format input/output field index. Only one value is tracked for any assay. For example, to track the output of the model’s field house_value at index 0, the iopath is 'output house_value 0.
baseline_start
datetime.datetime (Optional)
The start time for the inferences to use as the baseline. Must be included with baseline_end. Cannot be included with baseline_data.
baseline_end
datetime.datetime (Optional)
The end time of the baseline window. the baseline. Windows start immediately after the baseline window and are run at regular intervals continuously until the assay is deactivated or deleted. Must be included with baseline_start. Cannot be included with baseline_data..
baseline_data
numpy.array (Optional)
The baseline data in numpy array format. Cannot be included with either baseline_start or baseline_data.
Baselines are created in one of two ways:
Date Range: The baseline_start and baseline_end retrieves the inference requests and results for the pipeline from the start and end period. This data is summarized and used to create the baseline.
Numpy Values: The baseline_data sets the baseline from a provided numpy array.
Define the Baseline Example
This example shows two methods of defining the baseline for an assay:
"assays from date baseline": This assay uses historical inference requests to define the baseline. This assay is saved to the variable assay_builder_from_dates.
"assays from numpy": This assay uses a pre-generated numpy array to define the baseline. This assay is saved to the variable assay_builder_from_numpy.
In both cases, the following parameters are used:
Parameter
Value
assay_name
"assays from date baseline" and "assays from numpy"
pipeline
mainpipeline: A pipeline with a ML model that predicts house prices. The output field for this model is variable.
model_name
"houseprice-predictor" - the model name set during model upload.
iopath
These assays monitor the model’s output field variable at index 0. From this, the iopath setting is "output variable 0".
The difference between the two assays’ parameters determines how the baseline is generated.
"assays from date baseline": Uses the baseline_start and baseline_end to set the time period of inference requests and results to gather data from.
"assays from numpy": Uses a pre-generated numpy array as for the baseline data.
For each of our assays, we will set the time period of inference data to compare against the baseline data.
# Build the assay, based on the start and end of our baseline time, # and tracking the output variable index 0assay_builder_from_dates=wl.build_assay(assay_name="assays from date baseline",
pipeline=mainpipeline,
model_name="house-price-estimator",
iopath="output variable 0",
baseline_start=assay_baseline_start,
baseline_end=assay_baseline_end)
# set the width, interval, and time period assay_builder_from_dates.add_run_until(datetime.datetime.now())
assay_builder_from_dates.window_builder().add_width(minutes=1).add_interval(minutes=1).add_start(assay_window_start)
assay_config_from_dates=assay_builder_from_dates.build()
assay_results_from_dates=assay_config_from_dates.interactive_run()
# assay builder by baselineassay_builder_from_numpy=wl.build_assay(assay_name="assays from numpy",
pipeline=mainpipeline,
model_name="house-price-estimator",
iopath="output variable 0",
baseline_data=small_results_baseline)
# set the width, interval, and time period assay_builder_from_numpy.add_run_until(datetime.datetime.now())
assay_builder_from_numpy.window_builder().add_width(minutes=1).add_interval(minutes=1).add_start(assay_window_start)
assay_config_from_numpy=assay_builder_from_numpy.build()
assay_results_from_numpy=assay_config_from_numpy.interactive_run()
Now that the baseline is defined, we look at different configuration options and view how the assay baseline and results changes. Once we determine what gives us the best method of determining model drift, we can create the assay.
Analysis List Chart Scores
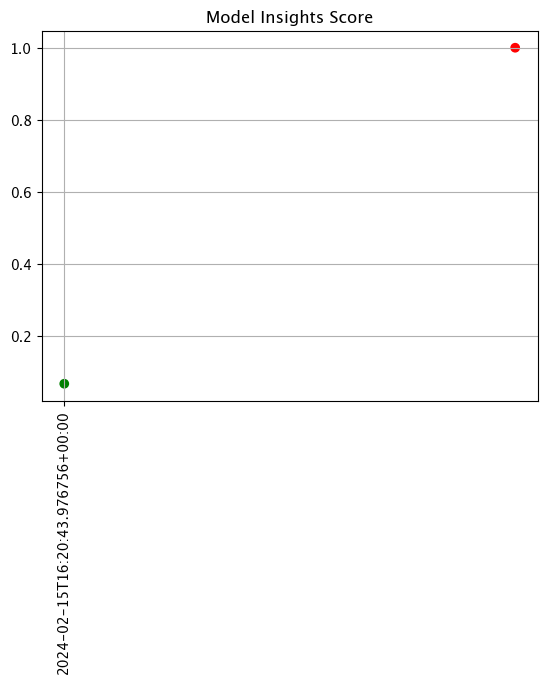
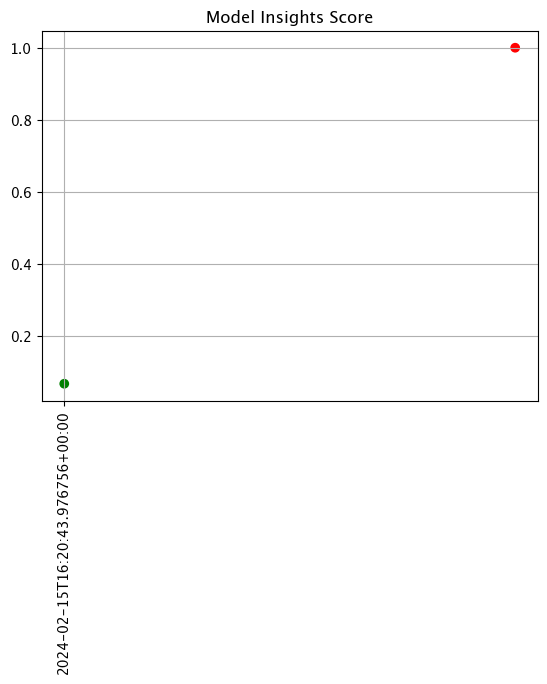
Analysis List scores show the assay scores for each assay result interval in one chart. Values that are outside of the alert threshold are colored red, while scores within the alert threshold are green.
The following example shows retrieving the assay results and displaying the chart scores. From our example, we have two windows - the first should be green, and the second is red showing that values were outside the alert threshold.
# Build the assay, based on the start and end of our baseline time, # and tracking the output variable index 0assay_builder_from_dates=wl.build_assay(assay_name="assays from date baseline",
pipeline=mainpipeline,
model_name="house-price-estimator",
iopath="output variable 0",
baseline_start=assay_baseline_start,
baseline_end=assay_baseline_end)
# set the width, interval, and time period assay_builder_from_dates.add_run_until(datetime.datetime.now())
assay_builder_from_dates.window_builder().add_width(minutes=1).add_interval(minutes=1).add_start(assay_window_start)
assay_config_from_dates=assay_builder_from_dates.build()
assay_results_from_dates=assay_config_from_dates.interactive_run()
assay_results_from_dates.chart_scores()
Analysis Chart
The method wallaroo.assay.AssayAnalysis.chart() displays a comparison between the baseline and an interval of inference data.
This is compared to the Chart Scores, which is a list of all of the inference data split into intervals, while the Analysis Chart shows the breakdown of one set of inference data against the baseline.
The window index. Interactive assay runs are None.
# Build the assay, based on the start and end of our baseline time, # and tracking the output variable index 0assay_builder_from_dates=wl.build_assay(assay_name="assays from date baseline",
pipeline=mainpipeline,
model_name="house-price-estimator",
iopath="output variable 0",
baseline_start=assay_baseline_start,
baseline_end=assay_baseline_end)
# set the width, interval, and time period assay_builder_from_dates.add_run_until(datetime.datetime.now())
assay_builder_from_dates.window_builder().add_width(minutes=1).add_interval(minutes=1).add_start(assay_window_start)
assay_config_from_dates=assay_builder_from_dates.build()
assay_results_from_dates=assay_config_from_dates.interactive_run()
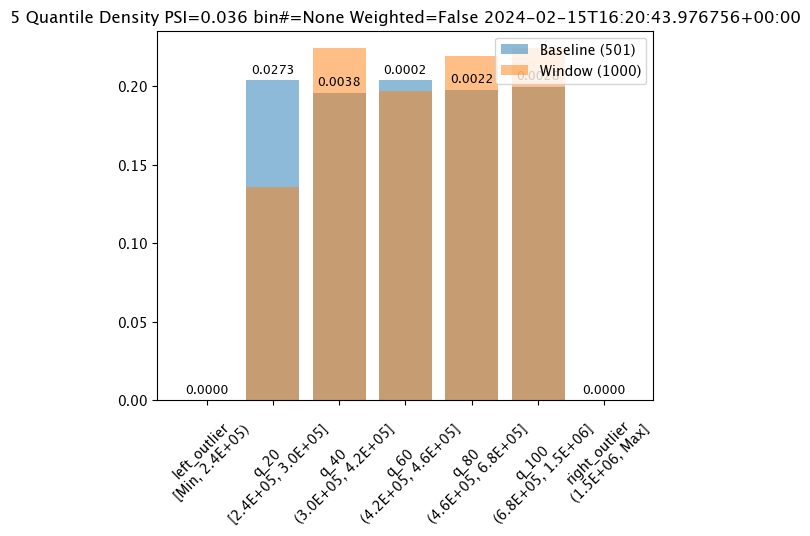
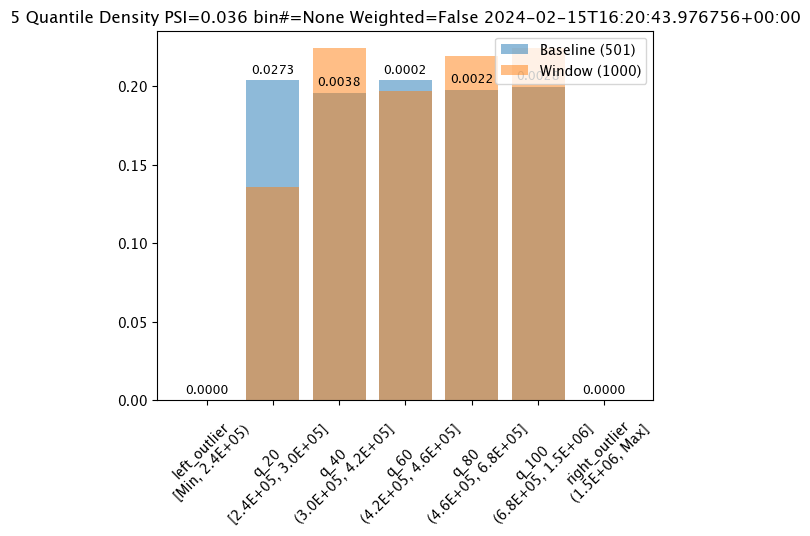
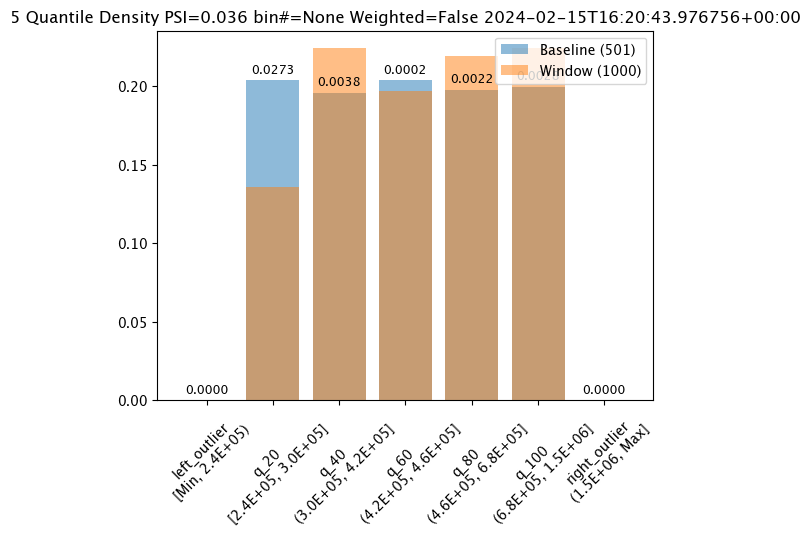
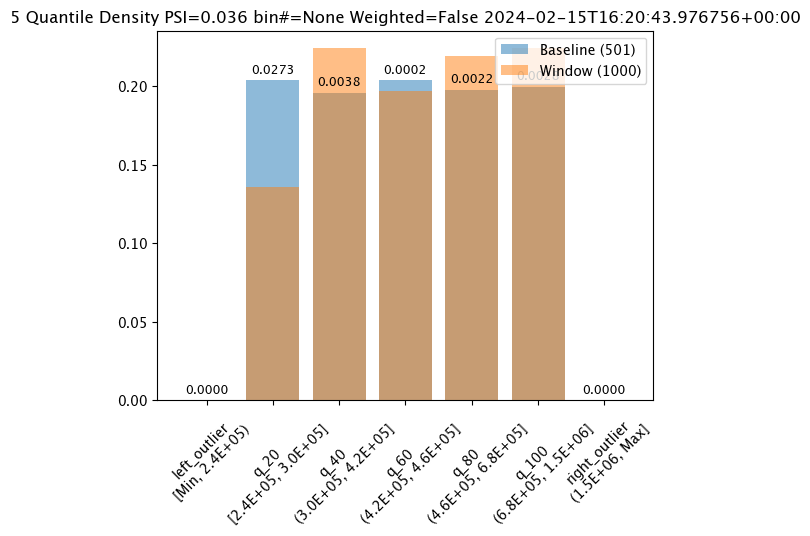
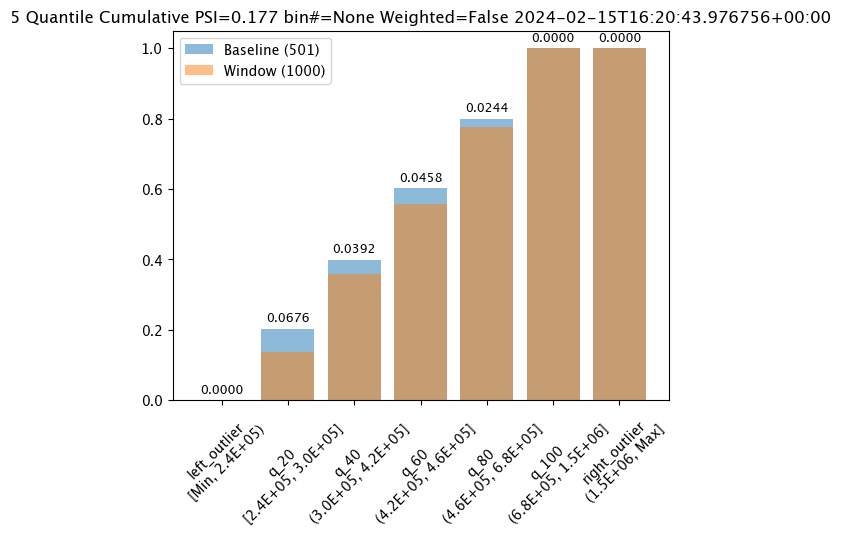
assay_results_from_dates[0].chart()
baseline mean = 495193.23178642715
window mean = 517763.394625
baseline median = 442168.125
window median = 448627.8125
bin_mode = Quantile
aggregation = Density
metric = PSI
weighted = False
score = 0.0363497101644573
scores = [0.0, 0.027271477163285655, 0.003847844548034077, 0.000217023993714693, 0.002199485350158766, 0.0028138791092641195, 0.0]
index = None
Analysis List DataFrame
wallaroo.assay.AssayAnalysisList.to_dataframe() returns a DataFrame showing the assay results for each window aka individual analysis. This DataFrame contains the following fields:
Field
Type
Description
assay_id
Integer/None
The assay id. Only provided from uploaded and executed assays.
name
String/None
The name of the assay. Only provided from uploaded and executed assays.
iopath
String/None
The iopath of the assay. Only provided from uploaded and executed assays.
score
Float
The assay score.
start
DateTime
The DateTime start of the assay window.
min
Float
The minimum value in the assay window.
max
Float
The maximum value in the assay window.
mean
Float
The mean value in the assay window.
median
Float
The median value in the assay window.
std
Float
The standard deviation value in the assay window.
warning_threshold
Float/None
The warning threshold of the assay window.
alert_threshold
Float/None
The alert threshold of the assay window.
status
String
The assay window status. Values are:
OK: The score is within accepted thresholds.
Warning: The score has triggered the warning_threshold if exists, but not the alert_threshold.
Alert: The score has triggered the the alert_threshold.
For this example, the assay analysis list DataFrame is listed.
From this tutorial, we should have 2 windows of dta to look at, each one minute apart. The first window should show status: OK, with the second window with the very large house prices will show status: alert
# Build the assay, based on the start and end of our baseline time, # and tracking the output variable index 0assay_builder_from_dates=wl.build_assay(assay_name="assays from date baseline",
pipeline=mainpipeline,
model_name="house-price-estimator",
iopath="output variable 0",
baseline_start=assay_baseline_start,
baseline_end=assay_baseline_end)
# set the width, interval, and time period assay_builder_from_dates.add_run_until(datetime.datetime.now())
assay_builder_from_dates.window_builder().add_width(minutes=1).add_interval(minutes=1).add_start(assay_window_start)
assay_config_from_dates=assay_builder_from_dates.build()
assay_results_from_dates=assay_config_from_dates.interactive_run()
assay_results_from_dates.to_dataframe()
assay_id
name
iopath
score
start
min
max
mean
median
std
warning_threshold
alert_threshold
status
0
None
0.036350
2024-02-15T16:20:43.976756+00:00
2.362387e+05
1489624.250
5.177634e+05
4.486278e+05
227729.030050
None
0.25
Ok
1
None
8.868614
2024-02-15T16:22:43.976756+00:00
1.514079e+06
2016006.125
1.885772e+06
1.946438e+06
160046.727324
None
0.25
Alert
Analysis List Full DataFrame
wallaroo.assay.AssayAnalysisList.to_full_dataframe() returns a DataFrame showing all values, including the inputs and outputs from the assay results for each window aka individual analysis. This DataFrame contains the following fields:
If baseline bin weights were provided, the list of those weights. Otherwise, None.
summarizer_provided_edges
List / None
If baseline bin edges were provided, the list of those edges. Otherwise, None.
status
String
The assay window status. Values are:
OK: The score is within accepted thresholds.
Warning: The score has triggered the warning_threshold if exists, but not the alert_threshold.
Alert: The score has triggered the the alert_threshold.
id
Integer/None
The id for the window aka analysis. Only provided from uploaded and executed assays.
assay_id
Integer/None
The assay id. Only provided from uploaded and executed assays.
pipeline_id
Integer/None
The pipeline id. Only provided from uploaded and executed assays.
warning_threshold
Float
The warning threshold set for the assay.
warning_threshold
Float
The warning threshold set for the assay.
bin_index
Integer/None
The bin index for the window aka analysis.
created_at
Datetime/None
The date and time the window aka analysis was generated. Only provided from uploaded and executed assays.
For this example, full DataFrame from an assay preview is generated.
From this tutorial, we should have 2 windows of dta to look at, each one minute apart. The first window should show status: OK, with the second window with the very large house prices will show status: alert
# Build the assay, based on the start and end of our baseline time, # and tracking the output variable index 0assay_builder_from_dates=wl.build_assay(assay_name="assays from date baseline",
pipeline=mainpipeline,
model_name="house-price-estimator",
iopath="output variable 0",
baseline_start=assay_baseline_start,
baseline_end=assay_baseline_end)
# set the width, interval, and time period assay_builder_from_dates.add_run_until(datetime.datetime.now())
assay_builder_from_dates.window_builder().add_width(minutes=1).add_interval(minutes=1).add_start(assay_window_start)
assay_config_from_dates=assay_builder_from_dates.build()
assay_results_from_dates=assay_config_from_dates.interactive_run()
assay_results_from_dates.to_full_dataframe()
window_start
analyzed_at
elapsed_millis
baseline_summary_count
baseline_summary_min
baseline_summary_max
baseline_summary_mean
baseline_summary_median
baseline_summary_std
baseline_summary_edges_0
...
summarizer_type
summarizer_bin_weights
summarizer_provided_edges
status
id
assay_id
pipeline_id
warning_threshold
bin_index
created_at
0
2024-02-15T16:20:43.976756+00:00
2024-02-15T16:26:42.266029+00:00
82
501
236238.671875
1514079.375
495193.231786
442168.125
226075.814267
236238.671875
...
UnivariateContinuous
None
None
Ok
None
None
None
None
None
None
1
2024-02-15T16:22:43.976756+00:00
2024-02-15T16:26:42.266134+00:00
83
501
236238.671875
1514079.375
495193.231786
442168.125
226075.814267
236238.671875
...
UnivariateContinuous
None
None
Alert
None
None
None
None
None
None
2 rows × 86 columns
Analysis Compare Basic Stats
The method wallaroo.assay.AssayAnalysis.compare_basic_stats returns a DataFrame comparing one set of inference data against the baseline.
This is compared to the Analysis List DataFrame, which is a list of all of the inference data split into intervals, while the Analysis Compare Basic Stats shows the breakdown of one set of inference data against the baseline.
# Build the assay, based on the start and end of our baseline time, # and tracking the output variable index 0assay_builder_from_dates=wl.build_assay(assay_name="assays from date baseline",
pipeline=mainpipeline,
model_name="house-price-estimator",
iopath="output variable 0",
baseline_start=assay_baseline_start,
baseline_end=assay_baseline_end)
# set the width, interval, and time period assay_builder_from_dates.add_run_until(datetime.datetime.now())
assay_builder_from_dates.window_builder().add_width(minutes=1).add_interval(minutes=1).add_start(assay_window_start)
assay_config_from_dates=assay_builder_from_dates.build()
assay_results_from_dates=assay_config_from_dates.interactive_run()
assay_results_from_dates[0].compare_basic_stats()
Baseline
Window
diff
pct_diff
count
501.0
1000.0
499.000000
99.600798
min
236238.671875
236238.671875
0.000000
0.000000
max
1514079.375
1489624.25
-24455.125000
-1.615181
mean
495193.231786
517763.394625
22570.162839
4.557850
median
442168.125
448627.8125
6459.687500
1.460912
std
226075.814267
227729.03005
1653.215783
0.731266
start
None
2024-02-15T16:20:43.976756+00:00
NaN
NaN
end
None
2024-02-15T16:21:43.976756+00:00
NaN
NaN
Configure Assays
Before creating the assay, configure the assay and continue to preview it until the best method for detecting drift is set. The following options are available.
Score Metric
The score is a distance between the baseline and the analysis window. The larger the score, the greater the difference between the baseline and the analysis window. The following methods are provided determining the score:
PSI (Default) - Population Stability Index (PSI).
MAXDIFF: Maximum difference between corresponding bins.
SUMDIFF: Mum of differences between corresponding bins.
The following three charts use each of the metrics. Note how the scores change based on the score type used.
# Build the assay, based on the start and end of our baseline time, # and tracking the output variable index 0assay_builder_from_dates=wl.build_assay(assay_name="assays from date baseline",
pipeline=mainpipeline,
model_name="house-price-estimator",
iopath="output variable 0",
baseline_start=assay_baseline_start,
baseline_end=assay_baseline_end)
# set metric PSI modeassay_builder_from_dates.summarizer_builder.add_metric(wallaroo.assay_config.Metric.PSI)
# set the width, interval, and time period assay_builder_from_dates.add_run_until(datetime.datetime.now())
assay_builder_from_dates.window_builder().add_width(minutes=1).add_interval(minutes=1).add_start(assay_window_start)
assay_config_from_dates=assay_builder_from_dates.build()
assay_results_from_dates=assay_config_from_dates.interactive_run()
assay_results_from_dates[0].chart()
baseline mean = 495193.23178642715
window mean = 517763.394625
baseline median = 442168.125
window median = 448627.8125
bin_mode = Quantile
aggregation = Density
metric = PSI
weighted = False
score = 0.0363497101644573
scores = [0.0, 0.027271477163285655, 0.003847844548034077, 0.000217023993714693, 0.002199485350158766, 0.0028138791092641195, 0.0]
index = None
# Build the assay, based on the start and end of our baseline time, # and tracking the output variable index 0assay_builder_from_dates=wl.build_assay(assay_name="assays from date baseline",
pipeline=mainpipeline,
model_name="house-price-estimator",
iopath="output variable 0",
baseline_start=assay_baseline_start,
baseline_end=assay_baseline_end)
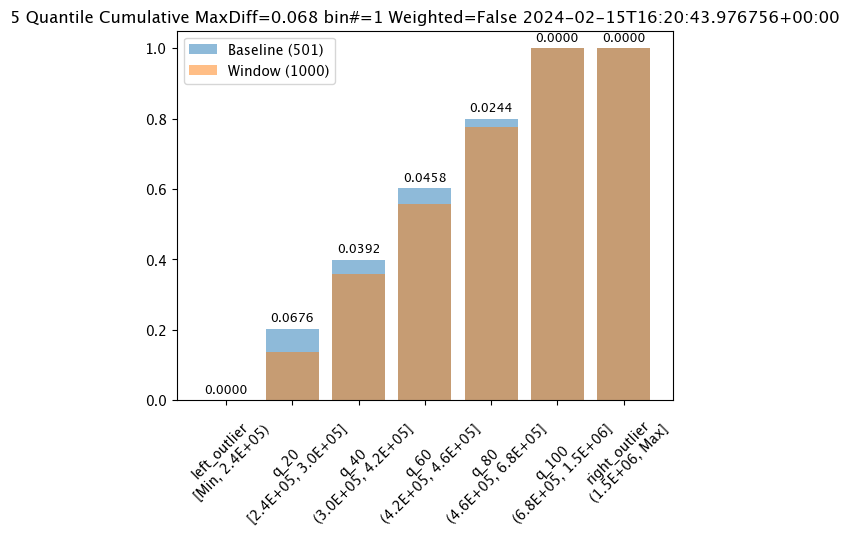
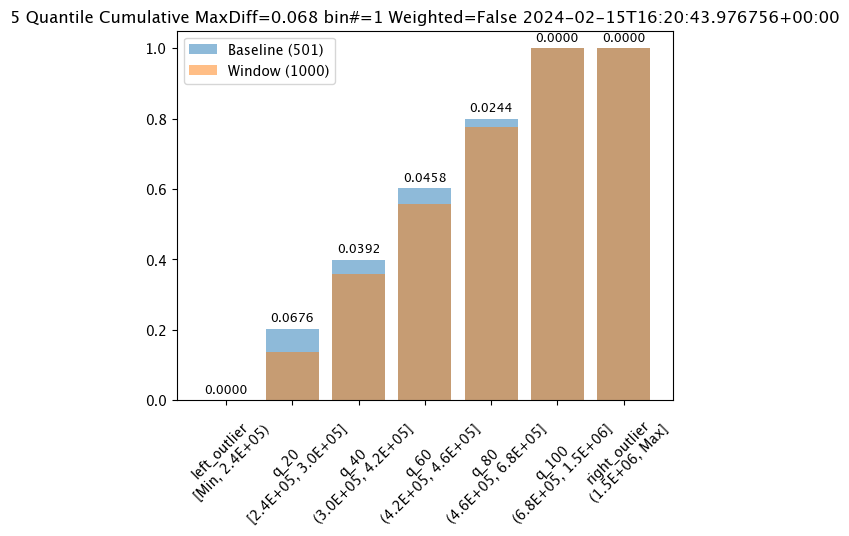
# set metric MAXDIFF modeassay_builder_from_dates.summarizer_builder.add_metric(wallaroo.assay_config.Metric.MAXDIFF)
# set the width, interval, and time period assay_builder_from_dates.add_run_until(datetime.datetime.now())
assay_builder_from_dates.window_builder().add_width(minutes=1).add_interval(minutes=1).add_start(assay_window_start)
assay_config_from_dates=assay_builder_from_dates.build()
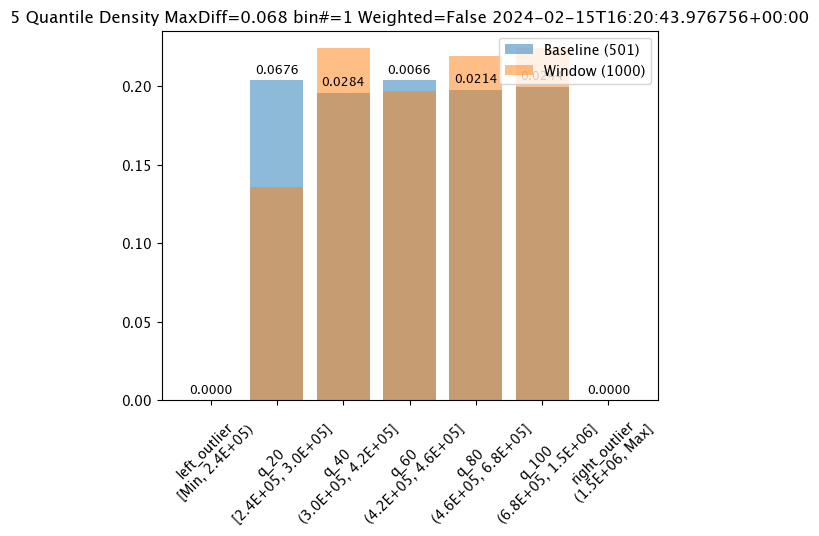
assay_results_from_dates=assay_config_from_dates.interactive_run()
assay_results_from_dates[0].chart()
baseline mean = 495193.23178642715
window mean = 517763.394625
baseline median = 442168.125
window median = 448627.8125
bin_mode = Quantile
aggregation = Density
metric = MaxDiff
weighted = False
score = 0.06759281437125747
scores = [0.0, 0.06759281437125747, 0.028391217564870255, 0.006592814371257472, 0.02139520958083832, 0.02439920159680639, 0.0]
index = 1
# Build the assay, based on the start and end of our baseline time, # and tracking the output variable index 0assay_builder_from_dates=wl.build_assay(assay_name="assays from date baseline",
pipeline=mainpipeline,
model_name="house-price-estimator",
iopath="output variable 0",
baseline_start=assay_baseline_start,
baseline_end=assay_baseline_end)
# set metric SUMDIFF modeassay_builder_from_dates.summarizer_builder.add_metric(wallaroo.assay_config.Metric.SUMDIFF)
# set the width, interval, and time period assay_builder_from_dates.add_run_until(datetime.datetime.now())
assay_builder_from_dates.window_builder().add_width(minutes=1).add_interval(minutes=1).add_start(assay_window_start)
assay_config_from_dates=assay_builder_from_dates.build()
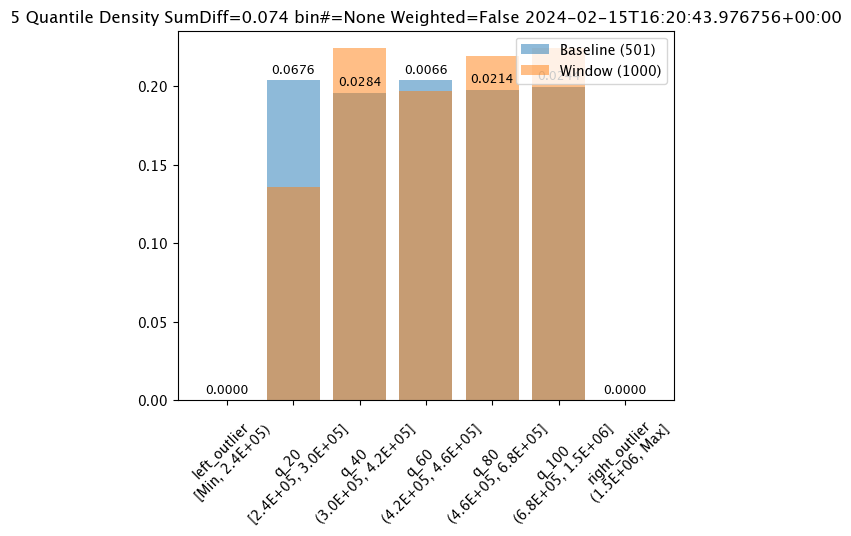
assay_results_from_dates=assay_config_from_dates.interactive_run()
assay_results_from_dates[0].chart()
baseline mean = 495193.23178642715
window mean = 517763.394625
baseline median = 442168.125
window median = 448627.8125
bin_mode = Quantile
aggregation = Density
metric = SumDiff
weighted = False
score = 0.07418562874251496
scores = [0.0, 0.06759281437125747, 0.028391217564870255, 0.006592814371257472, 0.02139520958083832, 0.02439920159680639, 0.0]
index = None
The following example updates the alert threshold to 0.5.
# Build the assay, based on the start and end of our baseline time, # and tracking the output variable index 0assay_builder_from_dates=wl.build_assay(assay_name="assays from date baseline",
pipeline=mainpipeline,
model_name="house-price-estimator",
iopath="output variable 0",
baseline_start=assay_baseline_start,
baseline_end=assay_baseline_end)
assay_builder_from_dates.add_alert_threshold(0.5)
# set the width, interval, and time period assay_builder_from_dates.add_run_until(datetime.datetime.now())
assay_builder_from_dates.window_builder().add_width(minutes=1).add_interval(minutes=1).add_start(assay_window_start)
assay_config_from_dates=assay_builder_from_dates.build()
assay_results_from_dates=assay_config_from_dates.interactive_run()
assay_results_from_dates.to_dataframe()
assay_id
name
iopath
score
start
min
max
mean
median
std
warning_threshold
alert_threshold
status
0
None
0.036350
2024-02-15T16:20:43.976756+00:00
2.362387e+05
1489624.250
5.177634e+05
4.486278e+05
227729.030050
None
0.5
Ok
1
None
8.868614
2024-02-15T16:22:43.976756+00:00
1.514079e+06
2016006.125
1.885772e+06
1.946438e+06
160046.727324
None
0.5
Alert
Number of Bins
Number of bins sets how the baseline data is partitioned. The total number of bins includes the set number plus the left_outlier and the right_outlier, so the total number of bins will be the total set + 2.
# Build the assay, based on the start and end of our baseline time, # and tracking the output variable index 0assay_builder_from_dates=wl.build_assay(assay_name="assays from date baseline",
pipeline=mainpipeline,
model_name="house-price-estimator",
iopath="output variable 0",
baseline_start=assay_baseline_start,
baseline_end=assay_baseline_end)
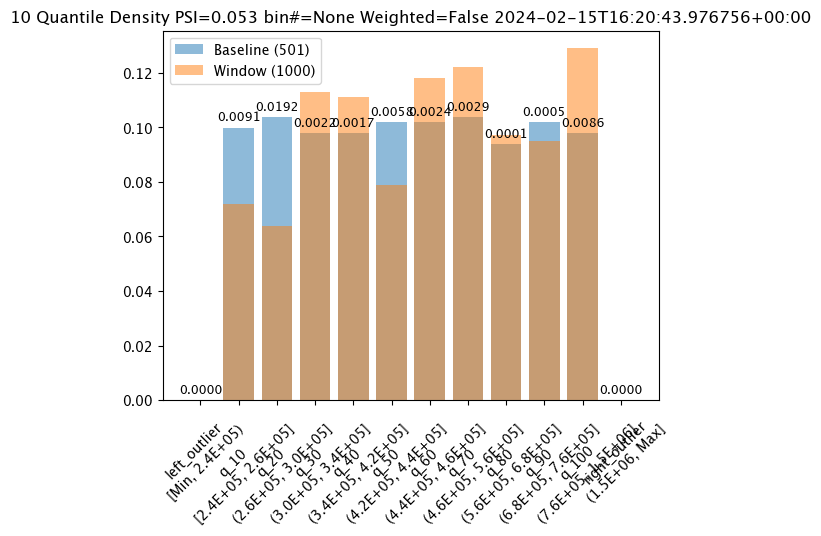
# Set the number of bins# update number of bins hereassay_builder_from_dates.summarizer_builder.add_num_bins(10)
# set the width, interval, and time period assay_builder_from_dates.add_run_until(datetime.datetime.now())
assay_builder_from_dates.window_builder().add_width(minutes=1).add_interval(minutes=1).add_start(assay_window_start)
assay_config_from_dates=assay_builder_from_dates.build()
assay_results_from_dates=assay_config_from_dates.interactive_run()
assay_results_from_dates[0].chart()
baseline mean = 495193.23178642715
window mean = 517763.394625
baseline median = 442168.125
window median = 448627.8125
bin_mode = Quantile
aggregation = Density
metric = PSI
weighted = False
score = 0.05250979748389363
scores = [0.0, 0.009076998929542533, 0.01924002322223739, 0.0021945246367443406, 0.0016700458183385653, 0.005779503770625584, 0.002393429678215835, 0.002942858220315506, 0.00010651192741915124, 0.00046961759334670583, 0.008636283687108028, 0.0]
index = None
Binning Mode
Binning Mode defines how the bins are separated. Binning modes are modified through the wallaroo.assay_config.UnivariateContinousSummarizerBuilder.add_bin_mode(bin_mode: bin_mode: wallaroo.assay_config.BinMode, edges: Optional[List[float]] = None).
Available bin_mode values from wallaroo.assay_config.Binmode are the following:
QUANTILE (Default): Based on percentages. If num_bins is 5 then quintiles so bins are created at the 20%, 40%, 60%, 80% and 100% points.
EQUAL: Evenly spaced bins where each bin is set with the formula min - max / num_bins
PROVIDED: The user provides the edge points for the bins.
If PROVIDED is supplied, then a List of float values must be provided for the edges parameter that matches the number of bins.
The following examples are used to show how each of the binning modes effects the bins.
# Build the assay, based on the start and end of our baseline time, # and tracking the output variable index 0assay_builder_from_dates=wl.build_assay(assay_name="assays from date baseline",
pipeline=mainpipeline,
model_name="house-price-estimator",
iopath="output variable 0",
baseline_start=assay_baseline_start,
baseline_end=assay_baseline_end)
# update binning mode hereassay_builder_from_dates.summarizer_builder.add_bin_mode(wallaroo.assay_config.BinMode.QUANTILE)
# set the width, interval, and time period assay_builder_from_dates.add_run_until(datetime.datetime.now())
assay_builder_from_dates.window_builder().add_width(minutes=1).add_interval(minutes=1).add_start(assay_window_start)
assay_config_from_dates=assay_builder_from_dates.build()
assay_results_from_dates=assay_config_from_dates.interactive_run()
assay_results_from_dates[0].chart()
baseline mean = 495193.23178642715
window mean = 517763.394625
baseline median = 442168.125
window median = 448627.8125
bin_mode = Quantile
aggregation = Density
metric = PSI
weighted = False
score = 0.0363497101644573
scores = [0.0, 0.027271477163285655, 0.003847844548034077, 0.000217023993714693, 0.002199485350158766, 0.0028138791092641195, 0.0]
index = None
# Build the assay, based on the start and end of our baseline time, # and tracking the output variable index 0assay_builder_from_dates=wl.build_assay(assay_name="assays from date baseline",
pipeline=mainpipeline,
model_name="house-price-estimator",
iopath="output variable 0",
baseline_start=assay_baseline_start,
baseline_end=assay_baseline_end)
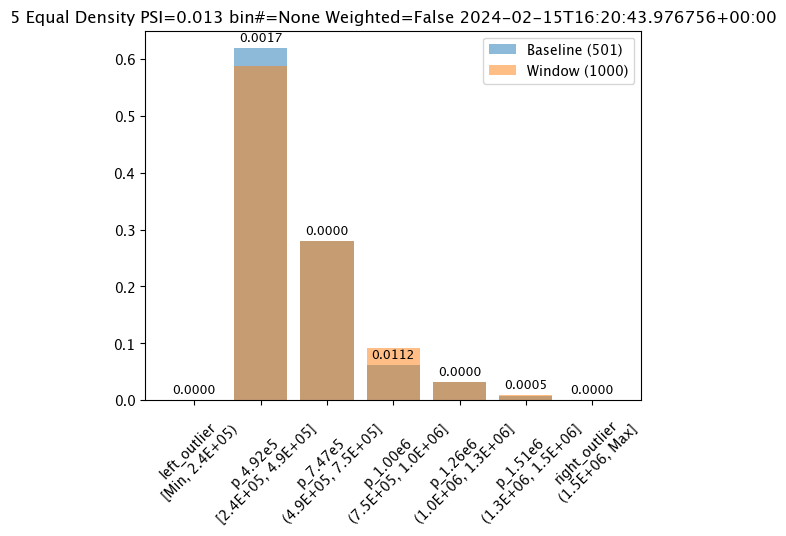
# update binning mode hereassay_builder_from_dates.summarizer_builder.add_bin_mode(wallaroo.assay_config.BinMode.EQUAL)
# set the width, interval, and time period assay_builder_from_dates.add_run_until(datetime.datetime.now())
assay_builder_from_dates.window_builder().add_width(minutes=1).add_interval(minutes=1).add_start(assay_window_start)
assay_config_from_dates=assay_builder_from_dates.build()
assay_results_from_dates=assay_config_from_dates.interactive_run()
assay_results_from_dates[0].chart()
baseline mean = 495193.23178642715
window mean = 517763.394625
baseline median = 442168.125
window median = 448627.8125
bin_mode = Equal
aggregation = Density
metric = PSI
weighted = False
score = 0.013362603453760629
scores = [0.0, 0.0016737762070682225, 1.1166481947075492e-06, 0.011233704798893194, 1.276169365380064e-07, 0.00045387818266796784, 0.0]
index = None
The following example manually sets the bin values.
The values in this dataset run from 200000 to 1500000. We can specify the bins with the BinMode.PROVIDED and specifying a list of floats with the right hand / upper edge of each bin and optionally the lower edge of the smallest bin. If the lowest edge is not specified the threshold for left outliers is taken from the smallest value in the baseline dataset.
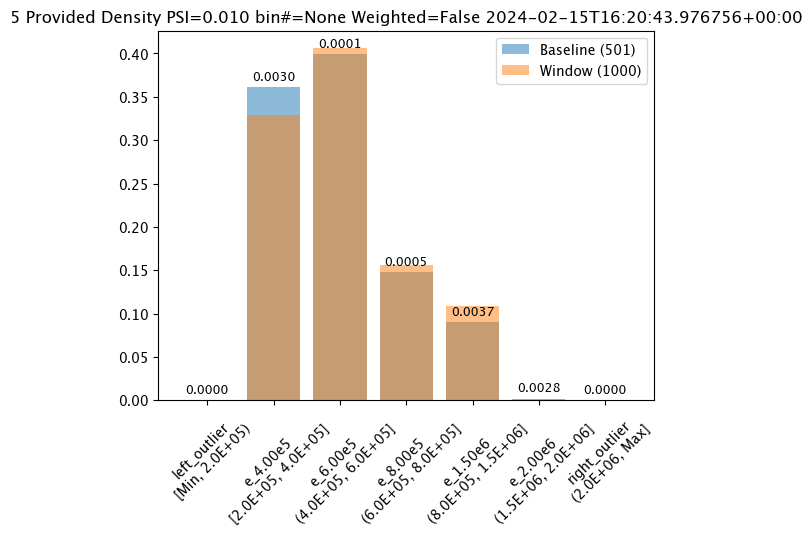
# Build the assay, based on the start and end of our baseline time, # and tracking the output variable index 0assay_builder_from_dates=wl.build_assay(assay_name="assays from date baseline",
pipeline=mainpipeline,
model_name="house-price-estimator",
iopath="output variable 0",
baseline_start=assay_baseline_start,
baseline_end=assay_baseline_end)
edges= [200000.0, 400000.0, 600000.0, 800000.0, 1500000.0, 2000000.0]
# update binning mode hereassay_builder_from_dates.summarizer_builder.add_bin_mode(wallaroo.assay_config.BinMode.PROVIDED, edges)
# set the width, interval, and time period assay_builder_from_dates.add_run_until(datetime.datetime.now())
assay_builder_from_dates.window_builder().add_width(minutes=1).add_interval(minutes=1).add_start(assay_window_start)
assay_config_from_dates=assay_builder_from_dates.build()
assay_results_from_dates=assay_config_from_dates.interactive_run()
assay_results_from_dates[0].chart()
baseline mean = 495193.23178642715
window mean = 517763.394625
baseline median = 442168.125
window median = 448627.8125
bin_mode = Provided
aggregation = Density
metric = PSI
weighted = False
score = 0.01005936099521711
scores = [0.0, 0.0030207963288415803, 0.00011480201840874194, 0.00045327555974347976, 0.0037119550613212583, 0.0027585320269020493, 0.0]
index = None
Aggregation.DENSITY (Default): Count the number/percentage of values that fall in each bin.
Aggregation.CUMULATIVE: Empirical Cumulative Density Function style, which keeps a cumulative count of the values/percentages that fall in each bin.
The following example demonstrate the different results between the two.
#Aggregation.DENSITY - the default# Build the assay, based on the start and end of our baseline time, # and tracking the output variable index 0assay_builder_from_dates=wl.build_assay(assay_name="assays from date baseline",
pipeline=mainpipeline,
model_name="house-price-estimator",
iopath="output variable 0",
baseline_start=assay_baseline_start,
baseline_end=assay_baseline_end)
assay_builder_from_dates.summarizer_builder.add_aggregation(wallaroo.assay_config.Aggregation.DENSITY)
# set the width, interval, and time period assay_builder_from_dates.add_run_until(datetime.datetime.now())
assay_builder_from_dates.window_builder().add_width(minutes=1).add_interval(minutes=1).add_start(assay_window_start)
assay_config_from_dates=assay_builder_from_dates.build()
assay_results_from_dates=assay_config_from_dates.interactive_run()
assay_results_from_dates[0].chart()
baseline mean = 495193.23178642715
window mean = 517763.394625
baseline median = 442168.125
window median = 448627.8125
bin_mode = Quantile
aggregation = Density
metric = PSI
weighted = False
score = 0.0363497101644573
scores = [0.0, 0.027271477163285655, 0.003847844548034077, 0.000217023993714693, 0.002199485350158766, 0.0028138791092641195, 0.0]
index = None
#Aggregation.CUMULATIVE# Build the assay, based on the start and end of our baseline time, # and tracking the output variable index 0assay_builder_from_dates=wl.build_assay(assay_name="assays from date baseline",
pipeline=mainpipeline,
model_name="house-price-estimator",
iopath="output variable 0",
baseline_start=assay_baseline_start,
baseline_end=assay_baseline_end)
assay_builder_from_dates.summarizer_builder.add_aggregation(wallaroo.assay_config.Aggregation.CUMULATIVE)
# set the width, interval, and time period assay_builder_from_dates.add_run_until(datetime.datetime.now())
assay_builder_from_dates.window_builder().add_width(minutes=1).add_interval(minutes=1).add_start(assay_window_start)
assay_config_from_dates=assay_builder_from_dates.build()
assay_results_from_dates=assay_config_from_dates.interactive_run()
assay_results_from_dates[0].chart()
baseline mean = 495193.23178642715
window mean = 517763.394625
baseline median = 442168.125
window median = 448627.8125
bin_mode = Quantile
aggregation = Cumulative
metric = PSI
weighted = False
score = 0.17698802395209584
scores = [0.0, 0.06759281437125747, 0.03920159680638724, 0.04579441117764471, 0.02439920159680642, 0.0, 0.0]
index = None
For example, an interval of 1 minute and a width of 1 minute collects 1 minutes worth of data every minute. An interval of 1 minute with a width of 5 minutes collects 5 minute of inference data every minute.
By default, the interval and width is 24 hours.
For this example, we’ll adjust the width and interval from 1 minute to 5 minutes and see how the number of analyses and their score changes.
# Build the assay, based on the start and end of our baseline time, # and tracking the output variable index 0assay_builder_from_dates=wl.build_assay(assay_name="assays from date baseline",
pipeline=mainpipeline,
model_name="house-price-estimator",
iopath="output variable 0",
baseline_start=assay_baseline_start,
baseline_end=assay_baseline_end)
# set the width, interval, and time period assay_builder_from_dates.add_run_until(datetime.datetime.now())
assay_builder_from_dates.window_builder().add_width(minutes=1).add_interval(minutes=1).add_start(assay_window_start)
assay_config_from_dates=assay_builder_from_dates.build()
assay_results_from_dates=assay_config_from_dates.interactive_run()
assay_results_from_dates.chart_scores()
# Build the assay, based on the start and end of our baseline time, # and tracking the output variable index 0assay_builder_from_dates=wl.build_assay(assay_name="assays from date baseline",
pipeline=mainpipeline,
model_name="house-price-estimator",
iopath="output variable 0",
baseline_start=assay_baseline_start,
baseline_end=assay_baseline_end)
# set the width, interval, and time period assay_builder_from_dates.add_run_until(datetime.datetime.now())
assay_builder_from_dates.window_builder().add_width(minutes=5).add_interval(minutes=5).add_start(assay_window_start)
assay_config_from_dates=assay_builder_from_dates.build()
assay_results_from_dates=assay_config_from_dates.interactive_run()
assay_results_from_dates.chart_scores()
Setting the wallaroo.assay_config.WindowBuilder.add_start sets the start date and time to collect inference data. When an assay is uploaded, this setting is included, and assay results will be displayed starting from that start date at the Inference Interval until the assay is paused. By default, add_start begins 24 hours after the assay is uploaded unless set in the assay configuration manually.
For the following example, the add_run_until setting is set to datetime.datetime.now() to collect all inference data from assay_window_start up until now, and the second example limits that example to only two minutes of data.
# inference data that includes all of the data until now assay_builder_from_dates=wl.build_assay(assay_name="assays from date baseline",
pipeline=mainpipeline,
model_name="house-price-estimator",
iopath="output variable 0",
baseline_start=assay_baseline_start,
baseline_end=assay_baseline_end)
# set the width, interval, and time period assay_builder_from_dates.add_run_until(datetime.datetime.now())
assay_builder_from_dates.window_builder().add_width(minutes=1).add_interval(minutes=1).add_start(assay_window_start)
assay_config_from_dates=assay_builder_from_dates.build()
assay_results_from_dates=assay_config_from_dates.interactive_run()
assay_results_from_dates.chart_scores()
# inference data that includes all of the data until now assay_builder_from_dates=wl.build_assay(assay_name="assays from date baseline",
pipeline=mainpipeline,
model_name="house-price-estimator",
iopath="output variable 0",
baseline_start=assay_baseline_start,
baseline_end=assay_baseline_end)
# set the width, interval, and time period assay_builder_from_dates.add_run_until(assay_window_start+datetime.timedelta(seconds=120))
assay_builder_from_dates.window_builder().add_width(minutes=1).add_interval(minutes=1).add_start(assay_window_start)
assay_config_from_dates=assay_builder_from_dates.build()
assay_results_from_dates=assay_config_from_dates.interactive_run()
assay_results_from_dates.chart_scores()
Create Assay
With the assay previewed and configuration options determined, we officially create it by uploading it to the Wallaroo instance.
Once it is uploaded, the assay runs an analysis based on the window width, interval, and the other settings configured.
Assays are uploaded with the wallaroo.assay_config.upload() method. This uploads the assay into the Wallaroo database with the configurations applied and returns the assay id. Note that assay names must be unique across the Wallaroo instance; attempting to upload an assay with the same name as an existing one will return an error.
wallaroo.assay_config.upload() returns the assay id for the assay.
Typically we would just call wallaroo.assay_config.upload() after configuring the assay. For the example below, we will perform the complete configuration in one window to show all of the configuration steps at once before creating the assay.
# Build the assay, based on the start and end of our baseline time, # and tracking the output variable index 0assay_builder_from_dates=wl.build_assay(assay_name="assays creation example",
pipeline=mainpipeline,
model_name="house-price-estimator",
iopath="output variable 0",
baseline_start=assay_baseline_start,
baseline_end=assay_baseline_end)
# set the width, interval, and assay start date and timeassay_builder_from_dates.window_builder().add_width(minutes=1).add_interval(minutes=1).add_start(assay_window_start)
# add other optionsassay_builder_from_dates.summarizer_builder.add_aggregation(wallaroo.assay_config.Aggregation.CUMULATIVE)
assay_builder_from_dates.summarizer_builder.add_metric(wallaroo.assay_config.Metric.MAXDIFF)
assay_builder_from_dates.add_alert_threshold(0.5)
assay_id=assay_builder_from_dates.upload()
The assay is now visible through the Wallaroo UI by selecting the workspace, then the pipeline, then Insights.
Get Assay Results
Once an assay is created the assay runs an analysis based on the window width, interval, and the other settings configured.
Assay results are retrieved with the wallaroo.client.get_assay_results method, which takes the following parameters:
Parameter
Type
Description
assay_id
Integer (Required)
The numerical id of the assay.
start
Datetime.Datetime (Required)
The start date and time of historical data from the pipeline to start analyses from.
end
Datetime.Datetime (Required)
The end date and time of historical data from the pipeline to limit analyses to.
IMPORTANT NOTE: This process requires that additional historical data is generated from the time the assay is created to when the results are available. To add additional inference data, use the Assay Test Data section above.
baseline mean = 495193.23178642715
window mean = 517763.394625
baseline median = 442168.125
window median = 448627.8125
bin_mode = Quantile
aggregation = Cumulative
metric = MaxDiff
weighted = False
score = 0.067592815
scores = [0.0, 0.06759281437125747, 0.03920159680638724, 0.04579441117764471, 0.02439920159680642, 0.0, 0.0]
index = 1
List and Retrieve Assay
If the assay id is not already know, it is retrieved from the wallaroo.client.list_assays() method. Select the assay to retrieve data for and retrieve its id with wallaroo.assay.Assay._id method.