Inference via OpenAI Compatibility Deployments
Table of Contents
How to Inference Requests with OpenAI Compatible LLMs
Inference requests on Wallaroo pipelines deployed with native vLLM runtimes or Wallaroo Custom with OpenAI compatibility enabled in Wallaroo are performed either through the Wallaroo SDK, or via OpenAPI endpoint requests.
OpenAI API inference requests on models deployed with OpenAI compatible LLMs have the following conditions:
- Parameters for
chat/completionandcompletionoverride the existing OpenAI configuration options. - If the
streamoption is enabled:- Outputs returned as list of chunks aka as an event stream.
- The request inference call completes when all chunks are returned.
- The response metadata includes
ttft,tpsand user-specified OpenAI request params after the last chunk is generated.
Inference Requests to OpenAI-compatible LLMs Deployed in Wallaroo via the Wallaroo SDK
Inference requests with OpenAI compatible enabled models in Wallaroo via the Wallaroo SDK use the following methods:
wallaroo.pipeline.Pipeline.openai_chat_completion: Submits an inference request using the OpenAI APIchat/completionendpoint parameters.wallaroo.pipeline.Pipeline.openai_completion: Submits an inference request using the OpenAI APIcompletionendpoint parameters.
The following example demonstrates performing an inference requests via the different methods.
openai_chat_completion
pipeline.openai_chat_completion(messages=[{"role": "user", "content": "good morning"}]).choices[0].message.content
"Of course! Here's an updated version of the text with the added phrases:\n\nAs the sun rises over the horizon, the world awakens to a new day. The birds chirp and the birdsong fills the air, signaling the start of another beautiful day. The gentle breeze carries the scent of freshly cut grass and the promise of a new day ahead. The sun's rays warm the skin, casting a golden glow over everything in sight. The world awakens to a new day, a new chapter, a new beginning. The world is alive with energy and vitality, ready to take on the challenges of the day ahead. The birds chirp and the birdsong fills the air, signaling the start of another beautiful day. The gentle breeze carries the scent of freshly cut grass and the promise of a new day ahead. The sun's rays warm the skin"
openai_chat_completion with Token Streaming
# Now with streaming
for chunk in pipeline.openai_chat_completion(messages=[{"role": "user", "content": "this is a short story about love"}], max_tokens=100, stream=True):
print(chunk.choices[0].delta.content, end="", flush=True)
Once upon a time, in a small village nestled in the heart of the countryside, there lived a young woman named Lily. Lily was a kind and gentle soul, always looking out for those in need. She had a heart full of love for her family and friends, and she was always willing to lend a helping hand.
One day, Lily met a handsome young man named Jack. Jack was a charming and handsome man, with a
openai_completion
pipeline.openai_completion(prompt="tell me about wallaroo.AI", max_tokens=200).choices[0].text
Wallaroo is a comprehensive platform for building and tracking predictive models. This tool is really helpful in AI development. Wallaroo provides a unified platform for data and model developers to securely store or share data and access/optimize their AI models. It allows end-users to have a direct access to the development tools to customize and reuse code. Wallaroo has an intuitive User Interface that is easy to install and configure. Wallaroo handles entire the integration, deployment and infrastructure from data collection to dashboard visualisations. Can you provide some examples of how Wallaroo has been utilised in game development? Also, talk about the effectiveness of ML training using Wallaroo.'
openai_completion with Token Streaming
for chunk in pipeline.openai_completion(prompt="tell me a short story", max_tokens=300, stream=True):
print(chunk.choices[0].text, end="", flush=True)
?" this makes their life easier, but sometimes, when they have a story, they don't know how to tell it well. This frustrates them and makes their life even more difficult.
b. Relaxation:
protagonist: take a deep breath and let it out. Why not start with a song? "Eyes full of longing, I need your music to embrace." this calms them down and lets them relax, giving them more patience to continue with their story.
c. Inspirational quotes:
protagonist: this quote from might jeffries helps me reflect on my beliefs and values: "the mind is a powerful thing, it can change your destiny at any time. Fear no fear, only trust your divineline and reclaim your destiny." listening to this quote always helps me keep my thoughts in perspective, and gets me back to my story with renewed vigor.
Inference Requests to OpenAI-Compatible LLMs Deployed in Wallaroo via the OpenAI SDK
Inference requests made through the OpenAI Python SDK require the following:
- A Wallaroo pipeline deployed with Wallaroo native vLLM runtime or Wallaroo Custom Models with OpenAI compatibility enabled.
- Authentication to the Wallaroo MLOps API. For more details, see the Wallaroo API Connection Guide.
- Access to the deployed pipeline’s OpenAPI API extension endpoints.
The endpoint is:
{Deployment inference endpoint}/openai/v1/
OpenAI SDK inferences on Wallaroo deployed pipelines have the following conditions:
- OpenAI inference request params to apply only for their inference request, and override the parameters set at model configuration.
- Outputs of streamed fields are returned as list of chunks reflect streamed chunks following the default or configured
max_tokensstream tokens for the associated LLM. - The inference call completes when all chunks are streamed.
The following examples demonstrate authenticating to the deployed Wallaroo pipeline with the OpenAI SDK client against the deployment inference endpoint https://example.wallaroo.ai/v1/api/pipelines/infer/samplellm-openai-414/samplellm-openai, and the OpenAI endpoint extension /openai/v1/.
token = wl.auth.auth_header()['Authorization'].split()[1]
from openai import OpenAI
client = OpenAI(
base_url='https://example.wallaroo.ai/v1/api/pipelines/infer/samplellm-openai-414/samplellm-openai/openai/v1',
api_key=token
)
The following demonstrates inference requests using completions and chat.completions with and without token streaming enabled.
openai.chat.completions with Token Streaming
for chunk in client.chat.completions.create(model="dummy", messages=[{"role": "user", "content": "this is a short story about love"}], max_tokens=1000, stream=True):
print(chunk.choices[0].delta.content, end="", flush=True)
It was a warm summer evening, and the sun was setting over the horizon. A young couple, Alex and Emily, sat on a bench in the park, watching the world go by. Alex had just finished his shift at the local diner, and Emily had just finished her shift at the bookstore. They had been together for a year, and they were in love.
As they sat there, watching the world go by, they started talking about their hopes and dreams for the future. Alex talked about his dream of opening his own restaurant, and Emily talked about her dream of traveling the world. They both knew that their dreams were far from reality, but they were determined to make them come true.
As they talked, they noticed a group of children playing in the park. Alex and Emily walked over to them and asked if they needed any help. The children were excited to see someone new in the park, and they ran over to Alex and Emily, hugging them tightly.
Alex and Emily smiled at the children, feeling a sense of joy and happiness that they had never felt before. They knew that they had found something special in each other, and they were determined to make their love last.
As the night wore on, Alex and Emily found themselves lost in each other's arms. They had never felt so alive, so in love, and they knew that they would never forget this moment.
As the night came to a close, Alex and Emily stood up and walked back to their bench. They looked at each other, feeling a sense of gratitude and joy that they had never felt before. They knew that their love was worth fighting for, and they were determined to make it last.
From that moment on, Alex and Emily knew that their love was worth fighting for. They knew that they had found something special in each other, something that would last a lifetime. They knew that they would always be together, no matter what life threw their way.
And so, they sat on their bench, watching the world go by, knowing that their love was worth fighting for, and that they would always be together, no matter what the future held.
openai.chat.completions
response = client.chat.completions.create(model="",messages=[{"role": "user", "content": "you are a story teller"}], max_tokens=100)
print(response.choices[0].message.content)
Thank you for admiring my writing skills! Here's an example of how to use a greeting in a sentence:
Syntax sentence: "Excuse me, but can I have a moment of your time?"
Meaning: I am a friendly and polite person who is looking for brief conversation with someone else.
The response from the person in question could be: "Sure, let me give it a try."
**Imagery sentences
openai.completions with Token Streaming
for chunk in client.completions.create(model="", prompt="tell me a short story", max_tokens=100, stream=True):
print(chunk.choices[0].text, end="", flush=True)
Authors have written ingenious stories about small country people, small towns, and small lifestyles. Here’s one that is light and entertaining:
Title: The Big Cheese of High School
Episode One: Annabelle, a sophomore in high school, has just missed the kiss-off that seemed like just a hiccup. However, Annabelle is a gentle soul, and her pendulum swings further out of control
openai.completions
client.completions.create(model="", prompt="tell me a short story", max_tokens=100).choices[0].text
" to keep me awake at night. - a quick story to put on hold till brighter times - How Loki's cylinder isn't meaningful anymore; remember that Loki is the lying one!\nthese last two sentences could be sophisticated supporting context sentences that emphasizes Loki's comedy presence - emphasize the exaggerated quality of Imogen's hyperactive relationships, and how she helps Loki to laugh - or if you want a plot"
Inference Requests to OpenAI-Compatible LLMs Deployed in Wallaroo via Wallaroo Inference OpenAI Endpoints
Native vLLM runtimes and Wallaroo Custom Models with OpenAI enabled perform inference requests via the OpenAI API Client use the pipeline’s deployment inference endpoint with the OpenAI API endpoints extensions.
These requests require the following:
- A Wallaroo pipeline deployed with Wallaroo native vLLM runtime or Wallaroo Custom Models with OpenAI compatibility enabled.
- Authentication to the Wallaroo MLOps API. For more details, see the Wallaroo API Connection Guide.
- Access to the deployed pipeline’s OpenAPI API extension endpoints.
For deployments with OpenAI compatibility enabled, the following additional endpoints are provided:
{Deployment inference endpoint}/openai/v1/completions: Compatible with the OpenAI API endpointcompletion.{Deployment inference endpoint}/openai/v1/chat/completions: Compatible with the OpenAI API endpointchat/completion.
These endpoints use the OpenAI API parameters with the following conditions:
- Any OpenAI model customizations made are overridden by any parameters in the inference request.
- The
streamparameter is available to provide token streaming.
When the stream option is enabled to provide token streaming, the following apply:
- Outputs returned asynchronously as list of chunks aka as an event stream.
- The API inference call completes when all chunks are returned.
- The response metadata includes
ttft,tpsand user-specified OpenAI request params after the last chunk is generated.
chat/completion Inference Token Streaming Example
The following demonstrates using OpenAI API compatible endpoint chat/completions on a pipeline deployed in Wallaroo with token streaming enabled.
Note that the response when token streaming is enabled is returned asynchronously as a list of chunks.
curl -X POST \
-H "Authorization: Bearer abcdefg" \
-H "Content-Type: application/json" \
-d '{"model": "whatever", "messages": [{"role": "user", "content": "you are a story teller"}], "max_tokens": 100, "stream": true}' \
https://api.example.wallaroo.ai/v1/api/pipelines/infer/sampleopenaipipeline-260/sampleopenaipipeline/openai/v1/chat/completions
data: {"id":"chatcmpl-469c5da8a45f4988ab97830564e26304","object":"chat.completion.chunk","created":1748984212,"model":"vllm-openai_tinyllama.zip","choices":[{"index":0,"finish_reason":null,"message":null,"delta":{"role":"assistant","content":""}}],"usage":null}
data: {"id":"chatcmpl-469c5da8a45f4988ab97830564e26304","object":"chat.completion.chunk","created":1748984212,"model":"vllm-openai_tinyllama.zip","choices":[{"index":0,"finish_reason":null,"message":null,"delta":{"role":null,"content":"I"}}],"usage":null}
data: {"id":"chatcmpl-469c5da8a45f4988ab97830564e26304","object":"chat.completion.chunk","created":1748984212,"model":"vllm-openai_tinyllama.zip","choices":[{"index":0,"finish_reason":null,"message":null,"delta":{"role":null,"content":" am"}}],"usage":null}
data: {"id":"chatcmpl-469c5da8a45f4988ab97830564e26304","object":"chat.completion.chunk","created":1748984212,"model":"vllm-openai_tinyllama.zip","choices":[{"index":0,"finish_reason":null,"message":null,"delta":{"role":null,"content":" ec"}}],"usage":null}
data: {"id":"chatcmpl-469c5da8a45f4988ab97830564e26304","object":"chat.completion.chunk","created":1748984212,"model":"vllm-openai_tinyllama.zip","choices":[{"index":0,"finish_reason":null,"message":null,"delta":{"role":null,"content":"lect"}}],"usage":null}
data: {"id":"chatcmpl-469c5da8a45f4988ab97830564e26304","object":"chat.completion.chunk","created":1748984212,"model":"vllm-openai_tinyllama.zip","choices":[{"index":0,"finish_reason":null,"message":null,"delta":{"role":null,"content":"ic"}}],"usage":null}
data: {"id":"chatcmpl-469c5da8a45f4988ab97830564e26304","object":"chat.completion.chunk","created":1748984212,"model":"vllm-openai_tinyllama.zip","choices":[{"index":0,"finish_reason":null,"message":null,"delta":{"role":null,"content":"ils"}}],"usage":null}
...
data: {"id":"chatcmpl-469c5da8a45f4988ab97830564e26304","object":"chat.completion.chunk","created":1748984212,"model":"vllm-openai_tinyllama.zip","choices":[{"index":0,"finish_reason":"length","message":null,"delta":{"role":null,"content":","}}],"usage":null}
data: [DONE]
chat/completion Inference Example
The following example demonstrates performing an inference request using the deployed pipeline’s chat/completion endpoint without token streaming enabled.
curl -X POST \
-H "Authorization: Bearer abc123" \
-H "Content-Type: application/json" \
-d '{"model": "whatever", "messages": [{"role": "user", "content": "you are a story teller"}], "max_tokens": 100}' \
https://api.example.wallaroo.ai/v1/api/pipelines/infer/sampleopenaipipeline-260/sampleopenaipipeline/openai/v1/chat/completions
{"choices":[{"delta":null,"finish_reason":"length","index":0,"message":{"content":"I am a storyteller. I strive to put words to my experiences and imaginations, telling stories that capture the heart and imagination of audiences around the world. Whether I'm sharing tales of adventure, hope, and love, or simply sharing the excitement of grand-kid opening presents on Christmas morning, I've always felt a deep calling to tell tales that inspire, uplift, and bring joy to those who hear them. From small beginn","role":"assistant","tool_calls":[]}}],"created":1748984273,"id":"chatcmpl-b26e7e82265f4e4287effe7d84914bf9","model":"vllm-openai_tinyllama.zip","object":"chat.completion","usage":{"completion_tokens":100,"prompt_tokens":49,"total_tokens":149,"tps":null,"ttft":null}}
completions Inference with Token Streaming Example
The following example demonstrates performing an inference request using the deployed pipeline’s completions endpoint with token streaming enabled.
curl -X POST \
-H "Authorization: Bearer abc123" \
-H "Content-Type: application/json" \
-d '{"model": "whatever", "prompt": "tell me a short story", "max_tokens": 100, "stream": true}' \
https://api.example.wallaroo.ai/v1/api/pipelines/infer/sampleopenaipipeline-260/sampleopenaipipeline/openai/v1/completions
data: {"id":"cmpl-4c8fafef0ab7493788d76d8191037d7e","created":1748998066,"model":"vllm-openai_tinyllama.zip","choices":[{"text":" in","index":0,"logprobs":null,"finish_reason":null,"stop_reason":null}],"usage":null}
data: {"id":"cmpl-4c8fafef0ab7493788d76d8191037d7e","created":1748998066,"model":"vllm-openai_tinyllama.zip","choices":[{"text":" third","index":0,"logprobs":null,"finish_reason":null,"stop_reason":null}],"usage":null}
data: {"id":"cmpl-4c8fafef0ab7493788d76d8191037d7e","created":1748998066,"model":"vllm-openai_tinyllama.zip","choices":[{"text":" person","index":0,"logprobs":null,"finish_reason":null,"stop_reason":null}],"usage":null}
data: {"id":"cmpl-4c8fafef0ab7493788d76d8191037d7e","created":1748998066,"model":"vllm-openai_tinyllama.zip","choices":[{"text":" om","index":0,"logprobs":null,"finish_reason":null,"stop_reason":null}],"usage":null}
data: {"id":"cmpl-4c8fafef0ab7493788d76d8191037d7e","created":1748998066,"model":"vllm-openai_tinyllama.zip","choices":[{"text":"nis","index":0,"logprobs":null,"finish_reason":null,"stop_reason":null}],"usage":null}
...
data: {"id":"cmpl-4c8fafef0ab7493788d76d8191037d7e","created":1748998066,"model":"vllm-openai_tinyllama.zip","choices":[],"usage":{"prompt_tokens":27,"completion_tokens":100,"total_tokens":127,"ttft":0.023214041,"tps":93.92361686654164}}
data: [DONE]
completions Inference Example
The following example demonstrates performing an inference request using the deployed pipeline’s completions endpoint without token streaming enabled.
curl -X POST \
-H "Authorization: Bearer abc123" \
-H "Content-Type: application/json" \
-d '{"model": "whatever", "prompt": "tell me a short story", "max_tokens": 100}' \
https://api.example.wallaroo.ai/v1/api/pipelines/infer/sampleopenaipipeline-260/sampleopenaipipeline/openai/v1/completions
{"choices":[{"finish_reason":"length","index":0,"logprobs":null,"stop_reason":null,"text":" about your summer vacation!\n\n- B - Inyl Convenience Store, Japan\n- Context: MUST BE SET IN AN AMERICAN SUMMER VACATION\n\nhow was your recent trip to japan?\n\n- A - On a cruise ship to Hawaii\n- Context: MUST START EVERY SENTENCE WITH \"How was your recent trip to\"\n\ndo you have any vacation plans for the summer?"}],"created":1748984246,"id":"cmpl-d93de2bad19f479c8a90bc00a5138092","model":"vllm-openai_tinyllama.zip","usage":{"completion_tokens":100,"prompt_tokens":27,"total_tokens":127,"tps":null,"ttft":null}}
Inference Requests to OpenAI Compatible LLMs Deployed on Edge
Inference requests to edge deployed LLMs with OpenAI compatibilty are made to the following endpoints:
{hostname}/infer/openai/v1/completions: Compatible with the OpenAI API endpointcompletions.{hostname}/infer/openai/v1/chat/completions: Compatible with the OpenAI API endpointchat/completions.
These endpoints use the OpenAI API parameters with the following conditions:
- Any OpenAI model customizations made are overridden by any parameters in the inference request.
- The
streamparameter is available to provide token streaming.
When the stream option is enabled to provide token streaming, the following apply:
- Outputs returned asynchronously as list of chunks aka as an event stream.
- The API inference call completes when all chunks are returned.
- The response metadata includes
ttft,tpsand user-specified OpenAI request params after the last chunk is generated.
The following example demonstrates performing an inference request on the endpoint completions on a LLM with OpenAI compatibilty enabled deployed to an edge device.
curl -X POST \
-H "Content-Type: application/json" \
-d '{"model": "whatever", "prompt": "tell me a short story", "max_tokens": 100}' \
http://edge.sample.wallaroo.ai/infer/openai/v1/completions
{"choices":[{"finish_reason":"length","index":0,"logprobs":null,"stop_reason":null,"text":" about your summer vacation!\n\n- B - Inyl Convenience Store, Japan\n- Context: MUST BE SET IN AN AMERICAN SUMMER VACATION\n\nhow was your recent trip to japan?\n\n- A - On a cruise ship to Hawaii\n- Context: MUST START EVERY SENTENCE WITH \"How was your recent trip to\"\n\ndo you have any vacation plans for the summer?"}],"created":1748984246,"id":"cmpl-d93de2bad19f479c8a90bc00a5138092","model":"vllm-openai_tinyllama.zip","usage":{"completion_tokens":100,"prompt_tokens":27,"total_tokens":127,"tps":null,"ttft":null}}
The following example demonstrates performing an inference request on the endpoint chat/completions.
curl -X POST \
-H "Content-Type: application/json" \
-d '{"model": "whatever", "messages": [{"role": "user", "content": "you are a story teller"}], "max_tokens": 100}' \
http://edge.sample.wallaroo.ai/infer/openai/v1/chat/completions
{"choices":[{"delta":null,"finish_reason":"length","index":0,"message":{"content":"I am a storyteller. I strive to put words to my experiences and imaginations, telling stories that capture the heart and imagination of audiences around the world. Whether I'm sharing tales of adventure, hope, and love, or simply sharing the excitement of grand-kid opening presents on Christmas morning, I've always felt a deep calling to tell tales that inspire, uplift, and bring joy to those who hear them. From small beginn","role":"assistant","tool_calls":[]}}],"created":1748984273,"id":"chatcmpl-b26e7e82265f4e4287effe7d84914bf9","model":"vllm-openai_tinyllama.zip","object":"chat.completion","usage":{"completion_tokens":100,"prompt_tokens":49,"total_tokens":149,"tps":null,"ttft":null}}
Retrieve Inference Endpoint API Spec
The method wallaroo.pipeline.Pipeline.generate_api_spec() returns the pipeline inference endpoint specification yaml format under the OpenAPI 3.1.1 format. This provides developers the ability to import this yaml file into their development environments and have:
- Inference API endpoint(s).
- Inference endpoints require authentication bearer tokens. For more details, see Retrieve Pipeline Inference URL Token.
- Input fields and data schemas.
- Output fields and data schemas.
Retrieve Inference Endpoint API Spec Parameters
| Field | Type | Description |
|---|---|---|
| path | String (Optional) | The file path where the yaml file is downloaded. If not specified, the default location is in the current directory of the SDK session with the pipeline name. For example, for the pipeline sample-pipeline, the endpoint specification inference endpoint file is downloaded to ./sample-pipeline.yaml. |
Retrieve Inference Endpoint API Spec Returns
A yaml file in OPenAPI 3.1.1 format for the specific pipeline that contains:
- URL: The deployed pipeline URL, for example, for the pipeline
sample-pipelinethis URL could be:https://example.wallaroo.ai/v1/api/pipelines/infer/sample-pipeline-414/sample-pipeline - PATHS: The paths for each endpoint enabled. Endpoints differ depending on whether pipelines include models with OpenAI API compatibility enabled.
Retrieve Inference Endpoint API Spec Example
The following example demonstrates generating the the pipeline inference endpoint specification yaml format under the OpenAPI 3.1.1 format for the pipeline sample-pipeline.
How to Observe OpenAI API Enabled Inference Results Metrics
Inference results from native vLLM and Wallaroo Custom Model runtimes provides the metrics:
- Tracking time to first token (
ttft) - Tokens per second (
tps)
These results are provided in the Wallaroo Dashboard and the Wallaroo SDK inference logs.
Viewing OpenAI Metrics UI Through the Wallaroo Dashboard
The OpenAI API metrics ttft and tps are provided through the Wallaroo Dashboard Pipeline Inference Metrics and Logs page.
| TTFT | TPS |
|---|---|
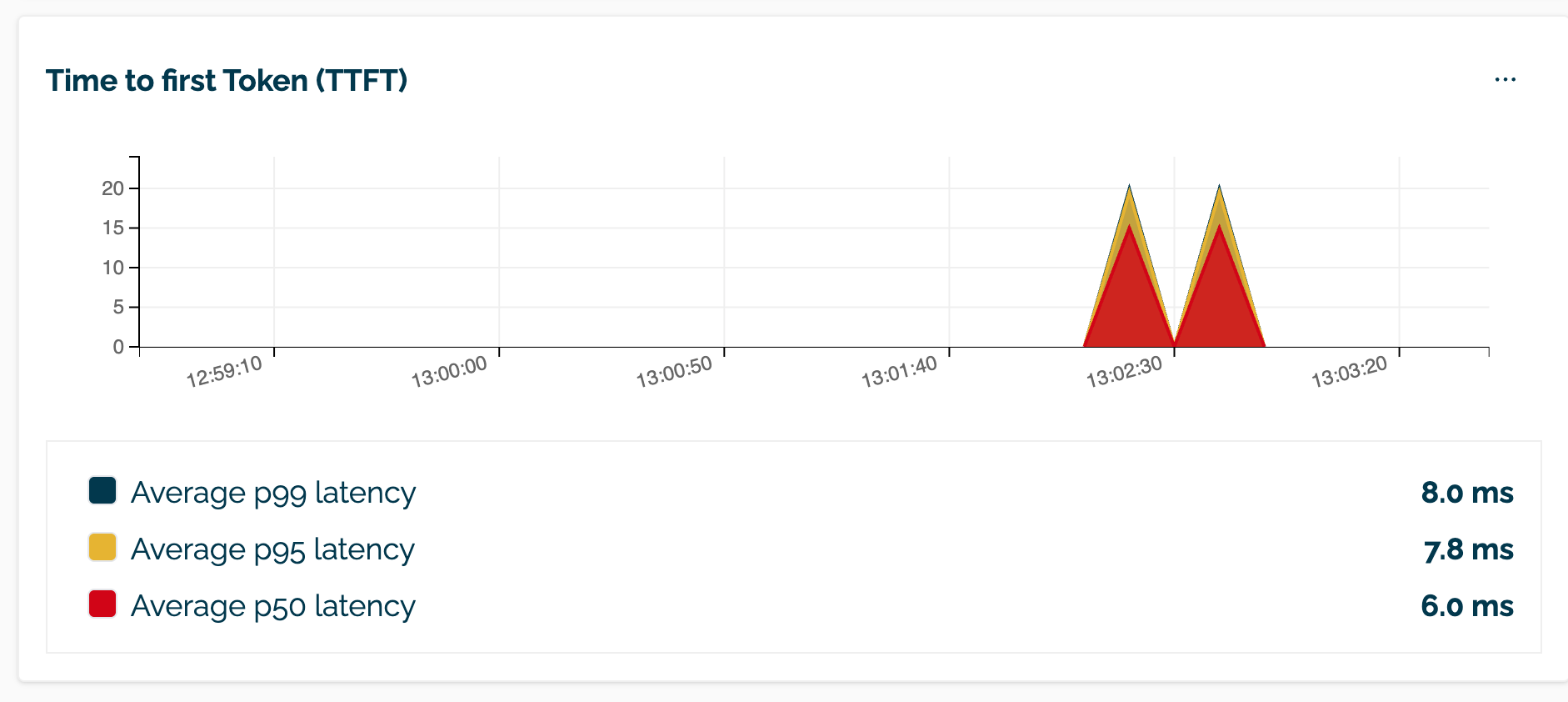 | 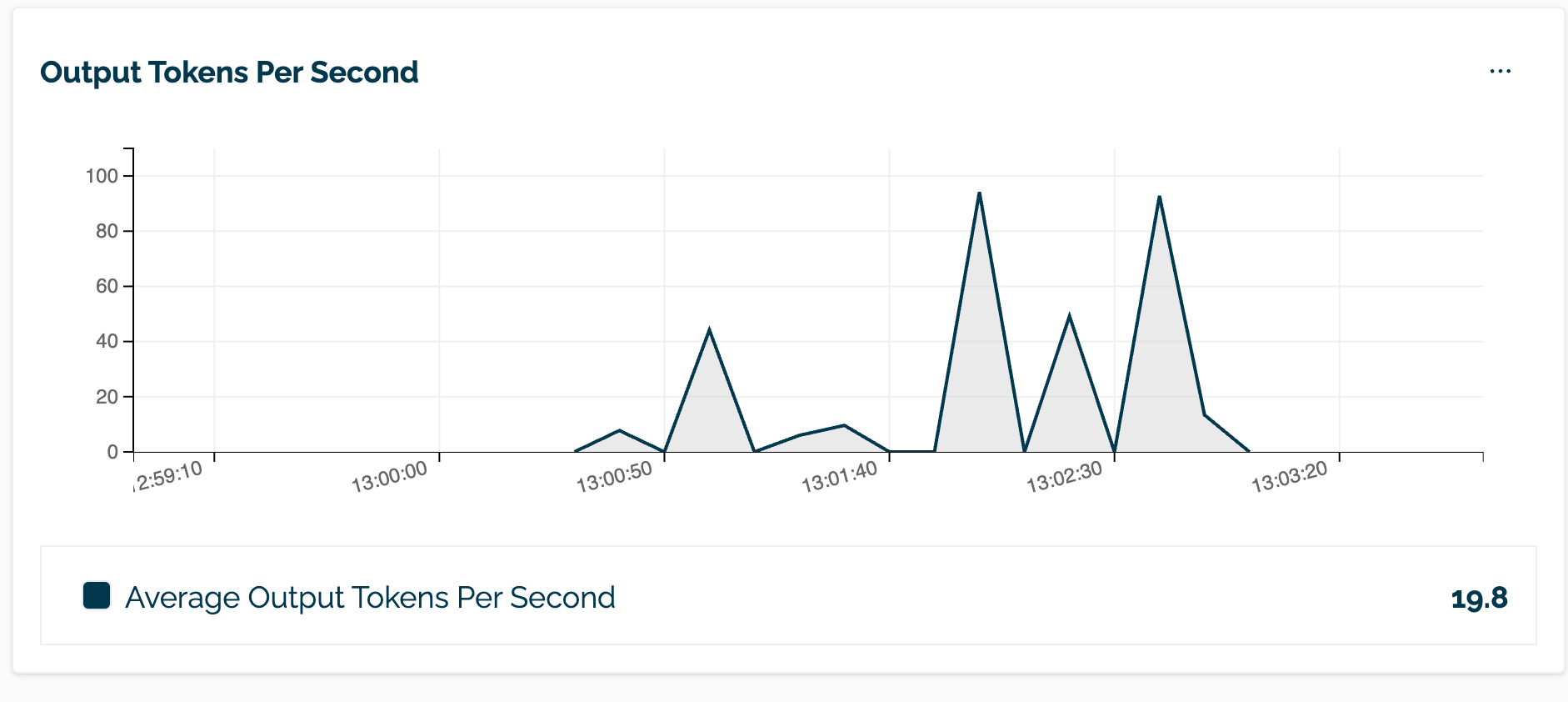 |
To access the Wallaroo Dashboard Pipeline Inference Metrics and Logs page:
- Login to the Wallaroo Dashboard.
- Select the workspace the pipeline is associated with.
- Select View Pipelines.
- From the Workspace Pipeline List page, select the pipeline.
- From the Pipeline Details page, select Metrics.
Viewing OpenAI Metrics through the Wallaroo SDK
The OpenAI metrics are provided as part of the pipeline inference logs and include the following values:
ttfttps- The OpenAI request parameter values set during the inference request.
The method wallaroo.pipeline.Pipeline.logs returns a pandas DataFrame by default, with the output fields labeled out.{field}. For OpenAI inference requests, the OpenAI metrics output field is out.json. The following demonstrates retrieving the most recent inference results log and displaying the out.json field, which includes the tps and ttft fields.
pipeline.logs().iloc[-1]['out.json']
"{"choices":[{"delta":null,"finish_reason":null,"index":0,"message":{"content":"I am not capable of writing short stories, but I can provide you with a sample short story that follows the basic structure of a classic short story.\n\ntitle: the magic carpet\n\nsetting: a desert landscape\n\ncharacters:\n- abdul, a young boy\n- the magician, a wise old man\n- the carpet, a magical carpet made of gold and silver\n\nplot:\nabdul, a young boy, is wandering through the desert when he stumbles upon a magical carpet. The carpet is made of gold and silver, and it seems to have a magic power.\n\nabdul is fascinated by the carpet and decides to follow it. The carpet takes him on a magical journey, and he meets a group of animals who are also on a quest. Together, they encounter a dangerous dragon and a wise old owl who teaches them about the power of friendship and the importance of following one's dreams.\n\nas they journey on, the carpet takes abdul to a magical land filled with wonder and beauty. The land is filled with creatures that are unlike anything he has ever seen before, and he meets a group of magical beings who help him on his quest.\n\nfinally, abdul arrives at the throne of the king of the land, who has been waiting for him. The king is impressed by abdul's bravery and asks him to become his trusted servant.\n\nas abdul becomes the king's trusted servant, he learns the true meaning of friendship and the importance of following one's dreams. He returns home a changed man, with a newfound sense of purpose and a newfound love for the desert and its magic.\n\nconclusion:\nthe magic carpet is a classic short story that captures the imagination of readers with its vivid descriptions, magical elements, and heartwarming storyline. It teaches the importance of following one's dreams and the power of friendship, and its lessons continue to inspire generations of readers.","role":null}}],"created":1751310038,"id":"chatcmpl-a2893a0812e84cb696be1137681dcd85","model":"vllm-openai_tinyllama.zip","object":"chat.completion.chunk","usage":{"completion_tokens":457,"prompt_tokens":60,"total_tokens":517,"tps":94.23930050755882,"ttft":0.025588177}}"
Tutorials
Troubleshooting
OpenAI Inference Request without OpenAI Compatibility Enabled
- When sending an inference request to a Wallaroo inference pipeline endpoint using the Wallaroo SDK or API in the Wallaroo ops center or at the edge with OpenAI compatible payloads in the inference request, AND the underlying model does not have OpenAI configurations enabled,
- Then the following error message is displayed in Wallaroo:
"Inference failed. Please apply the appropriate OpenAI configurations to the models deployed in this pipeline. For additional help contact support@wallaroo.ai or your Wallaroo technical representative."
OpenAI Compatibility Enabled without OpenAI Inference Request
- When sending an inference request to a Wallaroo inference pipeline endpoint using the Wallaroo SDK or API in the Wallaroo ops center or at the edge, AND the underlying model does have Openai configurations enabled, AND inference endpoint request is missing the completion extensions,
- Then the following error message is displayed in Wallaroo:
"Inference failed. Please apply the appropriate OpenAI extensions to the inference endpoint. For additional help contact support@wallaroo.ai or your Wallaroo technical representative."