Wallaroo SDK AWS Sagemaker Install Guide
This tutorial and the assets can be downloaded as part of the Wallaroo Tutorials repository.
Installing the Wallaroo SDK in AWS Sagemaker
Organizations that develop machine learning models can deploy models to Wallaroo from AWS Sagemaker to a Wallaroo instance through the Wallaroo SDK. The following guide is created to assist users with installing the Wallaroo SDK and making a standard connection to a Wallaroo instance.
Organizations can use Wallaroo SSO for Amazon Web Services to provide AWS users access to the Wallaroo instance.
These instructions are based on the on the Connect to Wallaroo guides.
This tutorial provides the following:
aloha-cnn-lstm.zip: A pre-trained open source model that uses an Aloha CNN LSTM model for classifying Domain names as being either legitimate or being used for nefarious purposes such as malware distribution.- Test Data Files:
data_1k.arrow: 1,000 recordsdata_25k.arrow: 25,000 records
For this example, a virtual python environment will be used. This will set the necessary libraries and specific Python version required.
Prerequisites
The following is required for this tutorial:
- A Wallaroo instance version 2024.4 or later.
- A AWS Sagemaker domain with a Notebook Instance.
- Python 3.10.6 or later.
- The following Python libraries installed:
General Steps
For our example, we will perform the following:
- Install Wallaroo SDK
- Set up a Python virtual environment through
condawith the libraries that enable the virtual environment for use in a Jupyter Hub environment. - Install the Wallaroo SDK.
- Set up a Python virtual environment through
- Wallaroo SDK from remote JupyterHub Demonstration (Optional): The following steps are an optional exercise to demonstrate using the Wallaroo SDK from a remote connection. The entire tutorial can be found on the Wallaroo Tutorials repository.
- Connect to a remote Wallaroo instance.
- Create a workspace for our work.
- Upload the Aloha model.
- Create a pipeline that can ingest our submitted data, submit it to the model, and export the results
- Run a sample inference through our pipeline by loading a file
- Retrieve the external deployment URL. This sample Wallaroo instance has been configured to create external inference URLs for pipelines. For more information, see the External Inference URL Guide.
- Run a sample inference through our pipeline’s external URL and store the results in a file. This assumes that the External Inference URLs have been enabled for the target Wallaroo instance.
- Undeploy the pipeline and return resources back to the Wallaroo instance’s Kubernetes environment.
Install Wallaroo SDK
Set Up Virtual Python Environment
To set up the Python virtual environment for use of the Wallaroo SDK:
From AWS Sagemaker, select the Notebook instances.
For the list of notebook instances, select Open JupyterLab for the notebook instance to be used.
From the Launcher, select Terminal.
From a terminal shell, create the Python virtual environment with
conda. Replacewallaroosdkwith the name of the virtual environment as required by your organization. Note that Python 3.10 is specified as a requirement for Python libraries used with the Wallaroo SDK. The following will install the latest version of Python 3.10.conda create -n wallaroosdk python=3.10(Optional) If the shells have not been initialized with conda, use the following to initialize it. The following examples will use the
bashshell.Initialize the bash shell with conda with the command:
conda init bashLaunch the bash shell that has been initialized for
conda:bash
Activate the new environment.
conda activate wallaroosdkInstall the
ipykernellibrary. This allows the JupyterHub notebooks to access the Python virtual environment as a kernel, and it required for the second part of this tutorial.conda install ipykernelInstall the new virtual environment as a python kernel.
ipython kernel install --user --name=wallaroosdk
Install the Wallaroo SDK. This process may take several minutes while the other required Python libraries are added to the virtual environment.
- IMPORTANT NOTE: The version of the Wallaroo SDK should match the Wallaroo instance. For example, this example connects to a Wallaroo Enterprise version
2026.1instance, so the SDK version should bewallaroo==2026.1.3.
pip install wallaroo==2026.1.3- IMPORTANT NOTE: The version of the Wallaroo SDK should match the Wallaroo instance. For example, this example connects to a Wallaroo Enterprise version
For organizations who will be using the Wallaroo SDK with Jupyter or similar services, the conda virtual environment has been installed, it can either be selected as a new Jupyter Notebook kernel, or the Notebook’s kernel can be set to an existing Jupyter notebook.
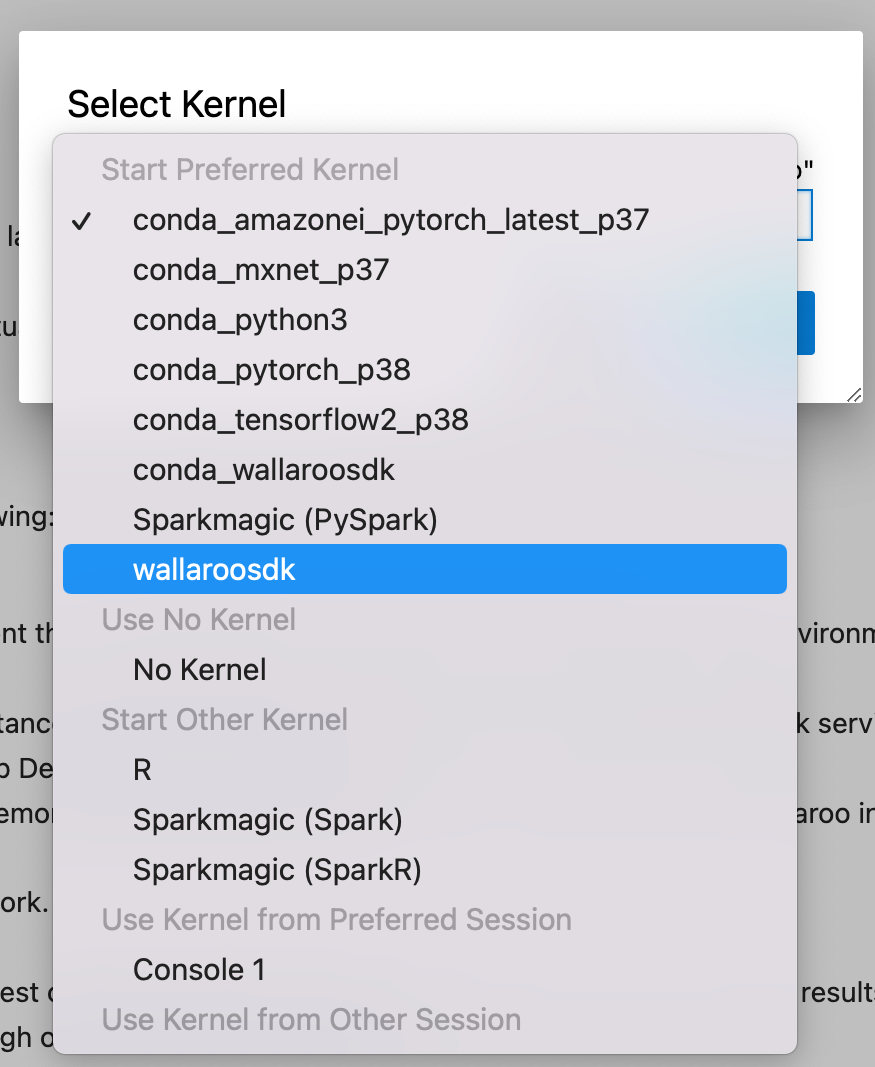
To use a new Notebook:
- From the main menu, select File->New-Notebook.
- From the Kernel selection dropbox, select the new virtual environment - in this case, wallaroosdk.
To update an existing Notebook to use the new virtual environment as a kernel:
- From the main menu, select Kernel->Change Kernel.
- Select the new kernel.
Sample Wallaroo Connection
With the Wallaroo Python SDK installed, remote commands and inferences can be performed through the following steps.
Open a Connection to Wallaroo
The first step is to connect to Wallaroo through the Wallaroo client.
This is accomplished using the wallaroo.Client(api_endpoint, auth_endpoint, auth_type command) command that connects to the Wallaroo instance services.
The Client method takes the following parameters:
- api_endpoint (String): The URL to the Wallaroo instance API service.
- auth_endpoint (String): The URL to the Wallaroo instance Authentication service.
- auth_type command (String): The authorization type. In this case,
SSO.
The URLs are based on the Wallaroo Domain. For more information, see the DNS Integration Guide. In the example below, replace the Wallaroo Domain with the domain of your Wallaroo installation.
Once run, the wallaroo.Client command provides a URL to grant the SDK permission to your specific Wallaroo environment. When displayed, enter the URL into a browser and confirm permissions. Depending on the configuration of the Wallaroo instance, the user will either be presented with a login request to the Wallaroo instance or be authenticated through a broker such as Google, Github, etc. To use the broker, select it from the list under the username/password login forms. For more information on Wallaroo authentication configurations, see the Wallaroo Authentication Configuration Guides.
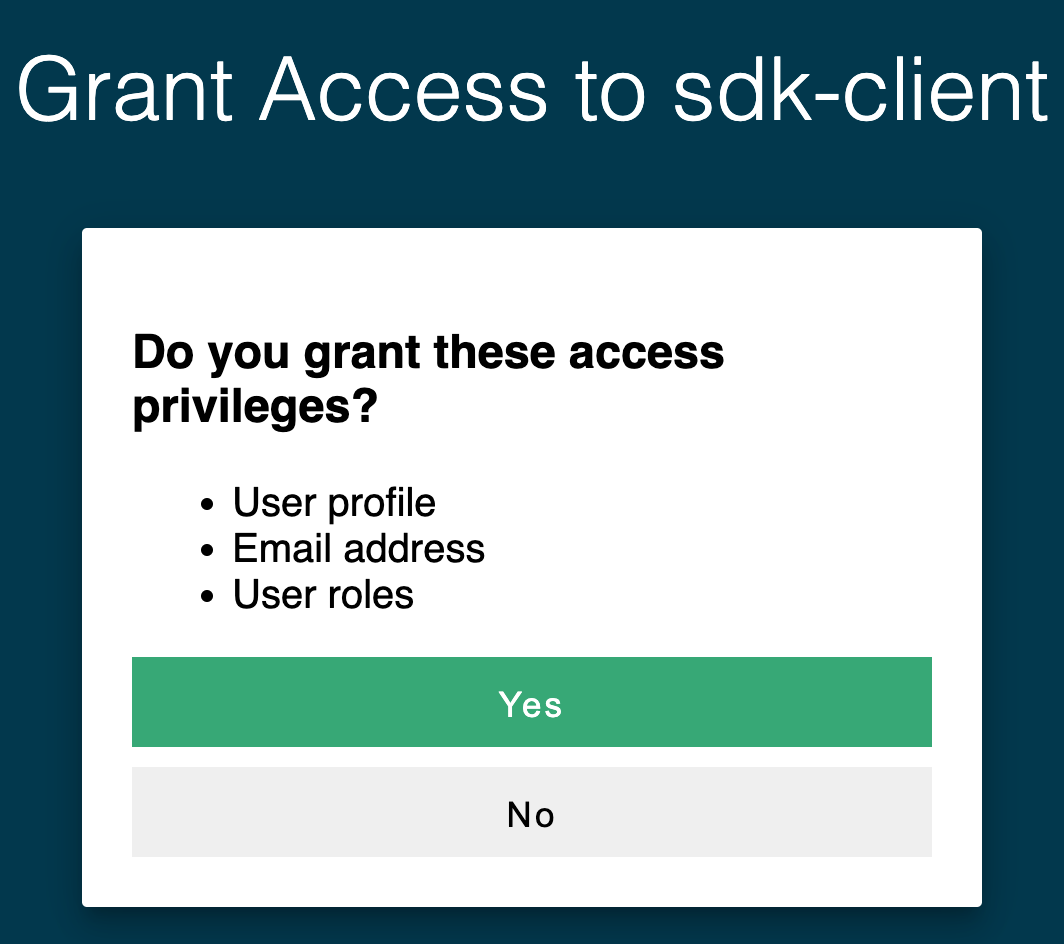
Once authenticated, the user will verify adding the device the user is establishing the connection from. Once both steps are complete, then the connection is granted.
The connection is stored in the variable wl for use in all other Wallaroo calls.
import wallaroo
from wallaroo.object import EntityNotFoundError
# to display dataframe tables
from IPython.display import display
# used to display dataframe information without truncating
import pandas as pd
pd.set_option('display.max_colwidth', None)
import pyarrow as pa
wallaroo.__version__
'2023.4.0b1'
Connect to Wallaroo
For this example, a connection through the Wallaroo SDK is used. For more information, see the Wallaroo SDK Essentials Guide: Client Connection.
For connections to Wallaroo from an external connection, the wallaroo.client.Client method uses the following parameters:
- api_endpoint: The Wallaroo Domain name.
- auth_type: The authorization type. This example will use
sso.
# SSO login
wl = wallaroo.Client()
# wallarooDomain = 'wallaroo.example.com`
# wl = wallaroo.Client(api_endpoint=f"https://{wallarooDomain}",
# auth_type="sso")
Wallaroo Remote SDK Examples
The following examples can be used by an organization to test using the Wallaroo SDK from a remote location from their Wallaroo instance. These examples show how to create workspaces, deploy pipelines, and perform inferences through the SDK and API.
Create the Workspace
We will create a workspace to work in and call it the sdkworkspace, then set it as current workspace environment. We’ll also create our pipeline in advance as sdkpipeline.
- IMPORTANT NOTE: For this example, the Aloha model is stored in the file
alohacnnlstm.zip. When using tensor based models, the zip file must match the name of the tensor directory. For example, if the tensor directory isalohacnnlstm, then the .zip file must be namedalohacnnlstm.zip.
workspace_name = 'sdkquickworkspace'
pipeline_name = 'sdkquickpipeline'
model_name = 'sdkquickmodel'
model_file_name = './alohacnnlstm.zip'
def get_workspace(name):
workspace = None
for ws in wl.list_workspaces():
if ws.name() == name:
workspace= ws
if(workspace == None):
workspace = wl.create_workspace(name)
return workspace
def get_pipeline(name):
try:
pipeline = wl.pipelines_by_name(name)[0]
except EntityNotFoundError:
pipeline = wl.build_pipeline(name)
return pipeline
workspace = get_workspace(workspace_name)
wl.set_current_workspace(workspace)
pipeline = get_pipeline(pipeline_name)
pipeline
| name | sdkquickpipeline |
|---|---|
| created | 2023-10-31 19:04:45.856204+00:00 |
| last_updated | 2023-10-31 19:04:45.856204+00:00 |
| deployed | (none) |
| arch | None |
| tags | |
| versions | 5757db0a-1ae6-45f8-ae37-57fa3a37caab |
| steps | |
| published | False |
We can verify the workspace is created the current default workspace with the get_current_workspace() command.
wl.get_current_workspace()
{'name': 'sdkquickworkspace', 'id': 13, 'archived': False, 'created_by': '1394d144-06a0-4b6b-b2db-d7945810e39c', 'created_at': '2023-10-31T19:04:44.78403+00:00', 'models': [], 'pipelines': [{'name': 'sdkquickpipeline', 'create_time': datetime.datetime(2023, 10, 31, 19, 4, 45, 856204, tzinfo=tzutc()), 'definition': '[]'}]}
Upload the Models
Now we will upload our model. Note that for this example we are applying the model from a .ZIP file. The Aloha model is a protobuf file that has been defined for evaluating web pages, and we will configure it to use data in the tensorflow format.
from wallaroo.framework import Framework
model = wl.upload_model(model_name, model_file_name, framework=Framework.TENSORFLOW).configure("tensorflow")
Deploy a Model
Now that we have a model that we want to use we will create a deployment for it.
We will tell the deployment we are using a tensorflow model and give the deployment name and the configuration we want for the deployment.
To do this, we’ll create our pipeline that can ingest the data, pass the data to our Aloha model, and give us a final output. We’ll call our pipeline externalsdkpipeline, then deploy it so it’s ready to receive data. The deployment process usually takes about 45 seconds.
pipeline.add_model_step(model)
| name | sdkquickpipeline |
|---|---|
| created | 2023-10-31 19:04:45.856204+00:00 |
| last_updated | 2023-10-31 19:04:45.856204+00:00 |
| deployed | (none) |
| arch | None |
| tags | |
| versions | 5757db0a-1ae6-45f8-ae37-57fa3a37caab |
| steps | |
| published | False |
pipeline.deploy()
| name | sdkquickpipeline |
|---|---|
| created | 2023-10-31 19:04:45.856204+00:00 |
| last_updated | 2023-10-31 19:04:51.298382+00:00 |
| deployed | True |
| arch | None |
| tags | |
| versions | 6d23f8dc-2ce1-4bf6-88ec-ec2278534bbf, 5757db0a-1ae6-45f8-ae37-57fa3a37caab |
| steps | sdkquickmodel |
| published | False |
We can verify that the pipeline is running and list what models are associated with it.
pipeline.status()
{'status': 'Running',
'details': [],
'engines': [{'ip': '10.244.3.76',
'name': 'engine-757f469d7-gzn7z',
'status': 'Running',
'reason': None,
'details': [],
'pipeline_statuses': {'pipelines': [{'id': 'sdkquickpipeline',
'status': 'Running'}]},
'model_statuses': {'models': [{'name': 'sdkquickmodel',
'version': '59e390be-812d-447a-99bc-36b115e643db',
'sha': 'd71d9ffc61aaac58c2b1ed70a2db13d1416fb9d3f5b891e5e4e2e97180fe22f8',
'status': 'Running'}]}}],
'engine_lbs': [{'ip': '10.244.4.97',
'name': 'engine-lb-584f54c899-jmksp',
'status': 'Running',
'reason': None,
'details': []}],
'sidekicks': []}
Inferences
Infer 1 row
Now that the pipeline is deployed and our Aloha model is in place, we’ll perform a smoke test to verify the pipeline is up and running properly. We’ll use the infer_from_file command to load a single encoded URL into the inference engine and print the results back out.
The result should tell us that the tokenized URL is legitimate (0) or fraud (1). This sample data should return close to 1.
## Demonstrate via straight infer
smoke_test = pd.DataFrame.from_records(
[
{
"text_input":[
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
28,
16,
32,
23,
29,
32,
30,
19,
26,
17
]
}
]
)
result = pipeline.infer(smoke_test)
display(result.loc[:, ["time","out.main"]])
| time | out.main | |
|---|---|---|
| 0 | 2023-10-31 19:05:04.128 | [0.997564] |
Infer 1,000 Rows
We can also infer an entire batch as one request either with the Pipeline infer method with multiple rows, or loaded from a file using the Pipeline infer_from_file method. For this example, we will run a batch on 1,000 records using the file data_1k.arrow. This is an Apache Arrow table, which gives the added benefit of speed and lower file size as a binary file rather than a text JSON file.
We’ll infer the 1,000 records, then convert it to a DataFrame and display the first 5 to save space in our Jupyter Notebook.
result = pipeline.infer_from_file('./data/data_1k.arrow')
outputs = result.to_pandas()
display(outputs.head(5).loc[:, ["time","out.main"]])
| time | out.main | |
|---|---|---|
| 0 | 2023-10-31 19:05:05.088 | [0.997564] |
| 1 | 2023-10-31 19:05:05.088 | [0.9885122] |
| 2 | 2023-10-31 19:05:05.088 | [0.9993358] |
| 3 | 2023-10-31 19:05:05.088 | [0.99999857] |
| 4 | 2023-10-31 19:05:05.088 | [0.9984837] |
Batch Inference
Now that our smoke test is successful, let’s really give it some data. We have two inference files we can use:
data-1k.arrow: Contains 10,000 inferencesdata-25k.arrow: Contains 25,000 inferences
These inference inputs are Apache Arrow tables, which Wallaroo can ingest natively. These are binary files, and are faster to transmit because of their smaller size compared to JSON.
We’ll pipe the data-25k.arrow file through the pipeline deployment URL, and place the results in a file named response.df. Note that for larger batches of 1,000 inferences or more can be difficult to view in Jupyter Hub because of its size, so we’ll only display the first 5 results of the inference.
When retrieving the pipeline inference URL through an external SDK connection, the External Inference URL will be returned. This URL will function provided that the Enable external URL inference endpoints is enabled. For more information, see the Wallaroo Model Endpoints Guide.
pipeline.deploy()
| name | sdkquickpipeline |
|---|---|
| created | 2023-10-31 19:04:45.856204+00:00 |
| last_updated | 2023-10-31 19:05:06.169703+00:00 |
| deployed | True |
| arch | None |
| tags | |
| versions | 6b8f09e1-a424-4bbc-9cd6-8c5e5cf6169a, 6d23f8dc-2ce1-4bf6-88ec-ec2278534bbf, 5757db0a-1ae6-45f8-ae37-57fa3a37caab |
| steps | sdkquickmodel |
| published | False |
inference_url = pipeline._deployment._url()
inference_url
'https://doc-test.wallarooexample.ai/v1/api/pipelines/infer/sdkquickpipeline-17/sdkquickpipeline'
The API connection details can be retrieved through the Wallaroo client mlops() command. This will display the connection URL, bearer token, and other information. The bearer token is available for one hour before it expires.
For this example, the API connection details will be retrieved, then used to submit an inference request through the external inference URL retrieved earlier.
connection =wl.mlops().__dict__
token = connection['token']
token
'eyJhbGciOiJSUzI1NiIsInR5cCIgOiAiSldUIiwia2lkIiA6ICJTN1BMWjNzYUNVNmpTX1RyZ2FXak5SMkZWZXQ4OHhUNzJoNWQ5YVotUzdzIn0.eyJleHAiOjE2OTg3NzkxNDgsImlhdCI6MTY5ODc3OTA4OCwiYXV0aF90aW1lIjoxNjk4NzYxMjYxLCJqdGkiOiJmNTI5OTYzNC00NmI5LTQ3YjAtOTJlNy02ODRmNTVlMTg0MDQiLCJpc3MiOiJodHRwczovL2RvYy10ZXN0LmtleWNsb2FrLndhbGxhcm9vY29tbXVuaXR5Lm5pbmphL2F1dGgvcmVhbG1zL21hc3RlciIsImF1ZCI6WyJtYXN0ZXItcmVhbG0iLCJhY2NvdW50Il0sInN1YiI6IjEzOTRkMTQ0LTA2YTAtNGI2Yi1iMmRiLWQ3OTQ1ODEwZTM5YyIsInR5cCI6IkJlYXJlciIsImF6cCI6InNkay1jbGllbnQiLCJzZXNzaW9uX3N0YXRlIjoiODczYjFhYjUtNDgwMi00MmQ0LWJiMDctMWQ1ODNhNjFiZDE0IiwiYWNyIjoiMCIsInJlYWxtX2FjY2VzcyI6eyJyb2xlcyI6WyJkZWZhdWx0LXJvbGVzLW1hc3RlciIsIm9mZmxpbmVfYWNjZXNzIiwidW1hX2F1dGhvcml6YXRpb24iXX0sInJlc291cmNlX2FjY2VzcyI6eyJtYXN0ZXItcmVhbG0iOnsicm9sZXMiOlsibWFuYWdlLXVzZXJzIiwidmlldy11c2VycyIsInF1ZXJ5LWdyb3VwcyIsInF1ZXJ5LXVzZXJzIl19LCJhY2NvdW50Ijp7InJvbGVzIjpbIm1hbmFnZS1hY2NvdW50IiwibWFuYWdlLWFjY291bnQtbGlua3MiLCJ2aWV3LXByb2ZpbGUiXX19LCJzY29wZSI6ImVtYWlsIHByb2ZpbGUiLCJzaWQiOiI4NzNiMWFiNS00ODAyLTQyZDQtYmIwNy0xZDU4M2E2MWJkMTQiLCJlbWFpbF92ZXJpZmllZCI6ZmFsc2UsImh0dHBzOi8vaGFzdXJhLmlvL2p3dC9jbGFpbXMiOnsieC1oYXN1cmEtdXNlci1pZCI6IjEzOTRkMTQ0LTA2YTAtNGI2Yi1iMmRiLWQ3OTQ1ODEwZTM5YyIsIngtaGFzdXJhLWRlZmF1bHQtcm9sZSI6InVzZXIiLCJ4LWhhc3VyYS1hbGxvd2VkLXJvbGVzIjpbInVzZXIiXSwieC1oYXN1cmEtdXNlci1ncm91cHMiOiJ7fSJ9LCJuYW1lIjoiSm9obiBIYW5zYXJpY2siLCJwcmVmZXJyZWRfdXNlcm5hbWUiOiJqb2huLmh1bW1lbEB3YWxsYXJvby5haSIsImdpdmVuX25hbWUiOiJKb2huIiwiZmFtaWx5X25hbWUiOiJIYW5zYXJpY2siLCJlbWFpbCI6ImpvaG4uaHVtbWVsQHdhbGxhcm9vLmFpIn0.c71ggsoo6iQ0P-batJ6tPAYJYbzUkqIbqKRmX8ty3N3kqM6y-6RGHj-Aow1HVzSBw0mW3vrZckWkmu57i6tCXDmkYYXeOgst1XC0v5m_eXKPhw-oAh8dO4PPyHdssluvi2ZZ1Idf7erufqJrcyzkbbnPIMJ-bVazLtxuqSgwAbyU7FCbjm1x612msFmX9IbHfUfWNlG8dcrkp5Hy1sVFQCzaVnAQKrsPN9S5SaIvVcFFIOe55-ijzbVY2oAZK2bVSGmOzDm-3VZpRuQZtlIrHR88UwEXiL-bEw4nhq4_hvDMfhB__ehoZ4l3PkgeXJwIxcgkrrMHT8ed4RK7OpED2Q'
dataFile="./data/data_25k.arrow"
contentType="application/vnd.apache.arrow.file"
!curl -X POST {inference_url} -H "Authorization: Bearer {token}" -H "Content-Type:{contentType}" --data-binary @{dataFile} > curl_response.df
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
0 0 0 0 0 0 0 0 --:--:-- --:--:-- --:--:-- 0100 26.8M 100 22.0M 100 4874k 2292k 495k 0:00:09 0:00:09 --:--:-- 4856k100 4874k 0 1162k 0:00:04 0:00:04 --:--:-- 1164k
cc_data_from_file = pd.read_json('./curl_response.df', orient="records")
display(cc_data_from_file.head(5).loc[:, ["time","out"]])
| time | out | |
|---|---|---|
| 0 | 1698779110985 | {'banjori': [0.0015195821], 'corebot': [0.9829147500000001], 'cryptolocker': [0.012099549000000001], 'dircrypt': [4.7591115e-05], 'gozi': [2.0289428e-05], 'kraken': [0.00031977256999999996], 'locky': [0.011029262000000001], 'main': [0.997564], 'matsnu': [0.010341609], 'pykspa': [0.008038961], 'qakbot': [0.016155055], 'ramdo': [0.00623623], 'ramnit': [0.0009985747000000001], 'simda': [1.7933434e-26], 'suppobox': [1.388995e-27]} |
| 1 | 1698779110985 | {'banjori': [7.447196e-18], 'corebot': [6.7359245e-08], 'cryptolocker': [0.1708199], 'dircrypt': [1.3220122000000002e-09], 'gozi': [1.2758705999999999e-24], 'kraken': [0.22559543], 'locky': [0.34209849999999997], 'main': [0.99999994], 'matsnu': [0.3080186], 'pykspa': [0.1828217], 'qakbot': [3.802255e-11], 'ramdo': [0.2062254], 'ramnit': [0.15215826], 'simda': [1.1701982e-30], 'suppobox': [3.1514454e-38]} |
| 2 | 1698779110985 | {'banjori': [2.8598648999999997e-21], 'corebot': [9.302004000000001e-08], 'cryptolocker': [0.04445298], 'dircrypt': [6.1637580000000004e-09], 'gozi': [8.3496755e-23], 'kraken': [0.48234479999999996], 'locky': [0.26332903], 'main': [1.0], 'matsnu': [0.29800338], 'pykspa': [0.22361776], 'qakbot': [1.5238921e-06], 'ramdo': [0.32820392], 'ramnit': [0.029332489000000003], 'simda': [1.1995622e-31], 'suppobox': [0.0]} |
| 3 | 1698779110985 | {'banjori': [2.1387213e-15], 'corebot': [3.8817485e-10], 'cryptolocker': [0.045599736], 'dircrypt': [1.9090386e-07], 'gozi': [1.3140123e-25], 'kraken': [0.59542626], 'locky': [0.17374137], 'main': [0.9999996999999999], 'matsnu': [0.23151578], 'pykspa': [0.17591679999999998], 'qakbot': [1.0876152e-09], 'ramdo': [0.21832279999999998], 'ramnit': [0.0128692705], 'simda': [6.1588803e-28], 'suppobox': [1.4386237e-35]} |
| 4 | 1698779110985 | {'banjori': [9.453342500000001e-15], 'corebot': [7.091151e-10], 'cryptolocker': [0.049815163], 'dircrypt': [5.2914135e-09], 'gozi': [7.4132087e-19], 'kraken': [1.5504575e-13], 'locky': [1.079181e-15], 'main': [0.9999988999999999], 'matsnu': [1.5003075e-15], 'pykspa': [0.33075705], 'qakbot': [2.625885e-07], 'ramdo': [0.5036279], 'ramnit': [0.020393765], 'simda': [0.0], 'suppobox': [2.3292326e-38]} |
Undeploy Pipeline
When finished with our tests, we will undeploy the pipeline so we have the Kubernetes resources back for other tasks. Note that if the deployment variable is unchanged pipeline.deploy() will restart the inference engine in the same configuration as before.
pipeline.undeploy()
| name | sdkquickpipeline |
|---|---|
| created | 2023-10-31 19:04:45.856204+00:00 |
| last_updated | 2023-10-31 19:05:06.169703+00:00 |
| deployed | False |
| arch | None |
| tags | |
| versions | 6b8f09e1-a424-4bbc-9cd6-8c5e5cf6169a, 6d23f8dc-2ce1-4bf6-88ec-ec2278534bbf, 5757db0a-1ae6-45f8-ae37-57fa3a37caab |
| steps | sdkquickmodel |
| published | False |