Wallaroo SDK Essentials Guide: Pipelines
1 - Wallaroo SDK Essentials Guide: Anomaly Detection
Add Validations Method
Wallaroo provides validations to detect anomalous data from inference inputs and outputs.
Validations are added to a Wallaroo pipeline with the wallaroo.pipeline.add_validations method.
Adding validations to a pipeline takes the format:
pipeline.add_validations(
validation_name_01 = polars.Expr,
validation_name_02 = polars.Expr
...{additional validations}
)
Polars expressions are in the polars library version 0.18.5 Expression Python library.
Add Validations Method Parameters
wallaroo.pipeline.add_validations takes the following parameters.
| Field | Type | Description |
|---|---|---|
| {validation name} | Python variable | The name of the validation. This must match Python variable naming conventions. The {validation name} may not be count. Any validations submitted with the name count are ignored and an warning returned. Other validations part of the add_validations request are added to the pipeline. |
| {expression} | Polars Expression | The expression to validate the inference input or output data against. Must be in polars version 1.8.5 polars.Expr format. Expressions are typically set in the format below. |
Expressions are typically in the following format.
| Validation Section | Description | Example |
|---|---|---|
| Data to Evaluate | The data to evaluate from either an inference input or output. | polars.col(in/out.{column_name}).list.get({index}) Retrieve the data from the input or output at the column name at the list index. |
| Condition | The expression to perform on the data. If it returns True, then an anomaly is detected. | < 0.90 If the data is less than 0.90, return True. |
Add Validations Method Successful Returns
N/A: Nothing is returned on a successful add_validations request.
Add Validations Method Warning Returns
If any validations violate a warning condition, a warning is returned. Warning conditions include the following.
| Warning | Cause | Result |
|---|---|---|
count is not allowed. | A validation named count was included in the add_validations request. count is a reserved name. | All other validations other than count are added to the pipeline. |
Validation Examples
Common Data Selection Expressions
The following sample expressions demonstrate different methods of selecting which model input or output data to validate.
polars.col(in|out.{column_name}).list.get(index): Returns the index of a specific field. For example,pl.col("out.dense_1")returns from the inference the output the field dense_1, andlist.get(0)returns the first value in that list. Most output values from a Wallaroo inference result are a List of at least length 1, making this a common validation expression.polars.col(in.price_ranges).list.max(): Returns from the inference request the input field price_ranges the maximum value from a list of values.polars.col(out.price_ranges).mean()returns the mean for all values from the output fieldprice_ranges.
For example, to the following validation fraud detects values for the output of an inference request for the field dense_1 that are greater than 0.9, indicating a transaction has a high likelihood of fraud:
import polars as pl
pipeline.add_validations(
fraud = fraud=pl.col("out.dense_1").list.get(0) > 0.9
)
The following inference output shows the detected anomaly from an inference output:
| time | in.tensor | out.dense_1 | anomaly.count | anomaly.fraud | |
|---|---|---|---|---|---|
| 0 | 2024-02-02 16:05:42.152 | [1.0678324729, 18.1555563975, -1.6589551058, 5… | [0.981199] | 1 | True |
Detecting Input Anomalies
The following validation tests the inputs from sales figures for a week’s worth of sales:
| week | site_id | sales_count | |
|---|---|---|---|
| 0 | [28] | [site0001] | [1357, 1247, 350, 1437, 952, 757, 1831] |
To validate that any sales figure does not go below 500 units, the validation is:
import polars as pl
pipeline.add_validations(
minimum_sales=pl.col("in.sales_count").list.min() < 500
)
pipeline.deploy()
pipeline.infer_from_file(previous_week_sales)
For the input provided, the minimum_sales validation would return True, indicating an anomaly.
| time | out.predicted_sales | anomaly.count | anomaly.minimum_sales | |
|---|---|---|---|---|
| 0 | 2023-10-31 16:57:13.771 | [1527] | 1 | True |
Detecting Output Anomalies
The following validation detects an anomaly from a output.
fraud: Detects when an inference output for the fielddense_1at index0is greater than 0.9, indicating fraud.
# create the pipeline
sample_pipeline = wallaroo.client.build_pipeline("sample-pipeline")
# add a model step
sample_pipeline.add_model_step(ccfraud_model)
# add validations to the pipeline
sample_pipeline.add_validations(
fraud=pl.col("out.dense_1").list.get(0) > 0.9
)
sample_pipeline.deploy()
sample_pipeline.infer_from_file("dev_high_fraud.json")
| time | in.tensor | out.dense_1 | anomaly.count | anomaly.fraud | |
|---|---|---|---|---|---|
| 0 | 2024-02-02 16:05:42.152 | [1.0678324729, 18.1555563975, -1.6589551058, 5... | [0.981199] | 1 | True |
Multiple Validations
The following demonstrates multiple validations added to a pipeline at once and their results from inference requests. Two validations that track the same output field and index are applied to a pipeline:
fraud: Detects an anomaly when the inference output fielddense_1at index0value is greater than0.9.too_low: Detects an anomaly when the inference output fielddense_1at the index0value is lower than0.05.
sample_pipeline.add_validations(
fraud=pl.col("out.dense_1").list.get(0) > 0.9,
too_low=pl.col("out.dense_1").list.get(0) < 0.05
)
Two separate inferences where the output of the first is over 0.9 and the second is under 0.05 would be the following.
sample_pipeline.infer_from_file("high_fraud_example.json")
| time | in.tensor | out.dense_1 | anomaly.count | anomaly.fraud | anomaly.too_low | |
|---|---|---|---|---|---|---|
| 0 | 2024-02-02 16:05:42.152 | [1.0678324729, 18.1555563975, -1.6589551058, 5… | [0.981199] | 1 | True | False |
sample_pipeline.infer_from_file("low_fraud_example.json")
| time | in.tensor | out.dense_1 | anomaly.count | anomaly.fraud | anomaly.too_low | |
|---|---|---|---|---|---|---|
| 0 | 2024-02-02 16:05:38.452 | [1.0678324729, 0.2177810266, -1.7115145262, 0…. | [0.0014974177] | 1 | False | True |
The following example tracks two validations for a model that takes the previous week’s sales and projects the next week’s average sales with the field predicted_sales.
minimum_sales=pl.col("in.sales_count").list.min() < 500: The input fieldsales_countwith a range of values has any minimum value under500.average_sales_too_low=pl.col("out.predicted_sales").list.get(0) < 500: The output fieldpredicted_salesis less than500.
The following inputs return the following values. Note how the anomaly.count value changes by the number of validations that detect an anomaly.
Input 1:
In this example, one day had sales under 500, which triggers the minimum_sales validation to return True. The predicted sales are above 500, causing the average_sales_too_low validation to return False.
| week | site_id | sales_count | |
|---|---|---|---|
| 0 | [28] | [site0001] | [1357, 1247, 350, 1437, 952, 757, 1831] |
Output 1:
| time | out.predicted_sales | anomaly.count | anomaly.minimum_sales | anomaly.average_sales_too_low | |
|---|---|---|---|---|---|
| 0 | 2023-10-31 16:57:13.771 | [1527] | 1 | True | False |
Input 2:
In this example, multiple days have sales under 500, which triggers the minimum_sales validation to return True. The predicted average sales for the next week are above 500, causing the average_sales_too_low validation to return True.
| week | site_id | sales_count | |
|---|---|---|---|
| 0 | [29] | [site0001] | [497, 617, 350, 200, 150, 400, 110] |
Output 2:
| time | out.predicted_sales | anomaly.count | anomaly.minimum_sales | anomaly.average_sales_too_low | |
|---|---|---|---|---|---|
| 0 | 2023-10-31 16:57:13.771 | [325] | 2 | True | True |
Input 3:
In this example, no sales day figures are below 500, which triggers the minimum_sales validation to return False. The predicted sales for the next week is below 500, causing the average_sales_too_low validation to return True.
| week | site_id | sales_count | |
|---|---|---|---|
| 0 | [30] | [site0001] | [617, 525, 513, 517, 622, 757, 508] |
Output 3:
| time | out.predicted_sales | anomaly.count | anomaly.minimum_sales | anomaly.average_sales_too_low | |
|---|---|---|---|---|---|
| 0 | 2023-10-31 16:57:13.771 | [497] | 1 | False | True |
Compound Validations
The following combines multiple field checks into a single validation. For this, we will check for values of out.dense_1 that are between 0.05 and 0.9.
Each expression is separated by (). For example:
- Expression 1:
pl.col("out.dense_1").list.get(0) < 0.9 - Expression 2:
pl.col("out.dense_1").list.get(0) > 0.001 - Compound Expression:
(pl.col("out.dense_1").list.get(0) < 0.9) & (pl.col("out.dense_1").list.get(0) > 0.001)
sample_pipeline = sample_pipeline.add_validations(
in_between_2=(pl.col("out.dense_1").list.get(0) < 0.9) & (pl.col("out.dense_1").list.get(0) > 0.001)
)
results = sample_pipeline.infer_from_file("./data/cc_data_1k.df.json")
results.loc[results['anomaly.in_between_2'] == True]
| time | in.dense_input | out.dense_1 | anomaly.count | anomaly.fraud | anomaly.in_between_2 | anomaly.too_low | |
|---|---|---|---|---|---|---|---|
| 4 | 2024-02-08 17:48:49.305 | [0.5817662108, 0.097881551, 0.1546819424, 0.47... | [0.0010916889] | 1 | False | True | False |
| 7 | 2024-02-08 17:48:49.305 | [1.0379636346, -0.152987302, -1.0912561862, -0... | [0.0011294782] | 1 | False | True | False |
| 8 | 2024-02-08 17:48:49.305 | [0.1517283662, 0.6589966337, -0.3323713647, 0.... | [0.0018743575] | 1 | False | True | False |
| 9 | 2024-02-08 17:48:49.305 | [-0.1683100246, 0.7070470317, 0.1875234948, -0... | [0.0011520088] | 1 | False | True | False |
| 10 | 2024-02-08 17:48:49.305 | [0.6066235674, 0.0631839305, -0.0802961973, 0.... | [0.0016568303] | 1 | False | True | False |
| ... | ... | ... | ... | ... | ... | ... | ... |
| 982 | 2024-02-08 17:48:49.305 | [-0.0932906169, 0.2837744937, -0.061094265, 0.... | [0.0010192394] | 1 | False | True | False |
| 983 | 2024-02-08 17:48:49.305 | [0.0991458877, 0.5813808183, -0.3863062246, -0... | [0.0020678043] | 1 | False | True | False |
| 992 | 2024-02-08 17:48:49.305 | [1.0458395446, 0.2492453605, -1.5260449285, 0.... | [0.0013128221] | 1 | False | True | False |
| 998 | 2024-02-08 17:48:49.305 | [1.0046377125, 0.0343666504, -1.3512533246, 0.... | [0.0011070371] | 1 | False | True | False |
| 1000 | 2024-02-08 17:48:49.305 | [0.6118805301, 0.1726081102, 0.4310545502, 0.5... | [0.0012498498] | 1 | False | True | False |
2 - Wallaroo SDK Essentials Guide: Pipeline Management
Pipelines are the method of taking submitting data and processing that data through the models. Each pipeline can have one or more steps that submit the data from the previous step to the next one. Information can be submitted to a pipeline as a file, or through the pipeline’s URL.
A pipeline’s metrics can be viewed through the Wallaroo Dashboard Pipeline Details and Metrics page.
Pipeline Naming Requirements
Pipeline names map onto Kubernetes objects, and must be DNS compliant. Pipeline names must be ASCII alpha-numeric characters or dash (-) only. . and _ are not allowed.
Create a Pipeline
New pipelines are created in the current workspace.
NOTICE
Pipeline names are not forced to be unique. You can have 50 pipelines all named my-pipeline, which can cause confusion in determining which workspace to use.
It is recommended that organizations agree on a naming convention and select pipeline to use rather than creating a new one each time.
To create a new pipeline, use the Wallaroo Client build_pipeline("{Pipeline Name}") command.
The following example creates a new pipeline imdb-pipeline through a Wallaroo Client connection wl:
imdb_pipeline = wl.build_pipeline("imdb-pipeline")
imdb_pipeline.status()
{'status': 'Pipeline imdb-pipeline is not deployed'}
List All Pipelines
The Wallaroo Client method list_pipelines() lists all pipelines in a Wallaroo Instance.
List All Pipelines Parameters
N/A
List All Pipelines Returns
The following fields are returned from the list_pipeline method.
| Field | Type | Description |
|---|---|---|
| name | String | The assigned name of the pipeline. |
| created | DateTime | The date and time the pipeline was created. |
| last_updated | DateTime | The date and time the pipeline was updated. |
| deployed | Bool | Whether the pipeline is currently deployed or not. |
| tags | List | The list of tags applied to the pipeline. For more details, see Wallaroo SDK Essentials Guide: Tag Management. |
| versions | List | The list of pipeline versions, each version ID in UUID format. |
| steps | List | The list of pipeline steps. |
| published | Bool | If the pipeline was published to the Edge Deployment Registry. See Wallaroo SDK Essentials Guide: Pipeline Edge Publication for more details. |
List All Pipelines Example
wl.list_pipelines()
| name | created | last_updated | deployed | tags | versions | steps | published |
|---|---|---|---|---|---|---|---|
| edge-cv-retail | 2023-23-Aug 17:07:09 | 2023-23-Aug 17:07:38 | True | bf70eaf7-8c11-4b46-b751-916a43b1a555, 5eacb4cd-948f-4b82-9206-1eab30bd5488, 38b2bfc8-843d-4449-9935-ec82d9f86c49 | resnet-50 | True | |
| houseprice-estimator | 2023-22-Aug 20:39:35 | 2023-23-Aug 14:43:10 | True | a9fbe04e-4ec3-48fc-ac5f-998035c98f5a, 751aea9c-222d-4eac-8f4f-318fd4019db0, f42c0457-e4f3-4370-b152-0a220347de11 | house-price-prime | False | |
| biolabspipeline | 2023-22-Aug 16:07:20 | 2023-22-Aug 16:24:40 | False | 4c6dceb7-e692-4b8b-b615-4f7873eb020b, 59d0babe-bc1d-4dbb-959f-711c74f7b05d, ae834c0d-7a5b-4f87-9e2e-1f06f3cd25e7, 7c438222-28d8-4fca-9a70-eabee8a0fac5 | biolabsmodel | False | |
| biolabspipeline | 2023-22-Aug 16:03:33 | 2023-22-Aug 16:03:38 | False | 4e103a7d-cd4d-464b-b182-61d4041518a8, ec2a0fd6-21d4-4843-b7c3-65b1e5be1b85, 516f3848-be98-40d7-8564-a1e48eecb7a8 | biolabsmodel | False | |
| biolabspipelinegomj | 2023-22-Aug 15:11:12 | 2023-22-Aug 15:42:44 | False | 1dc9f89f-82aa-4a71-b21a-75dc8d5e4e51, 152d12f2-1200-46ad-ad04-60078c5aa284, 6ca59ffd-802e-4ad5-bd9a-35146b9fbda5, bdab08cc-3e99-4afc-b22d-657e33b76f29, 3c8feb0d-3124-4018-8dfa-06162156d51e | biolabsmodelgomj | False | |
| edge-pipeline | 2023-21-Aug 20:54:37 | 2023-22-Aug 19:06:46 | False | 2be013d9-a438-453c-a013-3fd8e6218394, a02b6af5-4235-42af-92c6-5ae678b35be4, e721ccad-11d8-4874-8388-4211c4957d18, d642e766-cffb-451f-b197-e058bedbdd5f, eb586aba-4908-4bff-84e1-bdeb1fa4b7d3, 2163d718-a5ea-41e3-b69f-095efa858462 | ccfraud | True | |
| p1 | 2023-21-Aug 19:38:44 | 2023-21-Aug 19:38:44 | (unknown) | 5f93e90a-e8d6-4e8a-8a1a-22eee80a3e13, 5f78247f-7bf9-445b-98a6-e146fb22b8e9 | True |
Select an Existing Pipeline
Rather than creating a new pipeline each time, an existing pipeline can be selected by using the list_pipelines() command and assigning one of the array members to a variable.
The following example sets the pipeline ccfraud-pipeline to the variable current_pipeline:
wl.list_pipelines()
[{'name': 'ccfraud-pipeline', 'create_time': datetime.datetime(2022, 4, 12, 17, 55, 41, 944976, tzinfo=tzutc()), 'definition': '[]'}]
current_pipeline = wl.list_pipelines()[0]
current_pipeline.status()
{'status': 'Running',
'details': None,
'engines': [{'ip': '10.244.5.4',
'name': 'engine-7fcc7df596-hvlxb',
'status': 'Running',
'reason': None,
'pipeline_statuses': {'pipelines': [{'id': 'ccfraud-pipeline',
'status': 'Running'}]},
'model_statuses': {'models': [{'name': 'ccfraud-model',
'version': '4624e8a8-1414-4408-8b40-e03da4b5cb68',
'sha': 'bc85ce596945f876256f41515c7501c399fd97ebcb9ab3dd41bf03f8937b4507',
'status': 'Running'}]}}],
'engine_lbs': [{'ip': '10.244.1.24',
'name': 'engine-lb-85846c64f8-mtq9p',
'status': 'Running',
'reason': None}]}
Pipeline Steps
Once a pipeline has been created, or during its creation process, a pipeline step can be added. The pipeline step refers to the model that will perform an inference off of the data submitted to it. Each time a step is added, it is added to the pipeline’s models array.
Pipeline steps are not saved until the pipeline is deployed. Until then, pipeline steps are stored in local memory as a potential pipeline configuration until the pipeline is deployed.
Add a Step to a Pipeline
A pipeline step is added through the pipeline add_model_step({Model}) command.
In the following example, two models uploaded to the workspace are added as pipeline step:
imdb_pipeline.add_model_step(embedder)
imdb_pipeline.add_model_step(smodel)
imdb_pipeline.status()
{'name': 'imdb-pipeline', 'create_time': datetime.datetime(2022, 3, 30, 21, 21, 31, 127756, tzinfo=tzutc()), 'definition': "[{'ModelInference': {'models': [{'name': 'embedder-o', 'version': '1c16d21d-fe4c-4081-98bc-65fefa465f7d', 'sha': 'd083fd87fa84451904f71ab8b9adfa88580beb92ca77c046800f79780a20b7e4'}]}}, {'ModelInference': {'models': [{'name': 'smodel-o', 'version': '8d311ba3-c336-48d3-99cd-85d95baa6f19', 'sha': '3473ea8700fbf1a1a8bfb112554a0dde8aab36758030dcde94a9357a83fd5650'}]}}]"}
Replace a Pipeline Step
The model specified in a pipeline step can be replaced with the pipeline method replace_with_model_step(index, model).
IMPORTANT NOTE
Pipeline steps can be replaced while a pipeline is deployed. This allows organizations to have pipelines deployed in a production environment and hot-swap out models for new versions without impacting performance or inferencing downtime.The following parameters are used for replacing a pipeline step:
| Parameter | Default Value | Purpose |
|---|---|---|
index | null | The pipeline step to be replaced. Pipeline steps follow array numbering, where the first step is 0, etc. |
model | null | The new model to be used in the pipeline step. |
In the following example, a deployed pipeline will have the initial model step replaced with a new one. A status of the pipeline will be displayed after deployment and after the pipeline swap to show the model has been replaced from ccfraudoriginal to ccfraudreplacement, each with their own versions.
pipeline.deploy()
pipeline.status()
{'status': 'Running',
'details': [],
'engines': [{'ip': '10.244.2.145',
'name': 'engine-75bfd7dc9d-7p9qk',
'status': 'Running',
'reason': None,
'details': [],
'pipeline_statuses': {'pipelines': [{'id': 'hotswappipeline',
'status': 'Running'}]},
'model_statuses': {'models': [{'name': 'ccfraudoriginal',
'version': '3a03dc94-716e-46bb-84c8-91bc99ceb2c3',
'sha': 'bc85ce596945f876256f41515c7501c399fd97ebcb9ab3dd41bf03f8937b4507',
'status': 'Running'}]}}],
'engine_lbs': [{'ip': '10.244.2.144',
'name': 'engine-lb-55dcdff64c-vf74s',
'status': 'Running',
'reason': None,
'details': []}],
'sidekicks': []}
pipeline.replace_with_model_step(0, replacement_model).deploy()
pipeline.status()
{'status': 'Running',
'details': [],
'engines': [{'ip': '10.244.2.153',
'name': 'engine-96486c95d-zfchr',
'status': 'Running',
'reason': None,
'details': [],
'pipeline_statuses': {'pipelines': [{'id': 'hotswappipeline',
'status': 'Running'}]},
'model_statuses': {'models': [{'name': 'ccfraudreplacement',
'version': '714efd19-5c83-42a8-aece-24b4ba530925',
'sha': 'bc85ce596945f876256f41515c7501c399fd97ebcb9ab3dd41bf03f8937b4507',
'status': 'Running'}]}}],
'engine_lbs': [{'ip': '10.244.2.154',
'name': 'engine-lb-55dcdff64c-9np9k',
'status': 'Running',
'reason': None,
'details': []}],
'sidekicks': []}
Pre and Post Processing Steps
A Pipeline Step can be more than models - they can also be pre processing and post processing steps. For example, this preprocessing step uses the following code:
import numpy
import pandas
import json
# add interaction terms for the model
def actual_preprocess(pdata):
pd = pdata.copy()
# convert boolean cust_known to 0/1
pd.cust_known = numpy.where(pd.cust_known, 1, 0)
# interact UnitPrice and cust_known
pd['UnitPriceXcust_known'] = pd.UnitPrice * pd.cust_known
return pd.loc[:, ['UnitPrice', 'cust_known', 'UnitPriceXcust_known']]
# If the data is a json string, call this wrapper instead
# Expected input:
# a dictionary with fields 'colnames', 'data'
# test that the code works here
def wallaroo_json(data):
obj = json.loads(data)
pdata = pandas.DataFrame(obj['query'],
columns=obj['colnames'])
pprocessed = actual_preprocess(pdata)
# return a dictionary, with the fields the model expect
return {
'tensor_fields': ['model_input'],
'model_input': pprocessed.to_numpy().tolist()
}
It is added as a Python module by uploading it as a model:
# load the preprocess module
module_pre = wl.upload_model("preprocess", "./preprocess.py").configure('python')
And then added to the pipeline as a step:
# now make a pipeline
demandcurve_pipeline = (wl.build_pipeline("demand-curve-pipeline")
.add_model_step(module_pre)
.add_model_step(demand_curve_model)
.add_model_step(module_post))
Remove a Pipeline Step
To remove a step from the pipeline, use the Pipeline remove_step(index) command, where the index is the array index for the pipeline’s steps.
In the following example the pipeline imdb_pipeline will have the step with the model smodel-o removed.
imdb_pipeline.status
<bound method Pipeline.status of {'name': 'imdb-pipeline', 'create_time': datetime.datetime(2022, 3, 30, 21, 21, 31, 127756, tzinfo=tzutc()), 'definition': "[{'ModelInference': {'models': [{'name': 'embedder-o', 'version': '1c16d21d-fe4c-4081-98bc-65fefa465f7d', 'sha': 'd083fd87fa84451904f71ab8b9adfa88580beb92ca77c046800f79780a20b7e4'}]}}, {'ModelInference': {'models': [{'name': 'smodel-o', 'version': '8d311ba3-c336-48d3-99cd-85d95baa6f19', 'sha': '3473ea8700fbf1a1a8bfb112554a0dde8aab36758030dcde94a9357a83fd5650'}]}}]"}>
imdb_pipeline.remove_step(1)
{'name': 'imdb-pipeline', 'create_time': datetime.datetime(2022, 3, 30, 21, 21, 31, 127756, tzinfo=tzutc()), 'definition': "[{'ModelInference': {'models': [{'name': 'embedder-o', 'version': '1c16d21d-fe4c-4081-98bc-65fefa465f7d', 'sha': 'd083fd87fa84451904f71ab8b9adfa88580beb92ca77c046800f79780a20b7e4'}]}}]"}
Clear All Pipeline Steps
The Pipeline clear() method removes all pipeline steps from a pipeline. Note that pipeline steps are not saved until the pipeline is deployed.
Pipeline Versions
Each time the pipeline steps are updated and the pipeline is either deployed or a pipeline version is manually created, a new pipeline version is created. This each Pipeline version includes the following:
| Field | Type | Description |
|---|---|---|
| name | String | The assigned name of the pipeline. |
| version | String | The UUID version identifier. |
| creation_time | DateTime | The date and time the pipeline was created. |
| last_updated_time | DateTime | The date and time the pipeline was updated. |
| deployed | Bool | Whether the pipeline is currently deployed or not. |
| tags | List | The list of tags applied to the pipeline. For more details, see Wallaroo SDK Essentials Guide: Tag Management. |
| steps | List | The list of pipeline steps. |
Create Pipeline Versions
Pipeline versions are saved automatically when the method wallaroo.pipeline.deploy(deployment_configuration) is called. Pipeline versions are stored manually with the wallaroo.pipeline.create_versions() method, which stores the current pipeline steps and other details stored in the local SDK session into the Wallaroo pipeline database.
The following example demonstrates setting a model as a pipeline step, then saving the pipeline configuration in the local SDK session to Wallaroo as a new pipeline version.
display("Current pipeline.")
display(pipeline) # display the current pipeline
pipeline.clear() #clear the current steps
pipeline.add_model_step(houseprice_rf_model_version) #set a different model as a pipeline step
new_pipeline_version = pipeline.create_version()
display("New pipeline version.")
display(new_pipeline_version)
Current pipeline.
| name | houseprice-estimator |
| version | 342f4605-9467-460e-866f-1b74e6e863d1 |
| creation_time | 2023-11-Sep 21:27:00 |
| last_updated_time | 2023-11-Sep 21:27:00 |
| deployed | False |
| tags | |
| steps | house-price-prime |
New pipeline version.
| name | houseprice-estimator |
| version | 937fd68d-2eaa-4b30-80b2-e66ea7be3086 |
| creation_time | 2023-26-Sep 16:36:13 |
| last_updated_time | 2023-26-Sep 16:36:13 |
| deployed | False |
| tags | |
| steps | house-price-rf-model |
List Pipeline Versions
Pipeline versions are retrieved with the method wallaroo.pipeline.versions() and returns a List of the versions of the pipelines listed in descending creation order, with the most recent version stored in position 0.
The following example demonstrates retrieving the list of pipeline version, then storing a specific version to a variable and displaying its version id and other details.
for pipeline_version in pipeline.versions():
display(pipeline_version)
pipeline_version_01 = pipeline.versions()[7]
display(pipeline_version_01.name())
display(pipeline_version_01)
| name | houseprice-estimator |
| version | 342f4605-9467-460e-866f-1b74e6e863d1 |
| creation_time | 2023-11-Sep 21:27:00 |
| last_updated_time | 2023-11-Sep 21:27:00 |
| deployed | False |
| tags | |
| steps | house-price-prime |
| name | houseprice-estimator |
| — | — |
| version | 47a5fb9f-2456-4132-abea-88a3147c4446 |
| creation_time | 2023-11-Sep 21:15:00 |
| last_updated_time | 2023-11-Sep 21:15:00 |
| deployed | False |
| tags | |
| steps | house-price-prime Check Check Check |
…
‘92f2b4f3-494b-4d69-895f-9e767ac1869d’
| name | houseprice-estimator |
| version | 92f2b4f3-494b-4d69-895f-9e767ac1869d |
| creation_time | 2023-11-Sep 20:49:17 |
| last_updated_time | 2023-11-Sep 20:49:17 |
| deployed | False |
| tags | |
| steps | house-price-rf-model |
Deploy a Pipeline
When a pipeline step is added or removed, the pipeline must be deployed through the pipeline deploy(deployment_config). This allocates resources to the pipeline from the Kubernetes environment and make it available to submit information to perform inferences. For full details on pipeline deployment configurations, see Wallaroo SDK Essentials Guide: Pipeline Deployment Configuration.
Pipelines do not need to be undeployed to deploy new pipeline versions or pipeline deployment configurations. For example, the following pipeline is deployed, new pipeline steps are set, and the pipeline deploy command is issues again. This creates a new version of the pipeline and updates the deployed pipeline with the new configuration.
# clear all steps
pipeline.clear()
# set modelA as the step
pipeline.add_model_step(modelA)
# deploy the pipeline - the version is saved and the resources allocated to the pipeline
pipeline.deploy()
# clear the steps - this configuration is only stored in the local SDK session until the deploy or create_version command is given
pipeline.clear()
# set modelB as the step
pipeline.add_model_step(modelB)
# deploy the pipeline - the pipeline configuration is saved and the pipeline deployment updated without significant downtime
pipeline.deploy()
Deploy Current Pipeline Version
By default, deploying a Wallaroo pipeline will deploy the most current version. For example:
sample_pipeline = wl.build_pipeline("test-pipeline")
sample_pipeline.add_model_step(model)
sample_pipeline.deploy()
sample_pipeline.status()
{'status': 'Running',
'details': None,
'engines': [{'ip': '10.12.1.65',
'name': 'engine-778b65459-f9mt5',
'status': 'Running',
'reason': None,
'pipeline_statuses': {'pipelines': [{'id': 'imdb-pipeline',
'status': 'Running'}]},
'model_statuses': {'models': [{'name': 'embedder-o',
'version': '1c16d21d-fe4c-4081-98bc-65fefa465f7d',
'sha': 'd083fd87fa84451904f71ab8b9adfa88580beb92ca77c046800f79780a20b7e4',
'status': 'Running'},
{'name': 'smodel-o',
'version': '8d311ba3-c336-48d3-99cd-85d95baa6f19',
'sha': '3473ea8700fbf1a1a8bfb112554a0dde8aab36758030dcde94a9357a83fd5650',
'status': 'Running'}]}}],
'engine_lbs': [{'ip': '10.12.1.66',
'name': 'engine-lb-85846c64f8-ggg2t',
'status': 'Running',
'reason': None}]}
Deploy Previous Pipeline Version
Pipeline versions are deployed with the method wallaroo.pipeline_variant.deploy(deployment_name, model_configs, config: Optional[wallaroo.deployment_config.DeploymentConfig]). Note that the deployment_name and model_configs are required. The model_configs are retrieved with the wallaroo.pipeline_variant.model_configs() method.
The following demonstrates retrieving a previous version of a pipeline, deploying it, and retrieving the deployment status.
pipeline_version = pipeline.versions()[7]
display(pipeline_version.name())
display(pipeline_version)
pipeline_version.deploy("houseprice-estimator", pipeline_version.model_configs())
display(pipeline.status())
| name | houseprice-estimator |
| version | 92f2b4f3-494b-4d69-895f-9e767ac1869d |
| creation_time | 2023-11-Sep 20:49:17 |
| last_updated_time | 2023-11-Sep 20:49:17 |
| deployed | False |
| tags | |
| steps | house-price-rf-model |
{'status': 'Running',
'details': [],
'engines': [{'ip': '10.244.3.211',
'name': 'engine-578dc7cdcf-qkx5n',
'status': 'Running',
'reason': None,
'details': [],
'pipeline_statuses': {'pipelines': [{'id': 'houseprice-estimator',
'status': 'Running'}]},
'model_statuses': {'models': [{'name': 'house-price-rf-model',
'version': '616c2306-bf93-417b-9656-37bee6f14379',
'sha': 'e22a0831aafd9917f3cc87a15ed267797f80e2afa12ad7d8810ca58f173b8cc6',
'status': 'Running'}]}}],
'engine_lbs': [{'ip': '10.244.4.243',
'name': 'engine-lb-584f54c899-2rtvg',
'status': 'Running',
'reason': None,
'details': []}],
'sidekicks': []}
Pipeline Status
Once complete, the pipeline status() command will show 'status':'Running'.
Pipeline deployments can be modified to enable auto-scaling to allow pipelines to allocate more or fewer resources based on need by setting the pipeline’s This will then be applied to the deployment of the pipelineccfraudPipelineby specifying it'sdeployment_config` optional parameter. If this optional parameter is not passed, then the deployment will defer to default values. For more information, see Manage Pipeline Deployment Configuration.
In the following example, the pipeline imdb-pipeline that contains two steps will be deployed with default deployment configuration:
imdb_pipeline.status
<bound method Pipeline.status of {'name': 'imdb-pipeline', 'create_time': datetime.datetime(2022, 3, 30, 21, 21, 31, 127756, tzinfo=tzutc()), 'definition': "[{'ModelInference': {'models': [{'name': 'embedder-o', 'version': '1c16d21d-fe4c-4081-98bc-65fefa465f7d', 'sha': 'd083fd87fa84451904f71ab8b9adfa88580beb92ca77c046800f79780a20b7e4'}]}}, {'ModelInference': {'models': [{'name': 'smodel-o', 'version': '8d311ba3-c336-48d3-99cd-85d95baa6f19', 'sha': '3473ea8700fbf1a1a8bfb112554a0dde8aab36758030dcde94a9357a83fd5650'}]}}]"}>
imdb_pipeline.deploy()
Waiting for deployment - this will take up to 45s ...... ok
imdb_pipeline.status()
{'status': 'Running',
'details': None,
'engines': [{'ip': '10.12.1.65',
'name': 'engine-778b65459-f9mt5',
'status': 'Running',
'reason': None,
'pipeline_statuses': {'pipelines': [{'id': 'imdb-pipeline',
'status': 'Running'}]},
'model_statuses': {'models': [{'name': 'embedder-o',
'version': '1c16d21d-fe4c-4081-98bc-65fefa465f7d',
'sha': 'd083fd87fa84451904f71ab8b9adfa88580beb92ca77c046800f79780a20b7e4',
'status': 'Running'},
{'name': 'smodel-o',
'version': '8d311ba3-c336-48d3-99cd-85d95baa6f19',
'sha': '3473ea8700fbf1a1a8bfb112554a0dde8aab36758030dcde94a9357a83fd5650',
'status': 'Running'}]}}],
'engine_lbs': [{'ip': '10.12.1.66',
'name': 'engine-lb-85846c64f8-ggg2t',
'status': 'Running',
'reason': None}]}
Manage Pipeline Deployment Configuration
For full details on pipeline deployment configurations, see Wallaroo SDK Essentials Guide: Pipeline Deployment Configuration.
Troubleshooting Pipeline Deployment
If you deploy more pipelines than your environment can handle, or if you deploy more pipelines than your license allows, you may see an error like the following:
LimitError: You have reached a license limit in your Wallaroo instance. In order to add additional resources, you can remove some of your existing resources. If you have any questions contact us at community@wallaroo.ai: MAX_PIPELINES_LIMIT_EXCEEDED
Undeploy any unnecessary pipelines either through the SDK or through the Wallaroo Pipeline Dashboard, then attempt to redeploy the pipeline in question again.
Undeploy a Pipeline
When a pipeline is not currently needed, it can be undeployed and its resources turned back to the Kubernetes environment. To undeploy a pipeline, use the pipeline undeploy() command.
In this example, the aloha_pipeline will be undeployed:
aloha_pipeline.undeploy()
{'name': 'aloha-test-demo', 'create_time': datetime.datetime(2022, 3, 29, 20, 34, 3, 960957, tzinfo=tzutc()), 'definition': "[{'ModelInference': {'models': [{'name': 'aloha-2', 'version': 'a8e8abdc-c22f-416c-a13c-5fe162357430', 'sha': 'fd998cd5e4964bbbb4f8d29d245a8ac67df81b62be767afbceb96a03d1a01520'}]}}]"}
Get Pipeline Status
The pipeline status() command shows the current status, models, and other information on a pipeline.
The following example shows the pipeline imdb_pipeline status before and after it is deployed:
imdb_pipeline.status
<bound method Pipeline.status of {'name': 'imdb-pipeline', 'create_time': datetime.datetime(2022, 3, 30, 21, 21, 31, 127756, tzinfo=tzutc()), 'definition': "[{'ModelInference': {'models': [{'name': 'embedder-o', 'version': '1c16d21d-fe4c-4081-98bc-65fefa465f7d', 'sha': 'd083fd87fa84451904f71ab8b9adfa88580beb92ca77c046800f79780a20b7e4'}]}}, {'ModelInference': {'models': [{'name': 'smodel-o', 'version': '8d311ba3-c336-48d3-99cd-85d95baa6f19', 'sha': '3473ea8700fbf1a1a8bfb112554a0dde8aab36758030dcde94a9357a83fd5650'}]}}]"}>
imdb_pipeline.deploy()
Waiting for deployment - this will take up to 45s ...... ok
imdb_pipeline.status()
{'status': 'Running',
'details': None,
'engines': [{'ip': '10.12.1.65',
'name': 'engine-778b65459-f9mt5',
'status': 'Running',
'reason': None,
'pipeline_statuses': {'pipelines': [{'id': 'imdb-pipeline',
'status': 'Running'}]},
'model_statuses': {'models': [{'name': 'embedder-o',
'version': '1c16d21d-fe4c-4081-98bc-65fefa465f7d',
'sha': 'd083fd87fa84451904f71ab8b9adfa88580beb92ca77c046800f79780a20b7e4',
'status': 'Running'},
{'name': 'smodel-o',
'version': '8d311ba3-c336-48d3-99cd-85d95baa6f19',
'sha': '3473ea8700fbf1a1a8bfb112554a0dde8aab36758030dcde94a9357a83fd5650',
'status': 'Running'}]}}],
'engine_lbs': [{'ip': '10.12.1.66',
'name': 'engine-lb-85846c64f8-ggg2t',
'status': 'Running',
'reason': None}]}
Anomaly Testing
Anomaly detection allows organizations to set validation parameters. A validation is added to a pipeline to test data based on a specific expression. If the expression is returned as False, this is detected as an anomaly and added to the InferenceResult object’s check_failures array and the pipeline logs.
Anomaly detection consists of the following steps:
- Set a validation: Add a validation to a pipeline that, when returned
False, adds an entry to theInferenceResultobject’scheck_failuresattribute with the expression that caused the failure. - Display anomalies: Anomalies detected through a Pipeline’s
validationattribute are displayed either through theInferenceResultobject’scheck_failuresattribute, or through the pipeline’s logs.
Set A Validation
Validations are added to a pipeline through the wallaroo.pipeline add_validation method. The following parameters are required:
| Parameter | Type | Description |
|---|---|---|
| name | String (Required) | The name of the validation |
| validation | wallaroo.checks.Expression (Required) | The validation expression that adds the result InferenceResult object’s check_failures attribute when expression result is False. The validation checks the expression against both the data value and the data type. |
Validation expressions take the format value Expression, with the expression being in the form of a :py:Expression:. For example, if the model housing_model is part of the pipeline steps, then a validation expression may be housing_model.outputs[0][0] < 100.0: If the output of the housing_model inference is less than 100, then the validation is True and no action is taken. Any values over 100, the validation is False which triggers adding the anomaly to the InferenceResult object’s check_failures attribute.
IMPORTANT NOTE
Validations test for the expression value and the data type. For example: 100 is considered an integer data type, while 100.0 is considered a float data type.
If the data type is an integer, and the value the expression is testing against is a float, then the validation check will always be triggered. Verify that the data type is properly set in the validation expression to ensure correct validation check results.
Note that multiple validations can be created to allow for multiple anomalies detection.
In the following example, a validation is added to the pipeline to detect housing prices that are below 100 (represented as $100 million), and trigger an anomaly for values above that level. When an inference is performed that triggers a validation failure, the results are displayed in the InferenceResult object’s check_failures attribute.
p = wl.build_pipeline('anomaly-housing-pipeline')
p = p.add_model_step(housing_model)
p = p.add_validation('price too high', housing_model.outputs[0][0] < 100.0)
pipeline = p.deploy()
test_input = {"dense_16_input":[[0.02675675, 0.0, 0.02677953, 0.0, 0.0010046, 0.00951931, 0.14795322, 0.0027145, 2, 0.98536841, 0.02988655, 0.04031725, 0.04298041]]}
response_trigger = pipeline.infer(test_input)
print("\n")
print(response_trigger)
[InferenceResult({'check_failures': [{'False': {'expr': 'anomaly-housing.outputs[0][0] < 100'}}],
'elapsed': 15110549,
'model_name': 'anomaly-housing',
'model_version': 'c3cf1577-6666-48d3-b85c-5d4a6e6567ea',
'original_data': {'dense_16_input': [[0.02675675,
0.0,
0.02677953,
0.0,
0.0010046,
0.00951931,
0.14795322,
0.0027145,
2,
0.98536841,
0.02988655,
0.04031725,
0.04298041]]},
'outputs': [{'Float': {'data': [350.46990966796875], 'dim': [1, 1], 'v': 1}}],
'pipeline_name': 'anomaly-housing-model',
'time': 1651257043312})]
Display Anomalies
Anomalies detected through a Pipeline’s validation attribute are displayed either through the InferenceResult object’s check_failures attribute, or through the pipeline’s logs.
To display an anomaly through the InferenceResult object, display the check_failures attribute.
In the following example, the an InferenceResult where the validation failed will display the failure in the check_failures attribute:
test_input = {"dense_16_input":[[0.02675675, 0.0, 0.02677953, 0.0, 0.0010046, 0.00951931, 0.14795322, 0.0027145, 2, 0.98536841, 0.02988655, 0.04031725, 0.04298041]]}
response_trigger = pipeline.infer(test_input)
print("\n")
print(response_trigger)
[InferenceResult({'check_failures': [{'False': {'expr': 'anomaly-housing-model.outputs[0][0] < '
'100'}}],
'elapsed': 12196540,
'model_name': 'anomaly-housing-model',
'model_version': 'a3b1c29f-c827-4aad-817d-485de464d59b',
'original_data': {'dense_16_input': [[0.02675675,
0.0,
0.02677953,
0.0,
0.0010046,
0.00951931,
0.14795322,
0.0027145,
2,
0.98536841,
0.02988655,
0.04031725,
0.04298041]]},
'outputs': [{'Float': {'data': [350.46990966796875], 'dim': [1, 1], 'v': 1}}],
'pipeline_name': 'anomaly-housing-pipeline',
'shadow_data': {},
'time': 1667416852255})]
The other methods is to use the pipeline.logs() method with the parameter valid=False, isolating the logs where the validation was returned as False.
In this example, a set of logs where the validation returned as False will be displayed:
pipeline.logs(valid=False)
| Timestamp | Output | Input | Anomalies |
|---|---|---|---|
| 2022-02-Nov 19:20:52 | [array([[350.46990967]])] | [[0.02675675, 0.0, 0.02677953, 0.0, 0.0010046, 0.00951931, 0.14795322, 0.0027145, 2, 0.98536841, 0.02988655, 0.04031725, 0.04298041]] | 1 |
A/B Testing
A/B testing is a method that provides the ability to test competing ML models for performance, accuracy or other useful benchmarks. Different models are added to the same pipeline steps as follows:
- Control or Champion model: The model currently used for inferences.
- Challenger model(s): The model or set of models compared to the challenger model.
A/B testing splits a portion of the inference requests between the champion model and the one or more challengers through the add_random_split method. This method splits the inferences submitted to the model through a randomly weighted step.
Each model receives inputs that are approximately proportional to the weight it is assigned. For example, with two models having weights 1 and 1, each will receive roughly equal amounts of inference inputs. If the weights were changed to 1 and 2, the models would receive roughly 33% and 66% respectively instead.
When choosing the model to use, a random number between 0.0 and 1.0 is generated. The weighted inputs are mapped to that range, and the random input is then used to select the model to use. For example, for the two-models equal-weight case, a random key of 0.4 would route to the first model, 0.6 would route to the second.
Add Random Split
A random split step can be added to a pipeline through the add_random_split method.
The following parameters are used when adding a random split step to a pipeline:
| Parameter | Type | Description |
|---|---|---|
| champion_weight | Float (Required) | The weight for the champion model. |
| champion_model | Wallaroo.Model (Required) | The uploaded champion model. |
| challenger_weight | Float (Required) | The weight of the challenger model. |
| challenger_model | Wallaroo.Model (Required) | The uploaded challenger model. |
| hash_key | String(Optional) | A key used instead of a random number for model selection. This must be between 0.0 and 1.0. |
Note that multiple challenger models with different weights can be added as the random split step.
add_random_split([(champion_weight, champion_model), (challenger_weight, challenger_model), (challenger_weight2, challenger_model2),...], hash_key)
In this example, a pipeline will be built with a 2:1 weighted ratio between the champion and a single challenger model.
pipeline = (wl.build_pipeline("randomsplitpipeline-demo")
.add_random_split([(2, control), (1, challenger)]))
The results for a series of single are displayed to show the random weighted split between the two models in action:
results = []
results.append(experiment_pipeline.infer_from_file("data/data-1.json"))
results.append(experiment_pipeline.infer_from_file("data/data-1.json"))
results.append(experiment_pipeline.infer_from_file("data/data-1.json"))
results.append(experiment_pipeline.infer_from_file("data/data-1.json"))
results.append(experiment_pipeline.infer_from_file("data/data-1.json"))
for result in results:
print(result[0].model())
print(result[0].data())
('aloha-control', 'ff81f634-8fb4-4a62-b873-93b02eb86ab4')
[array([[0.00151959]]), array([[0.98291481]]), array([[0.01209957]]), array([[4.75912966e-05]]), array([[2.02893716e-05]]), array([[0.00031977]]), array([[0.01102928]]), array([[0.99756402]]), array([[0.01034162]]), array([[0.00803896]]), array([[0.01615506]]), array([[0.00623623]]), array([[0.00099858]]), array([[1.79337805e-26]]), array([[1.38899512e-27]])]
('aloha-control', 'ff81f634-8fb4-4a62-b873-93b02eb86ab4')
[array([[0.00151959]]), array([[0.98291481]]), array([[0.01209957]]), array([[4.75912966e-05]]), array([[2.02893716e-05]]), array([[0.00031977]]), array([[0.01102928]]), array([[0.99756402]]), array([[0.01034162]]), array([[0.00803896]]), array([[0.01615506]]), array([[0.00623623]]), array([[0.00099858]]), array([[1.79337805e-26]]), array([[1.38899512e-27]])]
('aloha-challenger', '87fdfe08-170e-4231-a0b9-543728d6fc57')
[array([[0.00151959]]), array([[0.98291481]]), array([[0.01209957]]), array([[4.75912966e-05]]), array([[2.02893716e-05]]), array([[0.00031977]]), array([[0.01102928]]), array([[0.99756402]]), array([[0.01034162]]), array([[0.00803896]]), array([[0.01615506]]), array([[0.00623623]]), array([[0.00099858]]), array([[1.79337805e-26]]), array([[1.38899512e-27]])]
('aloha-challenger', '87fdfe08-170e-4231-a0b9-543728d6fc57')
[array([[0.00151959]]), array([[0.98291481]]), array([[0.01209957]]), array([[4.75912966e-05]]), array([[2.02893716e-05]]), array([[0.00031977]]), array([[0.01102928]]), array([[0.99756402]]), array([[0.01034162]]), array([[0.00803896]]), array([[0.01615506]]), array([[0.00623623]]), array([[0.00099858]]), array([[1.79337805e-26]]), array([[1.38899512e-27]])]
('aloha-challenger', '87fdfe08-170e-4231-a0b9-543728d6fc57')
[array([[0.00151959]]), array([[0.98291481]]), array([[0.01209957]]), array([[4.75912966e-05]]), array([[2.02893716e-05]]), array([[0.00031977]]), array([[0.01102928]]), array([[0.99756402]]), array([[0.01034162]]), array([[0.00803896]]), array([[0.01615506]]), array([[0.00623623]]), array([[0.00099858]]), array([[1.79337805e-26]]), array([[1.38899512e-27]])]
Replace With Random Split
If a pipeline already had steps as detailed in Add a Step to a Pipeline, this step can be replaced with a random split with the replace_with_random_split method.
The following parameters are used when adding a random split step to a pipeline:
| Parameter | Type | Description |
|---|---|---|
| index | Integer (Required) | The pipeline step being replaced. |
| champion_weight | Float (Required) | The weight for the champion model. |
| champion_model | Wallaroo.Model (Required) | The uploaded champion model. |
| **challenger_weight | Float (Required) | The weight of the challenger model. |
| challenger_model | Wallaroo.Model (Required) | The uploaded challenger model. |
| hash_key | String(Optional) | A key used instead of a random number for model selection. This must be between 0.0 and 1.0. |
Note that one or more challenger models can be added for the random split step:
replace_with_random_split(index, [(champion_weight, champion_model), (challenger_weight, challenger_model)], (challenger_weight2, challenger_model2),...], hash_key)
A/B Testing Logs
A/B Testing logs entries contain the model used for the inferences in the column out._model_split.
logs = experiment_pipeline.logs(limit=5)
display(logs.loc[:,['time', 'out._model_split', 'out.main']])
| time | out._model_split | out.main | |
|---|---|---|---|
| 0 | 2023-03-03 19:08:35.653 | [{“name”:“aloha-control”,“version”:“89389786-0c17-4214-938c-aa22dd28359f”,“sha”:“fd998cd5e4964bbbb4f8d29d245a8ac67df81b62be767afbceb96a03d1a01520”}] | [0.9999754] |
| 1 | 2023-03-03 19:08:35.702 | [{“name”:“aloha-challenger”,“version”:“3acd3835-be72-42c4-bcae-84368f416998”,“sha”:“223d26869d24976942f53ccb40b432e8b7c39f9ffcf1f719f3929d7595bceaf3”}] | [0.9999727] |
| 2 | 2023-03-03 19:08:35.753 | [{“name”:“aloha-challenger”,“version”:“3acd3835-be72-42c4-bcae-84368f416998”,“sha”:“223d26869d24976942f53ccb40b432e8b7c39f9ffcf1f719f3929d7595bceaf3”}] | [0.6606688] |
| 3 | 2023-03-03 19:08:35.799 | [{“name”:“aloha-control”,“version”:“89389786-0c17-4214-938c-aa22dd28359f”,“sha”:“fd998cd5e4964bbbb4f8d29d245a8ac67df81b62be767afbceb96a03d1a01520”}] | [0.9998954] |
| 4 | 2023-03-03 19:08:35.846 | [{“name”:“aloha-control”,“version”:“89389786-0c17-4214-938c-aa22dd28359f”,“sha”:“fd998cd5e4964bbbb4f8d29d245a8ac67df81b62be767afbceb96a03d1a01520”}] | [0.99999803] |
Pipeline Shadow Deployments
Wallaroo provides a method of testing the same data against two different models or sets of models at the same time through shadow deployments otherwise known as parallel deployments or A/B test. This allows data to be submitted to a pipeline with inferences running on several different sets of models. Typically this is performed on a model that is known to provide accurate results - the champion - and a model or set of models that is being tested to see if it provides more accurate or faster responses depending on the criteria known as the challenger(s). Multiple challengers can be tested against a single champion to determine which is “better” based on the organization’s criteria.
As described in the Wallaroo blog post The What, Why, and How of Model A/B Testing:
In data science, A/B tests can also be used to choose between two models in production, by measuring which model performs better in the real world. In this formulation, the control is often an existing model that is currently in production, sometimes called the champion. The treatment is a new model being considered to replace the old one. This new model is sometimes called the challenger….
Keep in mind that in machine learning, the terms experiments and trials also often refer to the process of finding a training configuration that works best for the problem at hand (this is sometimes called hyperparameter optimization).
When a shadow deployment is created, only the inference from the champion is returned in the InferenceResult Object data, while the result data for the shadow deployments is stored in the InferenceResult Object shadow_data.
Create Shadow Deployment
Create a parallel or shadow deployment for a pipeline with the pipeline.add_shadow_deploy(champion, challengers[]) method, where the champion is a Wallaroo Model object, and challengers[] is one or more Wallaroo Model objects.
Each inference request sent to the pipeline is sent to all the models. The prediction from the champion is returned by the pipeline, while the predictions from the challengers are not part of the standard output, but are kept stored in the shadow_data attribute and in the logs for later comparison.
In this example, a shadow deployment is created with the champion versus two challenger models.
champion = wl.upload_model(champion_model_name, champion_model_file).configure()
model2 = wl.upload_model(shadow_model_01_name, shadow_model_01_file).configure()
model3 = wl.upload_model(shadow_model_02_name, shadow_model_02_file).configure()
pipeline.add_shadow_deploy(champion, [model2, model3])
pipeline.deploy()
| name | cc-shadow |
| created | 2022-08-04 20:06:55.102203+00:00 |
| last_updated | 2022-08-04 20:37:28.785947+00:00 |
| deployed | True |
| tags | |
| steps | ccfraud-lstm |
An alternate method is with the pipeline.replace_with_shadow_deploy(index, champion, challengers[]) method, where the index is the pipeline step to replace.
Shadow Deploy Outputs
Model outputs are listed by column based on the model’s outputs. The output data is set by the term out, followed by the name of the model. For the default model, this is out.{variable_name}, while the shadow deployed models are in the format out_{model name}.variable, where {model name} is the name of the shadow deployed model.
sample_data_file = './smoke_test.df.json'
response = pipeline.infer_from_file(sample_data_file)
| time | in.tensor | out.dense_1 | check_failures | out_ccfraudrf.variable | out_ccfraudxgb.variable | |
|---|---|---|---|---|---|---|
| 0 | 2023-03-03 17:35:28.859 | [1.0678324729, 0.2177810266, -1.7115145262, 0.682285721, 1.0138553067, -0.4335000013, 0.7395859437, -0.2882839595, -0.447262688, 0.5146124988, 0.3791316964, 0.5190619748, -0.4904593222, 1.1656456469, -0.9776307444, -0.6322198963, -0.6891477694, 0.1783317857, 0.1397992467, -0.3554220649, 0.4394217877, 1.4588397512, -0.3886829615, 0.4353492889, 1.7420053483, -0.4434654615, -0.1515747891, -0.2668451725, -1.4549617756] | [0.0014974177] | 0 | [1.0] | [0.0005066991] |
Retrieve Shadow Deployment Logs
Shadow deploy results are part of the Pipeline.logs() method. The output data is set by the term out, followed by the name of the model. For the default model, this is out.dense_1, while the shadow deployed models are in the format out_{model name}.variable, where {model name} is the name of the shadow deployed model.
logs = pipeline.logs()
display(logs)
| time | in.tensor | out.dense_1 | check_failures | out_ccfraudrf.variable | out_ccfraudxgb.variable | |
|---|---|---|---|---|---|---|
| 0 | 2023-03-03 17:35:28.859 | [1.0678324729, 0.2177810266, -1.7115145262, 0.682285721, 1.0138553067, -0.4335000013, 0.7395859437, -0.2882839595, -0.447262688, 0.5146124988, 0.3791316964, 0.5190619748, -0.4904593222, 1.1656456469, -0.9776307444, -0.6322198963, -0.6891477694, 0.1783317857, 0.1397992467, -0.3554220649, 0.4394217877, 1.4588397512, -0.3886829615, 0.4353492889, 1.7420053483, -0.4434654615, -0.1515747891, -0.2668451725, -1.4549617756] | [0.0014974177] | 0 | [1.0] | [0.0005066991] |
Get Pipeline URL Endpoint
The Pipeline URL Endpoint or the Pipeline Deploy URL is used to submit data to a pipeline to use for an inference. This is done through the pipeline _deployment._url() method.
In this example, the pipeline URL endpoint for the pipeline ccfraud_pipeline will be displayed:
ccfraud_pipeline._deployment._url()
'http://engine-lb.ccfraud-pipeline-1:29502/pipelines/ccfraud-pipeline'
3 - Wallaroo SDK Essentials Guide: Pipeline Deployment Configuration
Pipeline deployments configurations allow tailoring of a pipeline’s resources to match an organization’s and model’s requirements. Pipelines may require more memory, CPU cores, or GPUs to run to run all its steps efficiently. Pipeline deployment configurations also allow for multiple replicas of a model in a pipeline to provide scalability.
Create Pipeline Configuration
Setting a pipeline deployment configuration follows this process:
- Pipeline deployment configurations are created through the wallaroo ‘
deployment_config.DeploymentConfigBuilder()](https://docs.wallaroo.ai/wallaroo-developer-guides/wallaroo-sdk-guides/wallaroo-sdk-reference-guide/deployment_config/#DeploymentConfigBuilder) class. - Once the configuration options are set the pipeline deployment configuration is set with the
deployment_config.build()method. - The pipeline deployment configuration is then applied when the pipeline is deployed.
The following example shows a pipeline deployment configuration with 1 replica, 1 cpu, and 2Gi of memory set to be allocated to the pipeline.
deployment_config = wallaroo.DeploymentConfigBuilder()
.replica_count(1)
.cpus(1)
.memory("2Gi")
.build()
pipeline.deploy(deployment_config = deployment_config)
Pipeline resources can be configured with autoscaling. Autoscaling allows the user to define how many engines a pipeline starts with, the minimum amount of engines a pipeline uses, and the maximum amount of engines a pipeline can scale to. The pipeline scales up and down based on the average CPU utilization across the engines in a given pipeline as the user’s workload increases and decreases.
Pipeline Resource Configurations
Pipeline deployment configurations deal with two major components:
- Native Runtimes: Models that are deployed “as is” with the Wallaroo engine (Onnx, etc).
- Containerized Runtimes: Models that are packaged into a container then deployed as a container with the Wallaroo engine (MLFlow, etc).
These configurations can be mixed - both native runtimes and containerized runtimes deployed to the same pipeline, with resources allocated to each runtimes in different configurations.
The following resources configurations are available through the wallaroo.deployment_config object.
GPU and CPU Allocation
CPUs are allocated in fractions of total CPU power similar to the Kubernetes CPU definitions. cpus(0.25), cpus(1.0), etc are valid values.
GPUs can only be allocated by entire integer units from the GPU enabled nodepools. gpus(1), gpus(2), etc are valid values, while gpus(0.25) are not.
Organizations should be aware of how many GPUs are allocated to the cluster. If all GPUs are already allocated to other pipelines, or if there are not enough GPUs to fulfill the request, the pipeline deployment will fail and return an error message.
GPU Support
Wallaroo 2023.2.1 and above supports Kubernetes nodepools with Nvidia Cuda GPUs.
See the Create GPU Nodepools for Kubernetes Clusters guide for instructions on adding GPU enabled nodepools to a Kubernetes cluster.
IMPORTANT NOTE
If allocating GPUs to a Wallaroo pipeline, thedeployment_label configuration option must be used.Architecture Support
Wallaroo supports x86 and ARM architecture CPUs. For example, Azure supports Ampere® Altra® Arm-based processor included with the following virtual machines:
Pipeline deployment architectures are specified through the arch(wallaroo.engine_config.Architecture) parameter with x86 processors as the default architecture. To set the deployment architecture to ARM, specify the arch parameter as follows:
from wallaroo.engine_config import Architecture
arm_deployment_config = wallaroo.deployment_config.DeploymentConfigBuilder().arch(Architecture.ARM).build()
Target Architecture for ARM Deployment
Models uploaded to Wallaroo default to a target architecture deployment of x86. Wallaroo pipeline deployments default to x86.
Models with the target architecture ARM require the pipeline deployment configuration also be ARM. For example:
from wallaroo.engine_config import Architecture
resnet_model = wl.upload_model(resnet_model_name,
resnet_model_file_name,
framework=Framework.ONNX,
arch=Architecture.ARM
)
pipeline.add_model_step(resnet_model)
deployment_config = (wallaroo.deployment_config
.DeploymentConfigBuilder()
.cpus(2)
.memory('2Gi')
.arch(Architecture.ARM)
.build()
)
pipeline(deployment_config)
Native Runtime Configuration Methods
| Method | Parameters | Description | Enterprise Only Feature |
|---|---|---|---|
replica_count | (count: int) | The number of replicas of the pipeline to deploy. This allows for multiple deployments of the same models to be deployed to increase inferences through parallelization. | √ |
replica_autoscale_min_max | (maximum: int, minimum: int = 0) | Provides replicas to be scaled from 0 to some maximum number of replicas. This allows pipelines to spin up additional replicas as more resources are required, then spin them back down to save on resources and costs. | √ |
autoscale_cpu_utilization | (cpu_utilization_percentage: int) | Sets the average CPU percentage metric for when to load or unload another replica. | √ |
disable_autoscale | Disables autoscaling in the deployment configuration. | ||
cpus | (core_count: float) | Sets the number or fraction of CPUs to use for the pipeline, for example: 0.25, 1, 1.5, etc. The units are similar to the Kubernetes CPU definitions. | |
gpus | (core_count: int) | Sets the number of GPUs to allocate for native runtimes. GPUs are only allocated in whole units, not as fractions. Organizations should be aware of the total number of GPUs available to the cluster, and monitor which pipeline deployment configurations have gpus allocated to ensure they do not run out. If there are not enough gpus to allocate to a pipeline deployment configuration, and error message will be deployed when the pipeline is deployed. If gpus is called, then the deployment_label must be called and match the GPU Nodepool for the Wallaroo Cluster hosting the Wallaroo instance. | √ |
memory | (memory_spec: str) | Sets the amount of RAM to allocate the pipeline. The memory_spec string is in the format “{size as number}{unit value}”. The accepted unit values are:
| |
lb_cpus | (core_count: float) | Sets the number or fraction of CPUs to use for the pipeline’s load balancer, for example: 0.25, 1, 1.5, etc. The units, similar to the Kubernetes CPU definitions. | |
lb_memory | (memory_spec: str) | Sets the amount of RAM to allocate the pipeline’s load balancer. The memory_spec string is in the format “{size as number}{unit value}”. The accepted unit values are:
| |
deployment_label | (label: string) | Label used to match the nodepool label used for the pipeline. Required if gpus are set and must match the GPU nodepool label. See Create GPU Nodepools for Kubernetes Clusters for details on setting up GPU nodepools for Wallaroo. | √ |
arch | architecture: wallaroo.engine_config.Architecture | Sets the CPU architecture for the pipeline. This defaults to X86. Available options are:
|
Containerized Runtime Configuration Methods
| Method | Parameters | Description | Enterprise Only Feature |
|---|---|---|---|
sidekick_cpus | (model: wallaroo.model.Model, core_count: float) | Sets the number of CPUs to be used for the model’s sidekick container. Only affects image-based models (e.g. MLFlow models) in a deployment. The parameters are as follows:
| |
sidekick_memory | (model: wallaroo.model.Model, memory_spec: str) | Sets the memory available to for the model’s sidekick container. Only affects image-based models (e.g. MLFlow models) in a deployment. The parameters are as follows:
| |
sidekick_env | (model: wallaroo.model.Model, environment: Dict[str, str]) | Environment variables submitted to the model’s sidekick container. Only affects image-based models (e.g. MLFlow models) in a deployment. These are used specifically for containerized models that have environment variables that effect their performance. | |
sidekick_gpus | (model: wallaroo.model.Model, core_count: int) | Sets the number of GPUs to allocate for containerized runtimes. GPUs are only allocated in whole units, not as fractions. Organizations should be aware of the total number of GPUs available to the cluster, and monitor which pipeline deployment configurations have gpus allocated to ensure they do not run out. If there are not enough gpus to allocate to a pipeline deployment configuration, and error message will be deployed when the pipeline is deployed. If called, then the deployment_label must be called and match the GPU Nodepool for the Wallaroo Cluster hosting the Wallaroo instance | √ |
sidekick_arch | architecture: wallaroo.engine_config.Architecture | Sets the CPU architecture for the pipeline. This defaults to X86. Available options are:
| √ |
Examples
Native Runtime Deployment
The following will set native runtime deployment to one quarter of a CPU with 1 Gi of Ram:
deployment_config = DeploymentConfigBuilder() \
.cpus(0.25).memory('1Gi') \
.build()
This example sets the replica count to 1, then sets the auto-scale to vary between 2 to 5 replicas depending on need, with 1 CPU and 1 GI RAM allocated per replica.
deploy_config = (wallaroo.DeploymentConfigBuilder()
.replica_count(1)
.replica_autoscale_min_max(minimum=2, maximum=5)
.cpus(1)
.memory("1Gi")
.build()
)
The following configuration allocates 1 GPU to the pipeline for native runtimes.
deployment_config = DeploymentConfigBuilder()
.cpus(0.25)
.memory('1Gi')
.gpus(1)
.deployment_label('doc-gpu-label:true')
.build()
Containerized Runtime Deployment
The following configuration allocates 0.25 CPU and 1Gi RAM to the containerized runtime sm_model, and passes that runtime environmental variables used for timeout settings.
deployment_config = DeploymentConfigBuilder()
.sidekick_cpus(sm_model, 0.25)
.sidekick_memory(sm_model, '1Gi')
.sidekick_env(sm_model,
{"GUNICORN_CMD_ARGS":
"__timeout=188 --workers=1"}
)
.build()
This example shows allocating 1 GPU to the containerized runtime model sm_model.
deployment_config = DeploymentConfigBuilder()
.sidekick_gpus(sm_model, 1)
.deployment_label('doc-gpu-label:true')
.sidekick_memory(sm_model, '1Gi')
.build()
Mixed Environments
The following configuration allocates 1 gpu to the pipeline for native runtimes, then another gpu to the containerized runtime sm_model for a total of 2 gpus allocated to the pipeline: one gpu for native runtimes, another gpu for the containerized runtime model sm_model.
deployment_config = DeploymentConfigBuilder()
.cpus(0.25)
.memory('1Gi')
.gpus(1)
.deployment_label('doc-gpu-label:true')
.sidekick_gpus(sm_model, 1)
.build()
4 - Wallaroo SDK Essentials Guide: Pipeline Log Management
Pipeline have their own set of log files that are retrieved and analyzed as needed with the either through:
- The Pipeline
logsmethod (returns either a DataFrame or Apache Arrow). - The Pipeline
export_logsmethod (saves either a DataFrame file in JSON format, or an Apache Arrow file).
Get Pipeline Logs
Pipeline logs are retrieved through the Pipeline logs method. By default, logs are returned as a DataFrame in reverse chronological order of insertion, with the most recent files displayed first.
Pipeline logs are segmented by pipeline versions. For example, if a new model step is added to a pipeline, a model swapped out of a pipeline step, etc - this generated a new pipeline version. log method requests will return logs based on the parameter that match the pipeline version. To request logs of a specific pipeline version, specify the start_datetime and end_datetime parameters based on the pipeline version logs requested.
IMPORTANT NOTE
Pipeline logs are returned either in reverse or forward chronological order of record insertion; depending on when a specific inference request completes, one inference record may be inserted out of chronological order by theTimestamp value, but still be in chronological order of insertion.This command takes the following parameters.
| Parameter | Type | Description |
|---|---|---|
limit | Int (Optional) (Default: 100) | Limits how many log records to display. If there are more pipeline logs than are being displayed, the Warning message Pipeline log record limit exceeded will be displayed. For example, if 100 log files were requested and there are a total of 1,000, the warning message will be displayed. |
start_datetime and end_datetime | DateTime (Optional) | Limits logs to all logs between the start_datetime and end_datetime DateTime parameters. These comply with the Python datetime library for formats such as:
Both parameters must be provided. Submitting a logs() request with only start_datetime or end_datetime will generate an exception.If start_datetime and end_datetime are provided as parameters even with any other parameter, then the records are returned in chronological order, with the oldest record displayed first. |
dataset | List[String] (OPTIONAL) | The datasets to be returned. The datasets available are:
metadata.elapsed: IMPORTANT NOTE: See Metadata Requests Restrictionsfor specifications on how this dataset can be used with other datasets.
|
dataset_exclude | List[String] (OPTIONAL) | Exclude specified datasets. |
dataset_separator | Sequence[[String], string] (OPTIONAL) | If set to “.”, return dataset will be flattened. |
arrow | Boolean (Optional) (Default: False) | If arrow is set to True, then the logs are returned as an Apache Arrow table. If arrow=False, then the logs are returned as a pandas DataFrame. |
All of the parameters can be used together, but start_datetime and end_datetime must be combined; if one is used, then so must the other. If start_datetime and end_datetime are used with any other parameter, then the log results are in chronological order of record insertion.
Log requests are limited to around 100k in size. For requests greater than 100k in size, use the Pipeline export_logs() method.
Logs include the following standard datasets:
| Parameter | Type | Description |
|---|---|---|
time | DateTime | The DateTime the inference request was made. |
in.{variable} | The input(s) for the inference request. Each input is listed as in.{variable_name}. For example, in.text_input, in.square_foot, in.number_of_rooms, etc. | |
out | The outputs(s) for the inference request, based on the ML model’s outputs. Each output is listed as out.{variable_name}. For example, out.maximum_offer_price, out.minimum_asking_price, out.trade_in_value, etc. | |
anomaly.count | Int | How many validation checks were triggered by the inference. For more information, see Wallaroo SDK Essentials Guide: Anomaly Detection |
out_{model_name}.{variable} | Only returned when using Pipeline Shadow Deployments. For each model in the shadow deploy step, their output is listed in the format out_{model_name}.{variable}. For example, out_shadow_model_xgb.maximum_offer_price, out_shadow_model_xgb.minimum_asking_price, out_shadow_model_xgb.trade_in_value, etc. | |
out._model_split | Only returned when using A/B Testing, used to display the model_name, model_version, and model_sha of the model used for the inference. |
In this example, the last 50 logs to the pipeline mainpipeline between two sample dates. In this case, all of the time column fields are the same since the inference request was sent as a batch.
logs = mainpipeline.logs(start_datetime=date_start, end_datetime=date_end)
display(len(logs))
display(logs)
538
| time | in.tensor | out.variable | anomaly.count | |
|---|---|---|---|---|
| 0 | 2023-04-24 18:09:33.970 | [4.0, 2.5, 2900.0, 5505.0, 2.0, 0.0, 0.0, 3.0, 8.0, 2900.0, 0.0, 47.6063, -122.02, 2970.0, 5251.0, 12.0, 0.0, 0.0] | [718013.75] | 0 |
| 1 | 2023-04-24 18:09:33.970 | [2.0, 2.5, 2170.0, 6361.0, 1.0, 0.0, 2.0, 3.0, 8.0, 2170.0, 0.0, 47.7109, -122.017, 2310.0, 7419.0, 6.0, 0.0, 0.0] | [615094.56] | 0 |
| 2 | 2023-04-24 18:09:33.970 | [3.0, 2.5, 1300.0, 812.0, 2.0, 0.0, 0.0, 3.0, 8.0, 880.0, 420.0, 47.5893, -122.317, 1300.0, 824.0, 6.0, 0.0, 0.0] | [448627.72] | 0 |
| 3 | 2023-04-24 18:09:33.970 | [4.0, 2.5, 2500.0, 8540.0, 2.0, 0.0, 0.0, 3.0, 9.0, 2500.0, 0.0, 47.5759, -121.994, 2560.0, 8475.0, 24.0, 0.0, 0.0] | [758714.2] | 0 |
| 4 | 2023-04-24 18:09:33.970 | [3.0, 1.75, 2200.0, 11520.0, 1.0, 0.0, 0.0, 4.0, 7.0, 2200.0, 0.0, 47.7659, -122.341, 1690.0, 8038.0, 62.0, 0.0, 0.0] | [513264.7] | 0 |
| … | … | … | … | … |
| 533 | 2023-04-24 18:09:33.970 | [3.0, 2.5, 1750.0, 7208.0, 2.0, 0.0, 0.0, 3.0, 8.0, 1750.0, 0.0, 47.4315, -122.192, 2050.0, 7524.0, 20.0, 0.0, 0.0] | [311909.6] | 0 |
| 534 | 2023-04-24 18:09:33.970 | [5.0, 1.75, 2330.0, 6450.0, 1.0, 0.0, 1.0, 3.0, 8.0, 1330.0, 1000.0, 47.4959, -122.367, 2330.0, 8258.0, 57.0, 0.0, 0.0] | [448720.28] | 0 |
| 535 | 2023-04-24 18:09:33.970 | [4.0, 3.5, 4460.0, 16271.0, 2.0, 0.0, 2.0, 3.0, 11.0, 4460.0, 0.0, 47.5862, -121.97, 4540.0, 17122.0, 13.0, 0.0, 0.0] | [1208638.0] | 0 |
| 536 | 2023-04-24 18:09:33.970 | [3.0, 2.75, 3010.0, 1842.0, 2.0, 0.0, 0.0, 3.0, 9.0, 3010.0, 0.0, 47.5836, -121.994, 2950.0, 4200.0, 3.0, 0.0, 0.0] | [795841.06] | 0 |
| 537 | 2023-04-24 18:09:33.970 | [2.0, 1.5, 1780.0, 4750.0, 1.0, 0.0, 0.0, 4.0, 7.0, 1080.0, 700.0, 47.6859, -122.395, 1690.0, 5962.0, 67.0, 0.0, 0.0] | [558463.3] | 0 |
538 rows × 4 columns
Metadata Requests Restrictions
The following restrictions are in place when requesting the following datasets:
metadatametadata.elaspedmetadata.last_modelmetadata.pipeline_version
Standard Pipeline Steps Log Requests
Effected pipeline steps:
add_model_stepreplace_with_model_step
For log file requests, the following metadata dataset requests for standard pipeline steps are available:
metadata
These must be paired with specific columns. * is not available when paired with metadata.
in: All input fields.out: All output fields.time: The DateTime the inference request was made.in.{input_fields}: Any input fields (tensor, etc.)out.{output_fields}: Any output fields (out.house_price,out.variable, etc.)anomaly.count: Any anomalies detected from validations.anomaly.{validation}: The validation that triggered the anomaly detection and whether it isTrue(indicating an anomaly was detected) orFalse. For more details, see Wallaroo SDK Essentials Guide: Anomaly Detection
For example, the following requests the metadata plus any output fields.
metadatalogs = mainpipeline.logs(dataset=["out","metadata"])
display(metadatalogs.loc[:, ['out.variable', 'metadata.last_model']])
| out.variable | metadata.last_model | |
|---|---|---|
| 0 | [581003.0] | {“model_name”:“logcontrol”,“model_sha”:“e22a0831aafd9917f3cc87a15ed267797f80e2afa12ad7d8810ca58f173b8cc6”} |
| 1 | [706823.56] | {“model_name”:“logcontrol”,“model_sha”:“e22a0831aafd9917f3cc87a15ed267797f80e2afa12ad7d8810ca58f173b8cc6”} |
| 2 | [1060847.5] | {“model_name”:“logcontrol”,“model_sha”:“e22a0831aafd9917f3cc87a15ed267797f80e2afa12ad7d8810ca58f173b8cc6”} |
| 3 | [441960.38] | {“model_name”:“logcontrol”,“model_sha”:“e22a0831aafd9917f3cc87a15ed267797f80e2afa12ad7d8810ca58f173b8cc6”} |
| 4 | [827411.0] | {“model_name”:“logcontrol”,“model_sha”:“e22a0831aafd9917f3cc87a15ed267797f80e2afa12ad7d8810ca58f173b8cc6”} |
Shadow Deploy Testing Pipeline Steps
Effected pipeline steps:
add_shadow_deployreplace_with_shadow_deploy
For log file requests, the following metadata dataset requests for shadow deploy testing pipeline steps are available:
metadata
These must be paired with specific columns. * is not available when paired with metadata. time must be included if dataset is used.
in: All input fields.out: All output fields.time: The DateTime the inference request was made.in.{input_fields}: Any input fields (tensor, etc.).out.{output_fields}: Any output fields matching the specificoutput_field(out.house_price,out.variable, etc.).out_: All shadow deployed challenger steps Any output fields matching the specificoutput_field(out.house_price,out.variable, etc.).anomaly.count: Any anomalies detected from validations.anomaly.{validation}: The validation that triggered the anomaly detection and whether it isTrue(indicating an anomaly was detected) orFalse. For more details, see Wallaroo SDK Essentials Guide: Anomaly Detection
The following example retrieves the logs from a pipeline with shadow deployed models, and displays the specific shadow deployed model outputs and the metadata.elasped field.
# Display metadata
metadatalogs = mainpipeline.logs(dataset=["out_logcontrolchallenger01.variable",
"out_logcontrolchallenger02.variable",
"metadata"
]
)
display(metadatalogs.loc[:, ['out_logcontrolchallenger01.variable',
'out_logcontrolchallenger02.variable',
'metadata.elapsed'
]
])
| out_logcontrolchallenger01.variable | out_logcontrolchallenger02.variable | metadata.elapsed | |
|---|---|---|---|
| 0 | [573391.1] | [596933.5] | [302804, 26900] |
| 1 | [663008.75] | [594914.2] | [302804, 26900] |
| 2 | [1520770.0] | [1491293.8] | [302804, 26900] |
| 3 | [381577.16] | [411258.3] | [302804, 26900] |
| 4 | [743487.94] | [787589.25] | [302804, 26900] |
A/B Deploy Testing Pipeline Steps
Effected pipeline steps:
add_random_splitreplace_with_random_split
For log file requests, the following metadata dataset requests for A/B testing pipeline steps are available:
metadata
These must be paired with specific columns. * is not available when paired with metadata. time must be included if dataset is used.
in: All input fields.out: All output fields.time: The DateTime the inference request was made. Must be requested in alldatasetrequests.in.{input_fields}: Any input fields (tensor, etc.).out.{output_fields}: Any output fields matching the specificoutput_field(out.house_price,out.variable, etc.).anomaly.count: Any anomalies detected from validations.anomaly.{validation}: The validation that triggered the anomaly detection and whether it isTrue(indicating an anomaly was detected) orFalse. For more details, see Wallaroo SDK Essentials Guide: Anomaly Detection
The following example retrieves the logs from a pipeline with A/B deployed models, and displays the output and the specific metadata.last_model field.
metadatalogs = mainpipeline.logs(dataset=["time",
"out",
"metadata"
]
)
display(metadatalogs.loc[:, ['out.variable', 'metadata.last_model']])
| out.variable | metadata.last_model | |
|---|---|---|
| 0 | [581003.0] | {“model_name”:“logcontrol”,“model_sha”:“e22a0831aafd9917f3cc87a15ed267797f80e2afa12ad7d8810ca58f173b8cc6”} |
| 1 | [706823.56] | {“model_name”:“logcontrol”,“model_sha”:“e22a0831aafd9917f3cc87a15ed267797f80e2afa12ad7d8810ca58f173b8cc6”} |
| 2 | [1060847.5] | {“model_name”:“logcontrol”,“model_sha”:“e22a0831aafd9917f3cc87a15ed267797f80e2afa12ad7d8810ca58f173b8cc6”} |
| 3 | [441960.38] | {“model_name”:“logcontrol”,“model_sha”:“e22a0831aafd9917f3cc87a15ed267797f80e2afa12ad7d8810ca58f173b8cc6”} |
| 4 | [827411.0] | {“model_name”:“logcontrol”,“model_sha”:“e22a0831aafd9917f3cc87a15ed267797f80e2afa12ad7d8810ca58f173b8cc6”} |
Export Pipeline Logs as File
The Pipeline method export_logs returns the Pipeline records as either by default pandas records in Newline Delimited JSON (NDJSON) format, or an Apache Arrow table files.
The output files are by default stores in the current working directory ./logs with the default prefix as the {pipeline name}-1, {pipeline name}-2, etc.
IMPORTANT NOTE
Files with the same names will be overwritten.The suffix by default will be json for pandas records in Newline Delimited JSON (NDJSON) format files. Logs are segmented by pipeline version across the limit, data_size_limit, or start_datetime and end_datetime parameters.
By default, logs are returned as a pandas record in NDJSON in reverse chronological order of insertion, with the most recent log insertions displayed first.
Pipeline logs are segmented by pipeline versions. For example, if a new model step is added to a pipeline, a model swapped out of a pipeline step, etc - this generated a new pipeline version.
IMPORTANT NOTE
Pipeline logs are returned either in reverse or forward chronological order of record insertion; depending on when a specific inference request completes, one inference record may be inserted out of chronological order by theTimestamp value, but still be in chronological order of insertion.This command takes the following parameters.
| Parameter | Type | Description |
|---|---|---|
directory | String (Optional) (Default: logs) | Logs are exported to a file from current working directory to directory. |
file_prefix | String (Optional) (Default: The name of the pipeline) | The name of the exported files. By default, this will the name of the pipeline and is segmented by pipeline version between the limits or the start and end period. For example: ’logpipeline-1.json`, etc. |
data_size_limit | String (Optional) (Default: 100MB) | The maximum size for the exported data in bytes. Note that file size is approximate to the request; a request of 10MiB may return 10.3MB of data. The fields are in the format “{size as number} {unit value}”, and can include a space so “10 MiB” and “10MiB” are the same. The accepted unit values are:
|
limit | Int (Optional) (Default: 100) | Limits how many log records to display. Defaults to 100. If there are more pipeline logs than are being displayed, the Warning message Pipeline log record limit exceeded will be displayed. For example, if 100 log files were requested and there are a total of 1,000, the warning message will be displayed. |
start_datetime and end_datetime | DateTime (Optional) | Limits logs to all logs between the start_datetime and end_datetime DateTime parameters. These comply with the Python datetime library for formats such as:
Both parameters must be provided. Submitting a logs() request with only start_datetime or end_datetime will generate an exception.If start_datetime and end_datetime are provided as parameters even with any other parameter, then the records are returned in chronological order, with the oldest record displayed first. |
filename | String (Required) | The file name to save the log file to. The requesting user must have write access to the file location. The requesting user must have write permission to the file location, and the target directory for the file must already exist. For example: If the file is set to /var/wallaroo/logs/pipeline.json, then the directory /var/wallaroo/logs must already exist. Otherwise file names are only limited by standard file naming rules for the target environment. |
dataset | List (OPTIONAL) | The datasets to be returned. The datasets available are:
metadata.elapsed: IMPORTANT NOTE: See Metadata Requests Restrictionsfor specifications on how this dataset can be used with other datasets.
|
dataset_exclude | List[String] (OPTIONAL) | Exclude specified datasets. |
dataset_separator | Sequence[[String], string] (OPTIONAL) | If set to “.”, return dataset will be flattened. |
arrow | Boolean (Optional) | Defaults to False. If arrow=True, then the logs are returned as an Apache Arrow table. If arrow=False, then the logs are returned as pandas record in NDJSON that can be imported into a pandas DataFrame. |
All of the parameters can be used together, but start_datetime and end_datetime must be combined; if one is used, then so must the other. If start_datetime and end_datetime are used with any other parameter, then the log results are in chronological order of record insertion.
File sizes are limited to around 10 MB in size. If the requested log file is greater than 10 MB, a Warning will be displayed indicating the end date of the log file downloaded so the request can be adjusted to capture the requested log files.
IMPORTANT NOTE
DataFrame file exports exported as pandas record in NDJSON are read back to a DataFrame through the the pandas read_json method with the parameter lines=True. For example:
data_df = pd.read_json("mainpipeline_logs.df.json", lines=True)
display(data_df)
In this example, the log files are saved as both Pandas DataFrame and Apache Arrow.
# Save the DataFrame version of the log file
mainpipeline.export_logs()
display(os.listdir('./logs'))
mainpipeline.export_logs(arrow=True)
display(os.listdir('./logs'))
Warning: There are more logs available. Please set a larger limit to export more data.
['pipeline-logs-1.json']
Warning: There are more logs available. Please set a larger limit to export more data.
['pipeline-logs-1.arrow', 'pipeline-logs-1.json']
Pipeline Log Storage
Pipeline logs have a set allocation of storage space and data requirements.
Pipeline Log Storage Warnings
To prevent storage and performance issues, inference result data may be dropped from pipeline logs by the following standards:
- Columns are progressively removed from the row starting with the largest input data size and working to the smallest, then the same for outputs.
For example, Computer Vision ML Models typically have large inputs and output values - a single pandas DataFrame inference request may be over 13 MB in size, and the inference results nearly as large. To prevent pipeline log storage issues, the input may be dropped from the pipeline logs, and if additional space is needed, the inference outputs would follow. The time column is preserved.
IMPORTANT NOTE
Inference Requests will always return all inputs, outputs, and other metadata unless specifically requested for exclusion. It is the pipeline logs that may drop columns for space purposes.If a pipeline has dropped columns for space purposes, this will be displayed when a log request is made with the following warning, with {columns} replaced with the dropped columns.
The inference log is above the allowable limit and the following columns may have been suppressed for various rows in the logs: {columns}. To review the dropped columns for an individual inference’s suppressed data, include dataset=["metadata"] in the log request.
Review Dropped Columns
To review what columns are dropped from pipeline logs for storage reasons, include the dataset metadata in the request to view the column metadata.dropped. This metadata field displays a List of any columns dropped from the pipeline logs.
For example:
metadatalogs = mainpipeline.logs(dataset=["time", "metadata"])
| time | metadata.dropped | |
|---|---|---|
| 0 | 2023-07-06 | 15:47:03.673 |
| 1 | 2023-07-06 | 15:47:03.673 |
| 2 | 2023-07-06 | 15:47:03.673 |
| 3 | 2023-07-06 | 15:47:03.673 |
| 4 | 2023-07-06 | 15:47:03.673 |
| … | … | … |
| 95 | 2023-07-06 | 15:47:03.673 |
| 96 | 2023-07-06 | 15:47:03.673 |
| 97 | 2023-07-06 | 15:47:03.673 |
| 98 | 2023-07-06 | 15:47:03.673 |
| 99 | 2023-07-06 | 15:47:03.673 |
Suppressed Data Elements
Data elements that do not fit the supported data types below, such as None or Null values, are not supported in pipeline logs. When present, undefined data will be written in the place of the null value, typically zeroes. Any null list values will present an empty list.
5 - Wallaroo SDK Essentials Guide: Pipeline Edge Publication
Wallaroo pipelines can be published to a Edge Open Container Initiative (OCI) Registry Service, known here as the Edge Registry Service, as a container images. This allows the Wallaroo pipelines to be deployed in other environments, such as Docker or Kubernetes with all of the pipeline model. When deployed, these pipelines can perform inferences from the ML models exactly as if they were deployed as part of a Wallaroo instance.
When a pipeline is updated with new model steps or deployment configurations, the updated pipeline is republished to the Edge Registry as a new repo and version. This allows DevOps engineers to update an Wallaroo pipeline in any container supporting environment with the new versions of the pipeline.
Pipeline Publishing Flow
A typical ML Model and Pipeline deployment to Wallaroo Ops and to remote locations as a Wallaroo Inference server is as follows:
- Components:
- Wallaroo Ops: The Wallaroo Ops provides the backbone services for ML Model deployment. This is where ML models are uploaded, pipelines created and deployed for inferencing, pipelines published to OCI compliant registries, and other functions.
- Wallaroo Inference Server: A remote deployment of a published Wallaroo pipeline with the Wallaroo Inference Engine outside the Wallaroo Ops instance. When the edge name is added to a Wallaroo publish, the Wallaroo Inference Server’s inference logs are submitted to the Wallaroo Ops instance. These inference logs are stored as part of the Wallaroo pipeline the remote deployment is published from.
- DevOps:
- Add Edge Publishing and Edge Observability to the Wallaroo Ops center. See Edge Deployment Registry Guide for details on updating the Wallaroo instance with Edge Publishing and Edge Observability.
- Data Scientists:
- Develop and train models.
- Test their deployments in Wallaroo Ops Center as Pipelines with:
- Pipeline Steps: The models part of the inference flow.
- Pipeline Deployment Configurations: CPUs, RAM, GPU, and Architecture settings to run the pipeline.
- Publish the Pipeline from the Wallaroo Ops to an OCI Registry: Store a image version of the Pipeline with models and pipeline configuration into the OCI Registry set by the DevOps engineers as the Wallaroo Edge Registry Service.
- DevOps:
- Retrieve the new or updated Wallaroo published pipeline from the Wallaroo Edge Registry Service.
- (Optional): Add an edge to the Wallaroo publish. This provides the
EDGE_BUNDLEwith the credentials for the Wallaroo Inference Server to transmit its inference result logs back to the Wallaroo Ops instance. These inference logs are added to the originating Wallaroo pipeline, labeled with themetadata.partitionbeing the name of the edge deployed Wallaroo Inference server. For more details, see Wallaroo SDK Essentials Guide: Pipeline Edge Publication: Edge Observability - Deploy the Pipeline as a Wallaroo Inference Server as a Docker or Kubernetes container, updating the resource allocations as part of the Helm chart, Docker Compose file, etc.

Enable Wallaroo Edge Registry
Set Edge Registry Service
Wallaroo Pipeline Publishes aka Wallaroo Servers are automatically routed to the Edge Open Container Initiative (OCI) Registry Service registered in the Wallaroo instance. This is enabled through either the Wallaroo Administrative Dashboard through kots, or by enabling it through a helm chart setting. From here on out, we will refer to it as the Edge Registry Service.
Set Edge Registry Service through Kots
To set the Edge Registry Settings through the Wallaroo Administrative Dashboard:
Launch the Wallaroo Administrative Dashboard using the following command, replacing the
--namespaceparameter with the Kubernetes namespace for the Wallaroo instance:kubectl kots admin-console --namespace wallarooOpen a browser at the URL detailed in the step above and authenticate using the console password set as described in the as detailed in the Wallaroo Install Guides.
From the top menu, select Config then scroll to Edge Deployment.
Enable Provide OCI registry credentials for pipelines.
Enter the following:
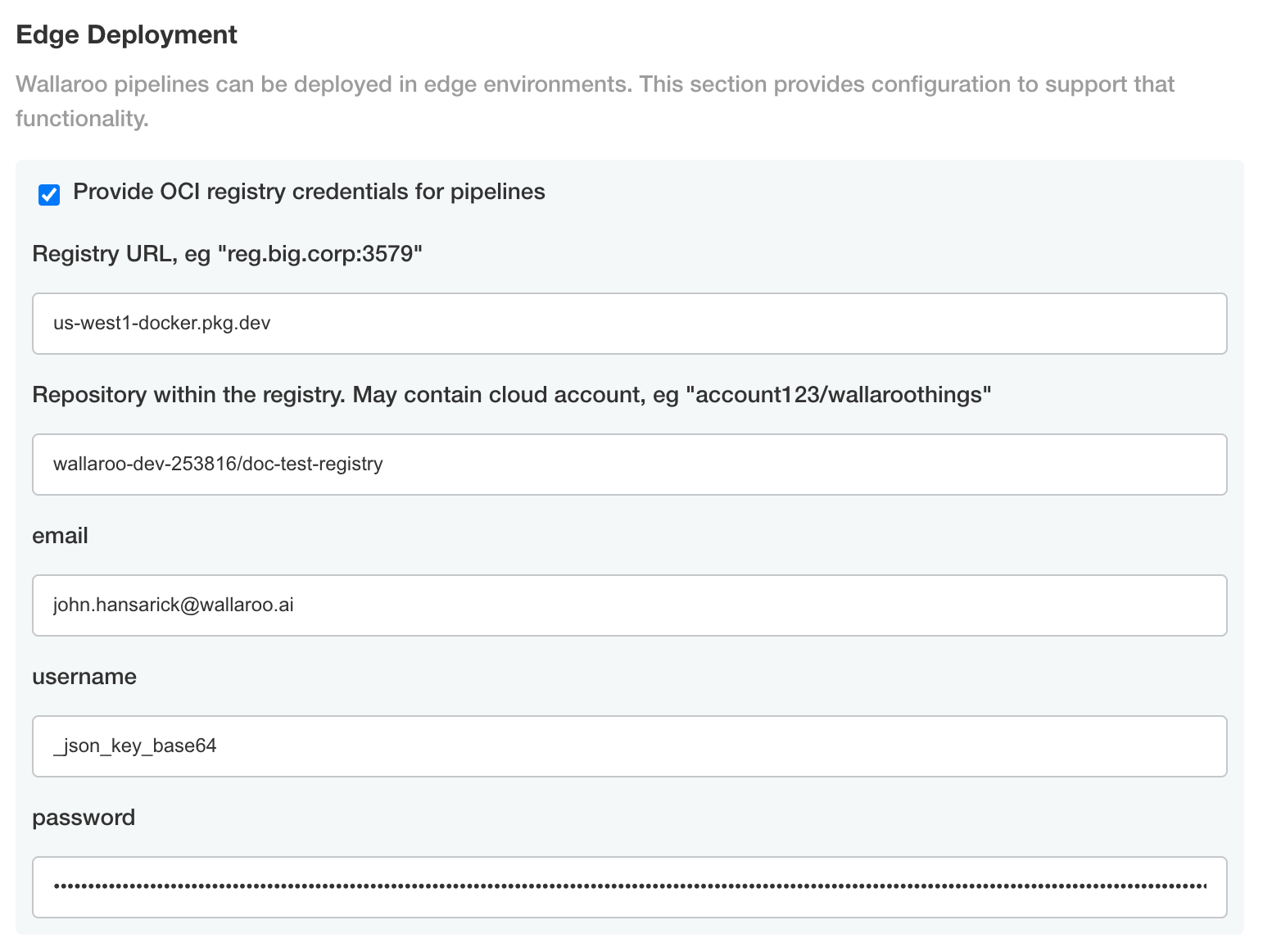
- Registry URL: The address of the registry service. For example:
us-west1-docker.pkg.dev. - email: The email address of the user account used to authenticate to the service.
- username: The account used to authenticate to the registry service.
- password: The password or token used to authenticate to the registry service.
- Registry URL: The address of the registry service. For example:
Save the updated configuration, then deploy it. Once complete, the edge registry settings will be available.
Set Edge Registry Service through Helm
The helm settings for adding the Edge Server configuration details are set through the ociRegistry element, with the following settings.
- ociRegistry: Sets the Edge Server registry information.
- enabled:
trueenables the Edge Server registry information,falsedisables it. - registry: The registry url. For example:
reg.big.corp:3579. - repository: The repository within the registry. This may include the cloud account, or the full path where the Wallaroo published pipelines should be kept. For example:
account123/wallaroo/pipelines. - email: Optional field to track the email address of the registry credential.
- username: The username to the registry. This may vary based on the provider. For example, GCP Artifact Registry with service accounts uses the username
_json_key_base64with the password as a base64 processed token of the credential information. - password: The password or token for the registry service.
- enabled:
Set Edge Observability Service
Edge Observability allows published Wallaroo Servers to community with the Wallaroo Ops center to update their associated Wallaroo Pipeline with inference results, visible in the Pipeline logs.
This process will create a new Kubernetes service edge-lb. Based on the configuration options below, the service will require an additional IP address separate from the Wallaroo service api-lb. The edge-lb will require a DNS hostname.
Set Edge Observability Service through Kots
To enable Edge Observability using the Wallaroo Administrative Dashboard for kots installed instances of Wallaroo Ops:
Launch the Wallaroo Administrative Dashboard using the following command, replacing the
--namespaceparameter with the Kubernetes namespace for the Wallaroo instance:kubectl kots admin-console --namespace wallarooOpen a browser at the URL detailed in the step above and authenticate using the console password set as described in the as detailed in the Wallaroo Install Guides.
Access Config and scroll to Edge Deployment and enable Enable pipelines deployed on the edge to send data back to the OpsCenter.
Set the following:
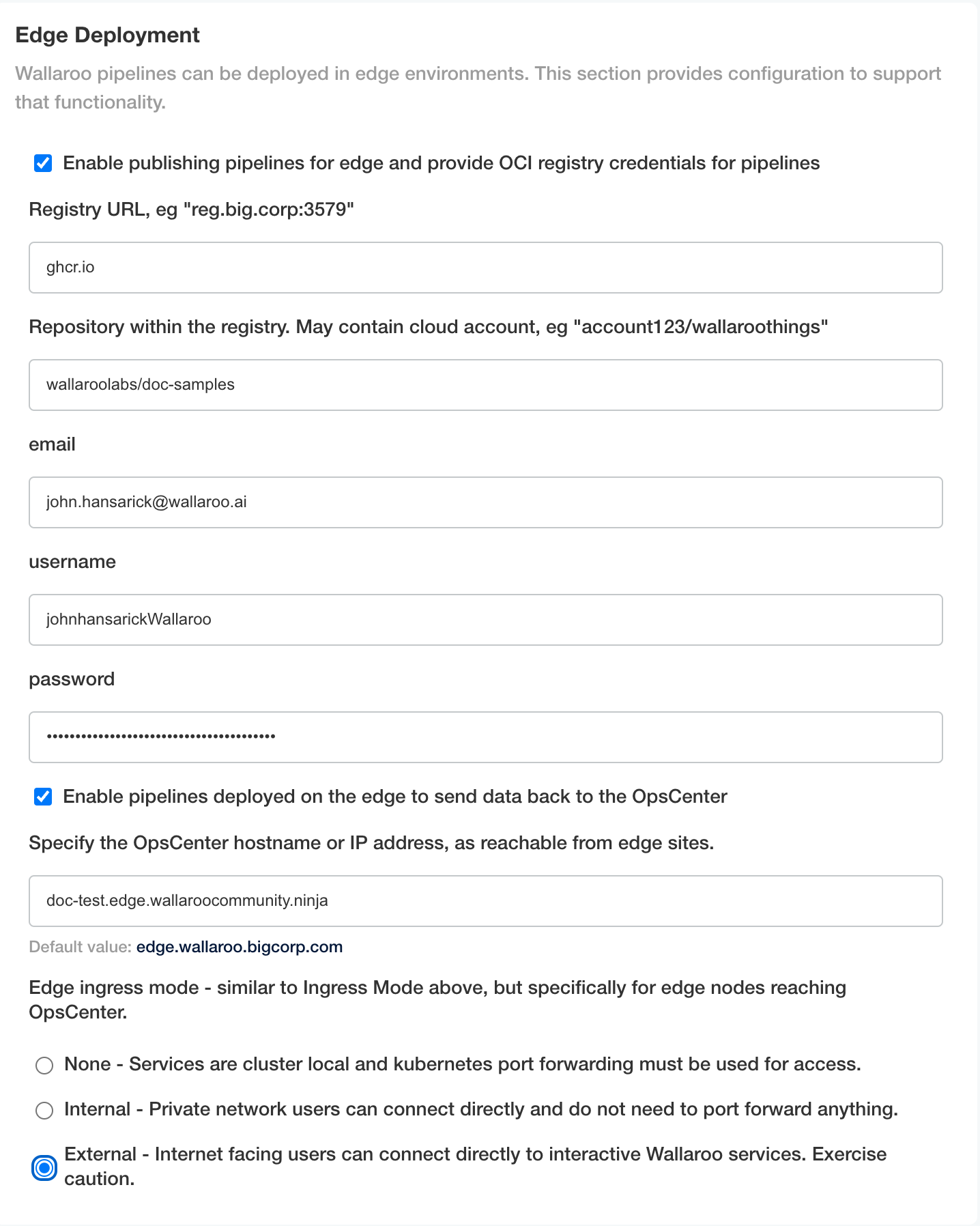
Specify the OpsCenter hostname or IP address, as reachable from edge sites.: Set the DNS address in the format
https://service.{suffix domain}. For example, if the domain suffix iswallaroo.example.comand the Wallaroo Edge Observabilty Service is set to the hostnameedge, then the URL to access theedgeservice is:edge.wallaroo.example.comEdge ingress mode: Set one of the following.
- None - Services are cluster local and kubernetes port forwarding must be used for access.
- Internal - Private network users can connect directly and do not need to port forward anything.
- External - Internet facing users can connect directly to interactive Wallaroo services. Exercise caution.
Save the updated configuration, then deploy it. Once complete, the edge observability service is available.
Set the DNS Hostname as described in the steps Set Edge Observability Service DNS Hostname.
Set Edge Observability Service through Helm
To enable the Edge Observability Service for Wallaroo Ops Helm based installation, include the following variables for the helm settings. For these instructions they are stored in local-values.yaml:
edgelb:
serviceType: LoadBalancer
enabled: true
opscenterHost: mitch4.edge.wallaroocommunity.ninja
pipelines:
enabled: true
Update the Wallaroo Helm installation with the same version as the Wallaroo ops and the channel. For example, if updating Wallaroo Enterprise server, use the following:
helm upgrade wallaroo oci://registry.replicated.com/wallaroo/ee/wallaroo --version 2023.4.0-4092 --values local-values.yaml
This process will take 5-15 minutes depending on other configuration options. Once complete, set the DNS address as described in Set Edge Observability Service DNS Hostname.
Set Edge Observability Service DNS Hostname
Once enabled, the Wallaroo Edge Observability Service requires a DNS address. The following instructions are specified for Edge ingress mode:External.
Obtain the external IP address of the the Wallaroo Edge Observability Service with the following command, replacing the
-n wallaroonamespace option with the one the Wallaroo Ops instance is installed into.EDGE_LOADBALANCER=$(kubectl get svc edge-lb -n wallaroo -o jsonpath='{.status.loadBalancer.ingress[0].ip}') && echo $EDGE_LOADBALANCERSet the DNS address to the hostname set in the step Set Edge Observability Service through Kots if using
kotsto install, or Set Edge Observability Service through Helm if usinghelm.
Registry Setup Guides
The following are short guides for setting up the credentials for different registry services. Refer to the registry documentation for full details.
The following process is used with a GitHub Container Registry to create the authentication tokens for use with a Wallaroo instance’s Private Model Registry configuration.
See the GitHub Working with the Container registry for full details.
The following process is used register a GitHub Container Registry with Wallaroo.
Create a new token as per the instructions from the Creating a personal access token (classic) guide. Note that a classic token is recommended for this process. Store this token in a secure location as it will not be able to be retrieved later from GitHub. Verify the following permissions are set:
Select the
write:packagesscope to download and upload container images and read and write their metadata.Select the
read:packagesscope to download container images and read their metadata (selected whenwrite:packagesis selected by default).Select the
delete:packagesscope to delete container images.
Store the token in a secure location.
This can be tested with docker by logging into the specified registry. For example:
docker login -u {Github Username} --password {Your Token} ghcr.io/{Your Github Username or Organization}
The following process is an example of setting up an Artifact Registry Service with Google Cloud Platform (GCP) that is used to store containerized model images and retrieve them for use with Wallaroo.
Uploading and downloading containerized models to a Google Cloud Platform Registry follows these general steps.
Create the GCP registry.
Create a Service Account that will manage the registry service requests.
Assign appropriate Artifact Registry role to the Service Account
Retrieve the Service Account credentials.
Using either a specific user, or the Service Account credentials, upload the containerized model to the registry service.
Add the service account credentials to the Wallaroo instance’s containerized model private registry configuration.
Prerequisites
The commands below use the Google gcloud command line tool, and expect that a Google Cloud Platform account is created and the gcloud application is associated with the GCP Project for the organization.
For full details on the process and other methods, see the Google GCP documentation.
- Create the Registry
The following is based on the Create a repository using the Google Cloud CLI.
The following information is needed up front:
- $REPOSITORY_NAME: What to call the registry.
- $LOCATION: Where the repository will be located. GCP locations are derived through the
gcloud artifacts locations listcommand. - $DESCRIPTION: Any details to be displayed. Sensitive data should not be included.
The follow example script will create a GCP registry with the minimum requirements.
REPOSITORY_NAME="YOUR NAME"
LOCATION="us-west1"
DESCRIPTION="My amazing registry."
gcloud artifacts repositories create REPOSITORY \
--repository-format=docker \
--location=LOCATION \
--description="$DESCRIPTION" \
--async
- Create a GCP Registry Service Account
The GCP Registry Service Account is used to manage the GCP registry service. The steps are details from the Google Create a service account guide.
The gcloud process for these steps are:
Connect the
gcloudapplication to the organization’s project.$PROJECT_ID="YOUR PROJECT ID" gcloud config set project $PROJECT_IDCreate the service account with the following:
- The name of the service account.
- A description of its purpose.
- The name to show when displayed.
SA_NAME="YOUR SERVICE ACCOUNT NAME" DESCRIPTION="Wallaroo container registry SA" DISPLAY_NAME="Wallaroo the Roo" gcloud iam service-accounts create $SA_NAME \ --description=$DESCRIPTION \ --display-name=$DISPLAY_NAME
- Assign Artifact Registry Role
Assign one or more of the following accounts to the new registry role based on the following criteria, as detailed in the Google GCP Repository Roles and Permissions Guide.
- For
pkg.devdomains.
| Role | Description |
|---|---|
| Artifact Registry Reader (roles/artifactregistry.reader) | View and get artifacts, view repository metadata. |
| Artifact Registry Writer (roles/artifactregistry.writer) | Read and write artifacts. |
| Artifact Registry Repository Administrator (roles/artifactregistry.repoAdmin) | Read, write, and delete artifacts. |
| Artifact Registry Administrator (roles/artifactregistry.admin) | Create and manage repositories and artifacts. |
- For
gcr.iorepositories.
| Role | Description |
|---|---|
| Artifact Registry Create-on-push Writer (roles/artifactregistry.createOnPushWriter) | Read and write artifacts. Create gcr.io repositories. |
| Artifact Registry Create-on-push Repository Administrator (roles/artifactregistry.createOnPushRepoAdmin) | Read, write, and delete artifacts. Create gcr.io repositories. |
For this example, we will add the Artifact Registry Create-on-push Writer to the created Service Account from the previous step.
Add the role to the service account, specifying the
memberas the new service account, and the role as the selected role. For this example, apkg.devis assumed for the Artifact Registry type.# for pkg.dev ROLE="roles/artifactregistry.writer" # for gcr.io #ROLE="roles/artifactregistry.createOnPushWriter gcloud projects add-iam-policy-binding \ $PROJECT_ID \ --member="serviceAccount:$SA_NAME@$PROJECT_ID.iam.gserviceaccount.com" \ --role=$ROLE
- Authenticate to Repository
To push and pull image from the new registry, we’ll use our new service account and authenticate through the local Docker application. See the GCP Push and pull images for details on using Docker and other methods to add artifacts to the GCP artifact registry.
- Set up Service Account Key
To set up the Service Account key, we’ll use the Google Console IAM & ADMIN dashboard based on the Set up authentication for Docker, using the JSON key approach.
From GCP console, search for
IAM & Admin.Select Service Accounts.
Select the service account to generate keys for.
Select the Email address listed and store this for later steps with the key generated through this process.
Select Keys, then Add Key, then Create new key.
Select JSON, then Create.
Store the key in a safe location.
- Convert SA Key to Base64
The key file downloaded in Set up Service Account Key needs to be converted to base64 with the following command, replacing the locations of KEY_FILE and KEYFILEBASE64:
KEY_FILE = ~/.gcp-sa-registry-keyfile.json
KEYFILEBASE64 = ~/.gcp-sa-registry-keyfile-b64.json
base64 -i $KEY_FILE -o $KEYFILEBASE64
This base64 key is then used as the authentication token, with the username _json_key_base64.
This can be tested with docker by logging into the specified registry. For example:
token=$(cat $KEYFILEBASE64)
cat $tok | docker login -u _json_key_base64 --password-stdin https://{GCP artifact registry region}.pkg.dev
Publish a Pipeline to the Edge Registry Service
See also the reference documentation: wallaroo.pipeline.publish.
Publish a Pipeline
Pipelines are published as images to the edge registry set in the Enable Wallaroo Edge Registry with the wallaroo.pipeline.publish method.
Publish a Pipeline Parameters
The publish method takes the following parameters. The containerized pipeline will be pushed to the Edge registry service with the model, pipeline configurations, and other artifacts needed to deploy the pipeline.
| Parameter | Type | Description |
|---|---|---|
deployment_config | wallaroo.deployment_config.DeploymentConfig (Optional) | Sets the pipeline deployment configuration. For example: For more information on pipeline deployment configuration, see the Wallaroo SDK Essentials Guide: Pipeline Deployment Configuration. |
Publish a Pipeline Returns
| Field | Type | Description |
|---|---|---|
| id | integer | Numerical Wallaroo id of the published pipeline. |
| pipeline version id | integer | Numerical Wallaroo id of the pipeline version published. |
| status | string | The status of the pipeline publication. Values include:
|
| Engine URL | string | The URL of the published pipeline engine in the edge registry. |
| Pipeline URL | string | The URL of the published pipeline in the edge registry. |
| Helm Chart URL | string | The URL of the helm chart for the published pipeline in the edge registry. |
| Helm Chart Reference | string | The help chart reference. |
| Helm Chart Version | string | The version of the Helm Chart of the published pipeline. This is also used as the Docker tag. |
| Engine Config | wallaroo.deployment_config.DeploymentConfig | The pipeline configuration included with the published pipeline. |
| Created At | DateTime | When the published pipeline was created. |
| Updated At | DateTime | When the published pipeline was updated. |
Publish a Pipeline Example
The following example shows how to publish a pipeline to the edge registry service associated with the Wallaroo instance.
# set the configuration
deployment_config = wallaroo.DeploymentConfigBuilder().replica_count(1).cpus(0.5).memory("900Mi").build()
# build the pipeline
pipeline = wl.build_pipeline("publish-example")
# add a model as a model step
pipeline.add_model_step(m2)
publish = pipeline.publish(deployment_config)
display(publish)
| ID | 4 |
| Pipeline Version ID | 10 |
| Status | Published |
| Engine URL | sample-registry.example.com/engine:main |
| Pipeline URL | sample-registry.example.com/pipelines/p1:6c3d9899-1335-456b-aaa0-52d03a017cc4 |
| Helm Chart URL | sample-registry.example.com/charts/p1 |
| Helm Chart Reference | sample-registry.example.com/charts@sha256:5523891f66fde830a9fc08603b3536dc2c4c1b16b51931ad2fdf9839e6eba129 |
| Helm Chart Version | 0.0.1-6c3d9899-1335-456b-aaa0-52d03a017cc4 |
| Engine Config | {’engine’: {‘resources’: {’limits’: {‘cpu’: 0.5, ‘memory’: ‘900Mi’}, ‘requests’: {‘cpu’: 0.5, ‘memory’: ‘900Mi’}}}, ’engineAux’: {‘images’: {}}, ’enginelb’: {}} |
| Created By | db13ee60-4162-4a42-a571-61c32e225e3e |
| Created At | 2023-08-17 14:04:44.939862+00:00 |
| Updated At | 2023-08-17 14:04:44.939862+00:00 |
List Publishes
All publishes created from a pipeline are displayed with the wallaroo.pipeline.publishes method.
List Publishes Parameters
N/A
List Publishes Returns
A List of the following fields:
| Field | Type | Description |
|---|---|---|
| id | integer | Numerical Wallaroo id of the published pipeline. |
| pipeline_version_id | integer | Numerical Wallaroo id of the pipeline version published. |
| engine_url | string | The URL of the published pipeline engine in the edge registry. |
| pipeline_url | string | The URL of the published pipeline in the edge registry. |
| created_by | string | The email address of the user that published the pipeline. |
| Created At | DateTime | When the published pipeline was created. |
| Updated At | DateTime | When the published pipeline was updated. |
List Publishes Example
The following shows a list of publishes from a pipeline.
pipeline.publishes()
| id | pipeline_version_id | engine_url | pipeline_url | created_by | created_at | updated_at |
|---|---|---|---|---|---|---|
| 1 | 4 | sample-registry.example.com/engine:main | sample-registry.example.com/pipelines/p1:01ab76f3-d007-48c4-870d-3d3c5a46902d | db13ee60-4162-4a42-a571-61c32e225e3e | 2023-16-Aug 20:22:31 | 2023-16-Aug 20:22:31 |
| 2 | 6 | sample-registry.example.com/engine:main | sample-registry.example.com/pipelines/p1:d3fb1b50-fe9a-4f54-bc32-fb9ff4ba49ee | db13ee60-4162-4a42-a571-61c32e225e3e | 2023-17-Aug 12:43:46 | 2023-17-Aug 12:43:46 |
| 3 | 8 | sample-registry.example.com/engine:main | sample-registry.example.com/pipelines/p1:97548f13-a791-41f5-bd54-c75649b72856 | db13ee60-4162-4a42-a571-61c32e225e3e | 2023-17-Aug 13:52:38 | 2023-17-Aug 13:52:38 |
| 4 | 10 | sample-registry.example.com/engine:main | sample-registry.example.com/pipelines/p1:6c3d9899-1335-456b-aaa0-52d03a017cc4 | db13ee60-4162-4a42-a571-61c32e225e3e | 2023-17-Aug 14:04:44 | 2023-17-Aug 14:04:44 |
Edge Observability
Edge Observability allows edge deployments of Wallaroo Server to transmit inference results back to the Wallaroo Ops center and become part of the pipeline’s logs. This is valuable for data scientists and MLOps engineers to retrieve edge deployment logs for use in model observability, drift, and other use cases.
Before starting, the Edge Observability Service must be enabled in the Wallaroo Ops center. See the Edge Deployment Registry Guide for details on enabling the Wallaroo Edge Deployment service.
Wallaroo Server edge observability is enabled when a new edge location is added to the pipeline publish. Each location has its own EDGE_BUNDLE settings, a Base64 encoded set of instructions informing the edge deployed Wallaroo Server on how to communicate with Wallaroo Ops center.
Add Edge
Wallaroo Servers edge deployments are added to a Wallaroo pipeline’s publish with the wallaroo.pipeline_publish.add_edge(name: string, tags: List[string]) method. The name is the unique primary key for each edge added to the pipeline publish and must be unique.
Add Edge Parameters
wallaroo.pipeline_publish.add_edge(name: string, tags: List[string]) has the following parameters.
| Field | Type | Description |
|---|---|---|
name | String (Required) | The name of the edge location. This must be a unique value across all edges in the Wallaroo instance. |
tags | List[String] (Optional) | A list of optional tags. |
Add Edge Returns
This returns a Publish Edge with the following fields:
| Field | Type | Description |
|---|---|---|
id | Integer | The integer ID of the pipeline publish. |
created_at | DateTime | The DateTime of the pipeline publish. |
docker_run_variables | String | The Docker variables in JSON entry with the key EDGE_BUNDLE as a base64 encoded value that include the following: The BUNDLE_VERSION, EDGE_NAME, JOIN_TOKEN_, OPSCENTER_HOST, PIPELINE_URL, and WORKSPACE_ID. For example: {'EDGE_BUNDLE': 'abcde'} |
engine_config | String | The Wallaroo wallaroo.deployment_config.DeploymentConfig for the pipeline. |
pipeline_version_id | Integer | The integer identifier of the pipeline version published. |
status | String | The status of the publish. Published is a successful publish. |
updated_at | DateTime | The DateTime when the pipeline publish was updated. |
user_images | List[String] | User images used in the pipeline publish. |
created_by | String | The UUID of the Wallaroo user that created the pipeline publish. |
engine_url | String | The URL for the published pipeline’s Wallaroo engine in the OCI registry. |
error | String | Any errors logged. |
helm | String | The helm chart, helm reference and helm version. |
pipeline_url | String | The URL for the published pipeline’s container in the OCI registry. |
pipeline_version_name | String | The UUID identifier of the pipeline version published. |
additional_properties | String | Any other identities. |
Add Edge Example
The following example demonstrates creating a publish from a pipeline, then adding a new edge to the publish.
# create publish
xgb_pub=xgboost_pipeline_version.publish(deploy_config)
display(xgb_pub)
Waiting for pipeline publish... It may take up to 600 sec.
Pipeline is Publishing...Published.
| ID | 1 |
| Pipeline Version | f388c109-8d57-4ed2-9806-aa13f854576b |
| Status | Published |
| Engine URL | ghcr.io/wallaroolabs/doc-samples/engines/proxy/wallaroo/ghcr.io/wallaroolabs/standalone-mini:v2023.4.0-main-4079 |
| Pipeline URL | ghcr.io/wallaroolabs/doc-samples/pipelines/edge-pipeline:f388c109-8d57-4ed2-9806-aa13f854576b |
| Helm Chart URL | oci://ghcr.io/wallaroolabs/doc-samples/charts/edge-pipeline |
| Helm Chart Reference | ghcr.io/wallaroolabs/doc-samples/charts@sha256:429aae187be641c22de5a333c737219a5ffaf908ac3673781cdf83f4ebbf7abc |
| Helm Chart Version | 0.0.1-f388c109-8d57-4ed2-9806-aa13f854576b |
| Engine Config | {'engine': {'resources': {'limits': {'cpu': 1.0, 'memory': '512Mi'}, 'requests': {'cpu': 1.0, 'memory': '512Mi'}}}, 'engineAux': {'images': {}}, 'enginelb': {'resources': {'limits': {'cpu': 1.0, 'memory': '512Mi'}, 'requests': {'cpu': 1.0, 'memory': '512Mi'}}}} |
| User Images | [] |
| Created By | john.hummel@wallaroo.ai |
| Created At | 2023-10-29 23:35:03.508703+00:00 |
| Updated At | 2023-10-29 23:35:03.508703+00:00 |
| Docker Run Variables | {} |
xgb_edge = xgb_pub.add_edge("xgb-ccfraud-edge-publish")
print(xgb_edge)
| ID | 2 |
| Pipeline Version | 60fb5c6e-db3e-497d-afc8-ccc149beba4a |
| Status | Published |
| Engine URL | ghcr.io/wallaroolabs/doc-samples/engines/proxy/wallaroo/ghcr.io/wallaroolabs/standalone-mini:v2023.4.0-main-4079 |
| Pipeline URL | ghcr.io/wallaroolabs/doc-samples/pipelines/edge-pipeline:60fb5c6e-db3e-497d-afc8-ccc149beba4a |
| Helm Chart URL | oci://ghcr.io/wallaroolabs/doc-samples/charts/edge-pipeline |
| Helm Chart Reference | ghcr.io/wallaroolabs/doc-samples/charts@sha256:2de830d875ac8e60984c391091e5fdc981ad74e56925545c99b5e5b222c612bc |
| Helm Chart Version | 0.0.1-60fb5c6e-db3e-497d-afc8-ccc149beba4a |
| Engine Config | {'engine': {'resources': {'limits': {'cpu': 1.0, 'memory': '512Mi'}, 'requests': {'cpu': 1.0, 'memory': '512Mi'}}}, 'engineAux': {'images': {}}, 'enginelb': {'resources': {'limits': {'cpu': 1.0, 'memory': '512Mi'}, 'requests': {'cpu': 1.0, 'memory': '512Mi'}}}} |
| User Images | [] |
| Created By | john.hummel@wallaroo.ai |
| Created At | 2023-10-29 23:35:21.956532+00:00 |
| Updated At | 2023-10-29 23:35:21.956532+00:00 |
| Docker Run Variables | {'EDGE_BUNDLE': 'abcde'} |
Remove Edge
Edges are removed with the wallaroo.pipeline_publish.remove_edge(name: string)
Remove Edge Parameters
wallaroo.pipeline_publish.remove_edge(name: string) has the following parameters.
| Field | Type | Description |
|---|---|---|
name | String (Required) | The name of the edge location being removed. |
Remove Edge Returns
Null
Remove Edge Example
This example will add two edges to a pipeline publish, list the edges for the pipeline, then remove one of the edges.
edge_01_name = f'edge-ccfraud-observability{random_suffix}'
edge01 = pub.add_edge(edge_01_name)
edge_02_name = f'edge-ccfraud-observability-02{random_suffix}'
edge02 = pub.add_edge(edge_02_name)
pipeline.list_edges()
| ID | Name | Tags | Pipeline Version | SPIFFE ID |
|---|---|---|---|---|
| 898bb58c-77c2-4164-b6cc-f004dc39e125 | edge-ccfraud-observabilityymgy | [] | 6 | wallaroo.ai/ns/deployments/edge/898bb58c-77c2-4164-b6cc-f004dc39e125 |
| 1f35731a-f4f6-4cd0-a23a-c4a326b73277 | edge-ccfraud-observability-02ymgy | [] | 6 | wallaroo.ai/ns/deployments/edge/1f35731a-f4f6-4cd0-a23a-c4a326b73277 |
sample = pub.remove_edge(edge_02_name)
display(sample)
| ID | Name | Tags | Pipeline Version | SPIFFE ID |
|---|---|---|---|---|
| 898bb58c-77c2-4164-b6cc-f004dc39e125 | edge-ccfraud-observabilityymgy | [] | 6 | wallaroo.ai/ns/deployments/edge/898bb58c-77c2-4164-b6cc-f004dc39e125 |
List Edges
The method wallaroo.pipeline.list_edges() displays any edges added to a pipeline’s publishes.
List Edges Parameters
None
List Edges Returns
The following fields are returned from a List of edges.
| Parameter | Type | Description |
|---|---|---|
cpus | Float | The number of cpus assigned as part of the pipeline configuration. |
id | String | The identifier of the edge in UUID format. |
memory | String | The memory assigned as part of the pipeline configuration in Kubernetes memory format. |
name | String | The assigned name for the edge. Edge names are used as the primary key. |
tags | List[String] | A list of tags assigned to the edge. |
pipeline_version_id | Integer | The pipeline version numerical idenfier. |
spiffe_id | String | The deployment edge identifier used to for edge communications. |
additional_properties | Dict | Any additional properties. |
List Edges Example
edge_01_name = f'edge-ccfraud-observability{random_suffix}'
edge01 = pub.add_edge(edge_01_name)
edge_02_name = f'edge-ccfraud-observability-02{random_suffix}'
edge02 = pub.add_edge(edge_02_name)
pipeline.list_edges()
| ID | Name | Tags | Pipeline Version | SPIFFE ID |
|---|---|---|---|---|
| 898bb58c-77c2-4164-b6cc-f004dc39e125 | edge-ccfraud-observabilityymgy | [] | 6 | wallaroo.ai/ns/deployments/edge/898bb58c-77c2-4164-b6cc-f004dc39e125 |
| 1f35731a-f4f6-4cd0-a23a-c4a326b73277 | edge-ccfraud-observability-02ymgy | [] | 6 | wallaroo.ai/ns/deployments/edge/1f35731a-f4f6-4cd0-a23a-c4a326b73277 |
Edge Bundle Token TTL
When an edge is added to a pipeline publish, the field docker_run_variables contains a JSON value for edge devices to connect to the Wallaroo Ops instance. The settings are stored in the key EDGE_BUNDLE as a base64 encoded value that include the following:
BUNDLE_VERSION: The current version of the bundled Wallaroo pipeline.EDGE_NAME: The edge name as defined when created and added to the pipeline publish.JOIN_TOKEN_: The one time authentication token for authenticating to the Wallaroo Ops instance.OPSCENTER_HOST: The hostname of the Wallaroo Ops edge service. See Edge Deployment Registry Guide for full details on enabling pipeline publishing and edge observability to Wallaroo.PIPELINE_URLWORKSPACE_ID.
For example:
{'edgeBundle': 'ZXhwb3J0IEJVTkRMRV9WRVJTSU9OPTEKZXhwb3J0IEVER0VfTkFNRT14Z2ItY2NmcmF1ZC1lZGdlLXRlc3QKZXhwb3J0IEpPSU5fVE9LRU49MzE0OGFkYTUtMjg1YS00ZmNhLWIzYjgtYjUwYTQ4ZDc1MTFiCmV4cG9ydCBPUFNDRU5URVJfSE9TVD1kb2MtdGVzdC5lZGdlLndhbGxhcm9vY29tbXVuaXR5Lm5pbmphCmV4cG9ydCBQSVBFTElORV9VUkw9Z2hjci5pby93YWxsYXJvb2xhYnMvZG9jLXNhbXBsZXMvcGlwZWxpbmVzL2VkZ2UtcGlwZWxpbmU6ZjM4OGMxMDktOGQ1Ny00ZWQyLTk4MDYtYWExM2Y4NTQ1NzZiCmV4cG9ydCBXT1JLU1BBQ0VfSUQ9NQ=='}
base64 -D
ZXhwb3J0IEJVTkRMRV9WRVJTSU9OPTEKZXhwb3J0IEVER0VfTkFNRT14Z2ItY2NmcmF1ZC1lZGdlLXRlc3QKZXhwb3J0IEpPSU5fVE9LRU49MzE0OGFkYTUtMjg1YS00ZmNhLWIzYjgtYjUwYTQ4ZDc1MTFiCmV4cG9ydCBPUFNDRU5URVJfSE9TVD1kb2MtdGVzdC5lZGdlLndhbGxhcm9vY29tbXVuaXR5Lm5pbmphCmV4cG9ydCBQSVBFTElORV9VUkw9Z2hjci5pby93YWxsYXJvb2xhYnMvZG9jLXNhbXBsZXMvcGlwZWxpbmVzL2VkZ2UtcGlwZWxpbmU6ZjM4OGMxMDktOGQ1Ny00ZWQyLTk4MDYtYWExM2Y4NTQ1NzZiCmV4cG9ydCBXT1JLU1BBQ0VfSUQ9NQ==^D
export BUNDLE_VERSION=1
export EDGE_NAME=xgb-ccfraud-edge-test
export JOIN_TOKEN=3148ada5-285a-4fca-b3b8-b50a48d7511b
export OPSCENTER_HOST=doc-test.edge.wallaroocommunity.ninja
export PIPELINE_URL=ghcr.io/wallaroolabs/doc-samples/pipelines/edge-pipeline:f388c109-8d57-4ed2-9806-aa13f854576b
export WORKSPACE_ID=5
The JOIN_TOKEN is a one time access token. Once used, a JOIN_TOKEN expires. The authentication session data is stored in persistent volumes. Persistent volumes must be specified for docker and docker compose based deployments of Wallaroo pipelines; helm based deployments automatically provide persistent volumes to store authentication credentials.
The JOIN_TOKEN has the following time to live (TTL) parameters.
- Once created, the
JOIN_TOKENis valid for 24 hours. After it expires the edge will not be allowed to contact the OpsCenter the first time and a new edge bundle will have to be created. - After an Edge joins to Wallaroo Ops for the first time with persistent storage, the edge must contact the Wallaroo Ops instance at least once every 7 days.
- If this period is exceeded, the authentication credentials will expire and a new edge bundle must be created with a new and valid
JOIN_TOKEN.
- If this period is exceeded, the authentication credentials will expire and a new edge bundle must be created with a new and valid
Wallaroo edges require unique names. To create a new edge bundle with the same name:
- Use the Remove Edge to remove the edge by name.
- Use Add Edge to add the edge with the same name. A new
EDGE_BUNDLEis generated with a newJOIN_TOKEN.
DevOps - Pipeline Edge Deployment
Once a pipeline is deployed to the Edge Registry service, it can be deployed in environments such as Docker, Kubernetes, or similar container running services by a DevOps engineer.
Docker Deployment
First, the DevOps engineer must authenticate to the same OCI Registry service used for the Wallaroo Edge Deployment registry.
For more details, check with the documentation on your artifact service. The following are provided for the three major cloud services:
- Set up authentication for Docker
- Authenticate with an Azure container registry
- Authenticating Amazon ECR Repositories for Docker CLI with Credential Helper
For the deployment, the engine URL is specified with the following environmental variables:
DEBUG(true|false): Whether to include debug output.OCI_REGISTRY: The URL of the registry service.CONFIG_CPUS: The number of CPUs to use.OCI_USERNAME: The edge registry username.OCI_PASSWORD: The edge registry password or token.PIPELINE_URL: The published pipeline URL.EDGE_BUNDLE(Optional): The base64 encoded edge token and other values to connect to the Wallaroo Ops instance. This is used for edge management and transmitting inference results for observability. IMPORTANT NOTE: The token forEDGE_BUNDLEis valid for one deployment. For subsequent deployments, generate a new edge location with its ownEDGE_BUNDLE.
Docker Deployment Example
Using our sample environment, here’s sample deployment using Docker with a computer vision ML model, the same used in the Wallaroo Use Case Tutorials Computer Vision: Retail tutorials.
Login through
dockerto confirm access to the registry service. First,docker login. For example, logging into the artifact registry with the token stored in the variabletok:cat $tok | docker login -u _json_key_base64 --password-stdin https://sample-registry.comThen deploy the Wallaroo published pipeline with an edge added to the pipeline publish through
docker run.IMPORTANT NOTE: Edge deployments with Edge Observability enabled with the
EDGE_BUNDLEoption include an authentication token that only authenticates once. To store the token long term, include the persistent volume flag-v {path to storage}setting.Deployment with
EDGE_BUNDLEfor observability.docker run -p 8080:8080 \ -v ./data:/persist \ -e DEBUG=true \ -e OCI_REGISTRY=$REGISTRYURL \ -e EDGE_BUNDLE=ZXhwb3J0IEJVTkRMRV9WRVJTSU9OPTEKZXhwb3J0IEVER0VfTkFNRT1lZGdlLWNjZnJhdWQtb2JzZXJ2YWJpbGl0eXlhaWcKZXhwb3J0IEpPSU5fVE9LRU49MjZmYzFjYjgtMjUxMi00YmU3LTk0ZGUtNjQ2NGI1MGQ2MzhiCmV4cG9ydCBPUFNDRU5URVJfSE9TVD1kb2MtdGVzdC5lZGdlLndhbGxhcm9vY29tbXVuaXR5Lm5pbmphCmV4cG9ydCBQSVBFTElORV9VUkw9Z2hjci5pby93YWxsYXJvb2xhYnMvZG9jLXNhbXBsZXMvcGlwZWxpbmVzL2VkZ2Utb2JzZXJ2YWJpbGl0eS1waXBlbGluZTozYjQ5ZmJhOC05NGQ4LTRmY2EtYWVjYy1jNzUyNTdmZDE2YzYKZXhwb3J0IFdPUktTUEFDRV9JRD03 \ -e CONFIG_CPUS=1 \ -e OCI_USERNAME=$REGISTRYUSERNAME \ -e OCI_PASSWORD=$REGISTRYPASSWORD \ -e PIPELINE_URL=ghcr.io/wallaroolabs/doc-samples/pipelines/edge-observability-pipeline:3b49fba8-94d8-4fca-aecc-c75257fd16c6 \ ghcr.io/wallaroolabs/doc-samples/engines/proxy/wallaroo/ghcr.io/wallaroolabs/standalone-mini:v2023.4.0-main-4079Connection to the Wallaroo Ops instance from edge deployment with
EDGE_BUNDLEis verified with the long entryNode attestation was successful.Deployment without observability.
docker run -p 8080:8080 \ -e DEBUG=true \ -e OCI_REGISTRY=$REGISTRYURL \ -e CONFIG_CPUS=1 \ -e OCI_USERNAME=$REGISTRYUSERNAME \ -e OCI_PASSWORD=$REGISTRYPASSWORD \ -e PIPELINE_URL=ghcr.io/wallaroolabs/doc-samples/pipelines/edge-observability-pipeline:3b49fba8-94d8-4fca-aecc-c75257fd16c6 \ ghcr.io/wallaroolabs/doc-samples/engines/proxy/wallaroo/ghcr.io/wallaroolabs/standalo
Docker Compose Deployment
For users who prefer to use docker compose, the following sample compose.yaml file is used to launch the Wallaroo Edge pipeline. This is the same used in the Wallaroo Use Case Tutorials Computer Vision: Retail tutorials. The volumes tag is used to preserve the login session from the one-time token generated as part of the EDGE_BUNDLE.
EDGE_BUNDLE is only required when adding an edge to a Wallaroo publish for observability. The following is deployed without observability.
services:
engine:
image: {Your Engine URL}
ports:
- 8080:8080
environment:
PIPELINE_URL: {Your Pipeline URL}
OCI_REGISTRY: {Your Edge Registry URL}
OCI_USERNAME: {Your Registry Username}
OCI_PASSWORD: {Your Token or Password}
CONFIG_CPUS: 4
The procedure is:
Login through
dockerto confirm access to the registry service. First,docker login. For example, logging into the artifact registry with the token stored in the variabletokto the registryus-west1-docker.pkg.dev:cat $tok | docker login -u _json_key_base64 --password-stdin https://sample-registry.comSet up the
compose.yamlfile.IMPORTANT NOTE: Edge deployments with Edge Observability enabled with the
EDGE_BUNDLEoption include an authentication token that only authenticates once. To store the token long term, include the persistent volume with thevolumes:tag.services: engine: image: sample-registry.com/engine:v2023.3.0-main-3707 ports: - 8080:8080 volumes: - ./data:/persist environment: PIPELINE_URL: sample-registry.com/pipelines/edge-cv-retail:bf70eaf7-8c11-4b46-b751-916a43b1a555 EDGE_BUNDLE: ZXhwb3J0IEJVTkRMRV9WRVJTSU9OPTEKZXhwb3J0IEVER0VfTkFNRT1lZGdlLWNjZnJhdWQtb2JzZXJ2YWJpbGl0eXlhaWcKZXhwb3J0IEpPSU5fVE9LRU49MjZmYzFjYjgtMjUxMi00YmU3LTk0ZGUtNjQ2NGI1MGQ2MzhiCmV4cG9ydCBPUFNDRU5URVJfSE9TVD1kb2MtdGVzdC5lZGdlLndhbGxhcm9vY29tbXVuaXR5Lm5pbmphCmV4cG9ydCBQSVBFTElORV9VUkw9Z2hjci5pby93YWxsYXJvb2xhYnMvZG9jLXNhbXBsZXMvcGlwZWxpbmVzL2VkZ2Utb2JzZXJ2YWJpbGl0eS1waXBlbGluZTozYjQ5ZmJhOC05NGQ4LTRmY2EtYWVjYy1jNzUyNTdmZDE2YzYKZXhwb3J0IFdPUktTUEFDRV9JRD03 OCI_REGISTRY: sample-registry.com OCI_USERNAME: _json_key_base64 OCI_PASSWORD: abc123 CONFIG_CPUS: 4Then deploy with
docker compose up.
Docker Compose Deployment Example
The deployment and undeployment is then just a simple docker compose up and docker compose down. The following shows an example of deploying the Wallaroo edge pipeline using docker compose.
docker compose up
[+] Running 1/1
✔ Container cv_data-engine-1 Recreated 0.5s
Attaching to cv_data-engine-1
cv_data-engine-1 | Wallaroo Engine - Standalone mode
cv_data-engine-1 | Login Succeeded
cv_data-engine-1 | Fetching manifest and config for pipeline: sample-registry.com/pipelines/edge-cv-retail:bf70eaf7-8c11-4b46-b751-916a43b1a555
cv_data-engine-1 | Fetching model layers
cv_data-engine-1 | digest: sha256:c6c8869645962e7711132a7e17aced2ac0f60dcdc2c7faa79b2de73847a87984
cv_data-engine-1 | filename: c6c8869645962e7711132a7e17aced2ac0f60dcdc2c7faa79b2de73847a87984
cv_data-engine-1 | name: resnet-50
cv_data-engine-1 | type: model
cv_data-engine-1 | runtime: onnx
cv_data-engine-1 | version: 693e19b5-0dc7-4afb-9922-e3f7feefe66d
cv_data-engine-1 |
cv_data-engine-1 | Fetched
cv_data-engine-1 | Starting engine
cv_data-engine-1 | Looking for preexisting `yaml` files in //modelconfigs
cv_data-engine-1 | Looking for preexisting `yaml` files in //pipelines
Helm Deployment
Published pipelines can be deployed through the use of helm charts.
Helm deployments take up to two steps - the first step is in retrieving the required values.yaml and making updates to override.
IMPORTANT NOTE: Edge deployments with Edge Observability enabled with the EDGE_BUNDLE option include an authentication token that only authenticates once. Helm chart installations automatically add a persistent volume during deployment to store the authentication session data for future deployments.
Login to the registry service with
helm registry login. For example, if the token is stored in the variabletok:helm registry login sample-registry.com --username _json_key_base64 --password $tokPull the helm charts from the published pipeline. The two fields are the Helm Chart URL and the Helm Chart version to specify the OCI . This typically takes the format of:
helm pull oci://{published.helm_chart_url} --version {published.helm_chart_version}Extract the
tgzfile and copy thevalues.yamland copy the values used to edit engine allocations, etc. The following are required for the deployment to run:ociRegistry: registry: {your registry service} username: {registry username here} password: {registry token here}For Wallaroo Server deployments with edge location set, the values include
edgeBundleas generated when the edge was added to the pipeline publish.ociRegistry: registry: {your registry service} username: {registry username here} password: {registry token here} edgeBundle: abcdefg
Store this into another file, suc as local-values.yaml.
Create the namespace to deploy the pipeline to. For example, the namespace
wallaroo-edge-pipelinewould be:kubectl create -n wallaroo-edge-pipelineDeploy the
helminstallation withhelm installthrough one of the following options:Specify the
tgzfile that was downloaded and the local values file. For example:helm install --namespace {namespace} --values {local values file} {helm install name} {tgz path}Specify the expended directory from the downloaded
tgzfile.helm install --namespace {namespace} --values {local values file} {helm install name} {helm directory path}Specify the Helm Pipeline Helm Chart and the Pipeline Helm Version.
helm install --namespace {namespace} --values {local values file} {helm install name} oci://{published.helm_chart_url} --version {published.helm_chart_version}
Once deployed, the DevOps engineer will have to forward the appropriate ports to the
svc/engine-svcservice in the specific pipeline. For example, usingkubectl port-forwardto the namespaceccfraudthat would be:kubectl port-forward svc/engine-svc -n ccfraud01 8080 --address 0.0.0.0`
Edge Deployment Endpoints
The following endpoints are available for API calls to the edge deployed pipeline.
List Pipelines
The endpoint /pipelines returns:
- id (String): The name of the pipeline.
- status (String): The status as either
Running, orErrorif there are any issues.
List Pipelines Example
curl localhost:8080/pipelines
{"pipelines":[{"id":"edge-cv-retail","status":"Running"}]}
List Models
The endpoint /models returns a List of models with the following fields:
- name (String): The model name.
- sha (String): The sha hash value of the ML model.
- status (String): The status of either Running or Error if there are any issues.
- version (String): The model version. This matches the version designation used by Wallaroo to track model versions in UUID format.
List Models Example
curl localhost:8080/models
{"models":[{"name":"resnet-50","sha":"c6c8869645962e7711132a7e17aced2ac0f60dcdc2c7faa79b2de73847a87984","status":"Running","version":"693e19b5-0dc7-4afb-9922-e3f7feefe66d"}]}
Edge Inference Endpoint
The inference endpoint takes the following pattern:
/pipelines/{pipeline-name}: Thepipeline-nameis the same as returned from the/pipelinesendpoint asid.
Wallaroo inference endpoint URLs accept the following data inputs through the Content-Type header:
Content-Type: application/vnd.apache.arrow.file: For Apache Arrow tables.Content-Type: application/json; format=pandas-records: For pandas DataFrame in record format.
Once deployed, we can perform an inference through the deployment URL.
The endpoint returns Content-Type: application/json; format=pandas-records by default with the following fields:
- check_failures (List[Integer]): Whether any validation checks were triggered. For more information, see Wallaroo SDK Essentials Guide: Pipeline Management: Anomaly Testing.
- elapsed (List[Integer]): A list of time in nanoseconds for:
- [0] The time to serialize the input.
- [1…n] How long each step took.
- model_name (String): The name of the model used.
- model_version (String): The version of the model in UUID format.
- original_data: The original input data. Returns
nullif the input may be too long for a proper return. - outputs (List): The outputs of the inference result separated by data type, where each data type includes:
- data: The returned values.
- dim (List[Integer]): The dimension shape returned.
- v (Integer): The vector shape of the data.
- pipeline_name (String): The name of the pipeline.
- shadow_data: Any shadow deployed data inferences in the same format as outputs.
- time (Integer): The time since UNIX epoch.
Edge Inference Endpoint Example
The following example demonstrates sending an Apache Arrow table to the Edge deployed pipeline, requesting the inference results back in a pandas DataFrame records format.
curl -X POST localhost:8080/pipelines/edge-cv-retail -H "Content-Type: application/vnd.apache.arrow.file" -H 'Accept: application/json; format=pandas-records' --data-binary @./data/image_224x224.arrow
Returns:
[{"check_failures":[],"elapsed":[1067541,21209776],"model_name":"resnet-50","model_version":"2e05e1d0-fcb3-4213-bba8-4bac13f53e8d","original_data":null,"outputs":[{"Int64":{"data":[535],"dim":[1],"v":1}},{"Float":{"data":[0.00009498586587142199,0.00009141524787992239,0.0004606838047038764,0.00007667174941161647,0.00008047101437114179,...],"dim":[1,1001],"v":1}}],"pipeline_name":"edge-cv-demo","shadow_data":{},"time":1694205578428}]
Edge Bundle Token Time To Live
When an edge is added to a pipeline publish, the field docker_run_variables contains a JSON value for edge devices to connect to the Wallaroo Ops instance.
The settings are stored in the key EDGE_BUNDLE as a base64 encoded value that include the following:
BUNDLE_VERSION: The current version of the bundled Wallaroo pipeline.EDGE_NAME: The edge name as defined when created and added to the pipeline publish.JOIN_TOKEN_: The one time authentication token for authenticating to the Wallaroo Ops instance.OPSCENTER_HOST: The hostname of the Wallaroo Ops edge service. See Edge Deployment Registry Guide for full details on enabling pipeline publishing and edge observability to Wallaroo.PIPELINE_URL: The OCI registry URL to the containerized pipeline.WORKSPACE_ID: The numerical ID of the workspace.
For example:
{'edgeBundle': 'ZXhwb3J0IEJVTkRMRV9WRVJTSU9OPTEKZXhwb3J0IEVER0VfTkFNRT14Z2ItY2NmcmF1ZC1lZGdlLXRlc3QKZXhwb3J0IEpPSU5fVE9LRU49MzE0OGFkYTUtMjg1YS00ZmNhLWIzYjgtYjUwYTQ4ZDc1MTFiCmV4cG9ydCBPUFNDRU5URVJfSE9TVD1kb2MtdGVzdC5lZGdlLndhbGxhcm9vY29tbXVuaXR5Lm5pbmphCmV4cG9ydCBQSVBFTElORV9VUkw9Z2hjci5pby93YWxsYXJvb2xhYnMvZG9jLXNhbXBsZXMvcGlwZWxpbmVzL2VkZ2UtcGlwZWxpbmU6ZjM4OGMxMDktOGQ1Ny00ZWQyLTk4MDYtYWExM2Y4NTQ1NzZiCmV4cG9ydCBXT1JLU1BBQ0VfSUQ9NQ=='}
base64 -D
ZXhwb3J0IEJVTkRMRV9WRVJTSU9OPTEKZXhwb3J0IEVER0VfTkFNRT14Z2ItY2NmcmF1ZC1lZGdlLXRlc3QKZXhwb3J0IEpPSU5fVE9LRU49MzE0OGFkYTUtMjg1YS00ZmNhLWIzYjgtYjUwYTQ4ZDc1MTFiCmV4cG9ydCBPUFNDRU5URVJfSE9TVD1kb2MtdGVzdC5lZGdlLndhbGxhcm9vY29tbXVuaXR5Lm5pbmphCmV4cG9ydCBQSVBFTElORV9VUkw9Z2hjci5pby93YWxsYXJvb2xhYnMvZG9jLXNhbXBsZXMvcGlwZWxpbmVzL2VkZ2UtcGlwZWxpbmU6ZjM4OGMxMDktOGQ1Ny00ZWQyLTk4MDYtYWExM2Y4NTQ1NzZiCmV4cG9ydCBXT1JLU1BBQ0VfSUQ9NQ==^D
export BUNDLE_VERSION=1
export EDGE_NAME=xgb-ccfraud-edge-test
export JOIN_TOKEN=3148ada5-285a-4fca-b3b8-b50a48d7511b
export OPSCENTER_HOST=doc-test.edge.wallaroocommunity.ninja
export PIPELINE_URL=ghcr.io/wallaroolabs/doc-samples/pipelines/edge-pipeline:f388c109-8d57-4ed2-9806-aa13f854576b
export WORKSPACE_ID=5
The JOIN_TOKEN is a one time access token. Once used, a JOIN_TOKEN expires. The authentication session data is stored in persistent volumes. Persistent volumes must be specified for docker and docker compose based deployments of Wallaroo pipelines; helm based deployments automatically provide persistent volumes to store authentication credentials.
The JOIN_TOKEN has the following time to live (TTL) parameters.
- Once created, the
JOIN_TOKENis valid for 24 hours. After it expires the edge will not be allowed to contact the OpsCenter the first time and a new edge bundle will have to be created. - After an Edge joins to Wallaroo Ops for the first time with persistent storage, the edge must contact the Wallaroo Ops instance at least once every 7 days.
- If this period is exceeded, the authentication credentials will expire and a new edge bundle must be created with a new and valid
JOIN_TOKEN.
- If this period is exceeded, the authentication credentials will expire and a new edge bundle must be created with a new and valid
Wallaroo edges require unique names. To create a new edge bundle with the same name:
- Use the Remove Edge to remove the edge by name.
- Use Add Edge to add the edge with the same name. A new
EDGE_BUNDLEis generated with a newJOIN_TOKEN.