Drift Detection for Edge And Multicloud Model Deployments
How to detect drift in Wallaroo for Edge And Multicloud AI Model deployments.
Table of Contents
Edge Model Drift Detection with Model Insights via the Wallaroo Dashboard
Model Drift Detection with Model Insights via the Wallaroo Dashboard allows organizations to create assays that monitor inference requests and results against an established baseline.
The following focuses on model drift detection for model deployment on edge locations. For full details on managing assays and model drift detection through the Wallaroo Dashboard, see Model Drift Detection with Model Insights.
Prerequisites
To monitor inference requests and results on edge locations, the following prerequisites must be met:
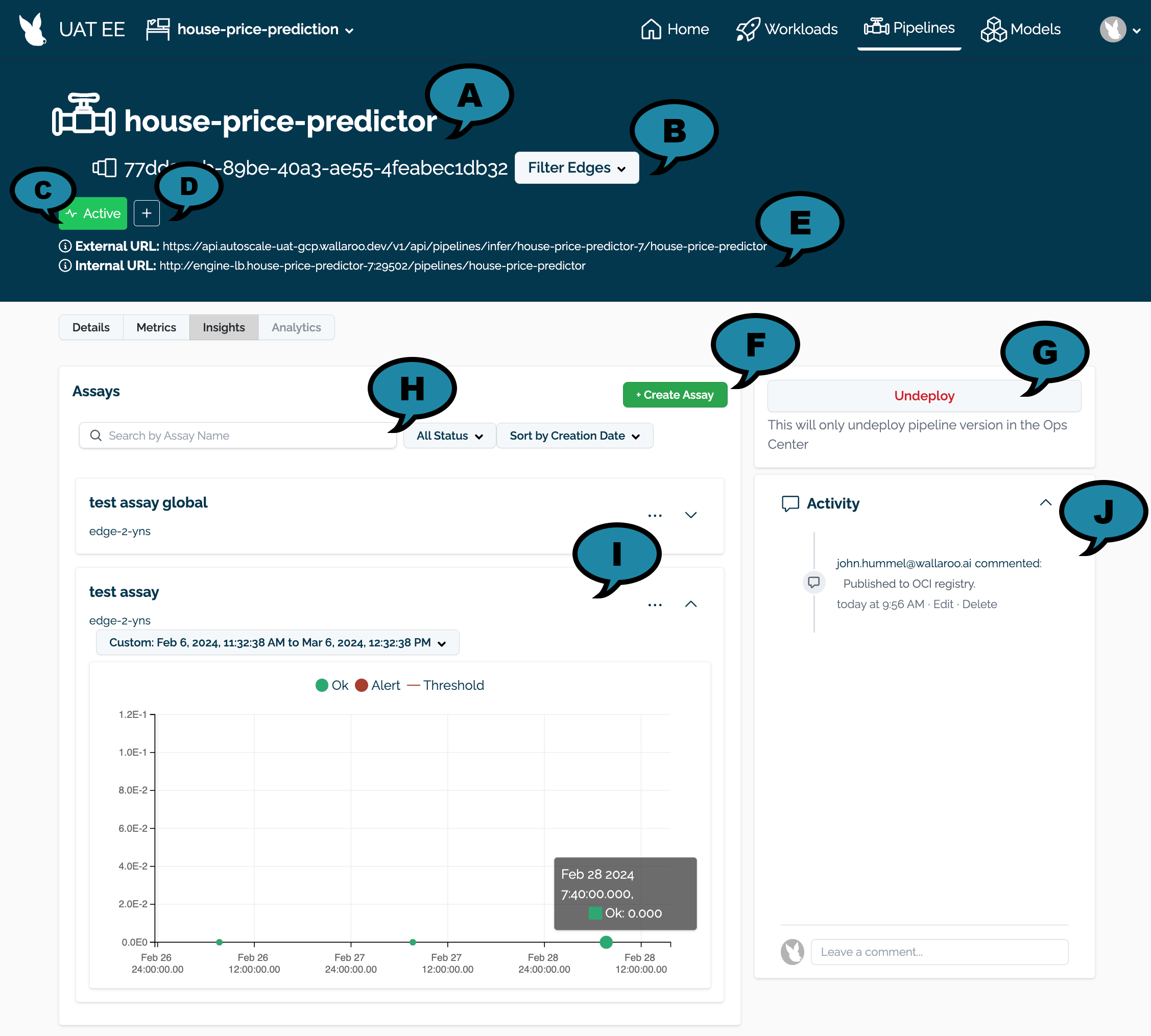
Edge deployments are filtered with the Filter Edges (B) option.
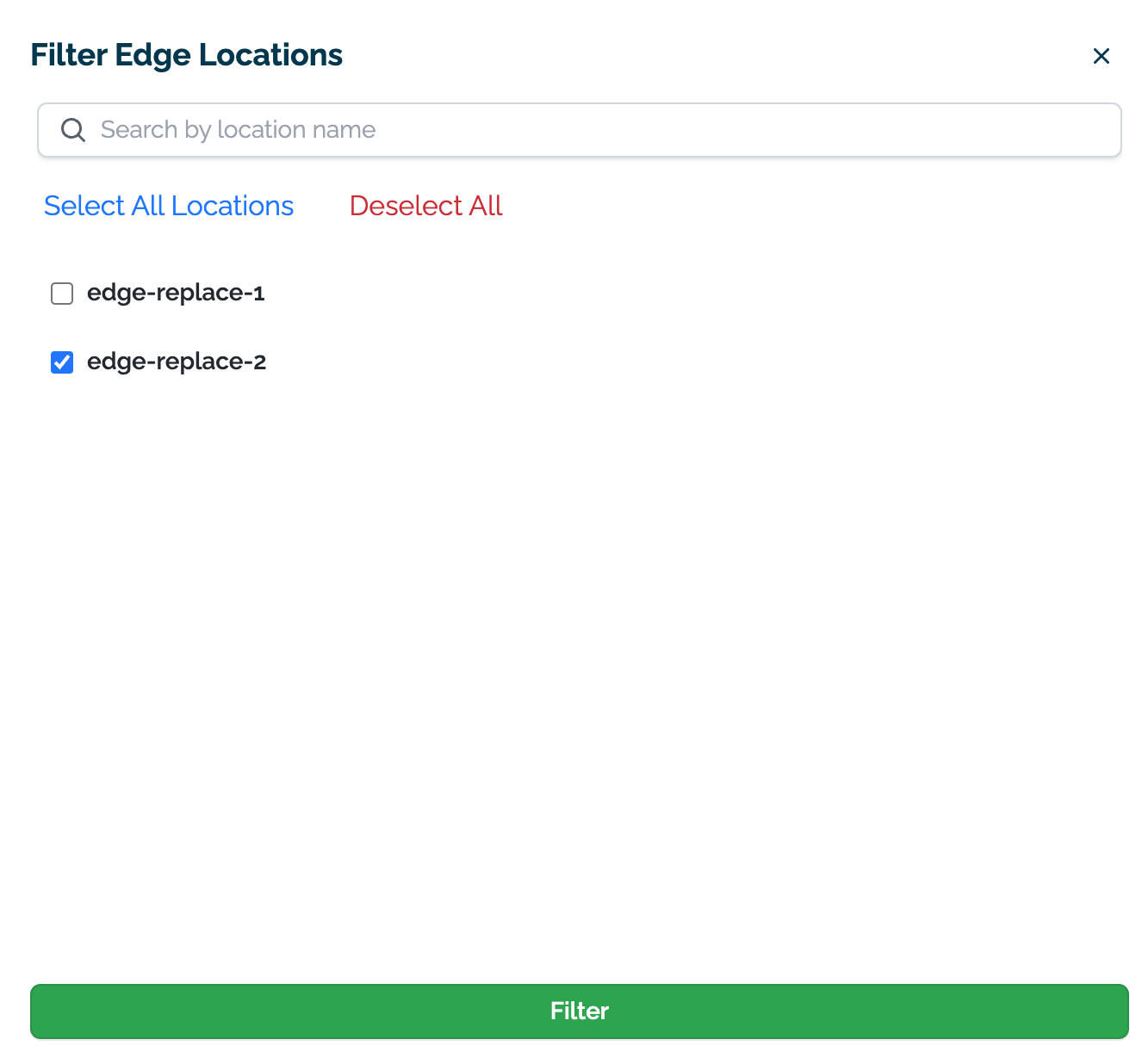
By default, all locations are displayed. Filter Edges provides a list of available edge deployments are displayed. Selecting one or more filters from the list limits the available metrics and logs displayed to only the selected locations.
Build a Edge Location Filtered Assay Through the Pipeline Dashboard
To create a new assay through the Wallaroo Pipeline Dashboard:
Log into the Wallaroo Dashboard.
Select the workspace containing the pipeline with the models being monitored from the Change Current Workspace and Workspace Management drop down.
Select View Pipelines.
Select the pipeline containing the models being monitored.
Select Insights.
Select Filter Edges and select the edge locations to include. By default, assays include all locations. By specifying edges in the filter, this restricts the inference inputs used for the assay baseline and assay analysis results to the specified locations.
Select +Create Assay.
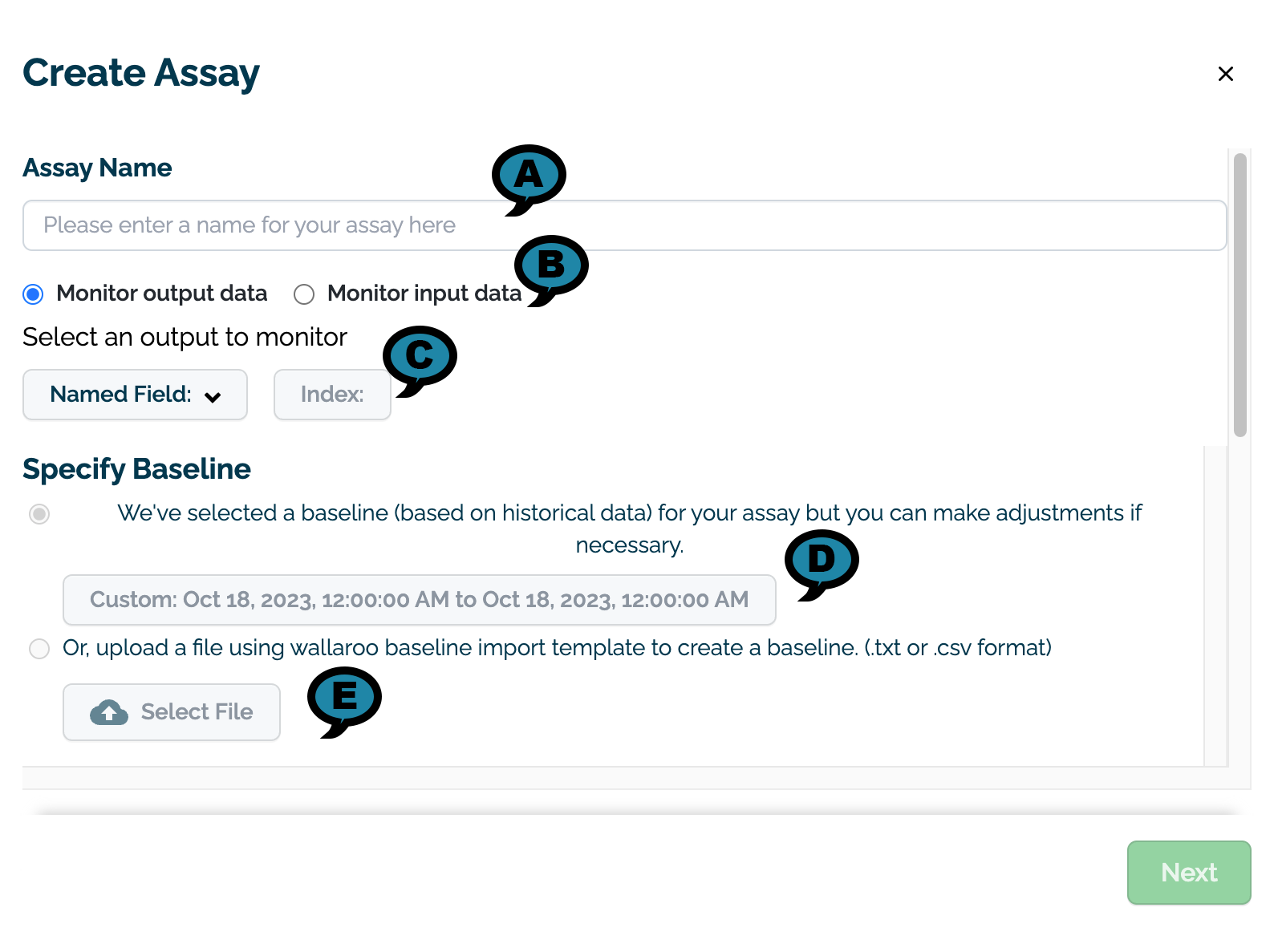
On the Create Assay module, enter the following:
On the Assay Name section, enter the following:
Assay Name(A): The name of the new assay.
Monitor output data or Monitor input data(B): Select whether to monitor input or output data.
Select an output/input to monitor(C): Select the input or output to monitor.
Named Field: The name of the field to monitor.
Index: The index of the monitored field.
On the Specify Baseline section, select one of the following options:
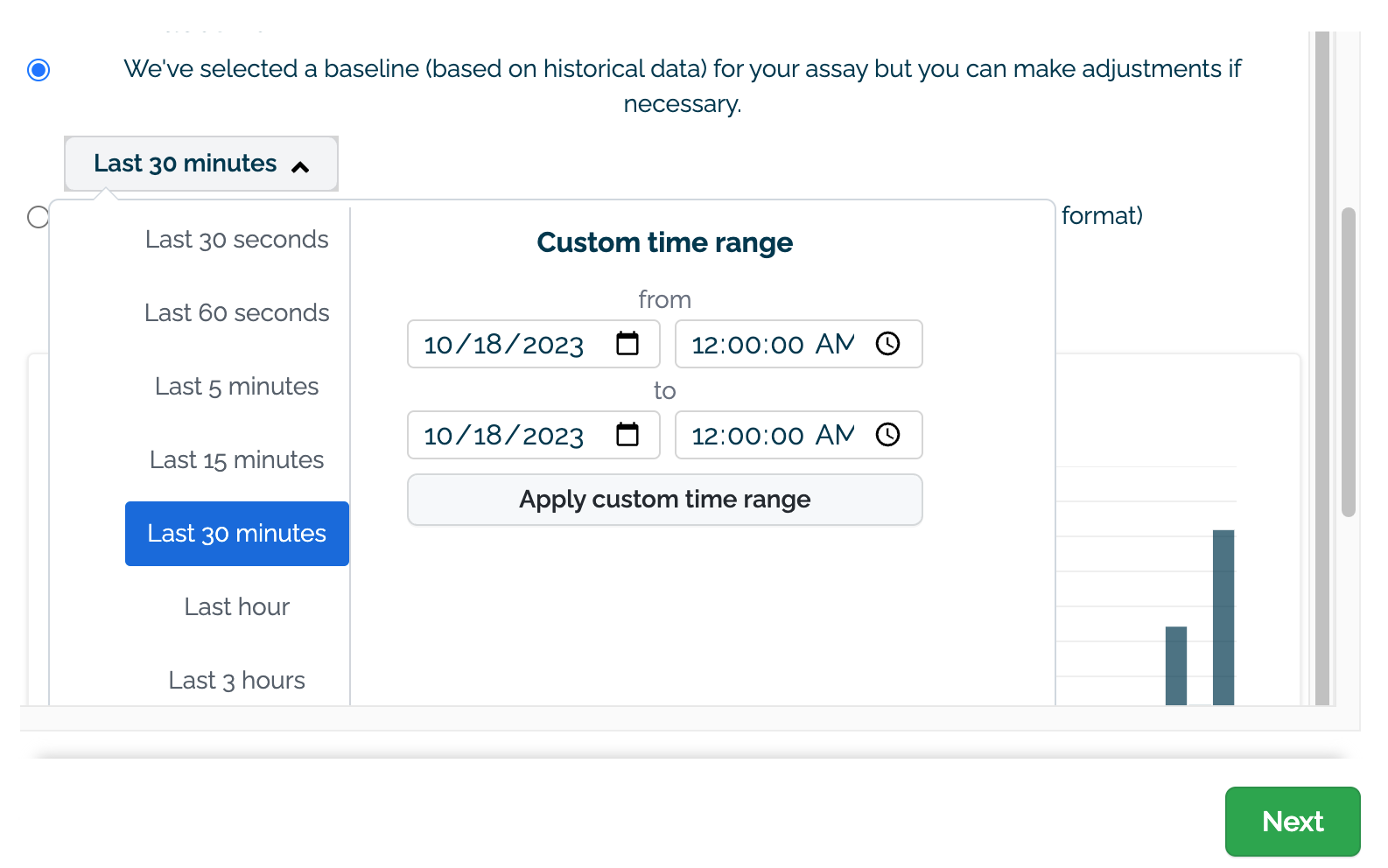
(D) Select the data to use for the baseline. This can either be set with a preset recent time period (last 30 seconds, last 60 seconds, etc) or with a custom date range.
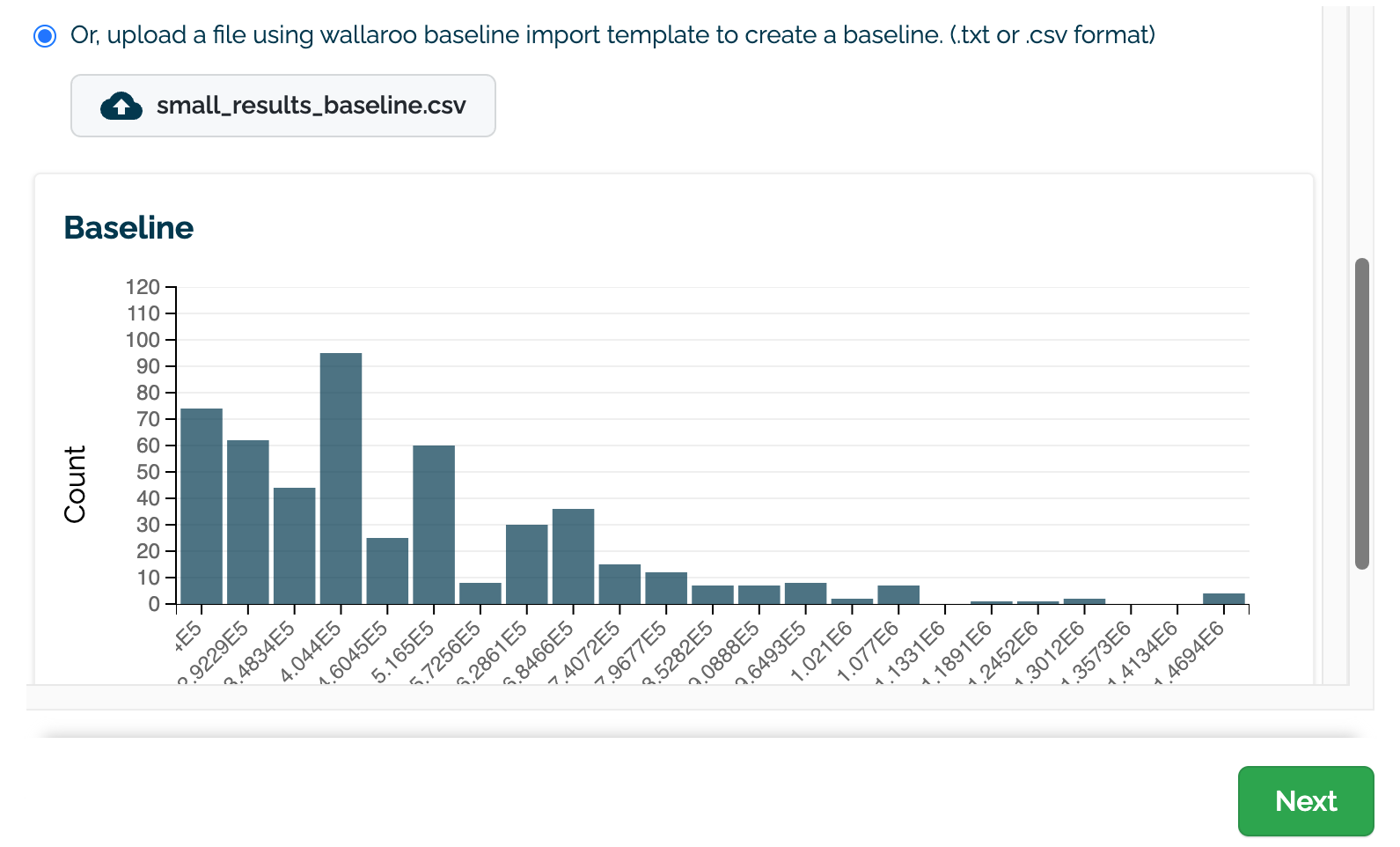
(E) Upload an assay baseline file as either a CSV or TXT file. These assay baselines must be a list of numpy (aka float) values that are comma and newline separated, terminating at the last record with no additional commas or returns.
Once selected, a preview graph of the baseline values will be displayed (C). Note that this may take a few seconds to generate.
Select Next to continue.
On the Settings Module:
Set the date and time range to view values generated by the assay. This can either be set with a preset recent time period (last 30 seconds, last 60 seconds, etc) or with a custom date range.
New assays are configured to run a new analysis for every 24 hours starting at the end of the baseline period. For information on how to adjust the scheduling period and other settings for the assay scheduling window, see the SDK section on how to Schedule Assay.
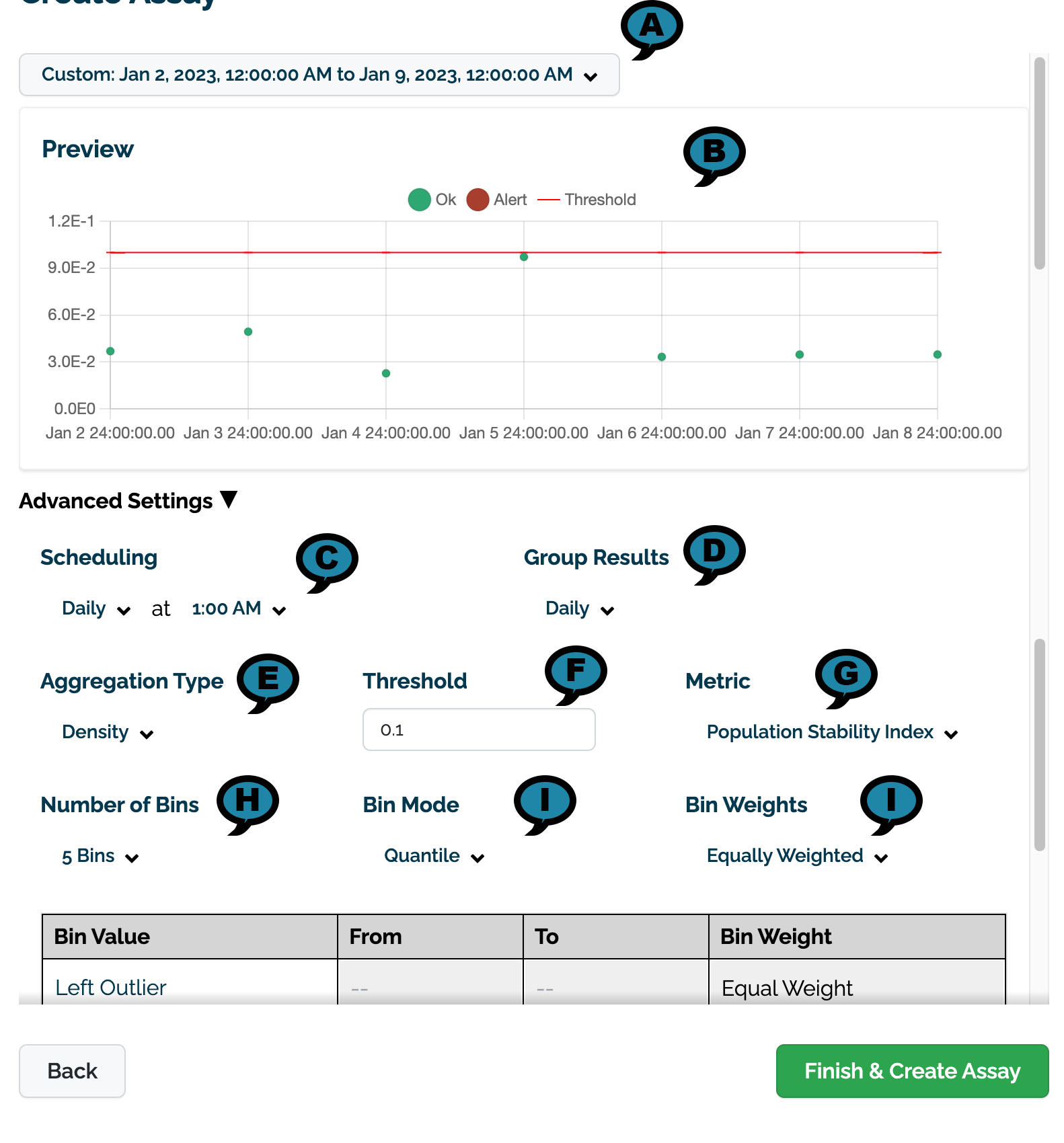
Set the following Advanced Settings.
(A) Preview Date Range: The date and times to for the preview chart.
(B) Preview: A preview of the assay results will be displayed based on the settings below.
(C) Scheduling: Set the Frequency (Daily, Every Minute, Hourly, Weekly, Default: Daily) and the Time (increments of one hour Default: 1:00 AM).
(D) Group Results: How the results are grouped: Daily (Default), Every Minute, Weekly, or Monthly.
(E) Aggregation Type: Density or Cumulative.
(F) Threshold:
Default: 0.1
(G) Metric:
Default: Population Stability Index
Maximum Difference of Bins
Sum of the Difference of Bins
(H) Number of Bins: From 5 to 14. Default: 5
(F) Bin Mode:
Equally Spaced
Default: Quantile
(I) Bin Weights: The bin weights:
Equally Weighted (Default)
Custom: Users can assign their own bin weights as required.
Review the preview chart to verify the settings are correct.
Select Build to complete the process and build the new assay.
Once created, it may take a few minutes for the assay to complete compiling data.
Model Insights via the Wallaroo SDK
Assays generated through the Wallaroo SDK can be previewed, configured, and uploaded to the Wallaroo Ops instance. The following is a condensed version of this process. For full details see the Wallaroo SDK Essentials Guide: Assays Management guide.
Model drift detection with assays using the Wallaroo SDK follows this general process.
Define the Baseline: From either historical inference data for a specific model in a pipeline, or from a pre-determine array of data, a baseline is formed.
Assay Preview: Once the baseline is formed, we preview the assay and configure the different options until we have the the best method of detecting environment or model drift.
Create Assay: With the previews and configuration complete, we upload the assay. The assay will perform an analysis on a regular scheduled based on the configuration.
Get Assay Results: Retrieve the analyses and use them to detect model drift and possible sources.
Pause/Resume Assay: Pause or restart an assay as needed.
Define the Baseline
Assay baselines are defined with the wallaroo.client.build_assay method. Through this process we define the baseline from either a range of dates or pre-generated values.
wallaroo.client.build_assay take the following parameters:
Parameter
Type
Description
assay_name
String (Required) - required
The name of the assay. Assay names must be unique across the Wallaroo instance.
pipeline
wallaroo.pipeline.Pipeline (Required)
The pipeline the assay is monitoring.
model_name
String (Optional) / None
The name of the model to monitor. This field should only be used to track the inputs/outputs for a specific model step in a pipeline. If no model_name is to be included, then the parameters must be passed a named parameters not positional ones.
iopath
String (Required)
The iopath of the assay in the format "input/output {field_name} {field_index}". For Assays V1, field_index is required for list values. For Assays V2, the field_index is required for list values and omitted for scaler values. For example, to monitor the output list field house_price at index 0, the iopath is output house_price 0. For data that are scaler values, no index is passed. For example, the iopath for the output scaler field model_confidence is 'output model_confidence', with no index value provided.
baseline_start
datetime.datetime (Optional)
The start time for the inferences to use as the baseline. Must be included with baseline_end. Cannot be included with baseline_data.
baseline_end
datetime.datetime (Optional)
The end time of the baseline window. the baseline. Windows start immediately after the baseline window and are run at regular intervals continuously until the assay is deactivated or deleted. Must be included with baseline_start. Cannot be included with baseline_data..
baseline_data
numpy.array (Optional)
The baseline data in numpy array format. Cannot be included with either baseline_start or baseline_data.
Note that model_name is an optional parameters when parameters are named. For example:
assay_builder_from_dates = wl.build_assay(assay_name="assays from date baseline",
pipeline=mainpipeline,
iopath="output variable 0",
baseline_start=assay_baseline_start,
baseline_end=assay_baseline_end)
or:
assay_builder_from_dates = wl.build_assay("assays from date baseline",
mainpipeline,
None, ## since we are using positional parameters, `None` must be included for the model parameter"output variable 0",
assay_baseline_start,
assay_baseline_end)
Baselines are created in one of two mutually exclusive methods:
Date Range: The baseline_start and baseline_end retrieves the inference requests and results for the pipeline from the start and end period. This data is summarized and used to create the baseline. For our examples, we’re using the variables assay_baseline_start and assay_baseline_end to represent a range of dates, with assay_baseline_start being set beforeassay_baseline_end.
Numpy Values: The baseline_data sets the baseline from a provided numpy array. This allows assay baselines to be created without first performing inferences in Wallaroo.
Define the Baseline by Location Example
This example shows the assay defined from the date ranges from the inferences performed earlier.
By default, all locations are included in the assay location filters. For our example we use wallaroo.assay_config.WindowBuilder.add_location_filter to specify location_01 for our baseline comparison results.
# Build the assay, based on the start and end of our baseline time, # and tracking the output variable index 0display(assay_baseline_start)
display(assay_baseline_end)
assay_baseline_from_dates = wl.build_assay(assay_name="assays from date baseline",
pipeline=mainpipeline,
iopath="output variable 0",
baseline_start=assay_baseline_start,
baseline_end=assay_baseline_end)
# set the location to the edge locationassay_baseline_from_dates.window_builder().add_location_filter([location_01])
# create the baseline from the datesassay_baseline_run_from_dates = assay_baseline_from_dates.build().interactive_baseline_run()
metadata: The inference metadata with the model information, inference time, and other related factors.
in data: Each input field assigned with the label in.{input field name}.
out data: Each output field assigned with the label out.{output field name}
Note that for assays generated from numpy values, there is only the out data based on the supplied baseline data.
In the following example, the baseline DataFrame is retrieved. Note that in this example, the partition is set to houseprice-edge-demonstration-01, the location specified when we set the location when creating the baseline.
Now that the baseline is defined, we look at different configuration options and view how the assay baseline and results changes. Once we determine what gives us the best method of determining model drift, we can create the assay.
The following examples show different methods of previewing the assay, then how to configure the assay by collecting data from different locations.
Analysis List Chart Scores
Analysis List scores show the assay scores for each assay result interval in one chart. Values that are outside of the alert threshold are colored red, while scores within the alert threshold are green.
The following example shows retrieving the assay results and displaying the chart scores for each window interval for location_01
# Create the assay baselineassay_baseline = wl.build_assay(assay_name="assays from date baseline",
pipeline=mainpipeline,
iopath="output variable 0",
baseline_start=assay_baseline_start,
baseline_end=assay_baseline_end)
# Set the assay parameters# set the location to the edge locationassay_baseline.window_builder().add_location_filter([location_01])
# The end date to gather inference resultsassay_baseline.add_run_until(datetime.datetime.now())
# Set the interval and window to one minute each, set the start date for gathering inference resultsassay_baseline.window_builder().add_width(minutes=1).add_interval(minutes=1).add_start(assay_window_start)
# build the assay configurationassay_config = assay_baseline.build()
# perform an interactive run and collect inference dataassay_results = assay_config.interactive_run()
# Preview the assay analysesassay_results.chart_scores()
# Create the assay baselineassay_baseline = wl.build_assay(assay_name="assays from date baseline",
pipeline=mainpipeline,
iopath="output variable 0",
baseline_start=assay_baseline_start,
baseline_end=assay_baseline_end)
# Set the assay parameters# set the location to the edge locationassay_baseline.window_builder().add_location_filter([location_01, location_02])
# The end date to gather inference resultsassay_baseline.add_run_until(datetime.datetime.now())
# Set the interval and window to one minute each, set the start date for gathering inference resultsassay_baseline.window_builder().add_width(minutes=1).add_interval(minutes=1).add_start(assay_window_start)
# build the assay configurationassay_config = assay_baseline.build()
# perform an interactive run and collect inference dataassay_results = assay_config.interactive_run()
# Preview the assay analysesassay_results.chart_scores()
Analysis Chart
The method wallaroo.assay.AssayAnalysis.chart() displays a comparison between the baseline and an interval of inference data.
This is compared to the Chart Scores, which is a list of all of the inference data split into intervals, while the Analysis Chart shows the breakdown of one set of inference data against the baseline.
The window index. Interactive assay runs are None.
# Create the assay baselineassay_baseline = wl.build_assay(assay_name="assays from date baseline",
pipeline=mainpipeline,
iopath="output variable 0",
baseline_start=assay_baseline_start,
baseline_end=assay_baseline_end)
# Set the assay parameters# set the location to the edge locationassay_baseline.window_builder().add_location_filter([location_01])
# The end date to gather inference resultsassay_baseline.add_run_until(datetime.datetime.now())
# Set the interval and window to one minute each, set the start date for gathering inference resultsassay_baseline.window_builder().add_width(minutes=1).add_interval(minutes=1).add_start(assay_window_start)
# build the assay configurationassay_config = assay_baseline.build()
# perform an interactive run and collect inference dataassay_results = assay_config.interactive_run()
# Preview the assay analysesassay_results[0].chart()
baseline mean = 506095.8288125
window mean = 539489.484203125
baseline median = 448627.71875
window median = 451046.9375
bin_mode = Quantile
aggregation = Density
metric = PSI
weighted = False
score = 0.015462902873991784
scores = [0.0, 0.0059506772863322935, 0.0016799749162599476, 0.0014003069563631675, 7.92105091847181e-05, 0.0040015865462431814, 0.002351146659608475]
index = None
Analysis List DataFrame
wallaroo.assay.AssayAnalysisList.to_dataframe() returns a DataFrame showing the assay results for each window aka individual analysis. This DataFrame contains the following fields:
Field
Type
Description
assay_id
Integer/None
The assay id. Only provided from uploaded and executed assays.
name
String/None
The name of the assay. Only provided from uploaded and executed assays.
iopath
String/None
The iopath of the assay. Only provided from uploaded and executed assays.
score
Float
The assay score.
start
DateTime
The DateTime start of the assay window.
min
Float
The minimum value in the assay window.
max
Float
The maximum value in the assay window.
mean
Float
The mean value in the assay window.
median
Float
The median value in the assay window.
std
Float
The standard deviation value in the assay window.
warning_threshold
Float/None
The warning threshold of the assay window.
alert_threshold
Float/None
The alert threshold of the assay window.
status
String
The assay window status. Values are:
OK: The score is within accepted thresholds.
Warning: The score has triggered the warning_threshold if exists, but not the alert_threshold.
Alert: The score has triggered the the alert_threshold.
For this example, the assay analysis list DataFrame is listed.
From this tutorial, we should have 2 windows of dta to look at, each one minute apart.
# Create the assay baselineassay_baseline = wl.build_assay(assay_name="assays from date baseline",
pipeline=mainpipeline,
iopath="output variable 0",
baseline_start=assay_baseline_start,
baseline_end=assay_baseline_end)
# Set the assay parameters# set the location to the edge locationassay_baseline.window_builder().add_location_filter([location_01])
# The end date to gather inference resultsassay_baseline.add_run_until(datetime.datetime.now())
# Set the interval and window to one minute each, set the start date for gathering inference resultsassay_baseline.window_builder().add_width(minutes=1).add_interval(minutes=1).add_start(assay_window_start)
# build the assay configurationassay_config = assay_baseline.build()
# perform an interactive run and collect inference dataassay_results = assay_config.interactive_run()
# Preview the assay analysesassay_results.to_dataframe()
id
assay_id
assay_name
iopath
pipeline_id
pipeline_name
workspace_id
workspace_name
score
start
min
max
mean
median
std
warning_threshold
alert_threshold
status
0
None
None
assays from date baseline
None
None
None
0.015463
2024-07-30T16:42:28.909163+00:00
236238.65625
2016006.0
539489.484203
451046.9375
264051.044244
None
0.25
Ok
Configure Assays
Before creating the assay, configure the assay and continue to preview it until the best method for detecting drift is set.
Location Filter
This tutorial focuses on the assay configuration method wallaroo.assay_config.WindowBuilder.add_location_filter.
Location Filter Parameters
add_location_filter takes the following parameters.
Parameter
Type
Description
locations
List(String)
The list of model deployment locations for the assay.
Location Filter Example
By default, the locations parameter includes all locations as part of the pipeline. This is seen in the default where no location filter is set, and of the inference data is shown.
For our examples, we will show different locations and how the assay changes. For the first example, we set the location to location_01 which was used to create the baseline, and included inferences that were likely to not trigger a model drift detection alert.
# Create the assay baselineassay_baseline = wl.build_assay(assay_name="assays from date baseline",
pipeline=mainpipeline,
iopath="output variable 0",
baseline_start=assay_baseline_start,
baseline_end=assay_baseline_end)
# Set the assay parameters# set the location to the edge locationassay_baseline.window_builder().add_location_filter([location_01])
# The end date to gather inference resultsassay_baseline.add_run_until(datetime.datetime.now())
# Set the interval and window to one minute each, set the start date for gathering inference resultsassay_baseline.window_builder().add_width(minutes=1).add_interval(minutes=1).add_start(assay_window_start)
# build the assay configurationassay_config = assay_baseline.build()
# perform an interactive run and collect inference dataassay_results = assay_config.interactive_run()
# Preview the assay analysesassay_results.chart_scores()
assay_results.to_dataframe()
id
assay_id
assay_name
iopath
pipeline_id
pipeline_name
workspace_id
workspace_name
score
start
min
max
mean
median
std
warning_threshold
alert_threshold
status
0
None
None
assays from date baseline
None
None
None
0.015463
2024-07-30T16:42:28.909163+00:00
236238.65625
2016006.0
539489.484203
451046.9375
264051.044244
None
0.25
Ok
Now we will set the location to location_02 which had a set of inferences likely to trigger a model drift alert.
# Create the assay baselineassay_baseline = wl.build_assay(assay_name="assays from date baseline",
pipeline=mainpipeline,
iopath="output variable 0",
baseline_start=assay_baseline_start,
baseline_end=assay_baseline_end)
# Set the assay parameters# set the location to the edge locationassay_baseline.window_builder().add_location_filter([location_02])
# The end date to gather inference resultsassay_baseline.add_run_until(datetime.datetime.now())
# Set the interval and window to one minute each, set the start date for gathering inference resultsassay_baseline.window_builder().add_width(minutes=1).add_interval(minutes=1).add_start(assay_window_start)
# build the assay configurationassay_config = assay_baseline.build()
# perform an interactive run and collect inference dataassay_results = assay_config.interactive_run()
# Preview the assay analysesassay_results.chart_scores()
assay_results.to_dataframe()
id
assay_id
assay_name
iopath
pipeline_id
pipeline_name
workspace_id
workspace_name
score
start
min
max
mean
median
std
warning_threshold
alert_threshold
status
0
None
None
assays from date baseline
None
None
None
0.015463
2024-07-30T16:43:28.909163+00:00
236238.65625
2016006.0
539489.484203
451046.9375
264051.044244
None
0.25
Ok
The next example includes location_01 and location_02. Since they were performed in distinct times, the model insights scores for each location is seen in the chart.
# Create the assay baselineassay_baseline = wl.build_assay(assay_name="assays from date baseline",
pipeline=mainpipeline,
iopath="output variable 0",
baseline_start=assay_baseline_start,
baseline_end=assay_baseline_end)
# Set the assay parameters# set the location to the edge locationassay_baseline.window_builder().add_location_filter([location_01, location_02])
# The end date to gather inference resultsassay_baseline.add_run_until(datetime.datetime.now())
# Set the interval and window to one minute each, set the start date for gathering inference resultsassay_baseline.window_builder().add_width(minutes=1).add_interval(minutes=1).add_start(assay_window_start)
# build the assay configurationassay_config = assay_baseline.build()
# perform an interactive run and collect inference dataassay_results = assay_config.interactive_run()
# Preview the assay analysesassay_results.chart_scores()
assay_results.to_dataframe()
id
assay_id
assay_name
iopath
pipeline_id
pipeline_name
workspace_id
workspace_name
score
start
min
max
mean
median
std
warning_threshold
alert_threshold
status
0
None
None
assays from date baseline
None
None
None
0.015463
2024-07-30T16:42:28.909163+00:00
236238.65625
2016006.0
539489.484203
451046.9375
264051.044244
None
0.25
Ok
1
None
None
assays from date baseline
None
None
None
0.015463
2024-07-30T16:43:28.909163+00:00
236238.65625
2016006.0
539489.484203
451046.9375
264051.044244
None
0.25
Ok
Create Assay
With the assay previewed and configuration options determined, we officially create it by uploading it to the Wallaroo instance.
Once it is uploaded, the assay runs an analysis based on the window width, interval, and the other settings configured.
Assays are uploaded with the wallaroo.assay_config.upload() method. This uploads the assay into the Wallaroo database with the configurations applied and returns the assay id. Note that assay names must be unique across the Wallaroo instance; attempting to upload an assay with the same name as an existing one will return an error.
wallaroo.assay_config.upload() returns the assay id for the assay.
Typically we would just call wallaroo.assay_config.upload() after configuring the assay. For the example below, we will perform the complete configuration in one window to show all of the configuration steps at once before creating the assay, and narrow the locations to location_01 and location_02. By default, all locations associated with a pipeline are included in the assay results unless the add_location_filter method is applied to specify location(s).
# Create the assay baselineassay_baseline = wl.build_assay(assay_name="assays from date baseline",
pipeline=mainpipeline,
iopath="output variable 0",
baseline_start=assay_baseline_start,
baseline_end=assay_baseline_end)
# Set the assay parameters# set the location to the edge locationassay_baseline.window_builder().add_location_filter([location_01])
# The end date to gather inference resultsassay_baseline.add_run_until(datetime.datetime.now())
# Set the interval and window to one minute each, set the start date for gathering inference resultsassay_baseline.window_builder().add_width(minutes=1).add_interval(minutes=1).add_start(assay_window_start)
assay_id = assay_baseline.upload()
The assay is now visible through the Wallaroo UI by selecting the workspace, then the pipeline, then Insights. The following is an example of another assay in the Wallaroo Dashboard.
Get Assay Info
Assay information is retrieved with the wallaroo.client.get_assay_info() which takes the following parameters.
Parameter
Type
Description
assay_id
Integer (Required)
The numerical id of the assay.
This returns the following:
Parameter
Type
Description
id
Integer
The numerical id of the assay.
name
String
The name of the assay.
active
Boolean
True: The assay is active and generates analyses based on its configuration. False: The assay is disabled and will not generate new analyses.
pipeline_name
String
The name of the pipeline the assay references.
last_run
DateTime
The date and time the assay last ran.
next_run
DateTime
THe date and time the assay analysis will next run.
alert_threshold
Float
The alert threshold setting for the assay.
baseline
Dict
The baseline and settings as set from the assay configuration.
If latency between the model’s edge deployment and the Wallaroo Ops Instance is higher than 0.5, the connection may time out and the inference results are not transmitted back to the Wallaroo Ops Center. To check the latency between the deployed model and the Wallaroo Ops Center, use the following command from the edge device:
For docker run deployments, increase the timeout with the option -e MTLS_CONNECTION_TIMEOUT=3.0. Increase the MTLS_CONNECTION_TIMEOUT further as needed for extreme low latency scenarios.