Custom Taints and Labels Guide
Table of Contents
Organizations can customize the taints and labels for their Kubernetes cluster running Wallaroo. Nodes in a Kubernetes cluster can have a taint applied to them. Any pod that does not have a toleration matching the taint is not be applied to that node.
This allows organizations to determine which pods can be deployed into specific nodes, reserving their Kubernetes resources for other services.
See the Kubernetes Taints and Tolerations documentation for more information.
Default Taints and Labels
The Wallaroo Enterprise Install Guides specify default taints applied to nodepools. These can be used to contain pod scheduling only to specific nodes where the pod tolerations match the nodes taints. By default, the following nodepools and their associated taints and labels are applied at installation.
| Nodepool | Taints | Labels | Description |
|---|---|---|---|
| general | N/A | wallaroo.ai/node-purpose: general | For general Wallaroo services. No taints are applied to this nodepool to allow any process not assigned with a deployment label to run in this space. |
| persistent | wallaroo.ai/persistent=true:NoSchedule | wallaroo.ai/node-purpose: persistent | For Wallaroo services with a persistentVolume settings, including JupyterHub, Minio, etc. |
| pipelines-x86 | wallaroo.ai/pipelines=true:NoSchedule | wallaroo.ai/node-purpose: pipelines | For deploying pipelines for default x86 architectures. The taints and label must be applied to any nodepool used for model deployments. |
The specific nodepool names may differ based on your cloud services naming requirements; check with the cloud services provider for the nodepool name requirements and adjust as needed.
Taints and Labels for Architecture and GPU Nodepools
Nodepools with specific architecture processors, AI accelerators, and GPUs used for model deployment with those specific resources require the following taints and labels.
| Node Type | Taints | Labels | Description |
|---|---|---|---|
| Model deployment without GPUs | wallaroo.ai/pipelines=true:NoSchedule | wallaroo.ai/node-purpose: pipelines | These nodepools are reserved for deploying pipelines for x86 and ARM based architectures without GPUs. |
| Model deployment with GPUs | wallaroo.ai/pipelines=true:NoSchedule |
| Models deployed on GPUs require two labels: wallaroo.ai/node-purpose: pipelines is required, as well as another label that is customized by the organization. Examples include: doc-gpu-label=true, wallaroo.ai/accelerator: a100, etc. These custom labels are used during model deployment with the deployment_label parameter. For details on deploying models with GPUs, see Deployment Configuration. For details on creating nodepools with GPUs, see Create GPU Nodepools for Kubernetes Clusters. |
| Model Packaging for ARM | N/A | wallaroo.ai/node-purpose: general | These nodepools are used for packaging models for the ARM architecture.. Models uploaded to Wallaroo are packaged in either the Wallaroo Native Runtimes or the Wallaroo Containerized Runtimes. Nodepools with specific CPU architectures, such as ARM, are used to package models uploaded with that specific architecture. For more details on deploying models to ARM architectures, see Run AI Workloads with ARM Processors For Edge and Multicloud Deployments. For details on creating nodepools with ARM processors, see Create ARM Nodepools for Kubernetes Clusters. |
Custom Tolerations
For organizations that use custom taints for their Kubernetes environments, the tolerations for Wallaroo services are updated either for kots based installations or helm based installations.
When updating the tolerations for Wallaroo, verify that the taints for the nodepools match the custom tolerations used.
Custom Tolerations for Kots Installations
To customize the tolerations and deployment labels applied for Wallaroo services, the following prerequisites must be met:
- Access to the Kubernetes environment running the Wallaroo instances.
- Have
kubectlandkotsinstalled and connected to the Kubernetes environment.
For full details on installing Wallaroo and the prerequisite software, see the Wallaroo Prerequisites Guide.
- Access the Kots Administrative Dashboard.
From a terminal with
kubectlandkotsinstalled and connected to the Kubernetes environment, run:kubectl kots admin-console --namespace wallarooThis will provide access to the Kots Administrative Dashboard through
http://localhost:8800:• Press Ctrl+C to exit • Go to http://localhost:8800 to access the Admin ConsoleLaunch a browser and connect to
http://localhost:8800.Enter the password created during the Wallaroo Install process. The Kots Administrative Dashboard will now be available.
- From the Kots Administrative Dashboard, select Config
- Update each of the following as needed:
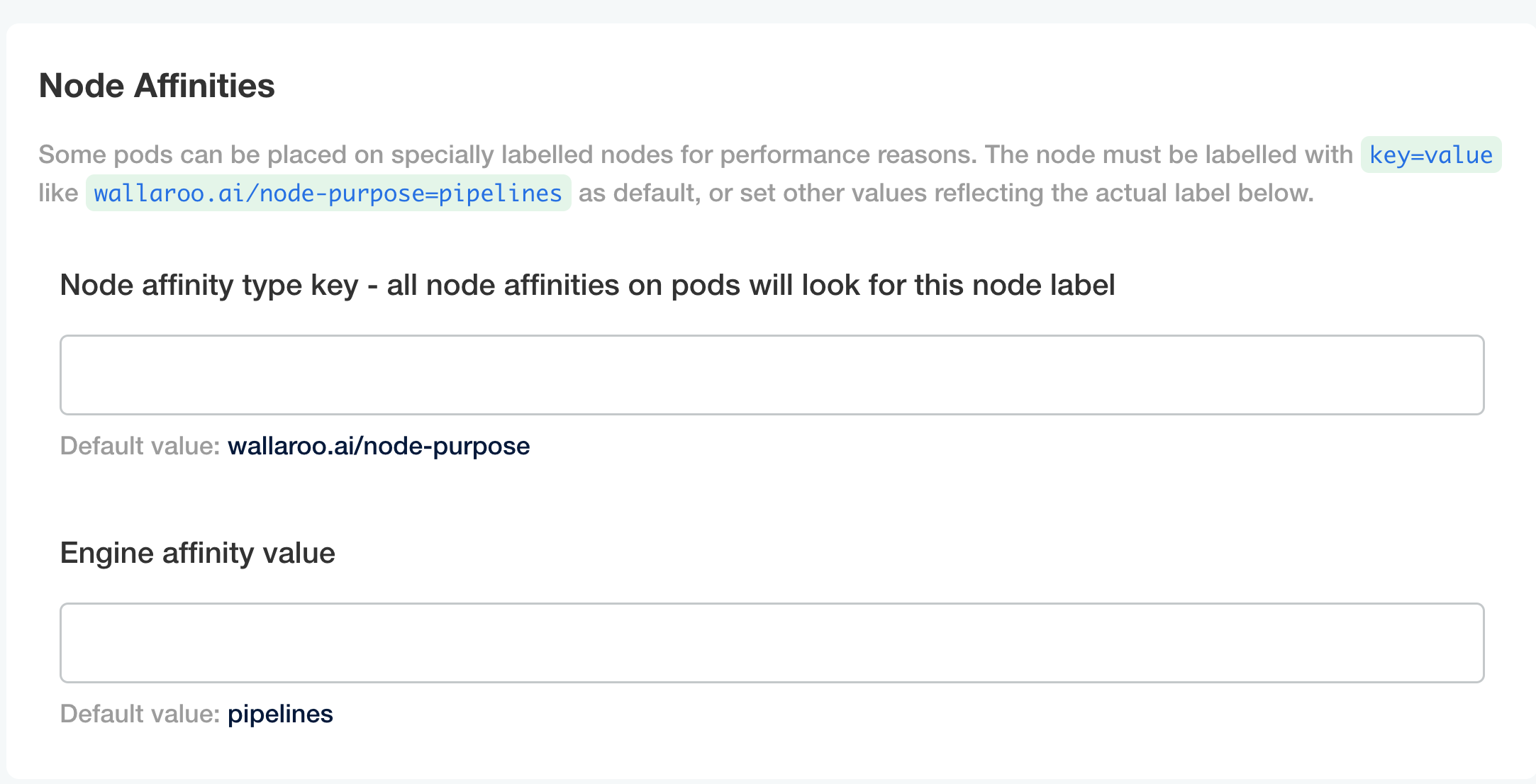
Node Affinities:
Node affinity type key: Verify that the node affinity key matches the label for the nodepools.
Engine affinity value: Set the engine affinity - the affinity used for pipeline deployment - to match the label.
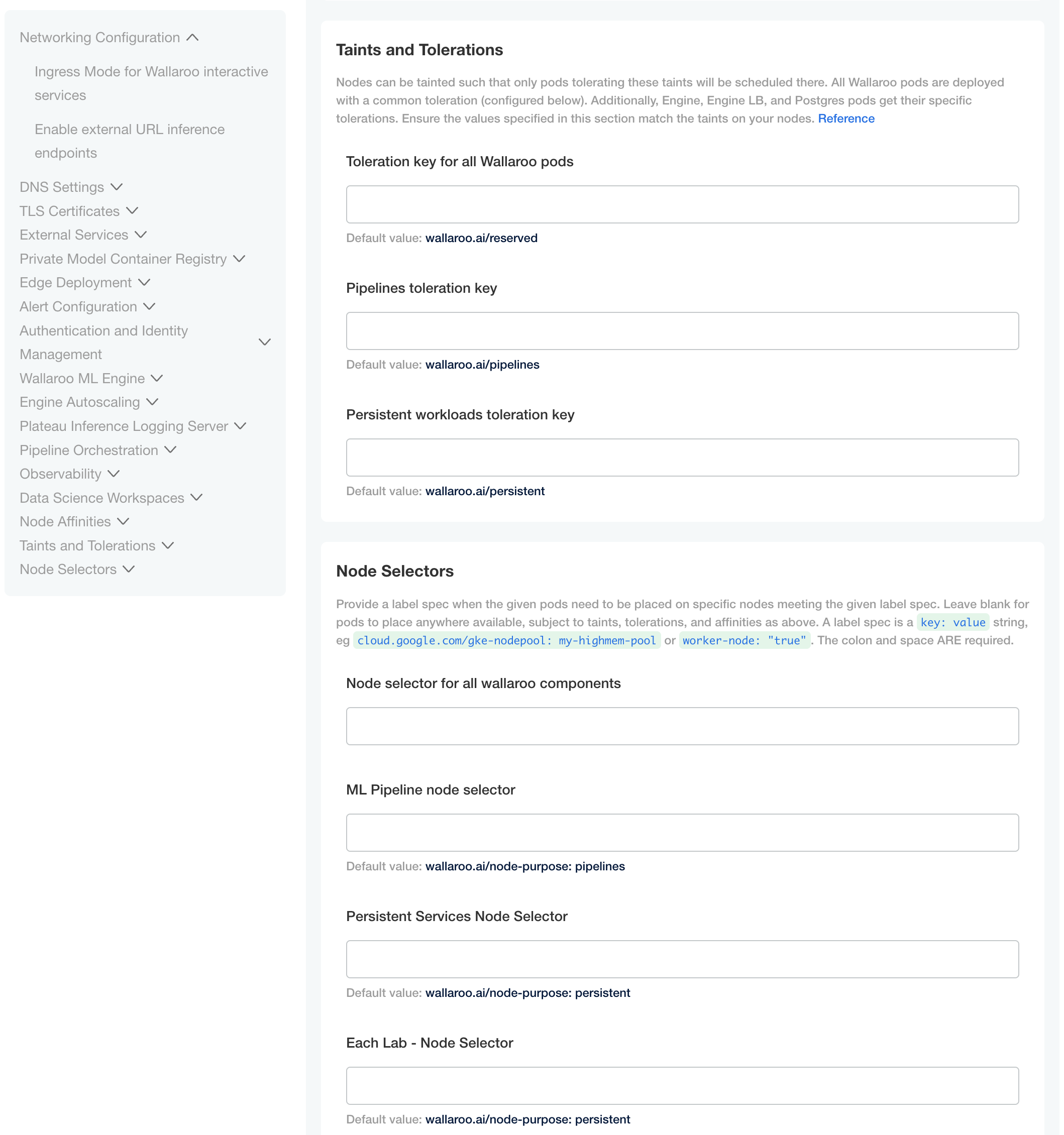
Taints and Tolerations. Set the custom tolerations to match the taints applied to the nodepools, and the node selectors to match the labels used for the nodepools.
Node Selectors: Update the node selector to match the custom nodepools labels for each service.
Custom Tolerations for Helm Installations
To set the custom tolerations for helm based installations of Wallaroo, set the tolerations via the local values.yaml file. The following sample shows setting the tolerations used during the helm based installation of Wallaroo. Verify that these match the taints applied to the nodepools for the Kubernetes cluster hosting the Wallaroo installation.
wallarooDomain: "wallaroo.example.com" # change to match the actual domain name
custTlsSecretName: cust-cert-secret
apilb:
serviceType: LoadBalancer
external_inference_endpoints_enabled: true
ingress_mode: internal # internal (Default), external,or none
dashboard:
clientName: "Wallaroo Helm Example" # Insert the name displayed in the Wallaroo Dashboard
kubernetes_distribution: "" # Required. One of: aks, eks, gke, oke, or kurl.
# Enable edge deployment
#ociRegistry:
# enabled: true # true enables the Edge Server registry information, false disables it.
# registry: ""# The registry url. For example: reg.big.corp:3579.
# repository: ""# The repository within the registry. This may include the cloud account, or the full path where the Wallaroo published pipelines should be kept. For example: account123/wallaroo/pipelines.
# email: "" # Optional field to track the email address of the registry credential.
# username: "" # The username to the registry. This may vary based on the provider. For example, GCP Artifact Registry with service accounts uses the username _json_key_base64 with the password as a base64 processed token of the credential information.
# password: "" # The password or token for the registry service.
# Enable edge deployment observability
# edgelb:
# enabled: true
# The nodeSelector and tolerations for all components
# This does not apply to nats, fluent-bit, or minio so needs to be applied separately
# nodeSelector:
# wallaroo.ai/reserved: true
# tolerations:
# - key: "wallaroo.ai/reserved"
# operator: "Exists"
# effect: "NoSchedule"
# To change the pipeline taint or nodeSelector,
# best practice is to change engine, enginelb, and engineAux
# together unless they will be in different pools.
# engine:
# nodeSelector:
# wallaroo.ai/node-purpose: pipelines
# tolerations:
# - key: "wallaroo.ai/pipelines"
# operator: "Exists"
# effect: "NoSchedule"
# enginelb:
# nodeSelector:
# wallaroo.ai/node-purpose: pipelines
# tolerations:
# - key: "wallaroo.ai/pipelines"
# operator: "Exists"
# effect: "NoSchedule"
# engineAux:
# nodeSelector:
# wallaroo.ai/node-purpose: pipelines
# tolerations:
# - key: "wallaroo.ai/pipelines"
# operator: "Exists"
# effect: "NoSchedule"
# For each service below, adjust the disk size and resources as required.
# If the nodeSelector or tolerations are changed for one service,
# the other services nodeSelector and tolerations **must** be changed to match
#
#
# plateau:
# diskSize: 100Gi
# resources:
# limits:
# memory: 4Gi
# cpu: 1000m
# requests:
# memory: 128Mi
# cpu: 100m
# nodeSelector:
# wallaroo.ai/node-purpose: persistent
# tolerations:
# - key: "wallaroo.ai/persistent"
# operator: "Exists"
# effect: "NoSchedule"
# Jupyter has both hub and lab nodeSelectors and tolerations
# They default to the same persistent pool, but can be assigned to different ones
# jupyter:
# nodeSelector: # Node placement for Hub administrative pods
# wallaroo.ai/node-purpose: persistent
# tolerations:
# - key: "wallaroo.ai/persistent"
# operator: "Exists"
# effect: "NoSchedule"
# labNodeSelector: # Node placement for Hub-spawned jupyterlab pods
# wallaroo.ai/node-purpose: persistent
# labTolerations:
# - key: "wallaroo.ai/persistent"
# operator: "Exists"
# effect: "NoSchedule"
# memory:
# limit: "4" # Each Lab - memory limit in GB
# guarantee: "2" # Each Lab - lemory guarantee in GB
# cpu:
# limit: "2.0" # Each Lab - fractional CPU limit
# guarantee: "1.0" # Each Lab - fractional CPU guarantee
# storage:
# capacity: "50" # Each Lab - disk storage capacity in GB
# minio:
# persistence:
# size: 25Gi
# nodeSelector:
# wallaroo.ai/node-purpose: persistent
# tolerations:
# - key: wallaroo.ai/persistent
# operator: "Exists"
# effect: "NoSchedule"
# resources:
# requests:
# memory: 1Gi
# postgres:
# diskSize: 10Gi
# nodeSelector:
# wallaroo.ai/node-purpose: persistent
# tolerations:
# - key: "wallaroo.ai/persistent"
# operator: "Exists"
# effect: "NoSchedule"
# resources:
# limits:
# memory: 2Gi
# cpu: 500m
# requests:
# memory: 512Mi
# cpu: 100m
# Prometheus has the usual persistent options, but also a retention size
# The the size on disk and time can be configured before removing it.
# prometheus:
# storageRetentionSizeGb: "10" # Retain this much data, in GB.
# storageRetentionTimeDays: "15" # When to remove old data. In days.
# nodeSelector:
# wallaroo.ai/node-purpose: persistent
# tolerations:
# - key: "wallaroo.ai/persistent"
# operator: "Exists"
# effect: "NoSchedule"
# resources:
# limits:
# memory: 6Gi
# cpu: 2000m
# requests:
# memory: 512Mi
# cpu: 100m
# nats:
# podTemplate:
# merge:
# spec:
# nodeSelector:
# wallaroo.ai/node-purpose: persistent
# tolerations:
# - key: "wallaroo.ai/persistent"
# operator: "Exists"
# effect: NoSchedule
# wallsvc:
# nodeSelector:
# wallaroo.ai/node-purpose: persistent
# tolerations:
# - key: "wallaroo.ai/persistent"
# operator: "Exists"
# effect: "NoSchedule"