Inference Results
Table of Contents
Retrieve Inference Metrics and Logs Via the Wallaroo Dashboard
Inference logs from Wallaroo deployments are available through the Wallaroo Dashboard through the Pipeline Metrics page.
How to Access the Pipeline Metrics Page
To access the metrics page for a specific pipeline:
- Login to the Wallaroo Dashboard.
- Select the workspace the pipeline is associated with.
- Select View Pipelines.
- From the Workspace Pipeline List page, select the pipeline.
- From the Pipeline Details page, select Metrics.
Pipeline Metrics Overview
The Pipeline Metrics page contains the following elements.
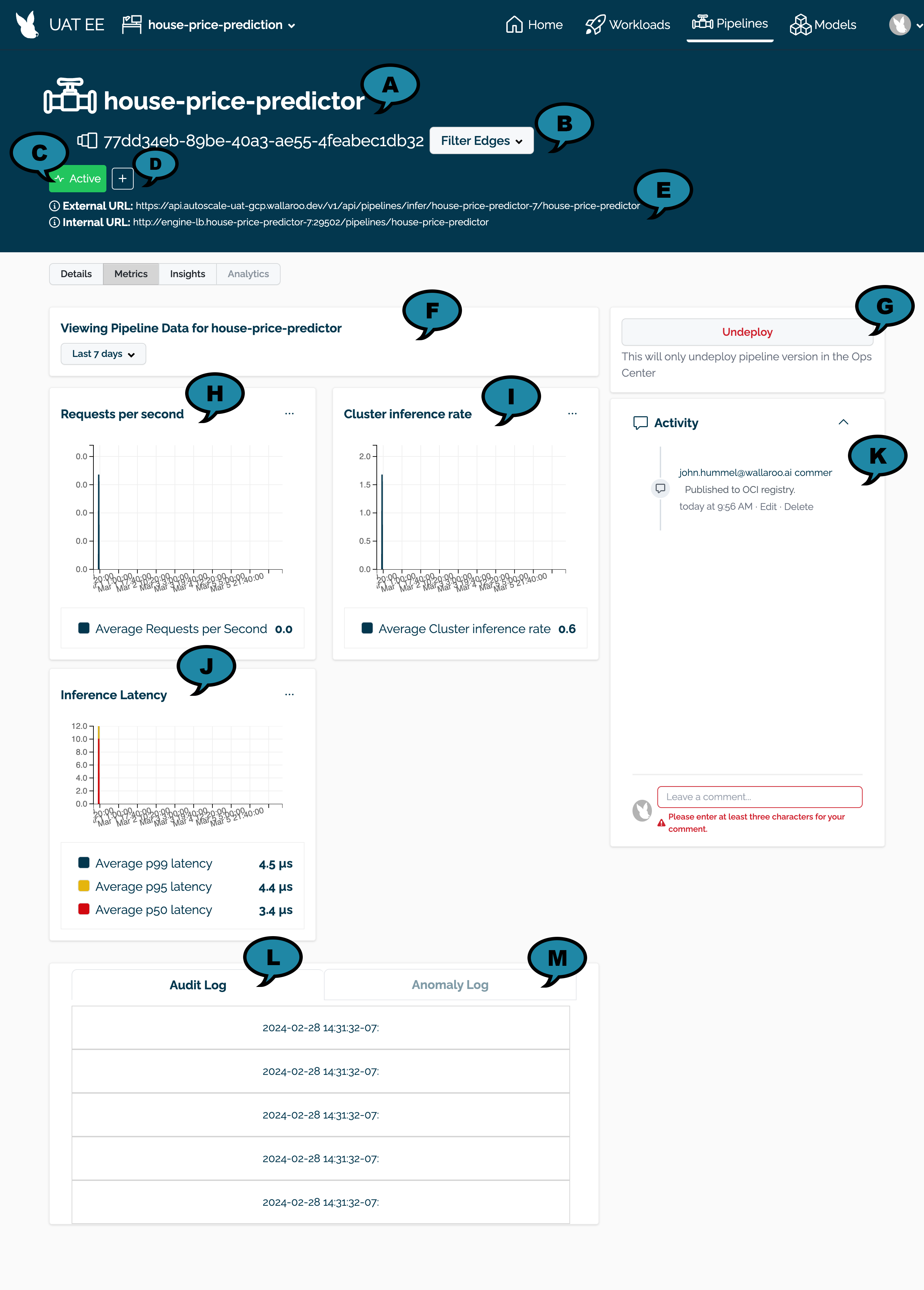
Pipeline Name and Identifier (A): The pipeline’s assigned name and unique identifier in UUID format.
Filter Edges (B): By default, all locations are displayed. Filter Edges provides a list of available edge deployments are displayed. Selecting one or more filters from the list limits the available metrics and logs displayed to only the selected locations.
Status (C): The status of the pipeline. The status only applies to the pipeline’s status in the Wallaroo Ops instance.. Options are:
- Active: The pipeline is deployed.
- Inactive: The pipeline is not deployed.
Tags (D): Any tags applied to the pipeline.
Inference Urls (E): The internal and external inference URLs for the deployed pipeline in the Wallaroo Ops instance.
Date Filter (F): Filter date and time to specify the period of time for inference requests to collect for the metrics.
Deploy/Undeploy the Pipeline (G): Deploy an inactive pipeline, or deploy an active pipeline in the Wallaroo Ops instance.
Requests per Second (H): The number of inference requests per second in the filtered date period. This chart data can be downloaded and shared with other users.
Cluster inference rate (I): The rate of inference requests completed in the filtered date period. This chart data can be downloaded and shared with other users.
Inference Latency (J): The latency between when an inference request is received versus when it is completed in the filtered date period. This chart data can be downloaded and shared with other users.
Activity (K): Comments left by users.
Audit Log (L): The inference audit logs. The logs are filtered by the Filter Edges settings and Date Filter.
Anomaly Log (M): The anomaly audit logs. These are included when anomaly detection validation rules are triggered. The logs are filtered by the Filter Edges settings and Date Filter.
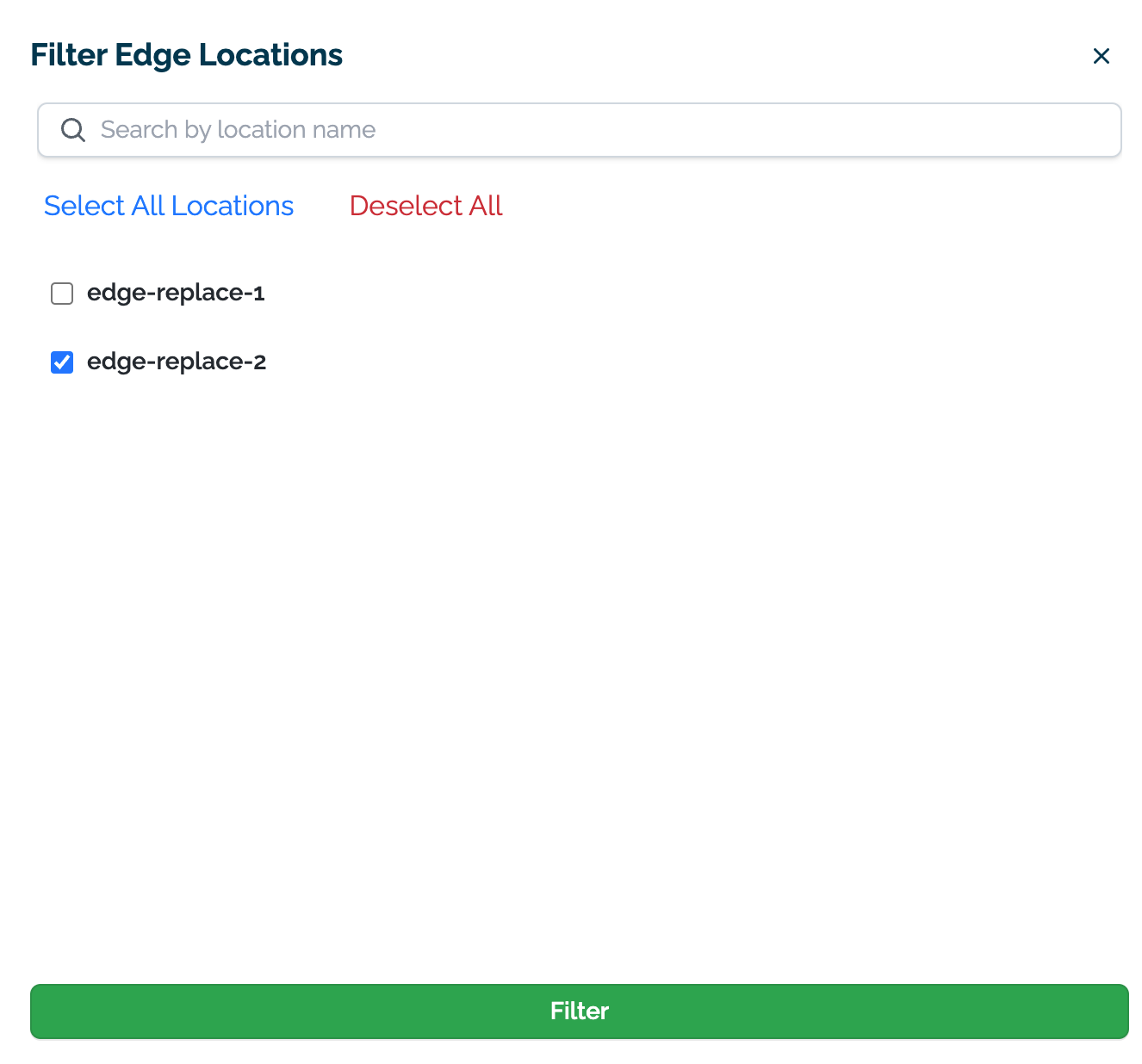
How to Filter by Edge Locations
By default, all location inference data is used for the Pipeline Metrics page.
To filter by Edge Locations:
- Select Filter Edges.
- Select the edges to filter inference results from.
- Select Filter when to set the filters.
- To clear the filters, select Clear filter next to the Filter Edges button.
How to Share Metric Charts and Data
To save metric data from the Requests per Second, Cluster inference rate and Inference Latency charts:
- Select the … menu option for the specific chart.
- Select one of the following:
- Download CSV: Downloads a CSV file with the Date and Time stamp and data for the specified chart.
- Copy shareable URL: Provides a publicly available URL for users to view the chart.
- View Enlarged: Displays a larger version of the chart.
Retrieve Inference Request Logs Via the Wallaroo SDK
Pipeline have their own set of log files that are retrieved and analyzed as needed with the either through:
- The Pipeline
logsmethod (returns either a DataFrame or Apache Arrow). - The Pipeline
export_logsmethod (saves either a DataFrame file in JSON format, or an Apache Arrow file).
Get Pipeline Logs
Pipeline logs are retrieved through the Pipeline logs method. By default, logs are returned as a DataFrame in reverse chronological order of insertion, with the most recent files displayed first.
Pipeline logs are segmented by pipeline versions. For example, if a new model step is added to a pipeline, a model swapped out of a pipeline step, etc - this generated a new pipeline version. log method requests will return logs based on the parameter that match the pipeline version. To request logs of a specific pipeline version, specify the start_datetime and end_datetime parameters based on the pipeline version logs requested.
IMPORTANT NOTE
Pipeline logs are returned either in reverse or forward chronological order of record insertion; depending on when a specific inference request completes, one inference record may be inserted out of chronological order by theTimestamp value, but still be in chronological order of insertion.This command takes the following parameters.
| Parameter | Type | Description |
|---|---|---|
limit | Int (Optional) (Default: 100) | Limits how many log records to display. If there are more pipeline logs than are being displayed, the Warning message Pipeline log record limit exceeded will be displayed. For example, if 100 log files were requested and there are a total of 1,000, the warning message will be displayed. |
start_datetime and end_datetime | DateTime (Optional) | Limits logs to all logs between the start_datetime and end_datetime DateTime parameters. These comply with the Python datetime library for formats such as:
Both parameters must be provided. Submitting a logs() request with only start_datetime or end_datetime will generate an exception.If start_datetime and end_datetime are provided as parameters even with any other parameter, then the records are returned in chronological order, with the oldest record displayed first. |
dataset | List[String] (OPTIONAL) | The datasets to be returned. The datasets available are:
metadata.elapsed: IMPORTANT NOTE: See Metadata Requests Restrictionsfor specifications on how this dataset can be used with other datasets.
|
dataset_exclude | List[String] (OPTIONAL) | Exclude specified datasets. |
dataset_separator | Sequence[[String], string] (OPTIONAL) | If set to “.”, return dataset will be flattened. |
arrow | Boolean (Optional) (Default: False) | If arrow is set to True, then the logs are returned as an Apache Arrow table. If arrow=False, then the logs are returned as a pandas DataFrame. |
All of the parameters can be used together, but start_datetime and end_datetime must be combined; if one is used, then so must the other. If start_datetime and end_datetime are used with any other parameter, then the log results are in chronological order of record insertion.
Log requests are limited to around 100k in size. For requests greater than 100k in size, use the Pipeline export_logs() method.
Logs include the following standard datasets:
| Parameter | Type | Description |
|---|---|---|
time | DateTime | The DateTime the inference request was made. |
in.{variable} | The input(s) for the inference request. Each input is listed as in.{variable_name}. For example, in.text_input, in.square_foot, in.number_of_rooms, etc. | |
out | The outputs(s) for the inference request, based on the ML model’s outputs. Each output is listed as out.{variable_name}. For example, out.maximum_offer_price, out.minimum_asking_price, out.trade_in_value, etc. | |
anomaly.count | Int | How many validation checks were triggered by the inference. For more information, see Wallaroo SDK Essentials Guide: Anomaly Detection |
out_{model_name}.{variable} | Only returned when using Pipeline Shadow Deployments. For each model in the shadow deploy step, their output is listed in the format out_{model_name}.{variable}. For example, out_shadow_model_xgb.maximum_offer_price, out_shadow_model_xgb.minimum_asking_price, out_shadow_model_xgb.trade_in_value, etc. | |
out._model_split | Only returned when using A/B Testing, used to display the model_name, model_version, and model_sha of the model used for the inference. |
In this example, the last 50 logs to the pipeline mainpipeline between two sample dates. In this case, all of the time column fields are the same since the inference request was sent as a batch.
logs = mainpipeline.logs(start_datetime=date_start, end_datetime=date_end)
display(len(logs))
display(logs)
538
| time | in.tensor | out.variable | anomaly.count | |
|---|---|---|---|---|
| 0 | 2023-04-24 18:09:33.970 | [4.0, 2.5, 2900.0, 5505.0, 2.0, 0.0, 0.0, 3.0, 8.0, 2900.0, 0.0, 47.6063, -122.02, 2970.0, 5251.0, 12.0, 0.0, 0.0] | [718013.75] | 0 |
| 1 | 2023-04-24 18:09:33.970 | [2.0, 2.5, 2170.0, 6361.0, 1.0, 0.0, 2.0, 3.0, 8.0, 2170.0, 0.0, 47.7109, -122.017, 2310.0, 7419.0, 6.0, 0.0, 0.0] | [615094.56] | 0 |
| 2 | 2023-04-24 18:09:33.970 | [3.0, 2.5, 1300.0, 812.0, 2.0, 0.0, 0.0, 3.0, 8.0, 880.0, 420.0, 47.5893, -122.317, 1300.0, 824.0, 6.0, 0.0, 0.0] | [448627.72] | 0 |
| 3 | 2023-04-24 18:09:33.970 | [4.0, 2.5, 2500.0, 8540.0, 2.0, 0.0, 0.0, 3.0, 9.0, 2500.0, 0.0, 47.5759, -121.994, 2560.0, 8475.0, 24.0, 0.0, 0.0] | [758714.2] | 0 |
| 4 | 2023-04-24 18:09:33.970 | [3.0, 1.75, 2200.0, 11520.0, 1.0, 0.0, 0.0, 4.0, 7.0, 2200.0, 0.0, 47.7659, -122.341, 1690.0, 8038.0, 62.0, 0.0, 0.0] | [513264.7] | 0 |
| … | … | … | … | … |
| 533 | 2023-04-24 18:09:33.970 | [3.0, 2.5, 1750.0, 7208.0, 2.0, 0.0, 0.0, 3.0, 8.0, 1750.0, 0.0, 47.4315, -122.192, 2050.0, 7524.0, 20.0, 0.0, 0.0] | [311909.6] | 0 |
| 534 | 2023-04-24 18:09:33.970 | [5.0, 1.75, 2330.0, 6450.0, 1.0, 0.0, 1.0, 3.0, 8.0, 1330.0, 1000.0, 47.4959, -122.367, 2330.0, 8258.0, 57.0, 0.0, 0.0] | [448720.28] | 0 |
| 535 | 2023-04-24 18:09:33.970 | [4.0, 3.5, 4460.0, 16271.0, 2.0, 0.0, 2.0, 3.0, 11.0, 4460.0, 0.0, 47.5862, -121.97, 4540.0, 17122.0, 13.0, 0.0, 0.0] | [1208638.0] | 0 |
| 536 | 2023-04-24 18:09:33.970 | [3.0, 2.75, 3010.0, 1842.0, 2.0, 0.0, 0.0, 3.0, 9.0, 3010.0, 0.0, 47.5836, -121.994, 2950.0, 4200.0, 3.0, 0.0, 0.0] | [795841.06] | 0 |
| 537 | 2023-04-24 18:09:33.970 | [2.0, 1.5, 1780.0, 4750.0, 1.0, 0.0, 0.0, 4.0, 7.0, 1080.0, 700.0, 47.6859, -122.395, 1690.0, 5962.0, 67.0, 0.0, 0.0] | [558463.3] | 0 |
538 rows × 4 columns
Metadata Requests Restrictions
The following restrictions are in place when requesting the following datasets:
metadatametadata.elaspedmetadata.last_modelmetadata.pipeline_version
Standard Pipeline Steps Log Requests
Effected pipeline steps:
add_model_stepreplace_with_model_step
For log file requests, the following metadata dataset requests for standard pipeline steps are available:
metadata
These must be paired with specific columns. * is not available when paired with metadata.
in: All input fields.out: All output fields.time: The DateTime the inference request was made.in.{input_fields}: Any input fields (tensor, etc.)out.{output_fields}: Any output fields (out.house_price,out.variable, etc.)anomaly.count: Any anomalies detected from validations.anomaly.{validation}: The validation that triggered the anomaly detection and whether it isTrue(indicating an anomaly was detected) orFalse. For more details, see Wallaroo SDK Essentials Guide: Anomaly Detection
For example, the following requests the metadata plus any output fields.
metadatalogs = mainpipeline.logs(dataset=["out","metadata"])
display(metadatalogs.loc[:, ['out.variable', 'metadata.last_model']])
| out.variable | metadata.last_model | |
|---|---|---|
| 0 | [581003.0] | {“model_name”:“logcontrol”,“model_sha”:“e22a0831aafd9917f3cc87a15ed267797f80e2afa12ad7d8810ca58f173b8cc6”} |
| 1 | [706823.56] | {“model_name”:“logcontrol”,“model_sha”:“e22a0831aafd9917f3cc87a15ed267797f80e2afa12ad7d8810ca58f173b8cc6”} |
| 2 | [1060847.5] | {“model_name”:“logcontrol”,“model_sha”:“e22a0831aafd9917f3cc87a15ed267797f80e2afa12ad7d8810ca58f173b8cc6”} |
| 3 | [441960.38] | {“model_name”:“logcontrol”,“model_sha”:“e22a0831aafd9917f3cc87a15ed267797f80e2afa12ad7d8810ca58f173b8cc6”} |
| 4 | [827411.0] | {“model_name”:“logcontrol”,“model_sha”:“e22a0831aafd9917f3cc87a15ed267797f80e2afa12ad7d8810ca58f173b8cc6”} |
Shadow Deploy Testing Pipeline Steps
Effected pipeline steps:
add_shadow_deployreplace_with_shadow_deploy
For log file requests, the following metadata dataset requests for shadow deploy testing pipeline steps are available:
metadata
These must be paired with specific columns. * is not available when paired with metadata. time must be included if dataset is used.
in: All input fields.out: All output fields.time: The DateTime the inference request was made.in.{input_fields}: Any input fields (tensor, etc.).out.{output_fields}: Any output fields matching the specificoutput_field(out.house_price,out.variable, etc.).out_: All shadow deployed challenger steps Any output fields matching the specificoutput_field(out.house_price,out.variable, etc.).anomaly.count: Any anomalies detected from validations.anomaly.{validation}: The validation that triggered the anomaly detection and whether it isTrue(indicating an anomaly was detected) orFalse. For more details, see Wallaroo SDK Essentials Guide: Anomaly Detection
The following example retrieves the logs from a pipeline with shadow deployed models, and displays the specific shadow deployed model outputs and the metadata.elasped field.
# Display metadata
metadatalogs = mainpipeline.logs(dataset=["out_logcontrolchallenger01.variable",
"out_logcontrolchallenger02.variable",
"metadata"
]
)
display(metadatalogs.loc[:, ['out_logcontrolchallenger01.variable',
'out_logcontrolchallenger02.variable',
'metadata.elapsed'
]
])
| out_logcontrolchallenger01.variable | out_logcontrolchallenger02.variable | metadata.elapsed | |
|---|---|---|---|
| 0 | [573391.1] | [596933.5] | [302804, 26900] |
| 1 | [663008.75] | [594914.2] | [302804, 26900] |
| 2 | [1520770.0] | [1491293.8] | [302804, 26900] |
| 3 | [381577.16] | [411258.3] | [302804, 26900] |
| 4 | [743487.94] | [787589.25] | [302804, 26900] |
A/B Deploy Testing Pipeline Steps
Effected pipeline steps:
add_random_splitreplace_with_random_split
For log file requests, the following metadata dataset requests for A/B testing pipeline steps are available:
metadata
These must be paired with specific columns. * is not available when paired with metadata. time must be included if dataset is used.
in: All input fields.out: All output fields.time: The DateTime the inference request was made. Must be requested in alldatasetrequests.in.{input_fields}: Any input fields (tensor, etc.).out.{output_fields}: Any output fields matching the specificoutput_field(out.house_price,out.variable, etc.).anomaly.count: Any anomalies detected from validations.anomaly.{validation}: The validation that triggered the anomaly detection and whether it isTrue(indicating an anomaly was detected) orFalse. For more details, see Wallaroo SDK Essentials Guide: Anomaly Detection
The following example retrieves the logs from a pipeline with A/B deployed models, and displays the output and the specific metadata.last_model field.
metadatalogs = mainpipeline.logs(dataset=["time",
"out",
"metadata"
]
)
display(metadatalogs.loc[:, ['out.variable', 'metadata.last_model']])
| out.variable | metadata.last_model | |
|---|---|---|
| 0 | [581003.0] | {“model_name”:“logcontrol”,“model_sha”:“e22a0831aafd9917f3cc87a15ed267797f80e2afa12ad7d8810ca58f173b8cc6”} |
| 1 | [706823.56] | {“model_name”:“logcontrol”,“model_sha”:“e22a0831aafd9917f3cc87a15ed267797f80e2afa12ad7d8810ca58f173b8cc6”} |
| 2 | [1060847.5] | {“model_name”:“logcontrol”,“model_sha”:“e22a0831aafd9917f3cc87a15ed267797f80e2afa12ad7d8810ca58f173b8cc6”} |
| 3 | [441960.38] | {“model_name”:“logcontrol”,“model_sha”:“e22a0831aafd9917f3cc87a15ed267797f80e2afa12ad7d8810ca58f173b8cc6”} |
| 4 | [827411.0] | {“model_name”:“logcontrol”,“model_sha”:“e22a0831aafd9917f3cc87a15ed267797f80e2afa12ad7d8810ca58f173b8cc6”} |
Export Pipeline Logs as File
The Pipeline method export_logs returns the Pipeline records as either by default pandas records in Newline Delimited JSON (NDJSON) format, or an Apache Arrow table files.
The output files are by default stores in the current working directory ./logs with the default prefix as the {pipeline name}-1, {pipeline name}-2, etc.
IMPORTANT NOTE
Files with the same names will be overwritten.The suffix by default will be json for pandas records in Newline Delimited JSON (NDJSON) format files. Logs are segmented by pipeline version across the limit, data_size_limit, or start_datetime and end_datetime parameters.
By default, logs are returned as a pandas record in NDJSON in reverse chronological order of insertion, with the most recent log insertions displayed first.
Pipeline logs are segmented by pipeline versions. For example, if a new model step is added to a pipeline, a model swapped out of a pipeline step, etc - this generated a new pipeline version.
IMPORTANT NOTE
Pipeline logs are returned either in reverse or forward chronological order of record insertion; depending on when a specific inference request completes, one inference record may be inserted out of chronological order by theTimestamp value, but still be in chronological order of insertion.This command takes the following parameters.
| Parameter | Type | Description |
|---|---|---|
directory | String (Optional) (Default: logs) | Logs are exported to a file from current working directory to directory. |
file_prefix | String (Optional) (Default: The name of the pipeline) | The name of the exported files. By default, this will the name of the pipeline and is segmented by pipeline version between the limits or the start and end period. For example: ’logpipeline-1.json`, etc. |
data_size_limit | String (Optional) (Default: 100MB) | The maximum size for the exported data in bytes. Note that file size is approximate to the request; a request of 10MiB may return 10.3MB of data. The fields are in the format “{size as number} {unit value}”, and can include a space so “10 MiB” and “10MiB” are the same. The accepted unit values are:
|
limit | Int (Optional) (Default: 100) | Limits how many log records to display. Defaults to 100. If there are more pipeline logs than are being displayed, the Warning message Pipeline log record limit exceeded will be displayed. For example, if 100 log files were requested and there are a total of 1,000, the warning message will be displayed. |
start_datetime and end_datetime | DateTime (Optional) | Limits logs to all logs between the start_datetime and end_datetime DateTime parameters. These comply with the Python datetime library for formats such as:
Both parameters must be provided. Submitting a logs() request with only start_datetime or end_datetime will generate an exception.If start_datetime and end_datetime are provided as parameters even with any other parameter, then the records are returned in chronological order, with the oldest record displayed first. |
filename | String (Required) | The file name to save the log file to. The requesting user must have write access to the file location. The requesting user must have write permission to the file location, and the target directory for the file must already exist. For example: If the file is set to /var/wallaroo/logs/pipeline.json, then the directory /var/wallaroo/logs must already exist. Otherwise file names are only limited by standard file naming rules for the target environment. |
dataset | List (OPTIONAL) | The datasets to be returned. The datasets available are:
metadata.elapsed: IMPORTANT NOTE: See Metadata Requests Restrictionsfor specifications on how this dataset can be used with other datasets.
|
dataset_exclude | List[String] (OPTIONAL) | Exclude specified datasets. |
dataset_separator | Sequence[[String], string] (OPTIONAL) | If set to “.”, return dataset will be flattened. |
arrow | Boolean (Optional) | Defaults to False. If arrow=True, then the logs are returned as an Apache Arrow table. If arrow=False, then the logs are returned as pandas record in NDJSON that can be imported into a pandas DataFrame. |
All of the parameters can be used together, but start_datetime and end_datetime must be combined; if one is used, then so must the other. If start_datetime and end_datetime are used with any other parameter, then the log results are in chronological order of record insertion.
File sizes are limited to around 10 MB in size. If the requested log file is greater than 10 MB, a Warning will be displayed indicating the end date of the log file downloaded so the request can be adjusted to capture the requested log files.
IMPORTANT NOTE
DataFrame file exports exported as pandas record in NDJSON are read back to a DataFrame through the the pandas read_json method with the parameter lines=True. For example:
data_df = pd.read_json("mainpipeline_logs.df.json", lines=True)
display(data_df)
In this example, the log files are saved as both Pandas DataFrame and Apache Arrow.
# Save the DataFrame version of the log file
mainpipeline.export_logs()
display(os.listdir('./logs'))
mainpipeline.export_logs(arrow=True)
display(os.listdir('./logs'))
Warning: There are more logs available. Please set a larger limit to export more data.
['pipeline-logs-1.json']
Warning: There are more logs available. Please set a larger limit to export more data.
['pipeline-logs-1.arrow', 'pipeline-logs-1.json']
Pipeline Log Storage
Pipeline logs have a set allocation of storage space and data requirements.
Pipeline Log Storage Warnings
To prevent storage and performance issues, inference result data may be dropped from pipeline logs by the following standards:
- Columns are progressively removed from the row starting with the largest input data size and working to the smallest, then the same for outputs.
For example, Computer Vision ML Models typically have large inputs and output values - a single pandas DataFrame inference request may be over 13 MB in size, and the inference results nearly as large. To prevent pipeline log storage issues, the input may be dropped from the pipeline logs, and if additional space is needed, the inference outputs would follow. The time column is preserved.
IMPORTANT NOTE
Inference Requests will always return all inputs, outputs, and other metadata unless specifically requested for exclusion. It is the pipeline logs that may drop columns for space purposes.If a pipeline has dropped columns for space purposes, this will be displayed when a log request is made with the following warning, with {columns} replaced with the dropped columns.
The inference log is above the allowable limit and the following columns may have been suppressed for various rows in the logs: {columns}. To review the dropped columns for an individual inference’s suppressed data, include dataset=["metadata"] in the log request.
Review Dropped Columns
To review what columns are dropped from pipeline logs for storage reasons, include the dataset metadata in the request to view the column metadata.dropped. This metadata field displays a List of any columns dropped from the pipeline logs.
For example:
metadatalogs = mainpipeline.logs(dataset=["time", "metadata"])
| time | metadata.dropped | |
|---|---|---|
| 0 | 2023-07-06 | 15:47:03.673 |
| 1 | 2023-07-06 | 15:47:03.673 |
| 2 | 2023-07-06 | 15:47:03.673 |
| 3 | 2023-07-06 | 15:47:03.673 |
| 4 | 2023-07-06 | 15:47:03.673 |
| … | … | … |
| 95 | 2023-07-06 | 15:47:03.673 |
| 96 | 2023-07-06 | 15:47:03.673 |
| 97 | 2023-07-06 | 15:47:03.673 |
| 98 | 2023-07-06 | 15:47:03.673 |
| 99 | 2023-07-06 | 15:47:03.673 |
Suppressed Data Elements
Data elements that do not fit the supported data types below, such as None or Null values, are not supported in pipeline logs. When present, undefined data will be written in the place of the null value, typically zeroes. Any null list values will present an empty list.
Retrieve Inference Request Logs Via the Wallaroo MLOps API
Inference Logs Endpoints
Pipeline logs are retrieved through the Wallaroo MLOps API with the following request.
- REQUEST URL
v1/api/pipelines/get_logs
- Headers
- Accept:
application/json; format=pandas-records: For the logs returned as pandas DataFrameapplication/vnd.apache.arrow.file: for the logs returned as Apache Arrow
- Accept:
- PARAMETERS
- pipeline_id (String Required): The name of the pipeline.
- workspace_id (Integer Required): The numerical identifier of the workspace.
- cursor (String Optional): Cursor returned with a previous page of results from a pipeline log request, used to retrieve the next page of information.
- order (String Optional Default:
Desc): The order for log inserts returned. Valid values are:Asc: In chronological order of inserts.Desc: In reverse chronological order of inserts.
- page_size (Integer Optional Default:
1000.): Max records per page. - start_time (String Optional): The start time of the period to retrieve logs for in RFC 3339 format for DateTime. Must be combined with
end_time. - end_time (String Optional): The end time of the period to retrieve logs for in RFC 3339 format for DateTime. Must be combined with
start_time.
- RETURNS
- The logs are returned by default as
'application/json; format=pandas-records'format. To request the logs as Apache Arrow tables, set the submission headerAccepttoapplication/vnd.apache.arrow.file. - Headers:
- x-iteration-cursor: Used to retrieve the next page of results. This is not included if
x-iteration-statusisAll. - x-iteration-status: Informs whether there are more records available outside of this log request parameters.
- All: This page includes all logs available from this request. If
x-iteration-statusisAll, thenx-iteration-cursoris not provided. - SchemaChange: A change in the log schema caused by actions such as pipeline version, etc.
- RecordLimited: The number of records exceeded from the page size, more records can be requested as the next page. There may be more records available to retrieve OR the record limit was reached for this request even if no more records are available in next cursor request.
- ByteLimited: The number of records exceeded the pipeline log limit which is around 100K.
- All: This page includes all logs available from this request. If
- x-iteration-cursor: Used to retrieve the next page of results. This is not included if
- The logs are returned by default as
Inference Logs Example: Standard Model Deployment
The following demonstrates retrieving inference logs from a standard model deployment.
# retrieve the authorization token
headers = wl.auth.auth_header()
url = f"{APIURL}/v1/api/pipelines/get_logs"
# Standard log retrieval
data = {
'pipeline_id': main_pipeline_name,
'workspace_id': workspace_id
}
response = requests.post(url, headers=headers, json=data)
standard_logs = pd.DataFrame.from_records(response.json())
display(standard_logs.head(5).loc[:, ["time", "in", "out"]])
| time | in | out | |
|---|---|---|---|
| 0 | 1684423875900 | {'tensor': [4.0, 2.5, 2900.0, 5505.0, 2.0, 0.0, 0.0, 3.0, 8.0, 2900.0, 0.0, 47.6063, -122.02, 2970.0, 5251.0, 12.0, 0.0, 0.0]} | {'variable': [718013.75]} |
| 1 | 1684423875900 | {'tensor': [2.0, 2.5, 2170.0, 6361.0, 1.0, 0.0, 2.0, 3.0, 8.0, 2170.0, 0.0, 47.7109, -122.017, 2310.0, 7419.0, 6.0, 0.0, 0.0]} | {'variable': [615094.56]} |
| 2 | 1684423875900 | {'tensor': [3.0, 2.5, 1300.0, 812.0, 2.0, 0.0, 0.0, 3.0, 8.0, 880.0, 420.0, 47.5893, -122.317, 1300.0, 824.0, 6.0, 0.0, 0.0]} | {'variable': [448627.72]} |
| 3 | 1684423875900 | {'tensor': [4.0, 2.5, 2500.0, 8540.0, 2.0, 0.0, 0.0, 3.0, 9.0, 2500.0, 0.0, 47.5759, -121.994, 2560.0, 8475.0, 24.0, 0.0, 0.0]} | {'variable': [758714.2]} |
| 4 | 1684423875900 | {'tensor': [3.0, 1.75, 2200.0, 11520.0, 1.0, 0.0, 0.0, 4.0, 7.0, 2200.0, 0.0, 47.7659, -122.341, 1690.0, 8038.0, 62.0, 0.0, 0.0]} | {'variable': [513264.7]} |
Inference Logs Example: Shadow Deploy Deployment
The following demonstrates retrieving inference logs from a model deployment with shadow deployed steps.
# Retrieve logs from specific date/time to only get the two DataFrame input inferences in ascending format
# retrieve the authorization token
headers = wl.auth.auth_header()
url = f"{APIURL}/v1/api/pipelines/get_logs"
# Standard log retrieval
data = {
'pipeline_id': main_pipeline_name,
'workspace_id': workspace_id,
'order': 'Asc',
'start_time': f'{shadow_date_start.isoformat()}',
'end_time': f'{shadow_date_end.isoformat()}'
}
response = requests.post(url, headers=headers, json=data)
standard_logs = pd.DataFrame.from_records(response.json())
display(standard_logs.head(5).loc[:, ["time", "out", "out_logcontrolchallenger01", "out_logcontrolchallenger02"]])
| time | out | out_logcontrolchallenger01 | out_logcontrolchallenger02 | |
|---|---|---|---|---|
| 0 | 1684427140394 | {'variable': [718013.75]} | {'variable': [659806.0]} | {'variable': [704901.9]} |
| 1 | 1684427140394 | {'variable': [615094.56]} | {'variable': [732883.5]} | {'variable': [695994.44]} |
| 2 | 1684427140394 | {'variable': [448627.72]} | {'variable': [419508.84]} | {'variable': [416164.8]} |
| 3 | 1684427140394 | {'variable': [758714.2]} | {'variable': [634028.8]} | {'variable': [655277.2]} |
| 4 | 1684427140394 | {'variable': [513264.7]} | {'variable': [427209.44]} | {'variable': [426854.66]} |
Inference Logs Example: A/B Test Deployment
The following demonstrates retrieving inference logs from a model deployment with A/B Testing deployed steps.
# Retrieve logs from specific date/time to only get the two DataFrame input inferences in ascending format
# retrieve the authorization token
headers = wl.auth.auth_header()
url = f"{APIURL}/v1/api/pipelines/get_logs"
# Standard log retrieval
data = {
'pipeline_id': main_pipeline_name,
'workspace_id': workspace_id,
'order': 'Asc',
'start_time': f'{ab_date_start.isoformat()}',
'end_time': f'{ab_date_end.isoformat()}'
}
response = requests.post(url, headers=headers, json=data)
standard_logs = pd.DataFrame.from_records(response.json())
display(standard_logs.head(5).loc[:, ["time", "out"]])
| time | out | |
|---|---|---|
| 0 | 1684427501820 | {'_model_split': ['{"name":"logcontrolchallenger02","version":"89dba25e-a11e-453d-9bcc-cddf8d6ddea0","sha":"ed6065a79d841f7e96307bb20d5ef22840f15da0b587efb51425c7ad60589d6a"}'], 'variable': [715947.75]} |
| 1 | 1684427502196 | {'_model_split': ['{"name":"logcontrolchallenger01","version":"07fe7686-9bd0-4fd3-9a7c-0e933a74003c","sha":"31e92d6ccb27b041a324a7ac22cf95d9d6cc3aa7e8263a229f7c4aec4938657c"}'], 'variable': [341386.34]} |
| 2 | 1684427503778 | {'_model_split': ['{"name":"logapicontrol","version":"70b76ecb-55c2-4d68-be9b-b440b11e6499","sha":"e22a0831aafd9917f3cc87a15ed267797f80e2afa12ad7d8810ca58f173b8cc6"}'], 'variable': [1039781.2]} |
| 3 | 1684427504566 | {'_model_split': ['{"name":"logcontrolchallenger02","version":"89dba25e-a11e-453d-9bcc-cddf8d6ddea0","sha":"ed6065a79d841f7e96307bb20d5ef22840f15da0b587efb51425c7ad60589d6a"}'], 'variable': [411090.75]} |
| 4 | 1684427505094 | {'_model_split': ['{"name":"logcontrolchallenger02","version":"89dba25e-a11e-453d-9bcc-cddf8d6ddea0","sha":"ed6065a79d841f7e96307bb20d5ef22840f15da0b587efb51425c7ad60589d6a"}'], 'variable': [296175.66]} |
Pipeline Log Storage
Pipeline logs have a set allocation of storage space and data requirements.
Pipeline Log Storage Warnings
To prevent storage and performance issues, inference result data may be dropped from pipeline logs by the following standards:
- Columns are progressively removed from the row starting with the largest input data size and working to the smallest, then the same for outputs.
For example, Computer Vision ML Models typically have large inputs and output values - a single pandas DataFrame inference request may be over 13 MB in size, and the inference results nearly as large. To prevent pipeline log storage issues, the input may be dropped from the pipeline logs, and if additional space is needed, the inference outputs would follow. The time column is preserved.
IMPORTANT NOTE
Inference Requests will always return all inputs, outputs, and other metadata unless specifically requested for exclusion. It is the pipeline logs that may drop columns for space purposes.If a pipeline has dropped columns for space purposes, this will be displayed when a log request is made with the following warning, with {columns} replaced with the dropped columns.
The inference log is above the allowable limit and the following columns may have been suppressed for various rows in the logs: {columns}. To review the dropped columns for an individual inference’s suppressed data, include dataset=["metadata"] in the log request.
Review Dropped Columns
To review what columns are dropped from pipeline logs for storage reasons, include the dataset metadata in the request to view the column metadata.dropped. This metadata field displays a List of any columns dropped from the pipeline logs.
For example:
# retrieve the authorization token
headers = wl.auth.auth_header()
url = f"{APIURL}/v1/api/pipelines/get_logs"
# Standard log retrieval
data = {
'pipeline_id': main_pipeline_name,
'workspace_id': workspace_id
}
response = requests.post(url, headers=headers, json=data)
standard_logs = pd.DataFrame.from_records(response.json())
display(len(standard_logs))
display(standard_logs.head(5).loc[:, ["time", "metadata"]])
cursor = response.headers['x-iteration-cursor']
| time | metadata | |
|---|---|---|
| 0 | 1688760035752 | {’last_model’: ‘{“model_name”:“logapicontrol”,“model_sha”:“e22a0831aafd9917f3cc87a15ed267797f80e2afa12ad7d8810ca58f173b8cc6”}’, ‘pipeline_version’: ‘’, ’elapsed’: [112967, 267146], ‘dropped’: []} |
| 1 | 1688760036054 | {’last_model’: ‘{“model_name”:“logapicontrol”,“model_sha”:“e22a0831aafd9917f3cc87a15ed267797f80e2afa12ad7d8810ca58f173b8cc6”}’, ‘pipeline_version’: ‘’, ’elapsed’: [37127, 594183], ‘dropped’: []} |
| 2 | 1688759857040 | {’last_model’: ‘{“model_name”:“logapicontrol”,“model_sha”:“e22a0831aafd9917f3cc87a15ed267797f80e2afa12ad7d8810ca58f173b8cc6”}’, ‘pipeline_version’: ‘’, ’elapsed’: [111082, 253184], ‘dropped’: []} |
| 3 | 1688759857526 | {’last_model’: ‘{“model_name”:“logapicontrol”,“model_sha”:“e22a0831aafd9917f3cc87a15ed267797f80e2afa12ad7d8810ca58f173b8cc6”}’, ‘pipeline_version’: ‘’, ’elapsed’: [43962, 265740], ‘dropped’: []} |
Suppressed Data Elements
Data elements that do not fit the supported data types below, such as None or Null values, are not supported in pipeline logs. When present, undefined data will be written in the place of the null value, typically zeroes. Any null list values will present an empty list.