Retail: Drift Detection
Tutorial Notebook 4: Observability Part 2 - Drift Detection
In the previous notebook you learned how to add simple validation rules to a pipeline, to monitor whether outputs (or inputs) stray out of some expected range. In this notebook, you will monitor the distribution of the pipeline’s predictions to see if the model, or the environment that it runs it, has changed.
Preliminaries
In the blocks below we will preload some required libraries; we will also redefine some of the convenience functions that you saw in the previous notebooks.
After that, you should log into Wallaroo and set your working environment to the workspace that you created for this tutorial. Please refer to Notebook 1 to refresh yourself on how to log in and set your working environment to the appropriate workspace.
# preload needed libraries
import wallaroo
from wallaroo.object import EntityNotFoundError
from IPython.display import display
# used to display DataFrame information without truncating
from IPython.display import display
import pandas as pd
pd.set_option('display.max_colwidth', None)
import json
import datetime
import time
# used for unique connection names
import string
import random
import pyarrow as pa
## convenience functions from the previous notebooks
## these functions assume your connection to wallaroo is called wl
# return the workspace called <name>, or create it if it does not exist.
# this function assumes your connection to wallaroo is called wl
def get_workspace(name):
workspace = None
for ws in wl.list_workspaces():
if ws.name() == name:
workspace= ws
if(workspace == None):
workspace = wl.create_workspace(name)
return workspace
# pull a single datum from a data frame
# and convert it to the format the model expects
def get_singleton(df, i):
singleton = df.iloc[i,:].to_numpy().tolist()
sdict = {'tensor': [singleton]}
return pd.DataFrame.from_dict(sdict)
# pull a batch of data from a data frame
# and convert to the format the model expects
def get_batch(df, first=0, nrows=1):
last = first + nrows
batch = df.iloc[first:last, :].to_numpy().tolist()
return pd.DataFrame.from_dict({'tensor': batch})
# Translated a column from a dataframe into a single array
# used for the Statsmodel forecast model
def get_singleton_forecast(df, field):
singleton = pd.DataFrame({field: [df[field].values.tolist()]})
return singleton
# Get the most recent version of a model in the workspace
# Assumes that the most recent version is the first in the list of versions.
# wl.get_current_workspace().models() returns a list of models in the current workspace
def get_model(mname):
modellist = wl.get_current_workspace().models()
model = [m.versions()[-1] for m in modellist if m.name() == mname]
if len(model) <= 0:
raise KeyError(f"model {mname} not found in this workspace")
return model[0]
# get a pipeline by name in the workspace
def get_pipeline(pname):
plist = wl.get_current_workspace().pipelines()
pipeline = [p for p in plist if p.name() == pname]
if len(pipeline) <= 0:
raise KeyError(f"pipeline {pname} not found in this workspace")
return pipeline[0]
## blank space to log in and go to correct workspace
## blank space to log in and go to the appropriate workspace
wl = wallaroo.Client()
import string
import random
suffix= ''.join(random.choice(string.ascii_lowercase) for i in range(4))
workspace_name = f'forecast-model-tutorial'
workspace = get_workspace(workspace_name)
wl.set_current_workspace(workspace)
{'name': 'forecast-model-tutorialjohn', 'id': 16, 'archived': False, 'created_by': '0a36fba2-ad42-441b-9a8c-bac8c68d13fa', 'created_at': '2023-08-02T15:50:52.816795+00:00', 'models': [{'name': 'forecast-control-model', 'versions': 3, 'owner_id': '""', 'last_update_time': datetime.datetime(2023, 8, 3, 1, 11, 50, 568151, tzinfo=tzutc()), 'created_at': datetime.datetime(2023, 8, 2, 15, 50, 54, 223186, tzinfo=tzutc())}, {'name': 'forecast-challenger01-model', 'versions': 3, 'owner_id': '""', 'last_update_time': datetime.datetime(2023, 8, 3, 13, 55, 23, 119224, tzinfo=tzutc()), 'created_at': datetime.datetime(2023, 8, 2, 15, 50, 55, 208179, tzinfo=tzutc())}, {'name': 'forecast-challenger02-model', 'versions': 3, 'owner_id': '""', 'last_update_time': datetime.datetime(2023, 8, 3, 13, 55, 24, 133756, tzinfo=tzutc()), 'created_at': datetime.datetime(2023, 8, 2, 15, 50, 56, 291043, tzinfo=tzutc())}], 'pipelines': [{'name': 'forecast-tutorial-pipeline', 'create_time': datetime.datetime(2023, 8, 2, 15, 50, 59, 480547, tzinfo=tzutc()), 'definition': '[]'}]}
Monitoring for Drift: Shift Happens.
In machine learning, you use data and known answers to train a model to make predictions for new previously unseen data. You do this with the assumption that the future unseen data will be similar to the data used during training: the future will look somewhat like the past.
But the conditions that existed when a model was created, trained and tested can change over time, due to various factors.
A good model should be robust to some amount of change in the environment; however, if the environment changes too much, your models may no longer be making the correct decisions. This situation is known as concept drift; too much drift can obsolete your models, requiring periodic retraining.
Let’s consider the example we’ve been working on: home sale price prediction. You may notice over time that there has been a change in the mix of properties in the listings portfolio: for example a dramatic increase or decrease in expensive properties (or more precisely, properties that the model thinks are expensive)
Such a change could be due to many factors: a change in interest rates; the appearance or disappearance of major sources of employment; new housing developments opening up in the area. Whatever the cause, detecting such a change quickly is crucial, so that the business can react quickly in the appropriate manner, whether that means simply retraining the model on fresher data, or a pivot in business strategy.
In Wallaroo you can monitor your housing model for signs of drift through the model monitoring and insight capability called Assays. Assays help you track changes in the environment that your model operates within, which can affect the model’s outcome. It does this by tracking the model’s predictions and/or the data coming into the model against an established baseline. If the distribution of monitored values in the current observation window differs too much from the baseline distribution, the assay will flag it. The figure below shows an example of a running scheduled assay.
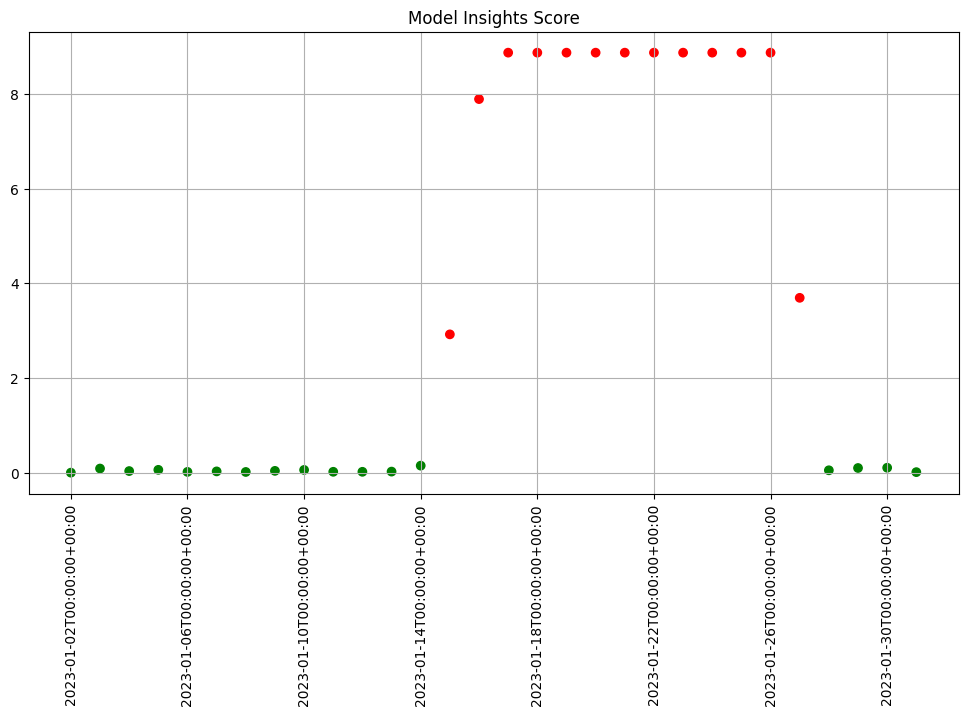
Figure: A daily assay that’s been running for a month. The dots represent the difference between the distribution of values in the daily observation window, and the baseline. When that difference exceeds the specified threshold (indicated by a red dot) an alert is set.
This next set of exercises will walk you through setting up an assay to monitor the predictions of your house price model, in order to detect drift.
NOTE
An assay is a monitoring process that typically runs over an extended, ongoing period of time. For example, one might set up an assay that every day monitors the previous 24 hours’ worth of predictions and compares it to a baseline. For the purposes of these exercises, we’ll be compressing processes what normally would take hours or days into minutes.
Exercise Prep: Create some datasets for demonstrating assays
Because assays are designed to detect changes in distributions, let’s try to set up data with different distributions to test with. Take your houseprice data and create two sets: a set with lower prices, and a set with higher prices. You can split however you choose.
The idea is we will pretend that the set of lower priced houses represent the “typical” mix of houses in the housing portfolio at the time you set your baseline; you will introduce the higher priced houses later, to represent an environmental change when more expensive houses suddenly enter the market.
- If you are using the pre-provided models to do these exercises, you can use the provided data sets
lowprice.df.jsonandhighprice.df.json. This is to establish our baseline as a set of known values, so the higher prices will trigger our assay alerts.
lowprice_data = pd.read_json('lowprice.df.json')
highprice_data = pd.read_json('highprice.df.json')
Note that the data in these files are already in the form expected by the models, so you don’t need to use the get_singleton or get_batch convenience functions to infer.
At the end of this exercise, you should have two sets of data to demonstrate assays. In the discussion below, we’ll refer to these sets as lowprice_data and highprice_data.
# blank spot to split or download data
sample_count = pd.read_csv('../data/test_data.csv')
# sample_df = sample_count.loc[0:20, ['count']]
inference_df = get_singleton_forecast(sample_count.loc[1:30], 'count')
display(inference_df)
| count | |
|---|---|
| 0 | [801, 1349, 1562, 1600, 1606, 1510, 959, 822, 1321, 1263, 1162, 1406, 1421, 1248, 1204, 1000, 683, 1650, 1927, 1543, 981, 986, 1416, 1985, 506, 431, 1167, 1098, 1096, 1501] |
We will use this data to set up some “historical data” in the house price prediction pipeline that you build in the assay exercises.
Setting up a baseline for the assay
In order to know whether the distribution of your model’s predictions have changed, you need a baseline to compare them to. This baseline should represent how you expect the model to behave at the time it was trained. This might be approximated by the distribution of the model’s predictions over some “typical” period of time. For example, we might collect the predictions of our model over the first few days after it’s been deployed. For these exercises, we’ll compress that to a few minutes. Currently, to set up a wallaroo assay the pipeline must have been running for some period of time, and the assumption is that this period of time is “typical”, and that the distributions of the inputs and the outputs of the model during this period of time are “typical.”
Exercise Prep: Run some inferences and set some time stamps
Here, we simulate having a pipeline that’s been running for a long enough period of time to set up an assay.
To send enough data through the pipeline to create assays, you execute something like the following code (using the appropriate names for your pipelines and models). Note that this step will take a little while, because of the sleep interval.
You will need the timestamps baseline_start, and baseline_end, for the next exercises.
# get your pipeline (in this example named "mypipeline")
pipeline = get_pipeline("mypipeline")
pipeline.deploy()
## Run some baseline data
# Where the baseline data will start
baseline_start = datetime.datetime.now()
# the number of samples we'll use for the baseline
nsample = 500
# Wait 30 seconds to set this data apart from the rest
# then send the data in batch
time.sleep(30)
# get a sample
lowprice_data_sample = lowprice_data.sample(nsample, replace=True).reset_index(drop=True)
pipeline.infer(lowprice_data_sample)
# Set the baseline end
baseline_end = datetime.datetime.now()
# blank space to get pipeline and set up baseline data
control_model_name = 'forecast-control-model'
bike_day_model = get_model(control_model_name)
pipeline_name = 'forecast-tutorial-pipeline'
pipeline = get_pipeline(pipeline_name)
# set the pipeline step
pipeline.undeploy()
pipeline.clear()
pipeline.add_model_step(bike_day_model)
pipeline.deploy()
pipeline.steps()
[{'ModelInference': {'models': [{'name': 'forecast-control-model', 'version': 'd9af417f-29c3-49b1-9cad-a930779825d2', 'sha': '98b5f0911f608fdf9052b1b6db95c89a2c77c4b10d8f64a6d27df846ac616eb1'}]}}]
# test inference
sample_count = pd.read_csv('../data/test_data.csv')
inference_df = get_singleton_forecast(sample_count.loc[2:22], 'count')
results = pipeline.infer(inference_df)
display(results)
| time | in.count | out.forecast | out.weekly_average | check_failures | |
|---|---|---|---|---|---|
| 0 | 2023-08-03 15:01:28.625 | [1349, 1562, 1600, 1606, 1510, 959, 822, 1321, 1263, 1162, 1406, 1421, 1248, 1204, 1000, 683, 1650, 1927, 1543, 981, 986] | [1278, 1295, 1295, 1295, 1295, 1295, 1295] | [1292.5714285714287] | 0 |
Before setting up an assay on this pipeline’s output, we may want to look at the distribution of the predictions over our selected baseline period. To do that, we’ll create an assay_builder that specifies the pipeline, the model in the pipeline, and the baseline period.. We’ll also specify that we want to look at the output of the model, which in the example code is named variable, and would appear as out.variable in the logs.
# print out one of the logs to get the name of the output variable
display(pipeline.logs(limit=1))
# get the model name directly off the pipeline (you could just hard code this, if you know the name)
model_name = pipeline.model_configs()[0].model().name()
assay_builder = ( wl.build_assay(assay_name, pipeline, model_name,
baseline_start, baseline_end)
.add_iopath("output variable 0") ) # specify that we are looking at the first output of the output variable "variable"
where baseline_start and baseline_end are the beginning and end of the baseline periods as datetime.datetime objects.
You can then examine the distribution of variable over the baseline period:
assay_builder.baseline_histogram()
Exercise: Create an assay builder and set a baseline
Create an assay builder to monitor the output of your house price pipeline. The baseline period should be from baseline_start to baseline_end.
- You will need to know the name of your output variable, and the name of the model in the pipeline.
Examine the baseline distribution.
## Blank space to create an assay builder and examine the baseline distribution
# we'll use the first month in 2011 as the baseline. Then we can compare the first month of 2022 next.
import datetime
baseline_start = datetime.datetime.now()
for i in range(30):
inference_df = get_singleton_forecast(sample_count.loc[i:i+30], 'count')
results = pipeline.infer(inference_df)
baseline_end = datetime.datetime.now()
# now build the actual baseline
import string
import random
assay_suffix= ''.join(random.choice(string.ascii_lowercase) for i in range(4))
assay_name = f'forecast assay {assay_suffix}'
assay_builder = ( wl.build_assay(assay_name,
pipeline,
control_model_name,
baseline_start,
baseline_end
)
.add_iopath("output weekly_average 0") )
baseline_run = assay_builder.build().interactive_baseline_run()
baseline_run.baseline_stats()
| Baseline | |
|---|---|
| count | 29 |
| min | 1232.428571 |
| max | 1800.142857 |
| mean | 1439.492611 |
| median | 1387.571429 |
| std | 168.388389 |
| start | 2023-08-03T15:03:54.045601Z |
| end | 2023-08-03T15:04:08.323293Z |
An assay should detect if the distribution of model predictions changes from the above distribution over regularly sampled observation windows. This is called drift.
To show drift, we’ll run more data through the pipeline – first some data drawn from the same distribution as the baseline (lowprice_data). Then, we will gradually introduce more data from a different distribution (highprice_data). We should see the difference between the baseline distribution and the distribution in the observation window increase.
To set up the data, you should do something like the below. It will take a while to run, because of all the sleep intervals.
You will need the assay_window_end for a later exercise.
IMPORTANT NOTE: To generate the data for the assay, this process may take 4-5 minutes. Because the shortest period of time for an assay window is 1 minute, the intervals of inference data are spaced to fall within that time period.
# Set the start for our assay window period.
assay_window_start = datetime.datetime.now()
# Run a set of house values, spread across a "longer" period of time
# run "typical" data
for x in range(4):
pipeline.infer(lowprice_data.sample(2*nsample, replace=True).reset_index(drop=True))
time.sleep(25)
# run a mix
for x in range(3):
pipeline.infer(lowprice_data.sample(nsample, replace=True).reset_index(drop=True))
pipeline.infer(highprice_data.sample(nsample, replace=True).reset_index(drop=True))
time.sleep(25)
# high price houses dominate the sample
for x in range(3):
pipeline.infer(highprice_data.sample(2*nsample, replace=True).reset_index(drop=True))
time.sleep(25)
# End our assay window period
assay_window_end = datetime.datetime.now()
Exercise Prep: Run some inferences and set some time stamps
Run more data through the pipeline, manifesting a drift, like the example above. It may around 10 minutes depending on how you stagger the inferences.
## Blank space to run more data
# same inferences as before, but now we'll jump ahead to 2012, and get 4 months of assays
import time
assay_start = datetime.datetime.now()
for i in range(30):
inference_df = get_singleton_forecast(sample_count.loc[i+367:i+397], 'count')
results = pipeline.infer(inference_df)
time.sleep(60)
for i in range(30):
inference_df = get_singleton_forecast(sample_count.loc[i+397:i+427], 'count')
results = pipeline.infer(inference_df)
time.sleep(60)
for i in range(30):
inference_df = get_singleton_forecast(sample_count.loc[i+427:i+457], 'count')
results = pipeline.infer(inference_df)
assay_end = datetime.datetime.now()
Defining the Assay Parameters
Now we’re finally ready to set up an assay!
The Observation Window
Once a baseline period has been established, you must define the window of observations that will be compared to the baseline. For instance, you might want to set up an assay that runs every 12 hours, collects the previous 24 hours’ predictions and compares the distribution of predictions within that 24 hour window to the baseline. To set such a comparison up would look like this:
assay_builder.window_builder().add_width(hours=24).add_interval(hours=12)
In other words width is the width of the observation window, and interval is how often an assay (comparison) is run. The default value of width is 24 hours; the default value of interval is to set it equal to width. The units can be specified in one of: minutes, hours, days, weeks.
The Comparison Threshold
Given an observation window and a baseline distribution, an assay computes the distribution of predictions in the observation window. It then calculates the “difference” (or “distance”) between the observed distribution and the baseline distribution. For the assay’s default distance metric (which we will use here), a good starting threshold is 0.1. Since a different value may work best for a specific situation, you can try interactive assay runs on historical data to find a good threshold, as we do in these exercises.
To set the assay threshold for the assays to 0.1:
assay_builder.add_alert_threshold(0.1)
Running an Assay on Historical Data
In this exercise, you will build an interactive assay over historical data. To do this, you need an end time (endtime).
Depending on the historical history, the window and interval may need adjusting. If using the previously generated information, an interval window as short as 1 minute may be useful.
Assuming you have an assay builder with the appropriate window parameters and threshold set, you can do an interactive run and look at the results would look like this.
# set the end of the interactive run
assay_builder.add_run_until(endtime)
# set the window
assay_builder.window_builder().add_width(hours=24).add_interval(hours=12)
assay_results = assay_builder.build().interactive_run()
df = assay_results.to_dataframe() # to return the results as a table
assay_results.chart_scores() # to plot the run
Exercise: Create an interactive assay
Use the assay_builder you created in the previous exercise to set up an interactive assay.
- The assay should run every minute, on a window that is a minute wide.
- Set the alert threshold to 0.1.
- You can use
assay_window_end(or a later timestamp) as the end of the interactive run.
Examine the assay results. Do you see any drift?
To try other ways of examining the assay results, see the “Interactive Assay Runs” section of the Model Insights tutorial.
# blank space for setting assay parameters, creating and examining an interactive assay
# now set up our interactive assay based on the window set above.
assay_builder = assay_builder.add_run_until(assay_end)
# We don't have many records at the moment, so set the width to 1 minute so it'll slice each
# one minute interval into a window to analyze
assay_builder.window_builder().add_width(minutes=1).add_interval(minutes=1)
# Build the assay and then do an interactive run rather than waiting for the next interval
assay_config = assay_builder.build()
assay_results = assay_config.interactive_run()
# Show how many assay windows were analyzed, then show the chart
print(f"Generated {len(assay_results)} analyses")
assay_results.chart_scores()
Generated 9 analyses
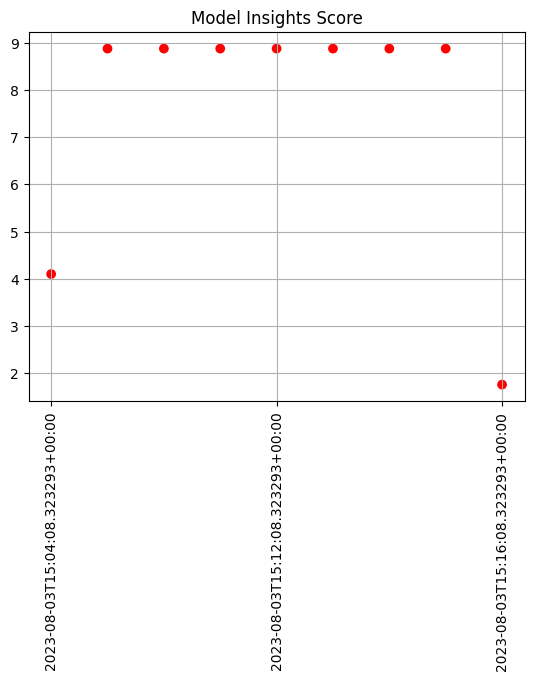
# Display the results as a DataFrame - we're mainly interested in the score and whether the
# alert threshold was triggered
display(assay_results.to_dataframe().loc[:, ["score", "start", "alert_threshold", "status"]])
| score | start | alert_threshold | status | |
|---|---|---|---|---|
| 0 | 4.103050 | 2023-08-03T15:04:08.323293+00:00 | 0.25 | Alert |
| 1 | 8.876929 | 2023-08-03T15:09:08.323293+00:00 | 0.25 | Alert |
| 2 | 8.876929 | 2023-08-03T15:10:08.323293+00:00 | 0.25 | Alert |
| 3 | 8.876929 | 2023-08-03T15:11:08.323293+00:00 | 0.25 | Alert |
| 4 | 8.876929 | 2023-08-03T15:12:08.323293+00:00 | 0.25 | Alert |
| 5 | 8.876929 | 2023-08-03T15:13:08.323293+00:00 | 0.25 | Alert |
| 6 | 8.876929 | 2023-08-03T15:14:08.323293+00:00 | 0.25 | Alert |
| 7 | 8.876929 | 2023-08-03T15:15:08.323293+00:00 | 0.25 | Alert |
| 8 | 1.761933 | 2023-08-03T15:16:08.323293+00:00 | 0.25 | Alert |
Scheduling an Assay to run on ongoing data
(We won’t be doing an exercise here, this is for future reference).
Once you are satisfied with the parameters you have set, you can schedule an assay to run regularly .
# create a fresh assay builder with the correct parameters
assay_builder = ( wl.build_assay(assay_name, pipeline, model_name,
baseline_start, baseline_end)
.add_iopath("output variable 0") )
# this assay runs every 24 hours on a 24 hour window
assay_builder.window_builder().add_width(hours=24)
assay_builder.add_alert_threshold(0.1)
# now schedule the assay
assay_id = assay_builder.upload()
You can use the assay id later to get the assay results.
You have now walked through setting up a basic assay and running it over historical data.
Congratulations!
In this tutorial you have
- Deployed a single step house price prediction pipeline and sent data to it.
- Compared two house price prediction models in an A/B test
- Compared two house price prediction models in a shadow deployment.
- Swapped the “winner” of the comparisons into the house price prediction pipeline.
- Set validation rules on the pipeline.
- Set up an assay on the pipeline to monitor for drift in its predictions.
Great job!
Cleaning up.
Now that the tutorial is complete, don’t forget to undeploy your pipeline to free up the resources.
# blank space to undeploy your pipeline
pipeline.undeploy()
| name | forecast-tutorial-pipeline |
|---|---|
| created | 2023-08-02 15:50:59.480547+00:00 |
| last_updated | 2023-08-03 15:01:17.534210+00:00 |
| deployed | False |
| tags | |
| versions | af0f9c1c-0c28-4aaa-81f5-abb470500960, 980ee03b-694e-47c7-b76b-43b3e927b281, 85af5504-f1e4-4d0d-bd9e-e46891211843, 39b82898-12b6-4a30-ab41-f06cb05c7391, d8edf8c5-07f0-455e-9f34-075b7062f56f, 170402aa-8e83-420e-bee3-51a9fca4a9d9, 14912dd4-5e3a-4314-9e3f-0ea3af3660c1, 3309619d-54b9-4499-8afd-ed7819339b64, 2af1f08c-976c-4d51-9cf6-2cc371788844, 76fbec8d-cebf-40e5-81d5-447170c4a836, c6c10a83-9b6c-449f-a5c3-63b36a3d749b, 436fe308-283f-43b0-a4f0-159c05193d97, eb9e5b9f-41d9-42dc-8e49-13ec4771abad, 4d062242-1477-40fd-bf11-835e6bd62c10, 1f3d774d-7626-4722-b4b8-7dedbaa35803, 12f73035-cf94-4e6c-b2b6-05946ab06aef, b4ec30ef-6724-467e-b42a-d54399198f32, 57e7acf8-b3f0-436b-a236-0b1d6e76ba18, 5697a317-d0e6-402b-9369-7f0e732cc1fa, 5d0cb620-f8ba-4b9d-a81b-0ba333584508, 6b14e208-1319-4bc4-927b-b76a4893d373, 0b44d911-c69e-4030-b481-84e947fe6c70, dc5605d2-bb6a-48d2-b83a-3d77b7e608af, a68819c0-7508-467e-9fc1-60cbf8aaf9e1, b908d302-ce87-4a52-8ef2-b595fac2c67e, 7b94201f-ef5b-4629-ae2f-acf894cb1fcf, dc8bf23f-b598-48c6-bb2d-c5098d264622, 3a8ebc46-6261-4977-8a60-038c99c255d7, 40ab9d3d-ee6c-4f0c-bf38-345385130285, 47792a90-bea8-432a-981f-232bf67288c8, 97b815f3-636b-4424-8be4-3d95bcf32b40, 0d2f2250-9a43-47ce-beef-32371986f798, 46c95b7f-a79e-41ee-8565-578f9c3c20e5, 1ff98a35-3468-4b70-84fc-fe71aed99a75, 73ff8fc2-ca4d-4ea1-887b-0d31190cfe36, f8188956-8b3e-4479-8b15-e8747fe915a6, 33e5cc2c-2bb2-4dc2-8a9e-c058e60f6163, 5d419693-97cc-461b-b72a-a389ab7a001b, 56c78f52-cba5-415c-913a-fee0e1863a90, a109a040-c8f2-46dc-8c0b-373ae10d4fa0, dcaec327-1358-42a7-88de-931602a42a72, debc509f-9481-464b-af7f-5c3138a9cdb4, b0d167aa-cc98-440a-8e85-1ae3f089745a, d9e69c40-c83b-48af-b6b9-caafcb85f08b, 186ffdd2-3a8f-40cc-8362-13cc20bd2f46, 535e6030-ebe5-4c79-b5cd-69b161637a99, c5c0218a-800b-4235-8767-64d18208e68a, 4559d934-33b0-4872-a788-4ef27f554482, 94d3e20b-add7-491c-aedd-4eb094a8aebf, ab4e58bf-3b75-4bf6-b6b3-f703fe61e7af, 3773f5c5-e4c5-4e46-a839-6945af15ca13, 3abf03dd-8eab-4a8d-8432-aa85a30c0eda, 5ec5e8dc-7492-498b-9652-b3733e4c87f7, 1d89287b-4eff-47ec-a7bb-8cedaac1f33f |
| steps | forecast-control-model |