Tutorials on uploading and registering ML models of different frameworks into Wallaroo.
Wallaroo ML Models Upload and Registrations
Tutorials on uploading ML Models of various frameworks into a Wallaroo instance.
- 1: Model Registry Service with Wallaroo Tutorials
- 2: Wallaroo SDK Upload Tutorials: Arbitrary Python
- 2.1: Wallaroo SDK Upload Arbitrary Python Tutorial: Generate VGG16 Model
- 2.2: Wallaroo SDK Upload Arbitrary Python Tutorial: Deploy VGG16 Model
- 3: Wallaroo SDK Upload Tutorials: Hugging Face
- 3.1: Wallaroo API Upload Tutorial: Hugging Face Zero Shot Classification
- 3.2: Wallaroo SDK Upload Tutorial: Hugging Face Zero Shot Classification
- 4: Wallaroo SDK Upload Tutorials: Python Step Shape
- 5: Wallaroo SDK Upload Tutorials: Pytorch
- 5.1: Wallaroo SDK Upload Tutorial: Pytorch Single IO
- 5.2: Wallaroo SDK Upload Tutorial: Pytorch Multiple IO
- 6: Wallaroo SDK Upload Tutorials: SKLearn
- 6.1: Wallaroo SDK Upload Tutorial: SKLearn Clustering Kmeans
- 6.2: Wallaroo SDK Upload Tutorial: SKLearn Clustering SVM
- 6.3: Wallaroo SDK Upload Tutorial: SKLearn Linear Regression
- 6.4: Wallaroo SDK Upload Tutorial: SKLearn Logistic Regression
- 6.5: Wallaroo SDK Upload Tutorial: SKLearn SVM PCA
- 7: Wallaroo SDK Upload Tutorials: Tensorflow
- 8: Wallaroo SDK Upload Tutorials: Tensorflow Keras
- 9: Wallaroo SDK Upload Tutorials: XGBoost
1 - Model Registry Service with Wallaroo Tutorials
How to use a Model Registry Service to upload models to a Wallaroo instance.
The following tutorials demonstrate how to add ML Models from a model registry service into a Wallaroo instance.
Artifact Requirements
Models are uploaded to the Wallaroo instance as the specific artifact - the “file” or other data that represents the file itself. This must comply with the Wallaroo model requirements framework and version or it will not be deployed. Note that for models that fall outside of the supported model types, they can be registered to a Wallaroo workspace as MLFlow 1.30.0 containerized models.
Supported Models
The following frameworks are supported. Frameworks fall under either Native or Containerized runtimes in the Wallaroo engine. For more details, see the specific framework what runtime a specific model framework runs in.
| Runtime Display | Model Runtime Space | Pipeline Configuration |
|---|---|---|
tensorflow | Native | Native Runtime Configuration Methods |
onnx | Native | Native Runtime Configuration Methods |
python | Native | Native Runtime Configuration Methods |
mlflow | Containerized | Containerized Runtime Deployment |
Please note the following.
IMPORTANT NOTICE: FRAMEWORK VERSIONS
The supported frameworks include the specific version of the model framework supported by Wallaroo. It is highly recommended to verify that models uploaded to Wallaroo meet the library and version requirements to ensure proper functioning.Wallaroo natively supports Open Neural Network Exchange (ONNX) models into the Wallaroo engine.
| Parameter | Description |
|---|---|
| Web Site | https://onnx.ai/ |
| Supported Libraries | See table below. |
| Framework | Framework.ONNX aka onnx |
| Runtime | Native aka onnx |
The following ONNX versions models are supported:
| Wallaroo Version | ONNX Version | ONNX IR Version | ONNX OPset Version | ONNX ML Opset Version |
|---|---|---|---|---|
| 2023.2.1 (July 2023) | 1.12.1 | 8 | 17 | 3 |
| 2023.2 (May 2023) | 1.12.1 | 8 | 17 | 3 |
| 2023.1 (March 2023) | 1.12.1 | 8 | 17 | 3 |
| 2022.4 (December 2022) | 1.12.1 | 8 | 17 | 3 |
| After April 2022 until release 2022.4 (December 2022) | 1.10.* | 7 | 15 | 2 |
| Before April 2022 | 1.6.* | 7 | 13 | 2 |
For the most recent release of Wallaroo 2023.2.1, the following native runtimes are supported:
- If converting another ML Model to ONNX (PyTorch, XGBoost, etc) using the onnxconverter-common library, the supported
DEFAULT_OPSET_NUMBERis 17.
Using different versions or settings outside of these specifications may result in inference issues and other unexpected behavior.
ONNX models always run in the native runtime space.
Data Schemas
ONNX models deployed to Wallaroo have the following data requirements.
- Equal rows constraint: The number of input rows and output rows must match.
- All inputs are tensors: The inputs are tensor arrays with the same shape.
- Data Type Consistency: Data types within each tensor are of the same type.
Equal Rows Constraint
Inference performed through ONNX models are assumed to be in batch format, where each input row corresponds to an output row. This is reflected in the in fields returned for an inference. In the following example, each input row for an inference is related directly to the inference output.
df = pd.read_json('./data/cc_data_1k.df.json')
display(df.head())
result = ccfraud_pipeline.infer(df.head())
display(result)
INPUT
| tensor | |
|---|---|
| 0 | [-1.0603297501, 2.3544967095000002, -3.5638788326, 5.1387348926, -1.2308457019, -0.7687824608, -3.5881228109, 1.8880837663, -3.2789674274, -3.9563254554, 4.0993439118, -5.6539176395, -0.8775733373, -9.131571192000001, -0.6093537873, -3.7480276773, -5.0309125017, -0.8748149526000001, 1.9870535692, 0.7005485718000001, 0.9204422758, -0.1041491809, 0.3229564351, -0.7418141657, 0.0384120159, 1.0993439146, 1.2603409756, -0.1466244739, -1.4463212439] |
| 1 | [-1.0603297501, 2.3544967095000002, -3.5638788326, 5.1387348926, -1.2308457019, -0.7687824608, -3.5881228109, 1.8880837663, -3.2789674274, -3.9563254554, 4.0993439118, -5.6539176395, -0.8775733373, -9.131571192000001, -0.6093537873, -3.7480276773, -5.0309125017, -0.8748149526000001, 1.9870535692, 0.7005485718000001, 0.9204422758, -0.1041491809, 0.3229564351, -0.7418141657, 0.0384120159, 1.0993439146, 1.2603409756, -0.1466244739, -1.4463212439] |
| 2 | [-1.0603297501, 2.3544967095000002, -3.5638788326, 5.1387348926, -1.2308457019, -0.7687824608, -3.5881228109, 1.8880837663, -3.2789674274, -3.9563254554, 4.0993439118, -5.6539176395, -0.8775733373, -9.131571192000001, -0.6093537873, -3.7480276773, -5.0309125017, -0.8748149526000001, 1.9870535692, 0.7005485718000001, 0.9204422758, -0.1041491809, 0.3229564351, -0.7418141657, 0.0384120159, 1.0993439146, 1.2603409756, -0.1466244739, -1.4463212439] |
| 3 | [-1.0603297501, 2.3544967095000002, -3.5638788326, 5.1387348926, -1.2308457019, -0.7687824608, -3.5881228109, 1.8880837663, -3.2789674274, -3.9563254554, 4.0993439118, -5.6539176395, -0.8775733373, -9.131571192000001, -0.6093537873, -3.7480276773, -5.0309125017, -0.8748149526000001, 1.9870535692, 0.7005485718000001, 0.9204422758, -0.1041491809, 0.3229564351, -0.7418141657, 0.0384120159, 1.0993439146, 1.2603409756, -0.1466244739, -1.4463212439] |
| 4 | [0.5817662108, 0.09788155100000001, 0.1546819424, 0.4754101949, -0.19788623060000002, -0.45043448540000003, 0.016654044700000002, -0.0256070551, 0.0920561602, -0.2783917153, 0.059329944100000004, -0.0196585416, -0.4225083157, -0.12175388770000001, 1.5473094894000001, 0.2391622864, 0.3553974881, -0.7685165301, -0.7000849355000001, -0.1190043285, -0.3450517133, -1.1065114108, 0.2523411195, 0.0209441826, 0.2199267436, 0.2540689265, -0.0450225094, 0.10867738980000001, 0.2547179311] |
OUTPUT
| time | in.tensor | out.dense_1 | check_failures | |
|---|---|---|---|---|
| 0 | 2023-11-17 20:34:17.005 | [-1.0603297501, 2.3544967095, -3.5638788326, 5.1387348926, -1.2308457019, -0.7687824608, -3.5881228109, 1.8880837663, -3.2789674274, -3.9563254554, 4.0993439118, -5.6539176395, -0.8775733373, -9.131571192, -0.6093537873, -3.7480276773, -5.0309125017, -0.8748149526, 1.9870535692, 0.7005485718, 0.9204422758, -0.1041491809, 0.3229564351, -0.7418141657, 0.0384120159, 1.0993439146, 1.2603409756, -0.1466244739, -1.4463212439] | [0.99300325] | 0 |
| 1 | 2023-11-17 20:34:17.005 | [-1.0603297501, 2.3544967095, -3.5638788326, 5.1387348926, -1.2308457019, -0.7687824608, -3.5881228109, 1.8880837663, -3.2789674274, -3.9563254554, 4.0993439118, -5.6539176395, -0.8775733373, -9.131571192, -0.6093537873, -3.7480276773, -5.0309125017, -0.8748149526, 1.9870535692, 0.7005485718, 0.9204422758, -0.1041491809, 0.3229564351, -0.7418141657, 0.0384120159, 1.0993439146, 1.2603409756, -0.1466244739, -1.4463212439] | [0.99300325] | 0 |
| 2 | 2023-11-17 20:34:17.005 | [-1.0603297501, 2.3544967095, -3.5638788326, 5.1387348926, -1.2308457019, -0.7687824608, -3.5881228109, 1.8880837663, -3.2789674274, -3.9563254554, 4.0993439118, -5.6539176395, -0.8775733373, -9.131571192, -0.6093537873, -3.7480276773, -5.0309125017, -0.8748149526, 1.9870535692, 0.7005485718, 0.9204422758, -0.1041491809, 0.3229564351, -0.7418141657, 0.0384120159, 1.0993439146, 1.2603409756, -0.1466244739, -1.4463212439] | [0.99300325] | 0 |
| 3 | 2023-11-17 20:34:17.005 | [-1.0603297501, 2.3544967095, -3.5638788326, 5.1387348926, -1.2308457019, -0.7687824608, -3.5881228109, 1.8880837663, -3.2789674274, -3.9563254554, 4.0993439118, -5.6539176395, -0.8775733373, -9.131571192, -0.6093537873, -3.7480276773, -5.0309125017, -0.8748149526, 1.9870535692, 0.7005485718, 0.9204422758, -0.1041491809, 0.3229564351, -0.7418141657, 0.0384120159, 1.0993439146, 1.2603409756, -0.1466244739, -1.4463212439] | [0.99300325] | 0 |
| 4 | 2023-11-17 20:34:17.005 | [0.5817662108, 0.097881551, 0.1546819424, 0.4754101949, -0.1978862306, -0.4504344854, 0.0166540447, -0.0256070551, 0.0920561602, -0.2783917153, 0.0593299441, -0.0196585416, -0.4225083157, -0.1217538877, 1.5473094894, 0.2391622864, 0.3553974881, -0.7685165301, -0.7000849355, -0.1190043285, -0.3450517133, -1.1065114108, 0.2523411195, 0.0209441826, 0.2199267436, 0.2540689265, -0.0450225094, 0.1086773898, 0.2547179311] | [0.0010916889] | 0 |
All Inputs Are Tensors
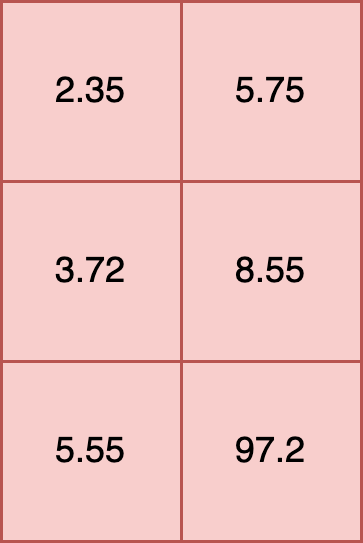
All inputs into an ONNX model must be tensors. This requires that the shape of each element is the same. For example, the following is a proper input:
t [
[2.35, 5.75],
[3.72, 8.55],
[5.55, 97.2]
]
Another example is a 2,2,3 tensor, where the shape of each element is (3,), and each element has 2 rows.
t = [
[2.35, 5.75, 19.2],
[3.72, 8.55, 10.5]
],
[
[5.55, 7.2, 15.7],
[9.6, 8.2, 2.3]
]
In this example each element has a shape of (2,). Tensors with elements of different shapes, known as ragged tensors, are not supported. For example:
t = [
[2.35, 5.75],
[3.72, 8.55, 10.5],
[5.55, 97.2]
])
**INVALID SHAPE**
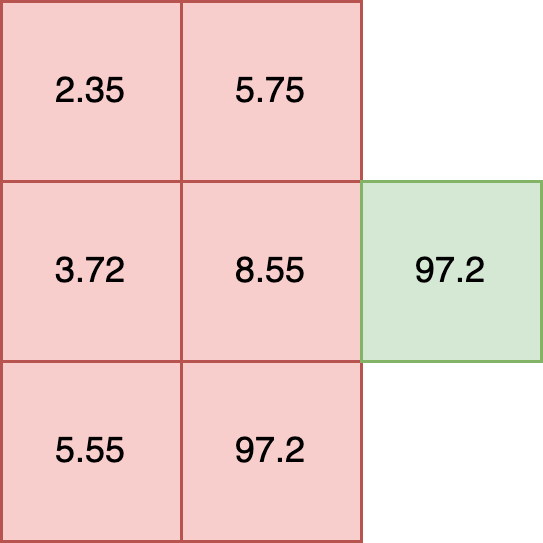
For models that require ragged tensor or other shapes, see other data formatting options such as Bring Your Own Predict models.
Data Type Consistency
All inputs into an ONNX model must have the same internal data type. For example, the following is valid because all of the data types within each element are float32.
t = [
[2.35, 5.75],
[3.72, 8.55],
[5.55, 97.2]
]
The following is invalid, as it mixes floats and strings in each element:
t = [
[2.35, "Bob"],
[3.72, "Nancy"],
[5.55, "Wani"]
]
The following inputs are valid, as each data type is consistent within the elements.
df = pd.DataFrame({
"t": [
[2.35, 5.75, 19.2],
[5.55, 7.2, 15.7],
],
"s": [
["Bob", "Nancy", "Wani"],
["Jason", "Rita", "Phoebe"]
]
})
df
| t | s | |
|---|---|---|
| 0 | [2.35, 5.75, 19.2] | [Bob, Nancy, Wani] |
| 1 | [5.55, 7.2, 15.7] | [Jason, Rita, Phoebe] |
| Parameter | Description |
|---|---|
| Web Site | https://www.tensorflow.org/ |
| Supported Libraries | tensorflow==2.9.1 |
| Framework | Framework.TENSORFLOW aka tensorflow |
| Runtime | Native aka tensorflow |
| Supported File Types | SavedModel format as .zip file |
IMPORTANT NOTE
These requirements are <strong>not</strong> for Tensorflow Keras models, only for non-Keras Tensorflow models in the SavedModel format. For Tensorflow Keras deployment in Wallaroo, see the Tensorflow Keras requirements.
TensorFlow File Format
TensorFlow models are .zip file of the SavedModel format. For example, the Aloha sample TensorFlow model is stored in the directory alohacnnlstm:
├── saved_model.pb
└── variables
├── variables.data-00000-of-00002
├── variables.data-00001-of-00002
└── variables.index
This is compressed into the .zip file alohacnnlstm.zip with the following command:
zip -r alohacnnlstm.zip alohacnnlstm/
ML models that meet the Tensorflow and SavedModel format will run as Wallaroo Native runtimes by default.
See the SavedModel guide for full details.
| Parameter | Description |
|---|---|
| Web Site | https://www.python.org/ |
| Supported Libraries | python==3.8 |
| Framework | Framework.PYTHON aka python |
| Runtime | Native aka python |
Python models uploaded to Wallaroo are executed as a native runtime.
Note that Python models - aka “Python steps” - are standalone python scripts that use the python libraries natively supported by the Wallaroo platform. These are used for either simple model deployment (such as ARIMA Statsmodels), or data formatting such as the postprocessing steps. A Wallaroo Python model will be composed of one Python script that matches the Wallaroo requirements.
This is contrasted with Arbitrary Python models, also known as Bring Your Own Predict (BYOP) allow for custom model deployments with supporting scripts and artifacts. These are used with pre-trained models (PyTorch, Tensorflow, etc) along with whatever supporting artifacts they require. Supporting artifacts can include other Python modules, model files, etc. These are zipped with all scripts, artifacts, and a requirements.txt file that indicates what other Python models need to be imported that are outside of the typical Wallaroo platform.
Python Models Requirements
Python models uploaded to Wallaroo are Python scripts that must include the wallaroo_json method as the entry point for the Wallaroo engine to use it as a Pipeline step.
This method receives the results of the previous Pipeline step, and its return value will be used in the next Pipeline step.
If the Python model is the first step in the pipeline, then it will be receiving the inference request data (for example: a preprocessing step). If it is the last step in the pipeline, then it will be the data returned from the inference request.
In the example below, the Python model is used as a post processing step for another ML model. The Python model expects to receive data from a ML Model who’s output is a DataFrame with the column dense_2. It then extracts the values of that column as a list, selects the first element, and returns a DataFrame with that element as the value of the column output.
def wallaroo_json(data: pd.DataFrame):
print(data)
return [{"output": [data["dense_2"].to_list()[0][0]]}]
In line with other Wallaroo inference results, the outputs of a Python step that returns a pandas DataFrame or Arrow Table will be listed in the out. metadata, with all inference outputs listed as out.{variable 1}, out.{variable 2}, etc. In the example above, this results the output field as the out.output field in the Wallaroo inference result.
| time | in.tensor | out.output | check_failures | |
|---|---|---|---|---|
| 0 | 2023-06-20 20:23:28.395 | [0.6878518042, 0.1760734021, -0.869514083, 0.3.. | [12.886651039123535] | 0 |
| Parameter | Description |
|---|---|
| Web Site | https://huggingface.co/models |
| Supported Libraries |
|
| Frameworks | The following Hugging Face pipelines are supported by Wallaroo.
|
| Runtime | Containerized aka tensorflow / mlflow |
Hugging Face Schemas
Input and output schemas for each Hugging Face pipeline are defined below. Note that adding additional inputs not specified below will raise errors, except for the following:
Framework.HUGGING-FACE-IMAGE-TO-TEXTFramework.HUGGING-FACE-TEXT-CLASSIFICATIONFramework.HUGGING-FACE-SUMMARIZATIONFramework.HUGGING-FACE-TRANSLATION
Additional inputs added to these Hugging Face pipelines will be added as key/pair value arguments to the model’s generate method. If the argument is not required, then the model will default to the values coded in the original Hugging Face model’s source code.
See the Hugging Face Pipeline documentation for more details on each pipeline and framework.
| Wallaroo Framework | Reference |
|---|---|
Framework.HUGGING-FACE-FEATURE-EXTRACTION |
Schemas:
input_schema = pa.schema([
pa.field('inputs', pa.string())
])
output_schema = pa.schema([
pa.field('output', pa.list_(
pa.list_(
pa.float64(),
list_size=128
),
))
])
| Wallaroo Framework | Reference |
|---|---|
Framework.HUGGING-FACE-IMAGE-CLASSIFICATION |
Schemas:
input_schema = pa.schema([
pa.field('inputs', pa.list_(
pa.list_(
pa.list_(
pa.int64(),
list_size=3
),
list_size=100
),
list_size=100
)),
pa.field('top_k', pa.int64()),
])
output_schema = pa.schema([
pa.field('score', pa.list_(pa.float64(), list_size=2)),
pa.field('label', pa.list_(pa.string(), list_size=2)),
])
| Wallaroo Framework | Reference |
|---|---|
Framework.HUGGING-FACE-IMAGE-SEGMENTATION |
Schemas:
input_schema = pa.schema([
pa.field('inputs',
pa.list_(
pa.list_(
pa.list_(
pa.int64(),
list_size=3
),
list_size=100
),
list_size=100
)),
pa.field('threshold', pa.float64()),
pa.field('mask_threshold', pa.float64()),
pa.field('overlap_mask_area_threshold', pa.float64()),
])
output_schema = pa.schema([
pa.field('score', pa.list_(pa.float64())),
pa.field('label', pa.list_(pa.string())),
pa.field('mask',
pa.list_(
pa.list_(
pa.list_(
pa.int64(),
list_size=100
),
list_size=100
),
)),
])
| Wallaroo Framework | Reference |
|---|---|
Framework.HUGGING-FACE-IMAGE-TO-TEXT |
Any parameter that is not part of the required inputs list will be forwarded to the model as a key/pair value to the underlying models generate method. If the additional input is not supported by the model, an error will be returned.
Schemas:
input_schema = pa.schema([
pa.field('inputs', pa.list_( #required
pa.list_(
pa.list_(
pa.int64(),
list_size=3
),
list_size=100
),
list_size=100
)),
# pa.field('max_new_tokens', pa.int64()), # optional
])
output_schema = pa.schema([
pa.field('generated_text', pa.list_(pa.string())),
])
| Wallaroo Framework | Reference |
|---|---|
Framework.HUGGING-FACE-OBJECT-DETECTION |
Schemas:
input_schema = pa.schema([
pa.field('inputs',
pa.list_(
pa.list_(
pa.list_(
pa.int64(),
list_size=3
),
list_size=100
),
list_size=100
)),
pa.field('threshold', pa.float64()),
])
output_schema = pa.schema([
pa.field('score', pa.list_(pa.float64())),
pa.field('label', pa.list_(pa.string())),
pa.field('box',
pa.list_( # dynamic output, i.e. dynamic number of boxes per input image, each sublist contains the 4 box coordinates
pa.list_(
pa.int64(),
list_size=4
),
),
),
])
| Wallaroo Framework | Reference |
|---|---|
Framework.HUGGING-FACE-QUESTION-ANSWERING |
Schemas:
input_schema = pa.schema([
pa.field('question', pa.string()),
pa.field('context', pa.string()),
pa.field('top_k', pa.int64()),
pa.field('doc_stride', pa.int64()),
pa.field('max_answer_len', pa.int64()),
pa.field('max_seq_len', pa.int64()),
pa.field('max_question_len', pa.int64()),
pa.field('handle_impossible_answer', pa.bool_()),
pa.field('align_to_words', pa.bool_()),
])
output_schema = pa.schema([
pa.field('score', pa.float64()),
pa.field('start', pa.int64()),
pa.field('end', pa.int64()),
pa.field('answer', pa.string()),
])
| Wallaroo Framework | Reference |
|---|---|
Framework.HUGGING-FACE-STABLE-DIFFUSION-TEXT-2-IMG |
Schemas:
input_schema = pa.schema([
pa.field('prompt', pa.string()),
pa.field('height', pa.int64()),
pa.field('width', pa.int64()),
pa.field('num_inference_steps', pa.int64()), # optional
pa.field('guidance_scale', pa.float64()), # optional
pa.field('negative_prompt', pa.string()), # optional
pa.field('num_images_per_prompt', pa.string()), # optional
pa.field('eta', pa.float64()) # optional
])
output_schema = pa.schema([
pa.field('images', pa.list_(
pa.list_(
pa.list_(
pa.int64(),
list_size=3
),
list_size=128
),
list_size=128
)),
])
| Wallaroo Framework | Reference |
|---|---|
Framework.HUGGING-FACE-SUMMARIZATION |
Any parameter that is not part of the required inputs list will be forwarded to the model as a key/pair value to the underlying models generate method. If the additional input is not supported by the model, an error will be returned.
Schemas:
input_schema = pa.schema([
pa.field('inputs', pa.string()),
pa.field('return_text', pa.bool_()),
pa.field('return_tensors', pa.bool_()),
pa.field('clean_up_tokenization_spaces', pa.bool_()),
# pa.field('extra_field', pa.int64()), # every extra field you specify will be forwarded as a key/value pair
])
output_schema = pa.schema([
pa.field('summary_text', pa.string()),
])
| Wallaroo Framework | Reference |
|---|---|
Framework.HUGGING-FACE-TEXT-CLASSIFICATION |
Schemas
input_schema = pa.schema([
pa.field('inputs', pa.string()), # required
pa.field('top_k', pa.int64()), # optional
pa.field('function_to_apply', pa.string()), # optional
])
output_schema = pa.schema([
pa.field('label', pa.list_(pa.string(), list_size=2)), # list with a number of items same as top_k, list_size can be skipped but may lead in worse performance
pa.field('score', pa.list_(pa.float64(), list_size=2)), # list with a number of items same as top_k, list_size can be skipped but may lead in worse performance
])
| Wallaroo Framework | Reference |
|---|---|
Framework.HUGGING-FACE-TRANSLATION |
Any parameter that is not part of the required inputs list will be forwarded to the model as a key/pair value to the underlying models generate method. If the additional input is not supported by the model, an error will be returned.
Schemas:
input_schema = pa.schema([
pa.field('inputs', pa.string()), # required
pa.field('return_tensors', pa.bool_()), # optional
pa.field('return_text', pa.bool_()), # optional
pa.field('clean_up_tokenization_spaces', pa.bool_()), # optional
pa.field('src_lang', pa.string()), # optional
pa.field('tgt_lang', pa.string()), # optional
# pa.field('extra_field', pa.int64()), # every extra field you specify will be forwarded as a key/value pair
])
output_schema = pa.schema([
pa.field('translation_text', pa.string()),
])
| Wallaroo Framework | Reference |
|---|---|
Framework.HUGGING-FACE-ZERO-SHOT-CLASSIFICATION |
Schemas:
input_schema = pa.schema([
pa.field('inputs', pa.string()), # required
pa.field('candidate_labels', pa.list_(pa.string(), list_size=2)), # required
pa.field('hypothesis_template', pa.string()), # optional
pa.field('multi_label', pa.bool_()), # optional
])
output_schema = pa.schema([
pa.field('sequence', pa.string()),
pa.field('scores', pa.list_(pa.float64(), list_size=2)), # same as number of candidate labels, list_size can be skipped by may result in slightly worse performance
pa.field('labels', pa.list_(pa.string(), list_size=2)), # same as number of candidate labels, list_size can be skipped by may result in slightly worse performance
])
| Wallaroo Framework | Reference |
|---|---|
Framework.HUGGING-FACE-ZERO-SHOT-IMAGE-CLASSIFICATION |
Schemas:
input_schema = pa.schema([
pa.field('inputs', # required
pa.list_(
pa.list_(
pa.list_(
pa.int64(),
list_size=3
),
list_size=100
),
list_size=100
)),
pa.field('candidate_labels', pa.list_(pa.string(), list_size=2)), # required
pa.field('hypothesis_template', pa.string()), # optional
])
output_schema = pa.schema([
pa.field('score', pa.list_(pa.float64(), list_size=2)), # same as number of candidate labels
pa.field('label', pa.list_(pa.string(), list_size=2)), # same as number of candidate labels
])
| Wallaroo Framework | Reference |
|---|---|
Framework.HUGGING-FACE-ZERO-SHOT-OBJECT-DETECTION |
Schemas:
input_schema = pa.schema([
pa.field('images',
pa.list_(
pa.list_(
pa.list_(
pa.int64(),
list_size=3
),
list_size=640
),
list_size=480
)),
pa.field('candidate_labels', pa.list_(pa.string(), list_size=3)),
pa.field('threshold', pa.float64()),
# pa.field('top_k', pa.int64()), # we want the model to return exactly the number of predictions, we shouldn't specify this
])
output_schema = pa.schema([
pa.field('score', pa.list_(pa.float64())), # variable output, depending on detected objects
pa.field('label', pa.list_(pa.string())), # variable output, depending on detected objects
pa.field('box',
pa.list_( # dynamic output, i.e. dynamic number of boxes per input image, each sublist contains the 4 box coordinates
pa.list_(
pa.int64(),
list_size=4
),
),
),
])
| Wallaroo Framework | Reference |
|---|---|
Framework.HUGGING-FACE-SENTIMENT-ANALYSIS | Hugging Face Sentiment Analysis |
| Wallaroo Framework | Reference |
|---|---|
Framework.HUGGING-FACE-TEXT-GENERATION |
Any parameter that is not part of the required inputs list will be forwarded to the model as a key/pair value to the underlying models generate method. If the additional input is not supported by the model, an error will be returned.
input_schema = pa.schema([
pa.field('inputs', pa.string()),
pa.field('return_tensors', pa.bool_()), # optional
pa.field('return_text', pa.bool_()), # optional
pa.field('return_full_text', pa.bool_()), # optional
pa.field('clean_up_tokenization_spaces', pa.bool_()), # optional
pa.field('prefix', pa.string()), # optional
pa.field('handle_long_generation', pa.string()), # optional
# pa.field('extra_field', pa.int64()), # every extra field you specify will be forwarded as a key/value pair
])
output_schema = pa.schema([
pa.field('generated_text', pa.list_(pa.string(), list_size=1))
])
| Parameter | Description |
|---|---|
| Web Site | https://pytorch.org/ |
| Supported Libraries |
|
| Framework | Framework.PYTORCH aka pytorch |
| Supported File Types | pt ot pth in TorchScript format |
| Runtime | Containerized aka mlflow |
Sci-kit Learn aka SKLearn.
| Parameter | Description |
|---|---|
| Web Site | https://scikit-learn.org/stable/index.html |
| Supported Libraries |
|
| Framework | Framework.SKLEARN aka sklearn |
| Runtime | Containerized aka tensorflow / mlflow |
SKLearn Schema Inputs
SKLearn schema follows a different format than other models. To prevent inputs from being out of order, the inputs should be submitted in a single row in the order the model is trained to accept, with all of the data types being the same. For example, the following DataFrame has 4 columns, each column a float.
| sepal length (cm) | sepal width (cm) | petal length (cm) | petal width (cm) | |
|---|---|---|---|---|
| 0 | 5.1 | 3.5 | 1.4 | 0.2 |
| 1 | 4.9 | 3.0 | 1.4 | 0.2 |
For submission to an SKLearn model, the data input schema will be a single array with 4 float values.
input_schema = pa.schema([
pa.field('inputs', pa.list_(pa.float64(), list_size=4))
])
When submitting as an inference, the DataFrame is converted to rows with the column data expressed as a single array. The data must be in the same order as the model expects, which is why the data is submitted as a single array rather than JSON labeled columns: this insures that the data is submitted in the exact order as the model is trained to accept.
Original DataFrame:
| sepal length (cm) | sepal width (cm) | petal length (cm) | petal width (cm) | |
|---|---|---|---|---|
| 0 | 5.1 | 3.5 | 1.4 | 0.2 |
| 1 | 4.9 | 3.0 | 1.4 | 0.2 |
Converted DataFrame:
| inputs | |
|---|---|
| 0 | [5.1, 3.5, 1.4, 0.2] |
| 1 | [4.9, 3.0, 1.4, 0.2] |
SKLearn Schema Outputs
Outputs for SKLearn that are meant to be predictions or probabilities when output by the model are labeled in the output schema for the model when uploaded to Wallaroo. For example, a model that outputs either 1 or 0 as its output would have the output schema as follows:
output_schema = pa.schema([
pa.field('predictions', pa.int32())
])
When used in Wallaroo, the inference result is contained in the out metadata as out.predictions.
pipeline.infer(dataframe)
| time | in.inputs | out.predictions | check_failures | |
|---|---|---|---|---|
| 0 | 2023-07-05 15:11:29.776 | [5.1, 3.5, 1.4, 0.2] | 0 | 0 |
| 1 | 2023-07-05 15:11:29.776 | [4.9, 3.0, 1.4, 0.2] | 0 | 0 |
| Parameter | Description |
|---|---|
| Web Site | https://www.tensorflow.org/api_docs/python/tf/keras/Model |
| Supported Libraries |
|
| Framework | Framework.KERAS aka keras |
| Supported File Types | SavedModel format as .zip file and HDF5 format |
| Runtime | Containerized aka mlflow |
TensorFlow Keras SavedModel Format
TensorFlow Keras SavedModel models are .zip file of the SavedModel format. For example, the Aloha sample TensorFlow model is stored in the directory alohacnnlstm:
├── saved_model.pb
└── variables
├── variables.data-00000-of-00002
├── variables.data-00001-of-00002
└── variables.index
This is compressed into the .zip file alohacnnlstm.zip with the following command:
zip -r alohacnnlstm.zip alohacnnlstm/
See the SavedModel guide for full details.
TensorFlow Keras H5 Format
Wallaroo supports the H5 for Tensorflow Keras models.
| Parameter | Description |
|---|---|
| Web Site | https://xgboost.ai/ |
| Supported Libraries | xgboost==1.7.4 |
| Framework | Framework.XGBOOST aka xgboost |
| Supported File Types | pickle (XGB files are not supported.) |
| Runtime | Containerized aka tensorflow / mlflow |
XGBoost Schema Inputs
XGBoost schema follows a different format than other models. To prevent inputs from being out of order, the inputs should be submitted in a single row in the order the model is trained to accept, with all of the data types being the same. If a model is originally trained to accept inputs of different data types, it will need to be retrained to only accept one data type for each column - typically pa.float64() is a good choice.
For example, the following DataFrame has 4 columns, each column a float.
| sepal length (cm) | sepal width (cm) | petal length (cm) | petal width (cm) | |
|---|---|---|---|---|
| 0 | 5.1 | 3.5 | 1.4 | 0.2 |
| 1 | 4.9 | 3.0 | 1.4 | 0.2 |
For submission to an XGBoost model, the data input schema will be a single array with 4 float values.
input_schema = pa.schema([
pa.field('inputs', pa.list_(pa.float64(), list_size=4))
])
When submitting as an inference, the DataFrame is converted to rows with the column data expressed as a single array. The data must be in the same order as the model expects, which is why the data is submitted as a single array rather than JSON labeled columns: this insures that the data is submitted in the exact order as the model is trained to accept.
Original DataFrame:
| sepal length (cm) | sepal width (cm) | petal length (cm) | petal width (cm) | |
|---|---|---|---|---|
| 0 | 5.1 | 3.5 | 1.4 | 0.2 |
| 1 | 4.9 | 3.0 | 1.4 | 0.2 |
Converted DataFrame:
| inputs | |
|---|---|
| 0 | [5.1, 3.5, 1.4, 0.2] |
| 1 | [4.9, 3.0, 1.4, 0.2] |
XGBoost Schema Outputs
Outputs for XGBoost are labeled based on the trained model outputs. For this example, the output is simply a single output listed as output. In the Wallaroo inference result, it is grouped with the metadata out as out.output.
output_schema = pa.schema([
pa.field('output', pa.int32())
])
pipeline.infer(dataframe)
| time | in.inputs | out.output | check_failures | |
|---|---|---|---|---|
| 0 | 2023-07-05 15:11:29.776 | [5.1, 3.5, 1.4, 0.2] | 0 | 0 |
| 1 | 2023-07-05 15:11:29.776 | [4.9, 3.0, 1.4, 0.2] | 0 | 0 |
| Parameter | Description |
|---|---|
| Web Site | https://www.python.org/ |
| Supported Libraries | python==3.8 |
| Framework | Framework.CUSTOM aka custom |
| Runtime | Containerized aka mlflow |
Arbitrary Python models, also known as Bring Your Own Predict (BYOP) allow for custom model deployments with supporting scripts and artifacts. These are used with pre-trained models (PyTorch, Tensorflow, etc) along with whatever supporting artifacts they require. Supporting artifacts can include other Python modules, model files, etc. These are zipped with all scripts, artifacts, and a requirements.txt file that indicates what other Python models need to be imported that are outside of the typical Wallaroo platform.
Contrast this with Wallaroo Python models - aka “Python steps”. These are standalone python scripts that use the python libraries natively supported by the Wallaroo platform. These are used for either simple model deployment (such as ARIMA Statsmodels), or data formatting such as the postprocessing steps. A Wallaroo Python model will be composed of one Python script that matches the Wallaroo requirements.
Arbitrary Python File Requirements
Arbitrary Python (BYOP) models are uploaded to Wallaroo via a ZIP file with the following components:
| Artifact | Type | Description |
|---|---|---|
Python scripts aka .py files with classes that extend mac.inference.Inference and mac.inference.creation.InferenceBuilder | Python Script | Extend the classes mac.inference.Inference and mac.inference.creation.InferenceBuilder. These are included with the Wallaroo SDK. Further details are in Arbitrary Python Script Requirements. Note that there is no specified naming requirements for the classes that extend mac.inference.Inference and mac.inference.creation.InferenceBuilder - any qualified class name is sufficient as long as these two classes are extended as defined below. |
requirements.txt | Python requirements file | This sets the Python libraries used for the arbitrary python model. These libraries should be targeted for Python 3.8 compliance. These requirements and the versions of libraries should be exactly the same between creating the model and deploying it in Wallaroo. This insures that the script and methods will function exactly the same as during the model creation process. |
| Other artifacts | Files | Other models, files, and other artifacts used in support of this model. |
For example, the if the arbitrary python model will be known as vgg_clustering, the contents may be in the following structure, with vgg_clustering as the storage directory:
vgg_clustering\
feature_extractor.h5
kmeans.pkl
custom_inference.py
requirements.txt
Note the inclusion of the custom_inference.py file. This file name is not required - any Python script or scripts that extend the classes listed above are sufficient. This Python script could have been named vgg_custom_model.py or any other name as long as it includes the extension of the classes listed above.
The sample arbitrary python model file is created with the command zip -r vgg_clustering.zip vgg_clustering/.
Wallaroo Arbitrary Python uses the Wallaroo SDK mac module, included in the Wallaroo SDK 2023.2.1 and above. See the Wallaroo SDK Install Guides for instructions on installing the Wallaroo SDK.
Arbitrary Python Script Requirements
The entry point of the arbitrary python model is any python script that extends the following classes. These are included with the Wallaroo SDK. The required methods that must be overridden are specified in each section below.
mac.inference.Inferenceinterface serves model inferences based on submitted input some input. Its purpose is to serve inferences for any supported arbitrary model framework (e.g.scikit,kerasetc.).classDiagram class Inference { <<Abstract>> +model Optional[Any] +expected_model_types()* Set +predict(input_data: InferenceData)* InferenceData -raise_error_if_model_is_not_assigned() None -raise_error_if_model_is_wrong_type() None }mac.inference.creation.InferenceBuilderbuilds a concreteInference, i.e. instantiates anInferenceobject, loads the appropriate model and assigns the model to to the Inference object.classDiagram class InferenceBuilder { +create(config InferenceConfig) * Inference -inference()* Any }
mac.inference.Inference
mac.inference.Inference Objects
| Object | Type | Description |
|---|---|---|
model Optional[Any] | An optional list of models that match the supported frameworks from wallaroo.framework.Framework included in the arbitrary python script. Note that this is optional - no models are actually required. A BYOP can refer to a specific model(s) used, be used for data processing and reshaping for later pipeline steps, or other needs. |
mac.inference.Inference Methods
| Method | Returns | Description |
|---|---|---|
expected_model_types (Required) | Set | Returns a Set of models expected for the inference as defined by the developer. Typically this is a set of one. Wallaroo checks the expected model types to verify that the model submitted through the InferenceBuilder method matches what this Inference class expects. |
_predict (input_data: mac.types.InferenceData) (Required) | mac.types.InferenceData | The entry point for the Wallaroo inference with the following input and output parameters that are defined when the model is updated.
InferenceDataValidationError exception is raised when the input data does not match mac.types.InferenceData. |
raise_error_if_model_is_not_assigned | N/A | Error when expected_model_types is not set. |
raise_error_if_model_is_wrong_type | N/A | Error when the model does not match the expected_model_types. |
mac.inference.creation.InferenceBuilder
InferenceBuilder builds a concrete Inference, i.e. instantiates an Inference object, loads the appropriate model and assigns the model to the Inference.
classDiagram
class InferenceBuilder {
+create(config InferenceConfig) * Inference
-inference()* Any
}Each model that is included requires its own InferenceBuilder. InferenceBuilder loads one model, then submits it to the Inference class when created. The Inference class checks this class against its expected_model_types() Set.
mac.inference.creation.InferenceBuilder Methods
| Method | Returns | Description |
|---|---|---|
create(config mac.config.inference.CustomInferenceConfig) (Required) | The custom Inference instance. | Creates an Inference subclass, then assigns a model and attributes. The CustomInferenceConfig is used to retrieve the config.model_path, which is a pathlib.Path object pointing to the folder where the model artifacts are saved. Every artifact loaded must be relative to config.model_path. This is set when the arbitrary python .zip file is uploaded and the environment for running it in Wallaroo is set. For example: loading the artifact vgg_clustering\feature_extractor.h5 would be set with config.model_path \ feature_extractor.h5. The model loaded must match an existing module. For our example, this is from sklearn.cluster import KMeans, and this must match the Inference expected_model_types. |
inference | custom Inference instance. | Returns the instantiated custom Inference object created from the create method. |
Arbitrary Python Runtime
Arbitrary Python always run in the containerized model runtime.
| Parameter | Description |
|---|---|
| Web Site | https://mlflow.org |
| Supported Libraries | mlflow==1.30.0 |
| Runtime | Containerized aka mlflow |
For models that do not fall under the supported model frameworks, organizations can use containerized MLFlow ML Models.
This guide details how to add ML Models from a model registry service into Wallaroo.
Wallaroo supports both public and private containerized model registries. See the Wallaroo Private Containerized Model Container Registry Guide for details on how to configure a Wallaroo instance with a private model registry.
Wallaroo users can register their trained MLFlow ML Models from a containerized model container registry into their Wallaroo instance and perform inferences with it through a Wallaroo pipeline.
As of this time, Wallaroo only supports MLFlow 1.30.0 containerized models. For information on how to containerize an MLFlow model, see the MLFlow Documentation.
Wallaroo supports both public and private containerized model registries. See the Wallaroo Private Containerized Model Container Registry Guide for details on how to configure a Wallaroo instance with a private model registry.
List Wallaroo Frameworks
Wallaroo frameworks are listed from the Wallaroo.Framework class. The following demonstrates listing all available supported frameworks.
from wallaroo.framework import Framework
[e.value for e in Framework]
['onnx',
'tensorflow',
'python',
'keras',
'sklearn',
'pytorch',
'xgboost',
'hugging-face-feature-extraction',
'hugging-face-image-classification',
'hugging-face-image-segmentation',
'hugging-face-image-to-text',
'hugging-face-object-detection',
'hugging-face-question-answering',
'hugging-face-stable-diffusion-text-2-img',
'hugging-face-summarization',
'hugging-face-text-classification',
'hugging-face-translation',
'hugging-face-zero-shot-classification',
'hugging-face-zero-shot-image-classification',
'hugging-face-zero-shot-object-detection',
'hugging-face-sentiment-analysis',
'hugging-face-text-generation']
1.1 - Model Registry Service with Wallaroo SDK Demonstration
How to use the Wallaroo SDK with Model Registry Services
This tutorial can be downloaded as part of the Wallaroo Tutorials repository.
MLFLow Registry Model Upload Demonstration
Wallaroo users can register their trained machine learning models from a model registry into their Wallaroo instance and perform inferences with it through a Wallaroo pipeline.
This guide details how to add ML Models from a model registry service into a Wallaroo instance.
Artifact Requirements
Models are uploaded to the Wallaroo instance as the specific artifact - the “file” or other data that represents the file itself. This must comply with the Wallaroo model requirements framework and version or it will not be deployed.
This tutorial will:
- Create a Wallaroo workspace and pipeline.
- Show how to connect a Wallaroo Registry that connects to a Model Registry Service.
- Use the registry connection details to upload a sample model to Wallaroo.
- Perform a sample inference.
Prerequisites
- A Wallaroo version 2023.2.1 or above instance.
- A Model (aka Artifact) Registry Service
References
Tutorial Steps
Import Libraries
We’ll start with importing the libraries we need for the tutorial.
import os
import wallaroo
Connect to the Wallaroo Instance through the User Interface
The next step is to connect to Wallaroo through the Wallaroo client. The Python library is included in the Wallaroo install and available through the Jupyter Hub interface provided with your Wallaroo environment.
This is accomplished using the wallaroo.Client() command, which provides a URL to grant the SDK permission to your specific Wallaroo environment. When displayed, enter the URL into a browser and confirm permissions. Store the connection into a variable that can be referenced later.
If logging into the Wallaroo instance through the internal JupyterHub service, use wl = wallaroo.Client(). For more information on Wallaroo Client settings, see the Client Connection guide.
wl=wallaroo.Client()
wl = wallaroo.Client()
wallarooPrefix = "doc-test."
wallarooSuffix = "wallarooexample.ai"
wl = wallaroo.Client(api_endpoint=f"https://{wallarooPrefix}api.{wallarooSuffix}",
auth_endpoint=f"https://{wallarooPrefix}keycloak.{wallarooSuffix}",
auth_type="sso")
Please log into the following URL in a web browser:
https://doc-test.keycloak.wallarooexample.ai/auth/realms/master/device?user_code=YOSQ-MZCY
Login successful!
Connect to Model Registry
The Wallaroo Registry stores the URL and authentication token to the Model Registry service, with the assigned name. Note that in this demonstration all URLs and token are examples.
registry = wl.create_model_registry(name="JeffRegistry45",
token="dapi67c8c0b04606f730e78b7ae5e3221015-3",
url="https://sample.registry.service.azuredatabricks.net")
registry
| Field | Value |
|---|---|
| Name | JeffRegistry45 |
| URL | https://sample.registry.service.azuredatabricks.net |
| Workspaces | john.hummel@wallaroo.ai - Default Workspace |
| Created At | 2023-17-Jul 19:54:49 |
| Updated At | 2023-17-Jul 19:54:49 |
List Model Registries
Registries associated with a workspace are listed with the Wallaroo.Client.list_model_registries() method.
# List all registries in this workspace
registries = wl.list_model_registries()
registries
| name | registry url | created at | updated at |
|---|---|---|---|
| JeffRegistry45 | https://sample.registry.service.azuredatabricks.net | 2023-17-Jul 17:56:52 | 2023-17-Jul 17:56:52 |
| JeffRegistry45 | https://sample.registry.service.azuredatabricks.net | 2023-17-Jul 19:54:49 | 2023-17-Jul 19:54:49 |
Create Workspace
For this demonstration, we will create a random Wallaroo workspace, then attach our registry to the workspace so it is accessible by other workspace users.
Add Registry to Workspace
Registries are assigned to a Wallaroo workspace with the Wallaroo.registry.add_registry_to_workspace method. This allows members of the workspace to access the registry connection. A registry can be associated with one or more workspaces.
Add Registry to Workspace Parameters
| Parameter | Type | Description |
|---|---|---|
name | string (Required) | The numerical identifier of the workspace. |
# Make a random new workspace
import math
import random
num = math.floor(random.random()* 1000)
workspace_id = wl.create_workspace(f"test{num}").id()
registry.add_registry_to_workspace(workspace_id=workspace_id)
| Field | Value |
|---|---|
| Name | JeffRegistry45 |
| URL | https://sample.registry.service.azuredatabricks.net |
| Workspaces | test68, john.hummel@wallaroo.ai - Default Workspace |
| Created At | 2023-17-Jul 19:54:49 |
| Updated At | 2023-17-Jul 19:54:49 |
Remove Registry from Workspace
Registries are removed from a Wallaroo workspace with the Registry remove_registry_from_workspace method.
Remove Registry from Workspace Parameters
| Parameter | Type | Description |
|---|---|---|
workspace_id | Integer (Required) | The numerical identifier of the workspace. |
registry.remove_registry_from_workspace(workspace_id=workspace_id)
| Field | Value |
|---|---|
| Name | JeffRegistry45 |
| URL | https://sample.registry.service.azuredatabricks.net |
| Workspaces | john.hummel@wallaroo.ai - Default Workspace |
| Created At | 2023-17-Jul 19:54:49 |
| Updated At | 2023-17-Jul 19:54:49 |
List Models in a Registry
A List of models available to the Wallaroo instance through the MLFlow Registry is performed with the Wallaroo.Registry.list_models() method.
registry_models = registry.list_models()
registry_models
| Name | Registry User | Versions | Created At | Updated At |
Select Model from Registry
Registry models are selected from the Wallaroo.Registry.list_models() method, then specifying the model to use.
single_registry_model = registry_models[4]
single_registry_model
| Name | verified-working |
| Registry User | gib.bhojraj@wallaroo.ai |
| Versions | 1 |
| Created At | 2023-11-Jul 16:18:03 |
| Updated At | 2023-11-Jul 16:57:54 |
List Model Versions
The Registry Model attribute versions shows the complete list of versions for the particular model.
single_registry_model.versions()
| Name | Version | Description |
| verified-working | 3 | None |
List Model Version Artifacts
Artifacts belonging to a MLFlow registry model are listed with the Model Version list_artifacts() method. This returns all artifacts for the model.
single_registry_model.versions()[1].list_artifacts()
| File Name | File Size | Full Path |
|---|---|---|
| MLmodel | 559B | https://sample.registry.service.azuredatabricks.net/api/2.0/dbfs/read?path=/databricks/mlflow-registry/9168792a16cb40a88de6959ef31e42a2/models/√erified-working/MLmodel |
| conda.yaml | 182B | https://sample.registry.service.azuredatabricks.net/api/2.0/dbfs/read?path=/databricks/mlflow-registry/9168792a16cb40a88de6959ef31e42a2/models/√erified-working/conda.yaml |
| model.pkl | 829B | https://sample.registry.service.azuredatabricks.net/api/2.0/dbfs/read?path=/databricks/mlflow-registry/9168792a16cb40a88de6959ef31e42a2/models/√erified-working/model.pkl |
| python_env.yaml | 122B | https://sample.registry.service.azuredatabricks.net/api/2.0/dbfs/read?path=/databricks/mlflow-registry/9168792a16cb40a88de6959ef31e42a2/models/√erified-working/python_env.yaml |
| requirements.txt | 73B | https://sample.registry.service.azuredatabricks.net/api/2.0/dbfs/read?path=/databricks/mlflow-registry/9168792a16cb40a88de6959ef31e42a2/models/√erified-working/requirements.txt |
Configure Data Schemas
To upload a ML Model to Wallaroo, the input and output schemas must be defined in pyarrow.lib.Schema format.
from wallaroo.framework import Framework
import pyarrow as pa
input_schema = pa.schema([
pa.field('inputs', pa.list_(pa.float64(), list_size=4))
])
output_schema = pa.schema([
pa.field('predictions', pa.int32()),
pa.field('probabilities', pa.list_(pa.float64(), list_size=3))
])
Upload a Model from a Registry
Models uploaded to the Wallaroo workspace are uploaded from a MLFlow Registry with the Wallaroo.Registry.upload method.
Upload a Model from a Registry Parameters
| Parameter | Type | Description |
|---|---|---|
name | string (Required) | The name to assign the model once uploaded. Model names are unique within a workspace. Models assigned the same name as an existing model will be uploaded as a new model version. |
path | string (Required) | The full path to the model artifact in the registry. |
framework | string (Required) | The Wallaroo model Framework. See Model Uploads and Registrations Supported Frameworks |
input_schema | pyarrow.lib.Schema (Required for non-native runtimes) | The input schema in Apache Arrow schema format. |
output_schema | pyarrow.lib.Schema (Required for non-native runtimes) | The output schema in Apache Arrow schema format. |
model = registry.upload_model(
name="verified-working",
path="https://sample.registry.service.azuredatabricks.net/api/2.0/dbfs/read?path=/databricks/mlflow-registry/9168792a16cb40a88de6959ef31e42a2/models/√erified-working/model.pkl",
framework=Framework.SKLEARN,
input_schema=input_schema,
output_schema=output_schema)
model
| Name | verified-working |
| Version | cf194b65-65b2-4d42-a4e2-6ca6fa5bfc42 |
| File Name | model.pkl |
| SHA | 5f4c25b0b564ab9fe0ea437424323501a460aa74463e81645a6419be67933ca4 |
| Status | pending_conversion |
| Image Path | None |
| Updated At | 2023-17-Jul 17:57:23 |
Verify the Model Status
Once uploaded, the model will undergo conversion. The following will loop through the model status until it is ready. Once ready, it is available for deployment.
import time
while model.status() != "ready" and model.status() != "error":
print(model.status())
time.sleep(3)
print(model.status())
pending_conversion
pending_conversion
pending_conversion
pending_conversion
pending_conversion
pending_conversion
pending_conversion
pending_conversion
pending_conversion
pending_conversion
converting
converting
converting
converting
converting
converting
converting
converting
converting
converting
converting
converting
converting
converting
converting
ready
Model Runtime
Once uploaded and converted, the model runtime is derived. This determines whether to allocate resources to pipeline’s native runtime environment or containerized runtime environment. For more details, see the Wallaroo SDK Essentials Guide: Pipeline Deployment Configuration guide.
model.config().runtime()
'mlflow'
Deploy Pipeline
The model is uploaded and ready for use. We’ll add it as a step in our pipeline, then deploy the pipeline. For this example we’re allocated 0.5 cpu to the runtime environment and 1 CPU to the containerized runtime environment.
import os, json
from wallaroo.deployment_config import DeploymentConfigBuilder
deployment_config = DeploymentConfigBuilder().cpus(0.5).sidekick_cpus(model, 1).build()
pipeline = wl.build_pipeline("jefftest1")
pipeline = pipeline.add_model_step(model)
deployment = pipeline.deploy(deployment_config=deployment_config)
pipeline.status()
{'status': 'Running',
'details': [],
'engines': [{'ip': '10.244.3.148',
'name': 'engine-86c7fc5c95-8kwh5',
'status': 'Running',
'reason': None,
'details': [],
'pipeline_statuses': {'pipelines': [{'id': 'jefftest1',
'status': 'Running'}]},
'model_statuses': {'models': [{'name': 'verified-working',
'version': 'cf194b65-65b2-4d42-a4e2-6ca6fa5bfc42',
'sha': '5f4c25b0b564ab9fe0ea437424323501a460aa74463e81645a6419be67933ca4',
'status': 'Running'}]}}],
'engine_lbs': [{'ip': '10.244.4.203',
'name': 'engine-lb-584f54c899-tpv5b',
'status': 'Running',
'reason': None,
'details': []}],
'sidekicks': [{'ip': '10.244.0.225',
'name': 'engine-sidekick-verified-working-43-74f957566d-9zdfh',
'status': 'Running',
'reason': None,
'details': [],
'statuses': '\n'}]}
Run Inference
A sample inference will be run. First the pandas DataFrame used for the inference is created, then the inference run through the pipeline’s infer method.
import pandas as pd
from sklearn.datasets import load_iris
data = load_iris(as_frame=True)
X = data['data'].values
dataframe = pd.DataFrame({"inputs": data['data'][:2].values.tolist()})
dataframe
| inputs | |
|---|---|
| 0 | [5.1, 3.5, 1.4, 0.2] |
| 1 | [4.9, 3.0, 1.4, 0.2] |
deployment.infer(dataframe)
| time | in.inputs | out.predictions | out.probabilities | check_failures | |
|---|---|---|---|---|---|
| 0 | 2023-07-17 17:59:18.840 | [5.1, 3.5, 1.4, 0.2] | 0 | [0.981814913291491, 0.018185072312411506, 1.43... | 0 |
| 1 | 2023-07-17 17:59:18.840 | [4.9, 3.0, 1.4, 0.2] | 0 | [0.9717552971628304, 0.02824467272952288, 3.01... | 0 |
Undeploy Pipelines
With the tutorial complete, the pipeline is undeployed to return the resources back to the cluster.
pipeline.undeploy()
| name | jefftest1 |
|---|---|
| created | 2023-07-17 17:59:05.922172+00:00 |
| last_updated | 2023-07-17 17:59:06.684060+00:00 |
| deployed | False |
| tags | |
| versions | c2cca319-fcad-47b2-9de0-ad5b2852d1a2, f1e6d1b5-96ee-46a1-bfdf-174310ff4270 |
| steps | verified-working |
2 - Wallaroo SDK Upload Tutorials: Arbitrary Python
How to upload different Arbitrary Python models to Wallaroo.
The following tutorials cover how to upload sample arbitrary python models into a Wallaroo instance.
| Parameter | Description |
|---|---|
| Web Site | https://www.python.org/ |
| Supported Libraries | python==3.8 |
| Framework | Framework.CUSTOM aka custom |
| Runtime | Containerized aka mlflow |
Arbitrary Python models, also known as Bring Your Own Predict (BYOP) allow for custom model deployments with supporting scripts and artifacts. These are used with pre-trained models (PyTorch, Tensorflow, etc) along with whatever supporting artifacts they require. Supporting artifacts can include other Python modules, model files, etc. These are zipped with all scripts, artifacts, and a requirements.txt file that indicates what other Python models need to be imported that are outside of the typical Wallaroo platform.
Contrast this with Wallaroo Python models - aka “Python steps”. These are standalone python scripts that use the python libraries natively supported by the Wallaroo platform. These are used for either simple model deployment (such as ARIMA Statsmodels), or data formatting such as the postprocessing steps. A Wallaroo Python model will be composed of one Python script that matches the Wallaroo requirements.
Arbitrary Python File Requirements
Arbitrary Python (BYOP) models are uploaded to Wallaroo via a ZIP file with the following components:
| Artifact | Type | Description |
|---|---|---|
Python scripts aka .py files with classes that extend mac.inference.Inference and mac.inference.creation.InferenceBuilder | Python Script | Extend the classes mac.inference.Inference and mac.inference.creation.InferenceBuilder. These are included with the Wallaroo SDK. Further details are in Arbitrary Python Script Requirements. Note that there is no specified naming requirements for the classes that extend mac.inference.Inference and mac.inference.creation.InferenceBuilder - any qualified class name is sufficient as long as these two classes are extended as defined below. |
requirements.txt | Python requirements file | This sets the Python libraries used for the arbitrary python model. These libraries should be targeted for Python 3.8 compliance. These requirements and the versions of libraries should be exactly the same between creating the model and deploying it in Wallaroo. This insures that the script and methods will function exactly the same as during the model creation process. |
| Other artifacts | Files | Other models, files, and other artifacts used in support of this model. |
For example, the if the arbitrary python model will be known as vgg_clustering, the contents may be in the following structure, with vgg_clustering as the storage directory:
vgg_clustering\
feature_extractor.h5
kmeans.pkl
custom_inference.py
requirements.txt
Note the inclusion of the custom_inference.py file. This file name is not required - any Python script or scripts that extend the classes listed above are sufficient. This Python script could have been named vgg_custom_model.py or any other name as long as it includes the extension of the classes listed above.
The sample arbitrary python model file is created with the command zip -r vgg_clustering.zip vgg_clustering/.
Wallaroo Arbitrary Python uses the Wallaroo SDK mac module, included in the Wallaroo SDK 2023.2.1 and above. See the Wallaroo SDK Install Guides for instructions on installing the Wallaroo SDK.
Arbitrary Python Script Requirements
The entry point of the arbitrary python model is any python script that extends the following classes. These are included with the Wallaroo SDK. The required methods that must be overridden are specified in each section below.
mac.inference.Inferenceinterface serves model inferences based on submitted input some input. Its purpose is to serve inferences for any supported arbitrary model framework (e.g.scikit,kerasetc.).classDiagram class Inference { <<Abstract>> +model Optional[Any] +expected_model_types()* Set +predict(input_data: InferenceData)* InferenceData -raise_error_if_model_is_not_assigned() None -raise_error_if_model_is_wrong_type() None }mac.inference.creation.InferenceBuilderbuilds a concreteInference, i.e. instantiates anInferenceobject, loads the appropriate model and assigns the model to to the Inference object.classDiagram class InferenceBuilder { +create(config InferenceConfig) * Inference -inference()* Any }
mac.inference.Inference
mac.inference.Inference Objects
| Object | Type | Description |
|---|---|---|
model Optional[Any] | An optional list of models that match the supported frameworks from wallaroo.framework.Framework included in the arbitrary python script. Note that this is optional - no models are actually required. A BYOP can refer to a specific model(s) used, be used for data processing and reshaping for later pipeline steps, or other needs. |
mac.inference.Inference Methods
| Method | Returns | Description |
|---|---|---|
expected_model_types (Required) | Set | Returns a Set of models expected for the inference as defined by the developer. Typically this is a set of one. Wallaroo checks the expected model types to verify that the model submitted through the InferenceBuilder method matches what this Inference class expects. |
_predict (input_data: mac.types.InferenceData) (Required) | mac.types.InferenceData | The entry point for the Wallaroo inference with the following input and output parameters that are defined when the model is updated.
InferenceDataValidationError exception is raised when the input data does not match mac.types.InferenceData. |
raise_error_if_model_is_not_assigned | N/A | Error when expected_model_types is not set. |
raise_error_if_model_is_wrong_type | N/A | Error when the model does not match the expected_model_types. |
mac.inference.creation.InferenceBuilder
InferenceBuilder builds a concrete Inference, i.e. instantiates an Inference object, loads the appropriate model and assigns the model to the Inference.
classDiagram
class InferenceBuilder {
+create(config InferenceConfig) * Inference
-inference()* Any
}Each model that is included requires its own InferenceBuilder. InferenceBuilder loads one model, then submits it to the Inference class when created. The Inference class checks this class against its expected_model_types() Set.
mac.inference.creation.InferenceBuilder Methods
| Method | Returns | Description |
|---|---|---|
create(config mac.config.inference.CustomInferenceConfig) (Required) | The custom Inference instance. | Creates an Inference subclass, then assigns a model and attributes. The CustomInferenceConfig is used to retrieve the config.model_path, which is a pathlib.Path object pointing to the folder where the model artifacts are saved. Every artifact loaded must be relative to config.model_path. This is set when the arbitrary python .zip file is uploaded and the environment for running it in Wallaroo is set. For example: loading the artifact vgg_clustering\feature_extractor.h5 would be set with config.model_path \ feature_extractor.h5. The model loaded must match an existing module. For our example, this is from sklearn.cluster import KMeans, and this must match the Inference expected_model_types. |
inference | custom Inference instance. | Returns the instantiated custom Inference object created from the create method. |
Arbitrary Python Runtime
Arbitrary Python always run in the containerized model runtime.
2.1 - Wallaroo SDK Upload Arbitrary Python Tutorial: Generate VGG16 Model
How to generate a VGG166 model for arbitrary python model deployment in Wallaroo.
This tutorial can be downloaded as part of the Wallaroo Tutorials repository.
Wallaroo SDK Upload Arbitrary Python Tutorial: Generate Model
This tutorial demonstrates how to use arbitrary python as a ML Model in Wallaroo. Arbitrary Python allows organizations to use Python scripts that require specific libraries and artifacts as models in the Wallaroo engine. This allows for highly flexible use of ML models with supporting scripts.
Tutorial Goals
This tutorial is split into two parts:
- Wallaroo SDK Upload Arbitrary Python Tutorial: Generate Model: Train a dummy
KMeansmodel for clustering images using a pre-trainedVGG16model oncifar10as a feature extractor. The Python entry points used for Wallaroo deployment will be added and described.- A copy of the arbitrary Python model
models/model-auto-conversion-BYOP-vgg16-clustering.zipis included in this tutorial, so this step can be skipped.
- A copy of the arbitrary Python model
- Arbitrary Python Tutorial Deploy Model in Wallaroo Upload and Deploy: Deploys the
KMeansmodel in an arbitrary Python package in Wallaroo, and perform sample inferences. The filemodels/model-auto-conversion-BYOP-vgg16-clustering.zipis provided so users can go right to testing deployment.
Arbitrary Python models, also known as Bring Your Own Predict (BYOP) allow for custom model deployments with supporting scripts and artifacts. These are used with pre-trained models (PyTorch, Tensorflow, etc) along with whatever supporting artifacts they require. Supporting artifacts can include other Python modules, model files, etc. These are zipped with all scripts, artifacts, and a requirements.txt file that indicates what other Python models need to be imported that are outside of the typical Wallaroo platform.
Contrast this with Wallaroo Python models - aka “Python steps”. These are standalone python scripts that use the python libraries natively supported by the Wallaroo platform. These are used for either simple model deployment (such as ARIMA Statsmodels), or data formatting such as the postprocessing steps. A Wallaroo Python model will be composed of one Python script that matches the Wallaroo requirements.
Arbitrary Python File Requirements
Arbitrary Python (BYOP) models are uploaded to Wallaroo via a ZIP file with the following components:
| Artifact | Type | Description |
|---|---|---|
Python scripts aka .py files with classes that extend mac.inference.Inference and mac.inference.creation.InferenceBuilder | Python Script | Extend the classes mac.inference.Inference and mac.inference.creation.InferenceBuilder. These are included with the Wallaroo SDK. Further details are in Arbitrary Python Script Requirements. Note that there is no specified naming requirements for the classes that extend mac.inference.Inference and mac.inference.creation.InferenceBuilder - any qualified class name is sufficient as long as these two classes are extended as defined below. |
requirements.txt | Python requirements file | This sets the Python libraries used for the arbitrary python model. These libraries should be targeted for Python 3.8 compliance. These requirements and the versions of libraries should be exactly the same between creating the model and deploying it in Wallaroo. This insures that the script and methods will function exactly the same as during the model creation process. |
| Other artifacts | Files | Other models, files, and other artifacts used in support of this model. |
For example, the if the arbitrary python model will be known as vgg_clustering, the contents may be in the following structure, with vgg_clustering as the storage directory:
vgg_clustering\
feature_extractor.h5
kmeans.pkl
custom_inference.py
requirements.txt
Note the inclusion of the custom_inference.py file. This file name is not required - any Python script or scripts that extend the classes listed above are sufficient. This Python script could have been named vgg_custom_model.py or any other name as long as it includes the extension of the classes listed above.
The sample arbitrary python model file is created with the command zip -r vgg_clustering.zip vgg_clustering/.
Wallaroo Arbitrary Python uses the Wallaroo SDK mac module, included in the Wallaroo SDK 2023.2.1 and above. See the Wallaroo SDK Install Guides for instructions on installing the Wallaroo SDK.
Arbitrary Python Script Requirements
The entry point of the arbitrary python model is any python script that extends the following classes. These are included with the Wallaroo SDK. The required methods that must be overridden are specified in each section below.
mac.inference.Inferenceinterface serves model inferences based on submitted input some input. Its purpose is to serve inferences for any supported arbitrary model framework (e.g.scikit,kerasetc.).classDiagram class Inference { <<Abstract>> +model Optional[Any] +expected_model_types()* Set +predict(input_data: InferenceData)* InferenceData -raise_error_if_model_is_not_assigned() None -raise_error_if_model_is_wrong_type() None }mac.inference.creation.InferenceBuilderbuilds a concreteInference, i.e. instantiates anInferenceobject, loads the appropriate model and assigns the model to to the Inference object.classDiagram class InferenceBuilder { +create(config InferenceConfig) * Inference -inference()* Any }
mac.inference.Inference
mac.inference.Inference Objects
| Object | Type | Description |
|---|---|---|
model Optional[Any] | An optional list of models that match the supported frameworks from wallaroo.framework.Framework included in the arbitrary python script. Note that this is optional - no models are actually required. A BYOP can refer to a specific model(s) used, be used for data processing and reshaping for later pipeline steps, or other needs. |
mac.inference.Inference Methods
| Method | Returns | Description |
|---|---|---|
expected_model_types (Required) | Set | Returns a Set of models expected for the inference as defined by the developer. Typically this is a set of one. Wallaroo checks the expected model types to verify that the model submitted through the InferenceBuilder method matches what this Inference class expects. |
_predict (input_data: mac.types.InferenceData) (Required) | mac.types.InferenceData | The entry point for the Wallaroo inference with the following input and output parameters that are defined when the model is updated.
InferenceDataValidationError exception is raised when the input data does not match mac.types.InferenceData. |
raise_error_if_model_is_not_assigned | N/A | Error when expected_model_types is not set. |
raise_error_if_model_is_wrong_type | N/A | Error when the model does not match the expected_model_types. |
mac.inference.creation.InferenceBuilder
InferenceBuilder builds a concrete Inference, i.e. instantiates an Inference object, loads the appropriate model and assigns the model to the Inference.
classDiagram
class InferenceBuilder {
+create(config InferenceConfig) * Inference
-inference()* Any
}Each model that is included requires its own InferenceBuilder. InferenceBuilder loads one model, then submits it to the Inference class when created. The Inference class checks this class against its expected_model_types() Set.
mac.inference.creation.InferenceBuilder Methods
| Method | Returns | Description |
|---|---|---|
create(config mac.config.inference.CustomInferenceConfig) (Required) | The custom Inference instance. | Creates an Inference subclass, then assigns a model and attributes. The CustomInferenceConfig is used to retrieve the config.model_path, which is a pathlib.Path object pointing to the folder where the model artifacts are saved. Every artifact loaded must be relative to config.model_path. This is set when the arbitrary python .zip file is uploaded and the environment for running it in Wallaroo is set. For example: loading the artifact vgg_clustering\feature_extractor.h5 would be set with config.model_path \ feature_extractor.h5. The model loaded must match an existing module. For our example, this is from sklearn.cluster import KMeans, and this must match the Inference expected_model_types. |
inference | custom Inference instance. | Returns the instantiated custom Inference object created from the create method. |
VGG16 Model Training Steps
This process will train a dummy KMeans model for clustering images using a pre-trained VGG16 model on cifar10 as a feature extractor. This model consists of the following elements:
- All elements are stored in the folder
models/vgg16_clustering. This will be converted to the zip filemodel-auto-conversion-BYOP-vgg16-clustering.zip. models/vgg16_clusteringwill contain the following:- All necessary model artifacts
- One or multiple Python files implementing the classes
InferenceandInferenceBuilder. The implemented classes can have any naming they desire as long as they inherit from the appropriate base classes. - a
requirements.txtfile with all necessary pip requirements to successfully run the inference
Import Libraries
The first step is to import the libraries we’ll be using. These are included by default in the Wallaroo instance’s JupyterHub service.
import numpy as np
import pandas as pd
import json
import os
import pickle
import pyarrow as pa
import tensorflow as tf
import warnings
warnings.filterwarnings('ignore')
from sklearn.cluster import KMeans
from tensorflow.keras.datasets import cifar10
from tensorflow.keras import Model
from tensorflow.keras.layers import Flatten
2023-07-07 16:16:26.511340: W tensorflow/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libcudart.so.11.0'; dlerror: libcudart.so.11.0: cannot open shared object file: No such file or directory
2023-07-07 16:16:26.511369: I tensorflow/stream_executor/cuda/cudart_stub.cc:29] Ignore above cudart dlerror if you do not have a GPU set up on your machine.
Variables
We’ll use these variables in later steps rather than hard code them in. In this case, the directory where we’ll store our artifacts.
model_directory = './models/vgg16_clustering'
Load Data Set
In this section, we will load our sample data and shape it.
# Load and preprocess the CIFAR-10 dataset
(X_train, y_train), (X_test, y_test) = cifar10.load_data()
# Normalize the pixel values to be between 0 and 1
X_train = X_train / 255.0
X_test = X_test / 255.0
X_train.shape
(50000, 32, 32, 3)
Train KMeans with VGG16 as feature extractor
Now we will train our model.
pretrained_model = tf.keras.applications.VGG16(include_top=False,
weights='imagenet',
input_shape=(32, 32, 3)
)
embedding_model = Model(inputs=pretrained_model.input,
outputs=Flatten()(pretrained_model.output))
2023-07-07 16:16:30.207936: W tensorflow/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libcuda.so.1'; dlerror: libcuda.so.1: cannot open shared object file: No such file or directory
2023-07-07 16:16:30.207966: W tensorflow/stream_executor/cuda/cuda_driver.cc:269] failed call to cuInit: UNKNOWN ERROR (303)
2023-07-07 16:16:30.207987: I tensorflow/stream_executor/cuda/cuda_diagnostics.cc:156] kernel driver does not appear to be running on this host (jupyter-john-2ehummel-40wallaroo-2eai): /proc/driver/nvidia/version does not exist
2023-07-07 16:16:30.208169: I tensorflow/core/platform/cpu_feature_guard.cc:151] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: AVX2 AVX512F FMA
To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.
X_train_embeddings = embedding_model.predict(X_train[:100])
X_test_embeddings = embedding_model.predict(X_test[:100])
kmeans = KMeans(n_clusters=2, random_state=0).fit(X_train_embeddings)
Save Models
Let’s first create the directory where the model artifacts will be saved:
os.makedirs(model_directory, exist_ok=True)
And now save the two models:
with open(f'{model_directory}/kmeans.pkl', 'wb') as fp:
pickle.dump(kmeans, fp)
embedding_model.save(f'{model_directory}/feature_extractor.h5')
WARNING:tensorflow:Compiled the loaded model, but the compiled metrics have yet to be built. `model.compile_metrics` will be empty until you train or evaluate the model.
All needed model artifacts have been now saved under our model directory.
Sample Arbitrary Python Script
The following shows an example of extending the Inference and InferenceBuilder classes for our specific model. This script is located in our model directory under ./models/vgg16_clustering.
"""This module features an example implementation of a custom Inference and its
corresponding InferenceBuilder."""
import pathlib
import pickle
from typing import Any, Set
import tensorflow as tf
from mac.config.inference import CustomInferenceConfig
from mac.inference import Inference
from mac.inference.creation import InferenceBuilder
from mac.types import InferenceData
from sklearn.cluster import KMeans
class ImageClustering(Inference):
"""Inference class for image clustering, that uses
a pre-trained VGG16 model on cifar10 as a feature extractor
and performs clustering on a trained KMeans model.
Attributes:
- feature_extractor: The embedding model we will use
as a feature extractor (i.e. a trained VGG16).
- expected_model_types: A set of model instance types that are expected by this inference.
- model: The model on which the inference is calculated.
"""
def __init__(self, feature_extractor: tf.keras.Model):
self.feature_extractor = feature_extractor
super().__init__()
@property
def expected_model_types(self) -> Set[Any]:
return {KMeans}
@Inference.model.setter # type: ignore
def model(self, model) -> None:
"""Sets the model on which the inference is calculated.
:param model: A model instance on which the inference is calculated.
:raises TypeError: If the model is not an instance of expected_model_types
(i.e. KMeans).
"""
self._raise_error_if_model_is_wrong_type(model) # this will make sure an error will be raised if the model is of wrong type
self._model = model
def _predict(self, input_data: InferenceData) -> InferenceData:
"""Calculates the inference on the given input data.
This is the core function that each subclass needs to implement
in order to calculate the inference.
:param input_data: The input data on which the inference is calculated.
It is of type InferenceData, meaning it comes as a dictionary of numpy
arrays.
:raises InferenceDataValidationError: If the input data is not valid.
Ideally, every subclass should raise this error if the input data is not valid.
:return: The output of the model, that is a dictionary of numpy arrays.
"""
# input_data maps to the input_schema we have defined
# with PyArrow, coming as a dictionary of numpy arrays
inputs = input_data["images"]
# Forward inputs to the models
embeddings = self.feature_extractor(inputs)
predictions = self.model.predict(embeddings.numpy())
# Return predictions as dictionary of numpy arrays
return {"predictions": predictions}
class ImageClusteringBuilder(InferenceBuilder):
"""InferenceBuilder subclass for ImageClustering, that loads
a pre-trained VGG16 model on cifar10 as a feature extractor
and a trained KMeans model, and creates an ImageClustering object."""
@property
def inference(self) -> ImageClustering:
return ImageClustering
def create(self, config: CustomInferenceConfig) -> ImageClustering:
"""Creates an Inference subclass and assigns a model and additionally
needed attributes to it.
:param config: Custom inference configuration. In particular, we're
interested in `config.model_path` that is a pathlib.Path object
pointing to the folder where the model artifacts are saved.
Every artifact we need to load from this folder has to be
relative to `config.model_path`.
:return: A custom Inference instance.
"""
feature_extractor = self._load_feature_extractor(
config.model_path / "feature_extractor.h5"
)
inference = self.inference(feature_extractor)
model = self._load_model(config.model_path / "kmeans.pkl")
inference.model = model
return inference
def _load_feature_extractor(
self, file_path: pathlib.Path
) -> tf.keras.Model:
return tf.keras.models.load_model(file_path)
def _load_model(self, file_path: pathlib.Path) -> KMeans:
with open(file_path.as_posix(), "rb") as fp:
model = pickle.load(fp)
return model
Create Requirements File
As a last step we need to create a requirements.txt file and save it under our vgg_clustering/. The file should contain all the necessary pip requirements needed to run the inference. It will have this data inside.
- IMPORTANT NOTE: Verify that the library versions match the required model versions and libraries for Wallaroo. Otherwise the deployed models
tensorflow==2.8.0
scikit-learn==1.2.2
Zip model folder
Assuming we have stored the following files inside out model directory models/vgg_clustering/:
feature_extractor.h5kmeans.pklcustom_inference.pyrequirements.txt
Now we will zip the file. This is performed with the zip command and the -r option to zip the contents of the entire directory.
zip -r model-auto-conversion-BYOP-vgg16-clustering.zip vgg16_clustering/
The arbitrary Python custom model can now be uploaded to the Wallaroo instance.
2.2 - Wallaroo SDK Upload Arbitrary Python Tutorial: Deploy VGG16 Model
How to deploy a VGG166 model as a arbitrary python model in Wallaroo.
This tutorial can be downloaded as part of the Wallaroo Tutorials repository.
Arbitrary Python Tutorial Deploy Model in Wallaroo Upload and Deploy
This tutorial demonstrates how to use arbitrary python as a ML Model in Wallaroo. Arbitrary Python allows organizations to use Python scripts that require specific libraries and artifacts as models in the Wallaroo engine. This allows for highly flexible use of ML models with supporting scripts.
Tutorial Goals
This tutorial is split into two parts:
- Wallaroo SDK Upload Arbitrary Python Tutorial: Generate Model: Train a dummy
KMeansmodel for clustering images using a pre-trainedVGG16model oncifar10as a feature extractor. The Python entry points used for Wallaroo deployment will be added and described.- A copy of the arbitrary Python model
models/model-auto-conversion-BYOP-vgg16-clustering.zipis included in this tutorial, so this step can be skipped.
- A copy of the arbitrary Python model
- Arbitrary Python Tutorial Deploy Model in Wallaroo Upload and Deploy: Deploys the
KMeansmodel in an arbitrary Python package in Wallaroo, and perform sample inferences. The filemodels/model-auto-conversion-BYOP-vgg16-clustering.zipis provided so users can go right to testing deployment.
Arbitrary Python models, also known as Bring Your Own Predict (BYOP) allow for custom model deployments with supporting scripts and artifacts. These are used with pre-trained models (PyTorch, Tensorflow, etc) along with whatever supporting artifacts they require. Supporting artifacts can include other Python modules, model files, etc. These are zipped with all scripts, artifacts, and a requirements.txt file that indicates what other Python models need to be imported that are outside of the typical Wallaroo platform.
Contrast this with Wallaroo Python models - aka “Python steps”. These are standalone python scripts that use the python libraries natively supported by the Wallaroo platform. These are used for either simple model deployment (such as ARIMA Statsmodels), or data formatting such as the postprocessing steps. A Wallaroo Python model will be composed of one Python script that matches the Wallaroo requirements.
Arbitrary Python File Requirements
Arbitrary Python (BYOP) models are uploaded to Wallaroo via a ZIP file with the following components:
| Artifact | Type | Description |
|---|---|---|
Python scripts aka .py files with classes that extend mac.inference.Inference and mac.inference.creation.InferenceBuilder | Python Script | Extend the classes mac.inference.Inference and mac.inference.creation.InferenceBuilder. These are included with the Wallaroo SDK. Further details are in Arbitrary Python Script Requirements. Note that there is no specified naming requirements for the classes that extend mac.inference.Inference and mac.inference.creation.InferenceBuilder - any qualified class name is sufficient as long as these two classes are extended as defined below. |
requirements.txt | Python requirements file | This sets the Python libraries used for the arbitrary python model. These libraries should be targeted for Python 3.8 compliance. These requirements and the versions of libraries should be exactly the same between creating the model and deploying it in Wallaroo. This insures that the script and methods will function exactly the same as during the model creation process. |
| Other artifacts | Files | Other models, files, and other artifacts used in support of this model. |
For example, the if the arbitrary python model will be known as vgg_clustering, the contents may be in the following structure, with vgg_clustering as the storage directory:
vgg_clustering\
feature_extractor.h5
kmeans.pkl
custom_inference.py
requirements.txt
Note the inclusion of the custom_inference.py file. This file name is not required - any Python script or scripts that extend the classes listed above are sufficient. This Python script could have been named vgg_custom_model.py or any other name as long as it includes the extension of the classes listed above.
The sample arbitrary python model file is created with the command zip -r vgg_clustering.zip vgg_clustering/.
Wallaroo Arbitrary Python uses the Wallaroo SDK mac module, included in the Wallaroo SDK 2023.2.1 and above. See the Wallaroo SDK Install Guides for instructions on installing the Wallaroo SDK.
Arbitrary Python Script Requirements
The entry point of the arbitrary python model is any python script that extends the following classes. These are included with the Wallaroo SDK. The required methods that must be overridden are specified in each section below.
mac.inference.Inferenceinterface serves model inferences based on submitted input some input. Its purpose is to serve inferences for any supported arbitrary model framework (e.g.scikit,kerasetc.).classDiagram class Inference { <<Abstract>> +model Optional[Any] +expected_model_types()* Set +predict(input_data: InferenceData)* InferenceData -raise_error_if_model_is_not_assigned() None -raise_error_if_model_is_wrong_type() None }mac.inference.creation.InferenceBuilderbuilds a concreteInference, i.e. instantiates anInferenceobject, loads the appropriate model and assigns the model to to the Inference object.classDiagram class InferenceBuilder { +create(config InferenceConfig) * Inference -inference()* Any }
mac.inference.Inference
mac.inference.Inference Objects
| Object | Type | Description |
|---|---|---|
model Optional[Any] | An optional list of models that match the supported frameworks from wallaroo.framework.Framework included in the arbitrary python script. Note that this is optional - no models are actually required. A BYOP can refer to a specific model(s) used, be used for data processing and reshaping for later pipeline steps, or other needs. |
mac.inference.Inference Methods
| Method | Returns | Description |
|---|---|---|
expected_model_types (Required) | Set | Returns a Set of models expected for the inference as defined by the developer. Typically this is a set of one. Wallaroo checks the expected model types to verify that the model submitted through the InferenceBuilder method matches what this Inference class expects. |
_predict (input_data: mac.types.InferenceData) (Required) | mac.types.InferenceData | The entry point for the Wallaroo inference with the following input and output parameters that are defined when the model is updated.
InferenceDataValidationError exception is raised when the input data does not match mac.types.InferenceData. |
raise_error_if_model_is_not_assigned | N/A | Error when expected_model_types is not set. |
raise_error_if_model_is_wrong_type | N/A | Error when the model does not match the expected_model_types. |
mac.inference.creation.InferenceBuilder
InferenceBuilder builds a concrete Inference, i.e. instantiates an Inference object, loads the appropriate model and assigns the model to the Inference.
classDiagram
class InferenceBuilder {
+create(config InferenceConfig) * Inference
-inference()* Any
}Each model that is included requires its own InferenceBuilder. InferenceBuilder loads one model, then submits it to the Inference class when created. The Inference class checks this class against its expected_model_types() Set.
mac.inference.creation.InferenceBuilder Methods
| Method | Returns | Description |
|---|---|---|
create(config mac.config.inference.CustomInferenceConfig) (Required) | The custom Inference instance. | Creates an Inference subclass, then assigns a model and attributes. The CustomInferenceConfig is used to retrieve the config.model_path, which is a pathlib.Path object pointing to the folder where the model artifacts are saved. Every artifact loaded must be relative to config.model_path. This is set when the arbitrary python .zip file is uploaded and the environment for running it in Wallaroo is set. For example: loading the artifact vgg_clustering\feature_extractor.h5 would be set with config.model_path \ feature_extractor.h5. The model loaded must match an existing module. For our example, this is from sklearn.cluster import KMeans, and this must match the Inference expected_model_types. |
inference | custom Inference instance. | Returns the instantiated custom Inference object created from the create method. |
Tutorial Steps
Import Libraries
The first step is to import the libraries we’ll be using. These are included by default in the Wallaroo instance’s JupyterHub service.
import numpy as np
import pandas as pd
import json
import os
import pickle
import pyarrow as pa
import tensorflow as tf
import wallaroo
from sklearn.cluster import KMeans
from tensorflow.keras.datasets import cifar10
from tensorflow.keras import Model
from tensorflow.keras.layers import Flatten
from wallaroo.pipeline import Pipeline
from wallaroo.deployment_config import DeploymentConfigBuilder
from wallaroo.framework import Framework
2023-07-07 16:18:13.974516: W tensorflow/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libcudart.so.11.0'; dlerror: libcudart.so.11.0: cannot open shared object file: No such file or directory
2023-07-07 16:18:13.974543: I tensorflow/stream_executor/cuda/cudart_stub.cc:29] Ignore above cudart dlerror if you do not have a GPU set up on your machine.
Open a Connection to Wallaroo
The next step is connect to Wallaroo through the Wallaroo client. The Python library is included in the Wallaroo install and available through the Jupyter Hub interface provided with your Wallaroo environment.
This is accomplished using the wallaroo.Client() command, which provides a URL to grant the SDK permission to your specific Wallaroo environment. When displayed, enter the URL into a browser and confirm permissions. Store the connection into a variable that can be referenced later.
If logging into the Wallaroo instance through the internal JupyterHub service, use wl = wallaroo.Client(). If logging in externally, update the wallarooPrefix and wallarooSuffix variables with the proper DNS information. For more information on Wallaroo DNS settings, see the Wallaroo DNS Integration Guide.
wl = wallaroo.Client()
Set Variables and Helper Functions
We’ll set the name of our workspace, pipeline, models and files. Workspace names must be unique across the Wallaroo workspace. For this, we’ll add in a randomly generated 4 characters to the workspace name to prevent collisions with other users’ workspaces. If running this tutorial, we recommend hard coding the workspace name so it will function in the same workspace each time it’s run.
We’ll set up some helper functions that will either use existing workspaces and pipelines, or create them if they do not already exist.
import string
import random
# make a random 4 character suffix to prevent overwriting other user's workspaces
suffix= ''.join(random.choice(string.ascii_lowercase) for i in range(4))
workspace_name = f'vgg16-clustering-workspace{suffix}'
pipeline_name = f'vgg16-clustering-pipeline'
model_name = 'vgg16-clustering'
model_file_name = './models/model-auto-conversion-BYOP-vgg16-clustering.zip'
def get_workspace(name):
workspace = None
for ws in wl.list_workspaces():
if ws.name() == name:
workspace= ws
if(workspace == None):
workspace = wl.create_workspace(name)
return workspace
def get_pipeline(name):
try:
pipeline = wl.pipelines_by_name(name)[0]
except EntityNotFoundError:
pipeline = wl.build_pipeline(name)
return pipeline
Create Workspace and Pipeline
We will now create the Wallaroo workspace to store our model and set it as the current workspace. Future commands will default to this workspace for pipeline creation, model uploads, etc. We’ll create our Wallaroo pipeline that is used to deploy our arbitrary Python model.
workspace = get_workspace(workspace_name)
wl.set_current_workspace(workspace)
pipeline = get_pipeline(pipeline_name)
Upload Arbitrary Python Model
Arbitrary Python models are uploaded to Wallaroo through the Wallaroo Client upload_model method.
Upload Arbitrary Python Model Parameters
The following parameters are required for Arbitrary Python models. Note that while some fields are considered as optional for the upload_model method, they are required for proper uploading of a Arbitrary Python model to Wallaroo.
| Parameter | Type | Description |
|---|---|---|
name | string (Required) | The name of the model. Model names are unique per workspace. Models that are uploaded with the same name are assigned as a new version of the model. |
path | string (Required) | The path to the model file being uploaded. |
framework | string (Upload Method Optional, Arbitrary Python model Required) | Set as Framework.CUSTOM. |
input_schema | pyarrow.lib.Schema (Upload Method Optional, Arbitrary Python model Required) | The input schema in Apache Arrow schema format. |
output_schema | pyarrow.lib.Schema (Upload Method Optional, Arbitrary Python model Required) | The output schema in Apache Arrow schema format. |
convert_wait | bool (Upload Method Optional, Arbitrary Python model Optional) (Default: True) |
|
Once the upload process starts, the model is containerized by the Wallaroo instance. This process may take up to 10 minutes.
Upload Arbitrary Python Model Return
The following is returned with a successful model upload and conversion.
| Field | Type | Description |
|---|---|---|
name | string | The name of the model. |
version | string | The model version as a unique UUID. |
file_name | string | The file name of the model as stored in Wallaroo. |
image_path | string | The image used to deploy the model in the Wallaroo engine. |
last_update_time | DateTime | When the model was last updated. |
For our example, we’ll start with setting the input_schema and output_schema that is expected by our ImageClustering._predict() method.
input_schema = pa.schema([
pa.field('images', pa.list_(
pa.list_(
pa.list_(
pa.int64(),
list_size=3
),
list_size=32
),
list_size=32
)),
])
output_schema = pa.schema([
pa.field('predictions', pa.int64()),
])
Upload Model
Now we’ll upload our model. The framework is Framework.CUSTOM for arbitrary Python models, and we’ll specify the input and output schemas for the upload.
model = wl.upload_model(model_name,
model_file_name,
framework=Framework.CUSTOM,
input_schema=input_schema,
output_schema=output_schema,
convert_wait=True)
model
Waiting for model conversion... It may take up to 10.0min.
Model is Pending conversion..Converting..................Ready.
| Name | vgg16-clustering |
| Version | 86eaa743-f659-4eac-9544-23893ea0101c |
| File Name | model-auto-conversion-BYOP-vgg16-clustering.zip |
| SHA | 9701562daa747b15846ce6e5eb20ba5d8b6ac77c38b62e58298da56252aa493f |
| Status | ready |
| Image Path | proxy.replicated.com/proxy/wallaroo/ghcr.io/wallaroolabs/mlflow-deploy:v2023.3.0-main-3481 |
| Updated At | 2023-07-Jul 16:20:20 |
Deploy Pipeline
The model is uploaded and ready for use. We’ll add it as a step in our pipeline, then deploy the pipeline. For this example we’re allocated 0.25 cpu and 4 Gi RAM to the pipeline through the pipeline’s deployment configuration.
pipeline.add_model_step(model)
| name | vgg16-clustering-pipeline |
|---|---|
| created | 2023-06-28 16:37:14.436166+00:00 |
| last_updated | 2023-07-07 02:09:17.095252+00:00 |
| deployed | False |
| tags | |
| versions | 21fb5777-f32d-4b86-99c1-3b099f0f671d, 610afdf4-850d-48f6-aad9-3115f389ee78, 13ed3d22-a82b-4a45-9b1d-5d668e9b2452, 9049c924-146f-4f7a-9e16-0b2565491547 |
| steps | vgg16-clustering |
deployment_config = DeploymentConfigBuilder() \
.cpus(0.25).memory('4Gi') \
.build()
pipeline.deploy(deployment_config=deployment_config)
pipeline.status()
Waiting for deployment - this will take up to 90s ....................... ok
{‘status’: ‘Running’,
‘details’: [],
’engines’: [{‘ip’: ‘10.244.17.211’,
’name’: ’engine-85bd45d44b-dstdp’,
‘status’: ‘Running’,
‘reason’: None,
‘details’: [],
‘pipeline_statuses’: {‘pipelines’: [{‘id’: ‘vgg16-clustering-pipeline’,
‘status’: ‘Running’}]},
‘model_statuses’: {‘models’: [{’name’: ‘vgg16-clustering’,
‘version’: ‘86eaa743-f659-4eac-9544-23893ea0101c’,
‘sha’: ‘9701562daa747b15846ce6e5eb20ba5d8b6ac77c38b62e58298da56252aa493f’,
‘status’: ‘Running’}]}}],
’engine_lbs’: [{‘ip’: ‘10.244.17.212’,
’name’: ’engine-lb-584f54c899-8mmpl’,
‘status’: ‘Running’,
‘reason’: None,
‘details’: []}],
‘sidekicks’: [{‘ip’: ‘10.244.17.210’,
’name’: ’engine-sidekick-vgg16-clustering-174-79f64f7cb4-25wqf’,
‘status’: ‘Running’,
‘reason’: None,
‘details’: [],
‘statuses’: ‘\n’}]}
Run inference
Everything is in place - we’ll now run a sample inference with some toy data. In this case we’re randomly generating some values in the data shape the model expects, then submitting an inference request through our deployed pipeline.
input_data = {
"images": [np.random.randint(0, 256, (32, 32, 3), dtype=np.uint8)] * 2,
}
dataframe = pd.DataFrame(input_data)
dataframe
| images | |
|---|---|
| 0 | [[[10, 214, 168], [50, 238, 47], [189, 15, 55]... |
| 1 | [[[10, 214, 168], [50, 238, 47], [189, 15, 55]... |
pipeline.infer(dataframe, timeout=10000)
| time | in.images | out.predictions | check_failures | |
|---|---|---|---|---|
| 0 | 2023-07-07 16:20:48.450 | [10, 214, 168, 50, 238, 47, 189, 15, 55, 218, ... | 1 | 0 |
| 1 | 2023-07-07 16:20:48.450 | [10, 214, 168, 50, 238, 47, 189, 15, 55, 218, ... | 1 | 0 |
Undeploy Pipelines
The inference is successful, so we will undeploy the pipeline and return the resources back to the cluster.
pipeline.undeploy()
Waiting for undeployment - this will take up to 45s ..................................... ok
| name | vgg16-clustering-pipeline |
|---|---|
| created | 2023-07-07 16:20:23.354098+00:00 |
| last_updated | 2023-07-07 16:20:23.354098+00:00 |
| deployed | False |
| tags | |
| versions | 62f3b65c-91e7-4057-a645-6ff5e62e3b21 |
| steps | vgg16-clustering |
3 - Wallaroo SDK Upload Tutorials: Hugging Face
How to upload different Hugging Face models to Wallaroo.
The following tutorials cover how to upload sample Hugging Face models. The complete list of supported Hugging Face pipelines are as follows.
| Parameter | Description |
|---|---|
| Web Site | https://huggingface.co/models |
| Supported Libraries |
|
| Frameworks | The following Hugging Face pipelines are supported by Wallaroo.
|
| Runtime | Containerized aka tensorflow / mlflow |
Hugging Face Schemas
Input and output schemas for each Hugging Face pipeline are defined below. Note that adding additional inputs not specified below will raise errors, except for the following:
Framework.HUGGING-FACE-IMAGE-TO-TEXTFramework.HUGGING-FACE-TEXT-CLASSIFICATIONFramework.HUGGING-FACE-SUMMARIZATIONFramework.HUGGING-FACE-TRANSLATION
Additional inputs added to these Hugging Face pipelines will be added as key/pair value arguments to the model’s generate method. If the argument is not required, then the model will default to the values coded in the original Hugging Face model’s source code.
See the Hugging Face Pipeline documentation for more details on each pipeline and framework.
| Wallaroo Framework | Reference |
|---|---|
Framework.HUGGING-FACE-FEATURE-EXTRACTION |
Schemas:
input_schema = pa.schema([
pa.field('inputs', pa.string())
])
output_schema = pa.schema([
pa.field('output', pa.list_(
pa.list_(
pa.float64(),
list_size=128
),
))
])
| Wallaroo Framework | Reference |
|---|---|
Framework.HUGGING-FACE-IMAGE-CLASSIFICATION |
Schemas:
input_schema = pa.schema([
pa.field('inputs', pa.list_(
pa.list_(
pa.list_(
pa.int64(),
list_size=3
),
list_size=100
),
list_size=100
)),
pa.field('top_k', pa.int64()),
])
output_schema = pa.schema([
pa.field('score', pa.list_(pa.float64(), list_size=2)),
pa.field('label', pa.list_(pa.string(), list_size=2)),
])
| Wallaroo Framework | Reference |
|---|---|
Framework.HUGGING-FACE-IMAGE-SEGMENTATION |
Schemas:
input_schema = pa.schema([
pa.field('inputs',
pa.list_(
pa.list_(
pa.list_(
pa.int64(),
list_size=3
),
list_size=100
),
list_size=100
)),
pa.field('threshold', pa.float64()),
pa.field('mask_threshold', pa.float64()),
pa.field('overlap_mask_area_threshold', pa.float64()),
])
output_schema = pa.schema([
pa.field('score', pa.list_(pa.float64())),
pa.field('label', pa.list_(pa.string())),
pa.field('mask',
pa.list_(
pa.list_(
pa.list_(
pa.int64(),
list_size=100
),
list_size=100
),
)),
])
| Wallaroo Framework | Reference |
|---|---|
Framework.HUGGING-FACE-IMAGE-TO-TEXT |
Any parameter that is not part of the required inputs list will be forwarded to the model as a key/pair value to the underlying models generate method. If the additional input is not supported by the model, an error will be returned.
Schemas:
input_schema = pa.schema([
pa.field('inputs', pa.list_( #required
pa.list_(
pa.list_(
pa.int64(),
list_size=3
),
list_size=100
),
list_size=100
)),
# pa.field('max_new_tokens', pa.int64()), # optional
])
output_schema = pa.schema([
pa.field('generated_text', pa.list_(pa.string())),
])
| Wallaroo Framework | Reference |
|---|---|
Framework.HUGGING-FACE-OBJECT-DETECTION |
Schemas:
input_schema = pa.schema([
pa.field('inputs',
pa.list_(
pa.list_(
pa.list_(
pa.int64(),
list_size=3
),
list_size=100
),
list_size=100
)),
pa.field('threshold', pa.float64()),
])
output_schema = pa.schema([
pa.field('score', pa.list_(pa.float64())),
pa.field('label', pa.list_(pa.string())),
pa.field('box',
pa.list_( # dynamic output, i.e. dynamic number of boxes per input image, each sublist contains the 4 box coordinates
pa.list_(
pa.int64(),
list_size=4
),
),
),
])
| Wallaroo Framework | Reference |
|---|---|
Framework.HUGGING-FACE-QUESTION-ANSWERING |
Schemas:
input_schema = pa.schema([
pa.field('question', pa.string()),
pa.field('context', pa.string()),
pa.field('top_k', pa.int64()),
pa.field('doc_stride', pa.int64()),
pa.field('max_answer_len', pa.int64()),
pa.field('max_seq_len', pa.int64()),
pa.field('max_question_len', pa.int64()),
pa.field('handle_impossible_answer', pa.bool_()),
pa.field('align_to_words', pa.bool_()),
])
output_schema = pa.schema([
pa.field('score', pa.float64()),
pa.field('start', pa.int64()),
pa.field('end', pa.int64()),
pa.field('answer', pa.string()),
])
| Wallaroo Framework | Reference |
|---|---|
Framework.HUGGING-FACE-STABLE-DIFFUSION-TEXT-2-IMG |
Schemas:
input_schema = pa.schema([
pa.field('prompt', pa.string()),
pa.field('height', pa.int64()),
pa.field('width', pa.int64()),
pa.field('num_inference_steps', pa.int64()), # optional
pa.field('guidance_scale', pa.float64()), # optional
pa.field('negative_prompt', pa.string()), # optional
pa.field('num_images_per_prompt', pa.string()), # optional
pa.field('eta', pa.float64()) # optional
])
output_schema = pa.schema([
pa.field('images', pa.list_(
pa.list_(
pa.list_(
pa.int64(),
list_size=3
),
list_size=128
),
list_size=128
)),
])
| Wallaroo Framework | Reference |
|---|---|
Framework.HUGGING-FACE-SUMMARIZATION |
Any parameter that is not part of the required inputs list will be forwarded to the model as a key/pair value to the underlying models generate method. If the additional input is not supported by the model, an error will be returned.
Schemas:
input_schema = pa.schema([
pa.field('inputs', pa.string()),
pa.field('return_text', pa.bool_()),
pa.field('return_tensors', pa.bool_()),
pa.field('clean_up_tokenization_spaces', pa.bool_()),
# pa.field('extra_field', pa.int64()), # every extra field you specify will be forwarded as a key/value pair
])
output_schema = pa.schema([
pa.field('summary_text', pa.string()),
])
| Wallaroo Framework | Reference |
|---|---|
Framework.HUGGING-FACE-TEXT-CLASSIFICATION |
Schemas
input_schema = pa.schema([
pa.field('inputs', pa.string()), # required
pa.field('top_k', pa.int64()), # optional
pa.field('function_to_apply', pa.string()), # optional
])
output_schema = pa.schema([
pa.field('label', pa.list_(pa.string(), list_size=2)), # list with a number of items same as top_k, list_size can be skipped but may lead in worse performance
pa.field('score', pa.list_(pa.float64(), list_size=2)), # list with a number of items same as top_k, list_size can be skipped but may lead in worse performance
])
| Wallaroo Framework | Reference |
|---|---|
Framework.HUGGING-FACE-TRANSLATION |
Any parameter that is not part of the required inputs list will be forwarded to the model as a key/pair value to the underlying models generate method. If the additional input is not supported by the model, an error will be returned.
Schemas:
input_schema = pa.schema([
pa.field('inputs', pa.string()), # required
pa.field('return_tensors', pa.bool_()), # optional
pa.field('return_text', pa.bool_()), # optional
pa.field('clean_up_tokenization_spaces', pa.bool_()), # optional
pa.field('src_lang', pa.string()), # optional
pa.field('tgt_lang', pa.string()), # optional
# pa.field('extra_field', pa.int64()), # every extra field you specify will be forwarded as a key/value pair
])
output_schema = pa.schema([
pa.field('translation_text', pa.string()),
])
| Wallaroo Framework | Reference |
|---|---|
Framework.HUGGING-FACE-ZERO-SHOT-CLASSIFICATION |
Schemas:
input_schema = pa.schema([
pa.field('inputs', pa.string()), # required
pa.field('candidate_labels', pa.list_(pa.string(), list_size=2)), # required
pa.field('hypothesis_template', pa.string()), # optional
pa.field('multi_label', pa.bool_()), # optional
])
output_schema = pa.schema([
pa.field('sequence', pa.string()),
pa.field('scores', pa.list_(pa.float64(), list_size=2)), # same as number of candidate labels, list_size can be skipped by may result in slightly worse performance
pa.field('labels', pa.list_(pa.string(), list_size=2)), # same as number of candidate labels, list_size can be skipped by may result in slightly worse performance
])
| Wallaroo Framework | Reference |
|---|---|
Framework.HUGGING-FACE-ZERO-SHOT-IMAGE-CLASSIFICATION |
Schemas:
input_schema = pa.schema([
pa.field('inputs', # required
pa.list_(
pa.list_(
pa.list_(
pa.int64(),
list_size=3
),
list_size=100
),
list_size=100
)),
pa.field('candidate_labels', pa.list_(pa.string(), list_size=2)), # required
pa.field('hypothesis_template', pa.string()), # optional
])
output_schema = pa.schema([
pa.field('score', pa.list_(pa.float64(), list_size=2)), # same as number of candidate labels
pa.field('label', pa.list_(pa.string(), list_size=2)), # same as number of candidate labels
])
| Wallaroo Framework | Reference |
|---|---|
Framework.HUGGING-FACE-ZERO-SHOT-OBJECT-DETECTION |
Schemas:
input_schema = pa.schema([
pa.field('images',
pa.list_(
pa.list_(
pa.list_(
pa.int64(),
list_size=3
),
list_size=640
),
list_size=480
)),
pa.field('candidate_labels', pa.list_(pa.string(), list_size=3)),
pa.field('threshold', pa.float64()),
# pa.field('top_k', pa.int64()), # we want the model to return exactly the number of predictions, we shouldn't specify this
])
output_schema = pa.schema([
pa.field('score', pa.list_(pa.float64())), # variable output, depending on detected objects
pa.field('label', pa.list_(pa.string())), # variable output, depending on detected objects
pa.field('box',
pa.list_( # dynamic output, i.e. dynamic number of boxes per input image, each sublist contains the 4 box coordinates
pa.list_(
pa.int64(),
list_size=4
),
),
),
])
| Wallaroo Framework | Reference |
|---|---|
Framework.HUGGING-FACE-SENTIMENT-ANALYSIS | Hugging Face Sentiment Analysis |
| Wallaroo Framework | Reference |
|---|---|
Framework.HUGGING-FACE-TEXT-GENERATION |
Any parameter that is not part of the required inputs list will be forwarded to the model as a key/pair value to the underlying models generate method. If the additional input is not supported by the model, an error will be returned.
input_schema = pa.schema([
pa.field('inputs', pa.string()),
pa.field('return_tensors', pa.bool_()), # optional
pa.field('return_text', pa.bool_()), # optional
pa.field('return_full_text', pa.bool_()), # optional
pa.field('clean_up_tokenization_spaces', pa.bool_()), # optional
pa.field('prefix', pa.string()), # optional
pa.field('handle_long_generation', pa.string()), # optional
# pa.field('extra_field', pa.int64()), # every extra field you specify will be forwarded as a key/value pair
])
output_schema = pa.schema([
pa.field('generated_text', pa.list_(pa.string(), list_size=1))
])
3.1 - Wallaroo API Upload Tutorial: Hugging Face Zero Shot Classification
How to upload a Hugging Face Zero Shot Classification model to Wallaroo via the MLOps API.
The Wallaroo 101 tutorial can be downloaded as part of the Wallaroo Tutorials repository.
Wallaroo Model Upload via MLops API: Hugging Face Zero Shot Classification
The following tutorial demonstrates how to upload a Hugging Face Zero Shot model to a Wallaroo instance.
Tutorial Goals
Demonstrate the following:
- Upload a Hugging Face Zero Shot Model to a Wallaroo instance.
- Create a pipeline and add the model as a pipeline step.
- Perform a sample inference.
Prerequisites
- A Wallaroo version 2023.2.1 or above instance
References
- Wallaroo MLOps API Essentials Guide: Model Upload and Registrations
- Wallaroo API Connection Guide
- DNS Integration Guide
Tutorial Steps
Import Libraries
import json
import os
import requests
import base64
import wallaroo
from wallaroo.pipeline import Pipeline
from wallaroo.deployment_config import DeploymentConfigBuilder
from wallaroo.framework import Framework
import pyarrow as pa
import numpy as np
import pandas as pd
Connect to Wallaroo
To perform the various Wallaroo MLOps API requests, we will use the Wallaroo SDK to generate the necessary tokens. For details on other methods of requesting and using authentication tokens with the Wallaroo MLOps API, see the Wallaroo API Connection Guide.
This is accomplished using the wallaroo.Client() command, which provides a URL to grant the SDK permission to your specific Wallaroo environment. When displayed, enter the URL into a browser and confirm permissions. Store the connection into a variable that can be referenced later.
If logging into the Wallaroo instance through the internal JupyterHub service, use wl = wallaroo.Client(). For more information on Wallaroo Client settings, see the Client Connection guide.
wl = wallaroo.Client()
Variables
The following variables will be set for the rest of the tutorial to set the following:
- Wallaroo Workspace
- Wallaroo Pipeline
- Wallaroo Model name and path
- Wallaroo Model Framework
- The DNS prefix and suffix for the Wallaroo instance.
To allow this tutorial to be run multiple times or by multiple users in the same Wallaroo instance, a random 4 character prefix will be added to the workspace, pipeline, and model.
Verify that the DNS prefix and suffix match the Wallaroo instance used for this tutorial. See the DNS Integration Guide for more details.
import string
import random
# make a random 4 character suffix to prevent overwriting other user's workspaces
suffix= ''.join(random.choice(string.ascii_lowercase) for i in range(4))
workspace_name = f'hugging-face-zero-shot-api{suffix}'
pipeline_name = f'hugging-face-zero-shot'
model_name = f'zero-shot-classification'
model_file_name = "./models/model-auto-conversion_hugging-face_dummy-pipelines_zero-shot-classification-pipeline.zip"
framework = "hugging-face-zero-shot-classification"
wallarooPrefix = "YOUR PREFIX."
wallarooPrefix = "YOUR SUFFIX"
wallarooPrefix = "doc-test."
wallarooSuffix = "wallarooexample.ai"
APIURL=f"https://{wallarooPrefix}api.{wallarooSuffix}"
APIURL
'https://doc-test.api.wallarooexample.ai'
Create the Workspace
In a production environment, the Wallaroo workspace that contains the pipeline and models would be created and deployed. We will quickly recreate those steps using the MLOps API.
Workspaces are created through the MLOps API with the /v1/api/workspaces/create command. This requires the workspace name be provided, and that the workspace not already exist in the Wallaroo instance.
Reference: MLOps API Create Workspace
# Retrieve the token
headers = wl.auth.auth_header()
# set Content-Type type
headers['Content-Type']='application/json'
# Create workspace
apiRequest = f"{APIURL}/v1/api/workspaces/create"
data = {
"workspace_name": workspace_name
}
response = requests.post(apiRequest, json=data, headers=headers, verify=True).json()
display(response)
# Stored for future examples
workspaceId = response['workspace_id']
{'workspace_id': 9}
Upload the Model
- Endpoint:
/v1/api/models/upload_and_convert
- Headers:
- Content-Type:
multipart/form-data
- Content-Type:
- Parameters
- name (String Required): The model name.
- visibility (String Required): Either
publicorprivate. - workspace_id (String Required): The numerical ID of the workspace to upload the model to.
- conversion (String Required): The conversion parameters that include the following:
- framework (String Required): The framework of the model being uploaded. See the list of supported models for more details.
- python_version (String Required): The version of Python required for model.
- requirements (String Required): Required libraries. Can be
[]if the requirements are default Wallaroo JupyterHub libraries. - input_schema (String Optional): The input schema from the Apache Arrow
pyarrow.lib.Schemaformat, encoded withbase64.b64encode. Only required for non-native runtime models. - output_schema (String Optional): The output schema from the Apache Arrow
pyarrow.lib.Schemaformat, encoded withbase64.b64encode. Only required for non-native runtime models.
Set the Schemas
The input and output schemas will be defined according to the Wallaroo Hugging Face schema requirements. The inputs are then base64 encoded for attachment in the API request.
input_schema = pa.schema([
pa.field('inputs', pa.string()), # required
pa.field('candidate_labels', pa.list_(pa.string(), list_size=2)), # required
pa.field('hypothesis_template', pa.string()), # optional
pa.field('multi_label', pa.bool_()), # optional
])
output_schema = pa.schema([
pa.field('sequence', pa.string()),
pa.field('scores', pa.list_(pa.float64(), list_size=2)), # same as number of candidate labels, list_size can be skipped by may result in slightly worse performance
pa.field('labels', pa.list_(pa.string(), list_size=2)), # same as number of candidate labels, list_size can be skipped by may result in slightly worse performance
])
encoded_input_schema = base64.b64encode(
bytes(input_schema.serialize())
).decode("utf8")
encoded_output_schema = base64.b64encode(
bytes(output_schema.serialize())
).decode("utf8")
Build the Request
We will now build the request to include the required data. We will be using the workspaceId returned when we created our workspace in a previous step, specifying the input and output schemas, and the framework.
metadata = {
"name": model_name,
"visibility": "private",
"workspace_id": workspaceId,
"conversion": {
"framework": framework,
"python_version": "3.8",
"requirements": []
},
"input_schema": encoded_input_schema,
"output_schema": encoded_output_schema,
}
Upload Model API Request
Now we will make our upload and convert request. The model is is stored for the next set of steps.
headers = wl.auth.auth_header()
files = {
'metadata': (None, json.dumps(metadata), "application/json"),
'file': (model_name, open(model_file_name,'rb'),'application/octet-stream')
}
response = requests.post(f'{APIURL}/v1/api/models/upload_and_convert',
headers=headers,
files=files)
print(response.json())
{'insert_models': {'returning': [{'models': [{'id': 9}]}]}}
# Get the model details
# Retrieve the token
headers = wl.auth.auth_header()
# set Content-Type type
headers['Content-Type']='application/json'
apiRequest = f"{APIURL}/v1/api/models/list_versions"
data = {
"model_id": model_name,
"models_pk_id" : modelId
}
status = None
while status != 'ready':
response = requests.post(apiRequest, json=data, headers=headers, verify=True).json()
# verify we have the right version
display(model)
model = next(model for model in response if model["id"] == modelId)
display(model)
status = model['status']
{'sha': '3dcc14dd925489d4f0a3960e90a7ab5917ab685ce955beca8924aa7bb9a69398',
'models_pk_id': 7,
'model_version': '284a2e7c-679a-40cc-9121-2747b81a0228',
'owner_id': '""',
'model_id': 'zero-shot-classification',
'id': 7,
'file_name': 'zero-shot-classification',
'image_path': 'proxy.replicated.com/proxy/wallaroo/ghcr.io/wallaroolabs/mlflow-deploy:v2023.3.0-main-3509',
'status': 'ready'}
{‘sha’: ‘3dcc14dd925489d4f0a3960e90a7ab5917ab685ce955beca8924aa7bb9a69398’,
‘models_pk_id’: 7,
‘model_version’: ‘284a2e7c-679a-40cc-9121-2747b81a0228’,
‘owner_id’: ‘""’,
‘model_id’: ‘zero-shot-classification’,
‘id’: 7,
‘file_name’: ‘zero-shot-classification’,
‘image_path’: ‘proxy.replicated.com/proxy/wallaroo/ghcr.io/wallaroolabs/mlflow-deploy:v2023.3.0-main-3509’,
‘status’: ‘ready’}
Model Upload Complete
With that, the model upload is complete and can be deployed into a Wallaroo pipeline.
3.2 - Wallaroo SDK Upload Tutorial: Hugging Face Zero Shot Classification
How to upload a Hugging Face Zero Shot Classification model to Wallaroo via the Wallaroo SDK.
The Wallaroo 101 tutorial can be downloaded as part of the Wallaroo Tutorials repository.
Wallaroo Model Upload via the Wallaroo SDK: Hugging Face Zero Shot Classification
The following tutorial demonstrates how to upload a Hugging Face Zero Shot model to a Wallaroo instance.
Tutorial Goals
Demonstrate the following:
- Upload a Hugging Face Zero Shot Model to a Wallaroo instance.
- Create a pipeline and add the model as a pipeline step.
- Perform a sample inference.
Prerequisites
- A Wallaroo version 2023.2.1 or above instance.
References
- Wallaroo MLOps API Essentials Guide: Model Upload and Registrations
- Wallaroo API Connection Guide
- DNS Integration Guide
Tutorial Steps
Import Libraries
The first step is to import the libraries we’ll be using. These are included by default in the Wallaroo instance’s JupyterHub service.
import json
import os
import wallaroo
from wallaroo.pipeline import Pipeline
from wallaroo.deployment_config import DeploymentConfigBuilder
from wallaroo.framework import Framework
from wallaroo.object import EntityNotFoundError
import os
os.environ["MODELS_ENABLED"] = "true"
import pyarrow as pa
import numpy as np
import pandas as pd
Open a Connection to Wallaroo
The next step is connect to Wallaroo through the Wallaroo client. The Python library is included in the Wallaroo install and available through the Jupyter Hub interface provided with your Wallaroo environment.
This is accomplished using the wallaroo.Client() command, which provides a URL to grant the SDK permission to your specific Wallaroo environment. When displayed, enter the URL into a browser and confirm permissions. Store the connection into a variable that can be referenced later.
If logging into the Wallaroo instance through the internal JupyterHub service, use wl = wallaroo.Client(). If logging in externally, update the wallarooPrefix and wallarooSuffix variables with the proper DNS information. For more information on Wallaroo DNS settings, see the Wallaroo DNS Integration Guide.
wl = wallaroo.Client()
Set Variables and Helper Functions
We’ll set the name of our workspace, pipeline, models and files. Workspace names must be unique across the Wallaroo workspace. For this, we’ll add in a randomly generated 4 characters to the workspace name to prevent collisions with other users’ workspaces. If running this tutorial, we recommend hard coding the workspace name so it will function in the same workspace each time it’s run.
We’ll set up some helper functions that will either use existing workspaces and pipelines, or create them if they do not already exist.
def get_workspace(name):
workspace = None
for ws in wl.list_workspaces():
if ws.name() == name:
workspace= ws
if(workspace == None):
workspace = wl.create_workspace(name)
return workspace
def get_pipeline(name):
try:
pipeline = wl.pipelines_by_name(name)[0]
except EntityNotFoundError:
pipeline = wl.build_pipeline(name)
return pipeline
import string
import random
# make a random 4 character suffix to prevent overwriting other user's workspaces
suffix= ''.join(random.choice(string.ascii_lowercase) for i in range(4))
workspace_name = f'hf-zero-shot-classification{suffix}'
pipeline_name = f'hf-zero-shot-classification'
model_name = 'hf-zero-shot-classification'
model_file_name = './models/model-auto-conversion_hugging-face_dummy-pipelines_zero-shot-classification-pipeline.zip'
Create Workspace and Pipeline
We will now create the Wallaroo workspace to store our model and set it as the current workspace. Future commands will default to this workspace for pipeline creation, model uploads, etc. We’ll create our Wallaroo pipeline to deploy our model.
workspace = get_workspace(workspace_name)
wl.set_current_workspace(workspace)
pipeline = get_pipeline(pipeline_name)
Configure Data Schemas
The following parameters are required for Hugging Face models. Note that while some fields are considered as optional for the upload_model method, they are required for proper uploading of a Hugging Face model to Wallaroo.
| Parameter | Type | Description |
|---|---|---|
name | string (Required) | The name of the model. Model names are unique per workspace. Models that are uploaded with the same name are assigned as a new version of the model. |
path | string (Required) | The path to the model file being uploaded. |
framework | string (Upload Method Optional, Hugging Face model Required) | Set as the framework. |
input_schema | pyarrow.lib.Schema (Upload Method Optional, Hugging Face model Required) | The input schema in Apache Arrow schema format. |
output_schema | pyarrow.lib.Schema (Upload Method Optional, Hugging Face model Required) | The output schema in Apache Arrow schema format. |
convert_wait | bool (Upload Method Optional, Hugging Face model Optional) (Default: True) |
|
The input and output schemas will be configured for the data inputs and outputs. More information on the available inputs under the official 🤗 Hugging Face source code.
input_schema = pa.schema([
pa.field('inputs', pa.string()), # required
pa.field('candidate_labels', pa.list_(pa.string(), list_size=2)), # required
pa.field('hypothesis_template', pa.string()), # optional
pa.field('multi_label', pa.bool_()), # optional
])
output_schema = pa.schema([
pa.field('sequence', pa.string()),
pa.field('scores', pa.list_(pa.float64(), list_size=2)), # same as number of candidate labels, list_size can be skipped by may result in slightly worse performance
pa.field('labels', pa.list_(pa.string(), list_size=2)), # same as number of candidate labels, list_size can be skipped by may result in slightly worse performance
])
Upload Model
The model will be uploaded with the framework set as Framework.HUGGING_FACE_ZERO_SHOT_CLASSIFICATION.
framework=Framework.HUGGING_FACE_ZERO_SHOT_CLASSIFICATION
model = wl.upload_model(model_name,
model_file_name,
framework=framework,
input_schema=input_schema,
output_schema=output_schema,
convert_wait=True)
model
Waiting for model conversion... It may take up to 10.0min.
Model is Pending conversion..Converting.............Ready.
| Name | hf-zero-shot-classification |
| Version | 56bd73be-74d1-46c9-81ad-f2aa7b0c3466 |
| File Name | model-auto-conversion_hugging-face_dummy-pipelines_zero-shot-classification-pipeline.zip |
| SHA | 3dcc14dd925489d4f0a3960e90a7ab5917ab685ce955beca8924aa7bb9a69398 |
| Status | ready |
| Image Path | proxy.replicated.com/proxy/wallaroo/ghcr.io/wallaroolabs/mlflow-deploy:v2023.3.0-main-3509 |
| Updated At | 2023-13-Jul 16:24:31 |
model.config().runtime()
'mlflow'
Deploy Pipeline
The model is uploaded and ready for use. We’ll add it as a step in our pipeline, then deploy the pipeline. For this example we’re allocated 0.25 cpu and 4 Gi RAM to the pipeline through the pipeline’s deployment configuration.
deployment_config = DeploymentConfigBuilder() \
.cpus(0.25).memory('1Gi') \
.build()
pipeline = get_pipeline(pipeline_name)
# clear the pipeline if used previously
pipeline.undeploy()
pipeline.clear()
pipeline.add_model_step(model)
pipeline.deploy(deployment_config=deployment_config)
pipeline.status()
{'status': 'Running',
'details': [],
'engines': [{'ip': '10.244.9.82',
'name': 'engine-7c9767fbcc-t9f9d',
'status': 'Running',
'reason': None,
'details': [],
'pipeline_statuses': {'pipelines': [{'id': 'hf-zero-shot-classification',
'status': 'Running'}]},
'model_statuses': {'models': [{'name': 'hf-zero-shot-classification',
'version': '56bd73be-74d1-46c9-81ad-f2aa7b0c3466',
'sha': '3dcc14dd925489d4f0a3960e90a7ab5917ab685ce955beca8924aa7bb9a69398',
'status': 'Running'}]}}],
'engine_lbs': [{'ip': '10.244.9.81',
'name': 'engine-lb-584f54c899-kz67n',
'status': 'Running',
'reason': None,
'details': []}],
'sidekicks': [{'ip': '10.244.9.79',
'name': 'engine-sidekick-hf-zero-shot-classification-251-5874655d474f5zt',
'status': 'Running',
'reason': None,
'details': [],
'statuses': '\n'}]}
Run Inference
A sample inference will be run. First the pandas DataFrame used for the inference is created, then the inference run through the pipeline’s infer method.
input_data = {
"inputs": ["this is a test", "this is another test"], # required
"candidate_labels": [["english", "german"], ["english", "german"]], # optional: using the defaults, similar to not passing this parameter
"hypothesis_template": ["This example is {}.", "This example is {}."], # optional: using the defaults, similar to not passing this parameter
"multi_label": [False, False], # optional: using the defaults, similar to not passing this parameter
}
dataframe = pd.DataFrame(input_data)
dataframe
| inputs | candidate_labels | hypothesis_template | multi_label | |
|---|---|---|---|---|
| 0 | this is a test | [english, german] | This example is {}. | False |
| 1 | this is another test | [english, german] | This example is {}. | False |
%time
pipeline.infer(dataframe)
CPU times: user 3 µs, sys: 0 ns, total: 3 µs
Wall time: 3.81 µs
| time | in.candidate_labels | in.hypothesis_template | in.inputs | in.multi_label | out.labels | out.scores | out.sequence | check_failures | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 2023-07-13 16:25:46.100 | [english, german] | This example is {}. | this is a test | False | [english, german] | [0.5040545463562012, 0.49594542384147644] | this is a test | 0 |
| 1 | 2023-07-13 16:25:46.100 | [english, german] | This example is {}. | this is another test | False | [english, german] | [0.5037839412689209, 0.4962160289287567] | this is another test | 0 |
Undeploy Pipelines
With the tutorial complete, the pipeline is undeployed to return the resources back to the cluster.
pipeline.undeploy()
| name | hf-zero-shot-classification |
|---|---|
| created | 2023-07-13 16:25:22.793477+00:00 |
| last_updated | 2023-07-13 16:25:22.793477+00:00 |
| deployed | False |
| tags | |
| versions | dedeaa61-8c3f-4a7d-8ac4-642b52d7afde |
| steps | hf-zero-shot-classification |
4 - Wallaroo SDK Upload Tutorials: Python Step Shape
How to upload different Python Step Shape models to Wallaroo.
The following tutorials cover how to upload sample Python Step Shape models into a Wallaroo instance.
Python scripts are uploaded to Wallaroo and and treated like an ML Models in Pipeline steps. These will be referred to as Python steps.
Python steps can include:
- Preprocessing steps to prepare the data received to be handed to ML Model deployed as another Pipeline step.
- Postprocessing steps to take data output by a ML Model as part of a Pipeline step, and prepare the data to be received by some other data store or entity.
- A model contained within a Python script.
In all of these, the requirements for uploading a Python script as a ML Model in Wallaroo are the same.
| Parameter | Description |
|---|---|
| Web Site | https://www.python.org/ |
| Supported Libraries | python==3.8 |
| Framework | Framework.PYTHON aka python |
| Runtime | Native aka python |
Python models uploaded to Wallaroo are executed as a native runtime.
Note that Python models - aka “Python steps” - are standalone python scripts that use the python libraries natively supported by the Wallaroo platform. These are used for either simple model deployment (such as ARIMA Statsmodels), or data formatting such as the postprocessing steps. A Wallaroo Python model will be composed of one Python script that matches the Wallaroo requirements.
This is contrasted with Arbitrary Python models, also known as Bring Your Own Predict (BYOP) allow for custom model deployments with supporting scripts and artifacts. These are used with pre-trained models (PyTorch, Tensorflow, etc) along with whatever supporting artifacts they require. Supporting artifacts can include other Python modules, model files, etc. These are zipped with all scripts, artifacts, and a requirements.txt file that indicates what other Python models need to be imported that are outside of the typical Wallaroo platform.
Python Models Requirements
Python models uploaded to Wallaroo are Python scripts that must include the wallaroo_json method as the entry point for the Wallaroo engine to use it as a Pipeline step.
This method receives the results of the previous Pipeline step, and its return value will be used in the next Pipeline step.
If the Python model is the first step in the pipeline, then it will be receiving the inference request data (for example: a preprocessing step). If it is the last step in the pipeline, then it will be the data returned from the inference request.
In the example below, the Python model is used as a post processing step for another ML model. The Python model expects to receive data from a ML Model who’s output is a DataFrame with the column dense_2. It then extracts the values of that column as a list, selects the first element, and returns a DataFrame with that element as the value of the column output.
def wallaroo_json(data: pd.DataFrame):
print(data)
return [{"output": [data["dense_2"].to_list()[0][0]]}]
In line with other Wallaroo inference results, the outputs of a Python step that returns a pandas DataFrame or Arrow Table will be listed in the out. metadata, with all inference outputs listed as out.{variable 1}, out.{variable 2}, etc. In the example above, this results the output field as the out.output field in the Wallaroo inference result.
| time | in.tensor | out.output | check_failures | |
|---|---|---|---|---|
| 0 | 2023-06-20 20:23:28.395 | [0.6878518042, 0.1760734021, -0.869514083, 0.3.. | [12.886651039123535] | 0 |
4.1 - Python Model Shape Upload to Wallaroo with the Wallaroo SDK
How to upload a Python Step Shape model to Wallaroo via the SDK
This tutorial can be downloaded as part of the Wallaroo Tutorials repository.
Python Model Upload to Wallaroo
Python scripts can be deployed to Wallaroo as Python Models. These are treated like other models, and are used for:
- ML Models: Models written entirely in Python script.
- Data Formatting: Typically preprocess or post process modules that shape incoming data into what a ML model expects, or receives data output by a ML model and changes the data for other processes to accept.
Models are added to Wallaroo pipelines as pipeline steps, with the data from the previous step submitted to the next one. Python steps require the entry method wallaroo_json. These methods should be structured to receive and send pandas DataFrames as the inputs and outputs.
This allows inference requests to a Wallaroo pipeline to receive pandas DataFrames or Apache Arrow tables, and return the same for consistent results.
This tutorial will:
- Create a Wallaroo workspace and pipeline.
- Upload the sample Python model and ONNX model.
- Demonstrate the outputs of the ONNX model to an inference request.
- Demonstrate the functionality of the Python model in reshaping data after an inference request.
- Use both the ONNX model and the Python model together as pipeline steps to perform an inference request and export the data for use.
Prerequisites
- A Wallaroo version 2023.2.1 or above instance.
References
Tutorial Steps
Import Libraries
We’ll start with importing the libraries we need for the tutorial. The main libraries used are:
- Wallaroo: To connect with the Wallaroo instance and perform the MLOps commands.
pyarrow: Used for formatting the data.pandas: Used for pandas DataFrame tables.
import wallaroo
from wallaroo.object import EntityNotFoundError
from wallaroo.framework import Framework
from wallaroo.deployment_config import DeploymentConfigBuilder
import pandas as pd
#import os
# import json
import pyarrow as pa
Connect to the Wallaroo Instance through the User Interface
The next step is to connect to Wallaroo through the Wallaroo client. The Python library is included in the Wallaroo install and available through the Jupyter Hub interface provided with your Wallaroo environment.
This is accomplished using the wallaroo.Client() command, which provides a URL to grant the SDK permission to your specific Wallaroo environment. When displayed, enter the URL into a browser and confirm permissions. Store the connection into a variable that can be referenced later.
If logging into the Wallaroo instance through the internal JupyterHub service, use wl = wallaroo.Client(). For more information on Wallaroo Client settings, see the Client Connection guide.
# Login through local Wallaroo instance
wl = wallaroo.Client()
Set Variables and Helper Functions
We’ll set the name of our workspace, pipeline, models and files. Workspace names must be unique across the Wallaroo workspace. For this, we’ll add in a randomly generated 4 characters to the workspace name to prevent collisions with other users’ workspaces. If running this tutorial, we recommend hard coding the workspace name so it will function in the same workspace each time it’s run.
We’ll set up some helper functions that will either use existing workspaces and pipelines, or create them if they do not already exist.
import string
import random
# make a random 4 character suffix to prevent overwriting other user's workspaces
suffix= ''.join(random.choice(string.ascii_lowercase) for i in range(4))
workspace_name = f'python-demo{suffix}'
pipeline_name = f'python-step-demo-pipeline'
onnx_model_name = 'house-price-sample'
onnx_model_file_name = './models/house_price_keras.onnx'
python_model_name = 'python-step'
python_model_file_name = './models/step.py'
def get_workspace(name):
workspace = None
for ws in wl.list_workspaces():
if ws.name() == name:
workspace= ws
if(workspace == None):
workspace = wl.create_workspace(name)
return workspace
def get_pipeline(name):
try:
pipeline = wl.pipelines_by_name(name)[0]
except EntityNotFoundError:
pipeline = wl.build_pipeline(name)
return pipeline
Create a New Workspace
For our tutorial, we’ll create the workspace, set it as the current workspace, then the pipeline we’ll add our models to.
Create New Workspace References
- Wallaroo SDK Essentials Guide: Workspace Management
- Wallaroo SDK Essentials Guide: Pipeline Management
workspace = get_workspace(workspace_name)
wl.set_current_workspace(workspace)
pipeline = get_pipeline(pipeline_name)
pipeline
| name | python-step-demo-pipeline |
|---|---|
| created | 2023-07-13 17:24:56.476527+00:00 |
| last_updated | 2023-07-13 17:27:07.599003+00:00 |
| deployed | False |
| tags | |
| versions | 58a293f0-30ab-43f4-a22a-be2d98ae6850, bbc3f22f-a2de-4f33-bc7a-0470db060b0e, 0d5be505-57dd-4098-ba81-896083633364, dbd52766-9448-4f1c-938f-2e38e7b7ce1c |
| steps | house-price-sample |
Model Descriptions
We have two models we’ll be using.
./models/house_price_keras.onnx: A ML model trained to forecast hour prices based on inputs. This forecast is stored in the columndense_2../models/step.py: A Python script that accepts the data from the house price model, and reformats the output. We’ll be using it as a post-processing step.
For the Python step, it contains the method wallaroo_json as the entry point used by Wallaroo when deployed as a pipeline step. Our sample script has the following:
# take a dataframe output of the house price model, and reformat the `dense_2`
# column as `output`
def wallaroo_json(data: pd.DataFrame):
print(data)
return [{"output": [data["dense_2"].to_list()[0][0]]}]
As seen from the description, all those function will do it take the DataFrame output of the house price model, and output a DataFrame replacing the first element in the list from column dense_2 with output.
Upload Models
Both of these models will be uploaded to our current workspace using the method upload_model(name, path, framework).configure(framework, input_schema, output_schema).
- For
./models/house_price_keras.onnx, we will specify it asFramework.ONNX. We do not need to specify the input and output schemas. - For
./models/step.py, we will set the input and output schemas in the requiredpyarrow.lib.Schemaformat.
Upload Model References
- Wallaroo SDK Essentials Guide: Model Uploads and Registrations: ONNX
- Wallaroo SDK Essentials Guide: Model Uploads and Registrations: Python Models
house_price_model = (wl.upload_model(onnx_model_name,
onnx_model_file_name,
framework=Framework.ONNX)
.configure('onnx')
)
input_schema = pa.schema([
pa.field('dense_2', pa.list_(pa.float64()))
])
output_schema = pa.schema([
pa.field('output', pa.list_(pa.float64()))
])
step = (wl.upload_model(python_model_name,
python_model_file_name,
framework=Framework.PYTHON)
.configure(
'python',
input_schema=input_schema,
output_schema=output_schema
)
)
Pipeline Steps
With our models uploaded, we’ll perform different configurations of the pipeline steps.
First we’ll add just the house price model to the pipeline, deploy it, and submit a sample inference.
# used to restrict the resources needed for this demonstration
deployment_config = DeploymentConfigBuilder() \
.cpus(0.25).memory('1Gi') \
.build()
# clear the pipeline if this tutorial was run before
pipeline.undeploy()
pipeline.clear()
pipeline.add_model_step(house_price_model)
pipeline.deploy(deployment_config=deployment_config)
| name | python-step-demo-pipeline |
|---|---|
| created | 2023-07-13 21:58:10.584660+00:00 |
| last_updated | 2023-07-13 21:58:10.584660+00:00 |
| deployed | True |
| tags | |
| versions | a4b11320-1867-4801-94bb-66ca5c625502 |
| steps | house-price-sample |
## sample inference data
data = pd.DataFrame.from_dict({"tensor": [[0.6878518042239091,
0.17607340208535074,
-0.8695140830357148,
0.34638762962802144,
-0.0916270832672289,
-0.022063226781124278,
-0.13969884765926363,
1.002792335666138,
-0.3067449033633758,
0.9272000630461978,
0.28326687982544635,
0.35935375728372815,
-0.682562654045523,
0.532642794275658,
-0.22705189652659302,
0.5743846356405602,
-0.18805086358065454]]})
results = pipeline.infer(data)
display(results)
| time | in.tensor | out.dense_2 | check_failures | |
|---|---|---|---|---|
| 0 | 2023-07-13 21:58:21.397 | [0.6878518042, 0.1760734021, -0.869514083, 0.3... | [12.886651] | 0 |
Inference with Pipeline Step
Our inference result had the results in the out.dense_2 column. We’ll clear the pipeline, then add in as the pipeline step just the Python postprocessing step we’ve created. Then for our inference request, we’ll just submit the output of the house price model. Our result should be the first element in the array returned in the out.output column.
pipeline.clear()
pipeline.add_model_step(step)
pipeline.deploy(deployment_config=deployment_config)
| name | python-step-demo-pipeline |
|---|---|
| created | 2023-07-13 21:58:10.584660+00:00 |
| last_updated | 2023-07-13 21:59:47.248922+00:00 |
| deployed | True |
| tags | |
| versions | 1b0969ac-d0cb-42f0-96ff-a5b4a1cb5702, a75268c3-7a5d-4c27-b3e9-3ae79ad46363, a4b11320-1867-4801-94bb-66ca5c625502 |
| steps | house-price-sample |
data = pd.DataFrame.from_dict({"dense_2": [12.886651]})
python_result = pipeline.infer(data)
display(python_result)
| time | in.dense_2 | out.output | check_failures | |
|---|---|---|---|---|
| 0 | 2023-07-13 21:59:53.065 | 12.886651 | [12.886651] | 0 |
Putting Both Models Together
Now we’ll do one last pipeline deployment with 2 steps:
- First the house price model that outputs the inference result into
dense_2. - Second the python step so it will accept the output of the house price model, and reshape it into
output.
import datetime
inference_start = datetime.datetime.now()
pipeline.undeploy()
pipeline.clear()
pipeline.add_model_step(house_price_model)
pipeline.add_model_step(step)
pipeline.deploy(deployment_config=deployment_config)
data = pd.DataFrame.from_dict({"tensor": [[0.6878518042239091,
0.17607340208535074,
-0.8695140830357148,
0.34638762962802144,
-0.0916270832672289,
-0.022063226781124278,
-0.13969884765926363,
1.002792335666138,
-0.3067449033633758,
0.9272000630461978,
0.28326687982544635,
0.35935375728372815,
-0.682562654045523,
0.532642794275658,
-0.22705189652659302,
0.5743846356405602,
-0.18805086358065454]]})
results = pipeline.infer(data)
display(results)
| time | in.tensor | out.output | check_failures | |
|---|---|---|---|---|
| 0 | 2023-07-13 22:05:58.341 | [0.6878518042, 0.1760734021, -0.869514083, 0.3... | [12.886651039123535] | 0 |
Pipeline Logs
As the data was exported by the pipeline step as a pandas DataFrame, it will be reflected in the pipeline logs. We’ll retrieve the most recent log from our most recent inference.
inference_end = datetime.datetime.now()
pipeline.logs(start_datetime=inference_start, end_datetime=inference_end)
| time | in.tensor | out.output | check_failures | |
|---|---|---|---|---|
| 0 | 2023-07-13 22:05:58.341 | [0.6878518042, 0.1760734021, -0.869514083, 0.3... | [12.886651039123535] | 0 |
Undeploy the Pipeline
With our tutorial complete, we’ll undeploy the pipeline and return the resources back to the cluster.
This process demonstrated how to structure a postprocessing Python script as a Wallaroo Pipeline step. This can be used for pre or post processing, Python based models, and other use cases.
pipeline.undeploy()
| name | python-step-demo-pipeline |
|---|---|
| created | 2023-07-13 21:58:10.584660+00:00 |
| last_updated | 2023-07-13 22:05:41.759261+00:00 |
| deployed | False |
| tags | |
| versions | a232bd5a-bdcc-4c33-a0fe-515508c7405f, e7012369-90b5-4127-bd25-70f7c7aa65ba, 6a84493f-cae6-458a-be7c-8160517e7b18, 1b0969ac-d0cb-42f0-96ff-a5b4a1cb5702, a75268c3-7a5d-4c27-b3e9-3ae79ad46363, a4b11320-1867-4801-94bb-66ca5c625502 |
| steps | house-price-sample |
5 - Wallaroo SDK Upload Tutorials: Pytorch
How to upload different Pytorch models to Wallaroo.
The following tutorials cover how to upload sample Pytorch models.
| Parameter | Description |
|---|---|
| Web Site | https://pytorch.org/ |
| Supported Libraries |
|
| Framework | Framework.PYTORCH aka pytorch |
| Supported File Types | pt ot pth in TorchScript format |
| Runtime | Containerized aka mlflow |
5.1 - Wallaroo SDK Upload Tutorial: Pytorch Single IO
How to upload a Pytorch model with single input/output to Wallaroo
This tutorial can be downloaded as part of the Wallaroo Tutorials repository.
Wallaroo Model Upload via the Wallaroo SDK: Pytorch Single Input Output
The following tutorial demonstrates how to upload a Pytorch Single Input Output model to a Wallaroo instance.
Tutorial Goals
Demonstrate the following:
- Upload a Pytorch Single Input Output to a Wallaroo instance.
- Create a pipeline and add the model as a pipeline step.
- Perform a sample inference.
Prerequisites
- A Wallaroo version 2023.2.1 or above instance.
References
- Wallaroo MLOps API Essentials Guide: Model Upload and Registrations
- Wallaroo API Connection Guide
- DNS Integration Guide
Tutorial Steps
Import Libraries
The first step is to import the libraries we’ll be using. These are included by default in the Wallaroo instance’s JupyterHub service.
import json
import os
import pickle
import wallaroo
from wallaroo.pipeline import Pipeline
from wallaroo.deployment_config import DeploymentConfigBuilder
from wallaroo.object import EntityNotFoundError
from wallaroo.framework import Framework
import os
os.environ["MODELS_ENABLED"] = "true"
import pyarrow as pa
import numpy as np
import pandas as pd
Open a Connection to Wallaroo
The next step is connect to Wallaroo through the Wallaroo client. The Python library is included in the Wallaroo install and available through the Jupyter Hub interface provided with your Wallaroo environment.
This is accomplished using the wallaroo.Client() command, which provides a URL to grant the SDK permission to your specific Wallaroo environment. When displayed, enter the URL into a browser and confirm permissions. Store the connection into a variable that can be referenced later.
If logging into the Wallaroo instance through the internal JupyterHub service, use wl = wallaroo.Client(). If logging in externally, update the wallarooPrefix and wallarooSuffix variables with the proper DNS information. For more information on Wallaroo DNS settings, see the Wallaroo DNS Integration Guide.
wl = wallaroo.Client()
wallarooPrefix = ""
wallarooSuffix = "autoscale-uat-ee.wallaroo.dev"
wl = wallaroo.Client(api_endpoint=f"https://{wallarooPrefix}api.{wallarooSuffix}",
auth_endpoint=f"https://{wallarooPrefix}keycloak.{wallarooSuffix}",
auth_type="sso")
Set Variables and Helper Functions
We’ll set the name of our workspace, pipeline, models and files. Workspace names must be unique across the Wallaroo workspace. For this, we’ll add in a randomly generated 4 characters to the workspace name to prevent collisions with other users’ workspaces. If running this tutorial, we recommend hard coding the workspace name so it will function in the same workspace each time it’s run.
We’ll set up some helper functions that will either use existing workspaces and pipelines, or create them if they do not already exist.
def get_workspace(name):
workspace = None
for ws in wl.list_workspaces():
if ws.name() == name:
workspace= ws
if(workspace == None):
workspace = wl.create_workspace(name)
return workspace
def get_pipeline(name):
try:
pipeline = wl.pipelines_by_name(name)[0]
except EntityNotFoundError:
pipeline = wl.build_pipeline(name)
return pipeline
import string
import random
# make a random 4 character suffix to prevent overwriting other user's workspaces
suffix= ''.join(random.choice(string.ascii_lowercase) for i in range(4))
workspace_name = f'pytorch-single-io{suffix}'
pipeline_name = f'pytorch-single-io'
model_name = 'pytorch-single-io'
model_file_name = "./models/model-auto-conversion_pytorch_single_io_model.pt"
Create Workspace and Pipeline
We will now create the Wallaroo workspace to store our model and set it as the current workspace. Future commands will default to this workspace for pipeline creation, model uploads, etc. We’ll create our Wallaroo pipeline to deploy our model.
workspace = get_workspace(workspace_name)
wl.set_current_workspace(workspace)
pipeline = get_pipeline(pipeline_name)
Configure Data Schemas
The following parameters are required for PyTorch models. Note that while some fields are considered as optional for the upload_model method, they are required for proper uploading of a PyTorch model to Wallaroo.
| Parameter | Type | Description |
|---|---|---|
name | string (Required) | The name of the model. Model names are unique per workspace. Models that are uploaded with the same name are assigned as a new version of the model. |
path | string (Required) | The path to the model file being uploaded. |
framework | string (Upload Method Optional, PyTorch model Required) | Set as the Framework.PyTorch. |
input_schema | pyarrow.lib.Schema (Upload Method Optional, PyTorch model Required) | The input schema in Apache Arrow schema format. |
output_schema | pyarrow.lib.Schema (Upload Method Optional, PyTorch model Required) | The output schema in Apache Arrow schema format. |
convert_wait | bool (Upload Method Optional, PyTorch model Optional) (Default: True) |
|
Once the upload process starts, the model is containerized by the Wallaroo instance. This process may take up to 10 minutes.
input_schema = pa.schema([
pa.field('input', pa.list_(pa.float64(), list_size=10))
])
output_schema = pa.schema([
pa.field('output', pa.list_(pa.float64(), list_size=1))
])
Upload Model
The model will be uploaded with the framework set as Framework.PYTORCH.
framework=Framework.PYTORCH
model = wl.upload_model(model_name,
model_file_name,
framework=framework,
input_schema=input_schema,
output_schema=output_schema
)
model
Waiting for model conversion... It may take up to 10.0min.
Model is Pending conversion..Converting.........Ready.
| Name | pytorch-single-io |
| Version | 60401663-c752-4448-b78d-7e4432e764f2 |
| File Name | model-auto-conversion_pytorch_single_io_model.pt |
| SHA | 23bdbafc51c3df7ac84e5f8b2833c592d7da2b27715a7da3e45bf732ea85b8bb |
| Status | ready |
| Image Path | proxy.replicated.com/proxy/wallaroo/ghcr.io/wallaroolabs/mlflow-deploy:v2023.3.0-main-3509 |
| Updated At | 2023-13-Jul 17:44:21 |
model.config().runtime()
'mlflow'
Deploy Pipeline
The model is uploaded and ready for use. We’ll add it as a step in our pipeline, then deploy the pipeline. For this example we’re allocated 0.25 cpu and 4 Gi RAM to the pipeline through the pipeline’s deployment configuration.
deployment_config = DeploymentConfigBuilder() \
.cpus(0.25).memory('1Gi') \
.build()
# clear the pipeline if it was used before
pipeline.undeploy()
pipeline.clear()
pipeline.add_model_step(model)
pipeline.deploy(deployment_config=deployment_config)
pipeline.status()
{'status': 'Running',
'details': [],
'engines': [{'ip': '10.244.9.174',
'name': 'engine-d4c87f97-bxgtn',
'status': 'Running',
'reason': None,
'details': [],
'pipeline_statuses': {'pipelines': [{'id': 'pytorch-single-io',
'status': 'Running'}]},
'model_statuses': {'models': [{'name': 'pytorch-single-io',
'version': '60401663-c752-4448-b78d-7e4432e764f2',
'sha': '23bdbafc51c3df7ac84e5f8b2833c592d7da2b27715a7da3e45bf732ea85b8bb',
'status': 'Running'}]}}],
'engine_lbs': [{'ip': '10.244.9.172',
'name': 'engine-lb-584f54c899-vd24j',
'status': 'Running',
'reason': None,
'details': []}],
'sidekicks': [{'ip': '10.244.9.173',
'name': 'engine-sidekick-pytorch-single-io-267-74ff565f46-r64l9',
'status': 'Running',
'reason': None,
'details': [],
'statuses': '\n'}]}
Run Inference
A sample inference will be run. First the pandas DataFrame used for the inference is created, then the inference run through the pipeline’s infer method.
mock_inference_data = np.random.rand(10, 10)
mock_dataframe = pd.DataFrame({"input": mock_inference_data.tolist()})
pipeline.infer(mock_dataframe)
| time | in.input | out.output | check_failures | |
|---|---|---|---|---|
| 0 | 2023-07-13 17:47:36.920 | [0.9793556002, 0.7185564171, 0.3036665062, 0.2... | [-0.17520469427108765] | 0 |
| 1 | 2023-07-13 17:47:36.920 | [0.1405072075, 0.6040986499, 0.4725817666, 0.9... | [-0.17446672916412354] | 0 |
| 2 | 2023-07-13 17:47:36.920 | [0.3610862346, 0.0217239609, 0.5346289561, 0.9... | [-0.18389971554279327] | 0 |
| 3 | 2023-07-13 17:47:36.920 | [0.9739280826, 0.4035630357, 0.7590709887, 0.7... | [-0.1760045289993286] | 0 |
| 4 | 2023-07-13 17:47:36.920 | [0.6488859167, 0.8076425858, 0.3775445684, 0.7... | [-0.17518186569213867] | 0 |
| 5 | 2023-07-13 17:47:36.920 | [0.7711169349, 0.3743345638, 0.3789860132, 0.6... | [-0.11498415470123291] | 0 |
| 6 | 2023-07-13 17:47:36.920 | [0.4095596117, 0.0426551485, 0.9338234503, 0.2... | [0.06910310685634613] | 0 |
| 7 | 2023-07-13 17:47:36.920 | [0.0986111718, 0.4338122288, 0.2258331516, 0.3... | [0.0066347867250442505] | 0 |
| 8 | 2023-07-13 17:47:36.920 | [0.2659302336, 0.9380703173, 0.7125008616, 0.9... | [-0.061735235154628754] | 0 |
| 9 | 2023-07-13 17:47:36.920 | [0.1378982605, 0.6003082091, 0.7641944662, 0.9... | [-0.1069975420832634] | 0 |
Undeploy Pipelines
With the tutorial complete, the pipeline is undeployed to return the resources back to the cluster.
pipeline.undeploy()
| name | pytorch-single-io |
|---|---|
| created | 2023-07-13 17:43:23.742820+00:00 |
| last_updated | 2023-07-13 17:44:26.785226+00:00 |
| deployed | False |
| tags | |
| versions | 49fe2e5b-b043-4a9e-bf68-2054b09cc051, 7405b506-7cce-47be-be4c-98baf0d11f75 |
| steps | pytorch-single-io |
5.2 - Wallaroo SDK Upload Tutorial: Pytorch Multiple IO
How to upload a Pytorch model with Multiple input/output to Wallaroo
This tutorial can be downloaded as part of the Wallaroo Tutorials repository.
Wallaroo Model Upload via the Wallaroo SDK: Pytorch Multiple Input Output
The following tutorial demonstrates how to upload a Pytorch Multiple Input Output model to a Wallaroo instance.
Tutorial Goals
Demonstrate the following:
- Upload a Pytorch Multiple Input Output to a Wallaroo instance.
- Create a pipeline and add the model as a pipeline step.
- Perform a sample inference.
Prerequisites
- A Wallaroo version 2023.2.1 or above instance.
References
- Wallaroo MLOps API Essentials Guide: Model Upload and Registrations
- Wallaroo API Connection Guide
- DNS Integration Guide
Tutorial Steps
Import Libraries
The first step is to import the libraries we’ll be using. These are included by default in the Wallaroo instance’s JupyterHub service.
import json
import os
import pickle
import wallaroo
from wallaroo.pipeline import Pipeline
from wallaroo.deployment_config import DeploymentConfigBuilder
from wallaroo.object import EntityNotFoundError
from wallaroo.framework import Framework
import os
os.environ["MODELS_ENABLED"] = "true"
import pyarrow as pa
import numpy as np
import pandas as pd
Open a Connection to Wallaroo
The next step is connect to Wallaroo through the Wallaroo client. The Python library is included in the Wallaroo install and available through the Jupyter Hub interface provided with your Wallaroo environment.
This is accomplished using the wallaroo.Client() command, which provides a URL to grant the SDK permission to your specific Wallaroo environment. When displayed, enter the URL into a browser and confirm permissions. Store the connection into a variable that can be referenced later.
If logging into the Wallaroo instance through the internal JupyterHub service, use wl = wallaroo.Client(). If logging in externally, update the wallarooPrefix and wallarooSuffix variables with the proper DNS information. For more information on Wallaroo DNS settings, see the Wallaroo DNS Integration Guide.
wl = wallaroo.Client()
Set Variables and Helper Functions
We’ll set the name of our workspace, pipeline, models and files. Workspace names must be unique across the Wallaroo workspace. For this, we’ll add in a randomly generated 4 characters to the workspace name to prevent collisions with other users’ workspaces. If running this tutorial, we recommend hard coding the workspace name so it will function in the same workspace each time it’s run.
We’ll set up some helper functions that will either use existing workspaces and pipelines, or create them if they do not already exist.
def get_workspace(name):
workspace = None
for ws in wl.list_workspaces():
if ws.name() == name:
workspace= ws
if(workspace == None):
workspace = wl.create_workspace(name)
return workspace
def get_pipeline(name):
try:
pipeline = wl.pipelines_by_name(name)[0]
except EntityNotFoundError:
pipeline = wl.build_pipeline(name)
return pipeline
import string
import random
# make a random 4 character suffix to prevent overwriting other user's workspaces
suffix= ''.join(random.choice(string.ascii_lowercase) for i in range(4))
workspace_name = f'pytorch-multi-io{suffix}'
pipeline_name = f'pytorch-multi-io'
model_name = 'pytorch-multi-io'
model_file_name = "./models/model-auto-conversion_pytorch_multi_io_model.pt"
Create Workspace and Pipeline
We will now create the Wallaroo workspace to store our model and set it as the current workspace. Future commands will default to this workspace for pipeline creation, model uploads, etc. We’ll create our Wallaroo pipeline to deploy our model.
workspace = get_workspace(workspace_name)
wl.set_current_workspace(workspace)
pipeline = get_pipeline(pipeline_name)
Configure Data Schemas
The following parameters are required for PyTorch models. Note that while some fields are considered as optional for the upload_model method, they are required for proper uploading of a PyTorch model to Wallaroo.
| Parameter | Type | Description |
|---|---|---|
name | string (Required) | The name of the model. Model names are unique per workspace. Models that are uploaded with the same name are assigned as a new version of the model. |
path | string (Required) | The path to the model file being uploaded. |
framework | string (Upload Method Optional, PyTorch model Required) | Set as the Framework.PyTorch. |
input_schema | pyarrow.lib.Schema (Upload Method Optional, PyTorch model Required) | The input schema in Apache Arrow schema format. |
output_schema | pyarrow.lib.Schema (Upload Method Optional, PyTorch model Required) | The output schema in Apache Arrow schema format. |
convert_wait | bool (Upload Method Optional, PyTorch model Optional) (Default: True) |
|
Once the upload process starts, the model is containerized by the Wallaroo instance. This process may take up to 10 minutes.
input_schema = pa.schema([
pa.field('input_1', pa.list_(pa.float64(), list_size=10)),
pa.field('input_2', pa.list_(pa.float64(), list_size=5))
])
output_schema = pa.schema([
pa.field('output_1', pa.list_(pa.float64(), list_size=3)),
pa.field('output_2', pa.list_(pa.float64(), list_size=2))
])
Upload Model
The model will be uploaded with the framework set as Framework.PYTORCH.
model = wl.upload_model(model_name,
model_file_name,
framework=Framework.PYTORCH,
input_schema=input_schema,
output_schema=output_schema
)
model
Waiting for model conversion... It may take up to 10.0min.
Model is Pending conversion.Converting..........Ready.
| Name | pytorch-multi-io |
| Version | d503b511-7a0c-4c90-9cbc-022467886dcd |
| File Name | model-auto-conversion_pytorch_multi_io_model.pt |
| SHA | 792db9ee9f41aded3c1d4705f50ccdedd21cafb8b6232c03e4a849b6da1050a8 |
| Status | ready |
| Image Path | proxy.replicated.com/proxy/wallaroo/ghcr.io/wallaroolabs/mlflow-deploy:v2023.3.0-main-3509 |
| Updated At | 2023-13-Jul 17:40:39 |
model.config().runtime()
'mlflow'
Deploy Pipeline
The model is uploaded and ready for use. We’ll add it as a step in our pipeline, then deploy the pipeline. For this example we’re allocated 0.25 cpu and 4 Gi RAM to the pipeline through the pipeline’s deployment configuration.
deployment_config = DeploymentConfigBuilder() \
.cpus(0.25).memory('1Gi') \
.build()
# clear the pipeline if it was used before
pipeline.undeploy()
pipeline.clear()
pipeline.add_model_step(model)
pipeline.deploy(deployment_config=deployment_config)
pipeline.status()
{'status': 'Running',
'details': [],
'engines': [{'ip': '10.244.9.169',
'name': 'engine-7d8fbd4b74-kc5l5',
'status': 'Running',
'reason': None,
'details': [],
'pipeline_statuses': {'pipelines': [{'id': 'pytorch-multi-io',
'status': 'Running'}]},
'model_statuses': {'models': [{'name': 'pytorch-multi-io',
'version': 'd503b511-7a0c-4c90-9cbc-022467886dcd',
'sha': '792db9ee9f41aded3c1d4705f50ccdedd21cafb8b6232c03e4a849b6da1050a8',
'status': 'Running'}]}}],
'engine_lbs': [{'ip': '10.244.9.167',
'name': 'engine-lb-584f54c899-xb4wd',
'status': 'Running',
'reason': None,
'details': []}],
'sidekicks': [{'ip': '10.244.9.168',
'name': 'engine-sidekick-pytorch-multi-io-266-c9fdfd57c-r26jj',
'status': 'Running',
'reason': None,
'details': [],
'statuses': '\n'}]}
Run Inference
A sample inference will be run. First the pandas DataFrame used for the inference is created, then the inference run through the pipeline’s infer method.
mock_inference_data = [np.random.rand(10, 10), np.random.rand(10, 5)]
mock_dataframe = pd.DataFrame(
{
"input_1": mock_inference_data[0].tolist(),
"input_2": mock_inference_data[1].tolist(),
}
)
pipeline.infer(mock_dataframe)
| time | in.input_1 | in.input_2 | out.output_1 | out.output_2 | check_failures | |
|---|---|---|---|---|---|---|
| 0 | 2023-07-13 17:41:15.828 | [0.7193870373, 0.0442841786, 0.0050186971, 0.9... | [0.5665563078, 0.2719984279, 0.8020988158, 0.9... | [-0.054150406271219254, -0.08067788183689117, ... | [-0.0867157131433487, 0.03102545440196991] | 0 |
| 1 | 2023-07-13 17:41:15.828 | [0.3303183352, 0.7338588864, 0.4901244227, 0.4... | [0.0020920459, 0.7473108704, 0.4701280309, 0.8... | [-0.0814041793346405, -0.008595120161771774, 0... | [0.22059735655784607, -0.0954931378364563] | 0 |
| 2 | 2023-07-13 17:41:15.828 | [0.8350163099, 0.9301095252, 0.4634737661, 0.0... | [0.2042988348, 0.3131013315, 0.2396516618, 0.8... | [-0.0936204195022583, 0.07057543098926544, 0.2... | [0.07758928835391998, 0.02205061912536621] | 0 |
| 3 | 2023-07-13 17:41:15.828 | [0.9560662259, 0.7334543871, 0.8347215148, 0.5... | [0.0846331092, 0.4104567348, 0.9964352268, 0.7... | [-0.07443580776453018, 0.00262654572725296, 0.... | [0.08881741762161255, 0.184173583984375] | 0 |
| 4 | 2023-07-13 17:41:15.828 | [0.8893996022, 0.0422634898, 0.094115839, 0.30... | [0.7091750984, 0.2677670739, 0.797334875, 0.60... | [0.011080481112003326, -0.03954530879855156, 0... | [0.02079789713025093, -0.023370355367660522] | 0 |
| 5 | 2023-07-13 17:41:15.828 | [0.360097173, 0.5326510416, 0.7427586985, 0.73... | [0.4059651678, 0.8209608747, 0.6650853071, 0.5... | [-0.041532136499881744, -0.02947094291448593, ... | [0.19275487959384918, -0.09685075283050537] | 0 |
| 6 | 2023-07-13 17:41:15.828 | [0.8493053911, 0.9772701228, 0.1395685377, 0.6... | [0.5020254829, 0.664290124, 0.0900637878, 0.27... | [0.023206554353237152, -0.05458785593509674, 0... | [0.252506822347641, -0.056555017828941345] | 0 |
| 7 | 2023-07-13 17:41:15.828 | [0.1783516801, 0.7383490632, 0.8826853, 0.8707... | [0.197614553, 0.7345261372, 0.3909055798, 0.12... | [-0.007199503481388092, -0.008408397436141968,... | [0.15768739581108093, 0.10399264097213745] | 0 |
| 8 | 2023-07-13 17:41:15.828 | [0.7671391397, 0.4079364465, 0.763576349, 0.26... | [0.3169436757, 0.3800284784, 0.1143413322, 0.2... | [-0.027935631573200226, 0.08666972815990448, 0... | [0.25775399804115295, -0.042692944407463074] | 0 |
| 9 | 2023-07-13 17:41:15.828 | [0.8885134534, 0.2440000822, 0.56551096, 0.780... | [0.1742113245, 0.624024604, 0.267043414, 0.153... | [-0.004899069666862488, 0.04411523416638374, 0... | [0.22322586178779602, -0.12406840920448303] | 0 |
Undeploy Pipelines
With the tutorial complete, the pipeline is undeployed to return the resources back to the cluster.
pipeline.undeploy()
| name | pytorch-multi-io |
|---|---|
| created | 2023-07-13 17:38:02.341959+00:00 |
| last_updated | 2023-07-13 17:40:44.329100+00:00 |
| deployed | False |
| tags | |
| versions | 6867e6c5-7193-44d8-9756-4dfbc8b7db5c, 7b21d715-e95e-4557-abd1-a856eaea6e42 |
| steps | pytorch-multi-io |
6 - Wallaroo SDK Upload Tutorials: SKLearn
How to upload different SKLearn models to Wallaroo.
The following tutorials cover how to upload sample SKLearn models.
Sci-kit Learn aka SKLearn.
| Parameter | Description |
|---|---|
| Web Site | https://scikit-learn.org/stable/index.html |
| Supported Libraries |
|
| Framework | Framework.SKLEARN aka sklearn |
| Runtime | Containerized aka tensorflow / mlflow |
SKLearn Schema Inputs
SKLearn schema follows a different format than other models. To prevent inputs from being out of order, the inputs should be submitted in a single row in the order the model is trained to accept, with all of the data types being the same. For example, the following DataFrame has 4 columns, each column a float.
| sepal length (cm) | sepal width (cm) | petal length (cm) | petal width (cm) | |
|---|---|---|---|---|
| 0 | 5.1 | 3.5 | 1.4 | 0.2 |
| 1 | 4.9 | 3.0 | 1.4 | 0.2 |
For submission to an SKLearn model, the data input schema will be a single array with 4 float values.
input_schema = pa.schema([
pa.field('inputs', pa.list_(pa.float64(), list_size=4))
])
When submitting as an inference, the DataFrame is converted to rows with the column data expressed as a single array. The data must be in the same order as the model expects, which is why the data is submitted as a single array rather than JSON labeled columns: this insures that the data is submitted in the exact order as the model is trained to accept.
Original DataFrame:
| sepal length (cm) | sepal width (cm) | petal length (cm) | petal width (cm) | |
|---|---|---|---|---|
| 0 | 5.1 | 3.5 | 1.4 | 0.2 |
| 1 | 4.9 | 3.0 | 1.4 | 0.2 |
Converted DataFrame:
| inputs | |
|---|---|
| 0 | [5.1, 3.5, 1.4, 0.2] |
| 1 | [4.9, 3.0, 1.4, 0.2] |
SKLearn Schema Outputs
Outputs for SKLearn that are meant to be predictions or probabilities when output by the model are labeled in the output schema for the model when uploaded to Wallaroo. For example, a model that outputs either 1 or 0 as its output would have the output schema as follows:
output_schema = pa.schema([
pa.field('predictions', pa.int32())
])
When used in Wallaroo, the inference result is contained in the out metadata as out.predictions.
pipeline.infer(dataframe)
| time | in.inputs | out.predictions | check_failures | |
|---|---|---|---|---|
| 0 | 2023-07-05 15:11:29.776 | [5.1, 3.5, 1.4, 0.2] | 0 | 0 |
| 1 | 2023-07-05 15:11:29.776 | [4.9, 3.0, 1.4, 0.2] | 0 | 0 |
6.1 - Wallaroo SDK Upload Tutorial: SKLearn Clustering Kmeans
How to upload a SKLearn Clustering Kmeans to Wallaroo
This tutorial can be downloaded as part of the Wallaroo Tutorials repository.
Wallaroo Model Upload via the Wallaroo SDK: SKLearn Clustering KMeans
The following tutorial demonstrates how to upload a SKLearn Clustering KMeans model to a Wallaroo instance.
Tutorial Goals
Demonstrate the following:
- Upload a SKLearn Clustering KMeans model to a Wallaroo instance.
- Create a pipeline and add the model as a pipeline step.
- Perform a sample inference.
Prerequisites
- A Wallaroo version 2023.2.1 or above instance.
References
- Wallaroo MLOps API Essentials Guide: Model Upload and Registrations
- Wallaroo API Connection Guide
- DNS Integration Guide
Tutorial Steps
Import Libraries
The first step is to import the libraries we’ll be using. These are included by default in the Wallaroo instance’s JupyterHub service.
import json
import os
import pickle
import wallaroo
from wallaroo.pipeline import Pipeline
from wallaroo.deployment_config import DeploymentConfigBuilder
from wallaroo.object import EntityNotFoundError
from wallaroo.framework import Framework
import os
os.environ["MODELS_ENABLED"] = "true"
import pyarrow as pa
import numpy as np
import pandas as pd
Open a Connection to Wallaroo
The next step is connect to Wallaroo through the Wallaroo client. The Python library is included in the Wallaroo install and available through the Jupyter Hub interface provided with your Wallaroo environment.
This is accomplished using the wallaroo.Client() command, which provides a URL to grant the SDK permission to your specific Wallaroo environment. When displayed, enter the URL into a browser and confirm permissions. Store the connection into a variable that can be referenced later.
If logging into the Wallaroo instance through the internal JupyterHub service, use wl = wallaroo.Client(). If logging in externally, update the wallarooPrefix and wallarooSuffix variables with the proper DNS information. For more information on Wallaroo DNS settings, see the Wallaroo DNS Integration Guide.
wl = wallaroo.Client()
Set Variables and Helper Functions
We’ll set the name of our workspace, pipeline, models and files. Workspace names must be unique across the Wallaroo workspace. For this, we’ll add in a randomly generated 4 characters to the workspace name to prevent collisions with other users’ workspaces. If running this tutorial, we recommend hard coding the workspace name so it will function in the same workspace each time it’s run.
We’ll set up some helper functions that will either use existing workspaces and pipelines, or create them if they do not already exist.
def get_workspace(name):
workspace = None
for ws in wl.list_workspaces():
if ws.name() == name:
workspace= ws
if(workspace == None):
workspace = wl.create_workspace(name)
return workspace
def get_pipeline(name):
try:
pipeline = wl.pipelines_by_name(name)[0]
except EntityNotFoundError:
pipeline = wl.build_pipeline(name)
return pipeline
import string
import random
# make a random 4 character suffix to prevent overwriting other user's workspaces
suffix= ''.join(random.choice(string.ascii_lowercase) for i in range(4))
workspace_name = f'sklearn-clustering-kmeans{suffix}'
pipeline_name = f'sklearn-clustering-kmeans'
model_name = 'sklearn-clustering-kmeans'
model_file_name = "models/model-auto-conversion_sklearn_kmeans.pkl"
Create Workspace and Pipeline
We will now create the Wallaroo workspace to store our model and set it as the current workspace. Future commands will default to this workspace for pipeline creation, model uploads, etc. We’ll create our Wallaroo pipeline to deploy our model.
workspace = get_workspace(workspace_name)
wl.set_current_workspace(workspace)
pipeline = get_pipeline(pipeline_name)
Configure Data Schemas
SKLearn models are uploaded to Wallaroo through the Wallaroo Client upload_model method.
Upload SKLearn Model Parameters
The following parameters are required for SKLearn models. Note that while some fields are considered as optional for the upload_model method, they are required for proper uploading of a SKLearn model to Wallaroo.
| Parameter | Type | Description |
|---|---|---|
name | string (Required) | The name of the model. Model names are unique per workspace. Models that are uploaded with the same name are assigned as a new version of the model. |
path | string (Required) | The path to the model file being uploaded. |
framework | string (Upload Method Optional, SKLearn model Required) | Set as the Framework.SKLEARN. |
input_schema | pyarrow.lib.Schema (Upload Method Optional, SKLearn model Required) | The input schema in Apache Arrow schema format. |
output_schema | pyarrow.lib.Schema (Upload Method Optional, SKLearn model Required) | The output schema in Apache Arrow schema format. |
convert_wait | bool (Upload Method Optional, SKLearn model Optional) (Default: True) |
|
Once the upload process starts, the model is containerized by the Wallaroo instance. This process may take up to 10 minutes.
input_schema = pa.schema([
pa.field('inputs', pa.list_(pa.float64(), list_size=4))
])
output_schema = pa.schema([
pa.field('predictions', pa.int32())
])
Upload Model
The model will be uploaded with the framework set as Framework.SKLEARN.
model = wl.upload_model(model_name,
model_file_name,
framework=Framework.SKLEARN,
input_schema=input_schema,
output_schema=output_schema)
model
Waiting for model conversion... It may take up to 10.0min.
Model is Pending conversion.......Converting............Ready.
| Name | sklearn-clustering-kmeans |
| Version | 1644dac9-5447-4654-b39f-a12560b1db55 |
| File Name | model-auto-conversion_sklearn_kmeans.pkl |
| SHA | b378a614854619dd573ec65b9b4ac73d0b397d50a048e733d96b68c5fdbec896 |
| Status | ready |
| Image Path | proxy.replicated.com/proxy/wallaroo/ghcr.io/wallaroolabs/mlflow-deploy:v2023.3.0-main-3509 |
| Updated At | 2023-13-Jul 17:57:33 |
model.config().runtime()
'mlflow'
Deploy Pipeline
The model is uploaded and ready for use. We’ll add it as a step in our pipeline, then deploy the pipeline. For this example we’re allocated 0.25 cpu and 4 Gi RAM to the pipeline through the pipeline’s deployment configuration.
deployment_config = DeploymentConfigBuilder() \
.cpus(0.25).memory('1Gi') \
.build()
# clear the pipeline if it was used before
pipeline.undeploy()
pipeline.clear()
pipeline.add_model_step(model)
pipeline.deploy(deployment_config=deployment_config)
pipeline.status()
{'status': 'Running',
'details': [],
'engines': [{'ip': '10.244.9.186',
'name': 'engine-6c546c75dd-xhjx6',
'status': 'Running',
'reason': None,
'details': [],
'pipeline_statuses': {'pipelines': [{'id': 'sklearn-clustering-kmeans',
'status': 'Running'}]},
'model_statuses': {'models': [{'name': 'sklearn-clustering-kmeans',
'version': '1644dac9-5447-4654-b39f-a12560b1db55',
'sha': 'b378a614854619dd573ec65b9b4ac73d0b397d50a048e733d96b68c5fdbec896',
'status': 'Running'}]}}],
'engine_lbs': [{'ip': '10.244.9.185',
'name': 'engine-lb-584f54c899-9j8gf',
'status': 'Running',
'reason': None,
'details': []}],
'sidekicks': [{'ip': '10.244.9.184',
'name': 'engine-sidekick-sklearn-clustering-kmeans-269-5d9597dc9f-gqqxf',
'status': 'Running',
'reason': None,
'details': [],
'statuses': '\n'}]}
Inference
SKLearn models must have all of the data as one line to prevent columns from being read out of order when submitting in JSON. The following will take in the data, convert the rows into a single inputs for the table, then perform the inference. From the output_schema we have defined the output as predictions which will be displayed in our inference result output as out.predictions.
data = pd.read_json('./data/test-sklearn-kmeans.json')
display(data)
# move the column values to a single array input
mock_dataframe = pd.DataFrame({"inputs": data[:2].values.tolist()})
display(mock_dataframe)
| sepal length (cm) | sepal width (cm) | petal length (cm) | petal width (cm) | |
|---|---|---|---|---|
| 0 | 5.1 | 3.5 | 1.4 | 0.2 |
| 1 | 4.9 | 3.0 | 1.4 | 0.2 |
| inputs | |
|---|---|
| 0 | [5.1, 3.5, 1.4, 0.2] |
| 1 | [4.9, 3.0, 1.4, 0.2] |
result = pipeline.infer(mock_dataframe)
display(result)
| time | in.inputs | out.predictions | check_failures | |
|---|---|---|---|---|
| 0 | 2023-07-13 18:01:14.756 | [5.1, 3.5, 1.4, 0.2] | 1 | 0 |
| 1 | 2023-07-13 18:01:14.756 | [4.9, 3.0, 1.4, 0.2] | 1 | 0 |
Undeploy Pipelines
With the tutorial complete, the pipeline is undeployed to return the resources back to the cluster.
pipeline.undeploy()
| name | sklearn-clustering-kmeans |
|---|---|
| created | 2023-07-13 17:58:35.744857+00:00 |
| last_updated | 2023-07-13 17:58:35.744857+00:00 |
| deployed | False |
| tags | |
| versions | 386117da-6d79-4349-a774-9610cc9df1bb |
| steps | sklearn-clustering-kmeans |
6.2 - Wallaroo SDK Upload Tutorial: SKLearn Clustering SVM
How to upload a SKLearn Clustering SVM to Wallaroo
This tutorial can be downloaded as part of the Wallaroo Tutorials repository.
Wallaroo Model Upload via the Wallaroo SDK: Sklearn Clustering SVM
The following tutorial demonstrates how to upload a SKLearn Clustering Support Vector Machine(SVM) model to a Wallaroo instance.
Tutorial Goals
Demonstrate the following:
- Upload a Sklearn Clustering SVM model to a Wallaroo instance.
- Create a pipeline and add the model as a pipeline step.
- Perform a sample inference.
Prerequisites
- A Wallaroo version 2023.2.1 or above instance.
References
- Wallaroo MLOps API Essentials Guide: Model Upload and Registrations
- Wallaroo API Connection Guide
- DNS Integration Guide
Tutorial Steps
Import Libraries
The first step is to import the libraries we’ll be using. These are included by default in the Wallaroo instance’s JupyterHub service.
import json
import os
import pickle
import wallaroo
from wallaroo.pipeline import Pipeline
from wallaroo.deployment_config import DeploymentConfigBuilder
from wallaroo.object import EntityNotFoundError
from wallaroo.framework import Framework
import os
os.environ["MODELS_ENABLED"] = "true"
import pyarrow as pa
import numpy as np
import pandas as pd
Open a Connection to Wallaroo
The next step is connect to Wallaroo through the Wallaroo client. The Python library is included in the Wallaroo install and available through the Jupyter Hub interface provided with your Wallaroo environment.
This is accomplished using the wallaroo.Client() command, which provides a URL to grant the SDK permission to your specific Wallaroo environment. When displayed, enter the URL into a browser and confirm permissions. Store the connection into a variable that can be referenced later.
If logging into the Wallaroo instance through the internal JupyterHub service, use wl = wallaroo.Client(). If logging in externally, update the wallarooPrefix and wallarooSuffix variables with the proper DNS information. For more information on Wallaroo DNS settings, see the Wallaroo DNS Integration Guide.
wl = wallaroo.Client()
Set Variables and Helper Functions
We’ll set the name of our workspace, pipeline, models and files. Workspace names must be unique across the Wallaroo workspace. For this, we’ll add in a randomly generated 4 characters to the workspace name to prevent collisions with other users’ workspaces. If running this tutorial, we recommend hard coding the workspace name so it will function in the same workspace each time it’s run.
We’ll set up some helper functions that will either use existing workspaces and pipelines, or create them if they do not already exist.
def get_workspace(name):
workspace = None
for ws in wl.list_workspaces():
if ws.name() == name:
workspace= ws
if(workspace == None):
workspace = wl.create_workspace(name)
return workspace
def get_pipeline(name):
try:
pipeline = wl.pipelines_by_name(name)[0]
except EntityNotFoundError:
pipeline = wl.build_pipeline(name)
return pipeline
import string
import random
# make a random 4 character suffix to prevent overwriting other user's workspaces
suffix= ''.join(random.choice(string.ascii_lowercase) for i in range(4))
workspace_name = f'sklearn-clustering-svm{suffix}'
pipeline_name = f'sklearn-clustering-svm'
model_name = 'sklearn-clustering-svm'
model_file_name = './models/model-auto-conversion_sklearn_svm_pipeline.pkl'
Create Workspace and Pipeline
We will now create the Wallaroo workspace to store our model and set it as the current workspace. Future commands will default to this workspace for pipeline creation, model uploads, etc. We’ll create our Wallaroo pipeline to deploy our model.
workspace = get_workspace(workspace_name)
wl.set_current_workspace(workspace)
pipeline = get_pipeline(pipeline_name)
Configure Data Schemas
SKLearn models are uploaded to Wallaroo through the Wallaroo Client upload_model method.
Upload SKLearn Model Parameters
The following parameters are required for SKLearn models. Note that while some fields are considered as optional for the upload_model method, they are required for proper uploading of a SKLearn model to Wallaroo.
| Parameter | Type | Description |
|---|---|---|
name | string (Required) | The name of the model. Model names are unique per workspace. Models that are uploaded with the same name are assigned as a new version of the model. |
path | string (Required) | The path to the model file being uploaded. |
framework | string (Upload Method Optional, SKLearn model Required) | Set as the Framework.SKLEARN. |
input_schema | pyarrow.lib.Schema (Upload Method Optional, SKLearn model Required) | The input schema in Apache Arrow schema format. |
output_schema | pyarrow.lib.Schema (Upload Method Optional, SKLearn model Required) | The output schema in Apache Arrow schema format. |
convert_wait | bool (Upload Method Optional, SKLearn model Optional) (Default: True) |
|
Once the upload process starts, the model is containerized by the Wallaroo instance. This process may take up to 10 minutes.
input_schema = pa.schema([
pa.field('inputs', pa.list_(pa.float64(), list_size=4))
])
output_schema = pa.schema([
pa.field('predictions', pa.int32())
])
Upload Model
The model will be uploaded with the framework set as Framework.SKLEARN.
model = wl.upload_model(model_name,
model_file_name,
framework=Framework.SKLEARN,
input_schema=input_schema,
output_schema=output_schema)
model
Waiting for model conversion... It may take up to 10.0min.
Model is Pending conversion.Converting..Pending conversion.Converting.......Ready.
| Name | sklearn-clustering-svm |
| Version | 984494d8-3908-4cf7-9bcb-c52116b8da7a |
| File Name | model-auto-conversion_sklearn_svm_pipeline.pkl |
| SHA | c6eec69d96f7eeb3db034600dea6b12da1d2b832c39252ec4942d02f68f52f40 |
| Status | ready |
| Image Path | proxy.replicated.com/proxy/wallaroo/ghcr.io/wallaroolabs/mlflow-deploy:v2023.3.0-main-3509 |
| Updated At | 2023-13-Jul 18:15:54 |
model.config().runtime()
'mlflow'
Deploy Pipeline
The model is uploaded and ready for use. We’ll add it as a step in our pipeline, then deploy the pipeline. For this example we’re allocated 0.25 cpu and 4 Gi RAM to the pipeline through the pipeline’s deployment configuration.
deployment_config = DeploymentConfigBuilder() \
.cpus(0.25).memory('1Gi') \
.build()
# clear the pipeline if it was used before
pipeline.undeploy()
pipeline.clear()
pipeline.add_model_step(model)
pipeline.deploy(deployment_config=deployment_config)
pipeline.status()
{'status': 'Running',
'details': [],
'engines': [{'ip': '10.244.9.198',
'name': 'engine-665c7458c4-z92xn',
'status': 'Running',
'reason': None,
'details': [],
'pipeline_statuses': {'pipelines': [{'id': 'sklearn-clustering-svm',
'status': 'Running'}]},
'model_statuses': {'models': [{'name': 'sklearn-clustering-svm',
'version': '984494d8-3908-4cf7-9bcb-c52116b8da7a',
'sha': 'c6eec69d96f7eeb3db034600dea6b12da1d2b832c39252ec4942d02f68f52f40',
'status': 'Running'}]}}],
'engine_lbs': [{'ip': '10.244.9.199',
'name': 'engine-lb-584f54c899-qwn65',
'status': 'Running',
'reason': None,
'details': []}],
'sidekicks': [{'ip': '10.244.9.197',
'name': 'engine-sidekick-sklearn-clustering-svm-271-7fc57d45d9-wg8bl',
'status': 'Running',
'reason': None,
'details': [],
'statuses': '\n'}]}
Inference
SKLearn models must have all of the data as one line to prevent columns from being read out of order when submitting in JSON. The following will take in the data, convert the rows into a single inputs for the table, then perform the inference. From the output_schema we have defined the output as predictions which will be displayed in our inference result output as out.predictions.
data = pd.read_json('./data/test_cluster-svm.json')
display(data)
# move the column values to a single array input
dataframe = pd.DataFrame({"inputs": data[:2].values.tolist()})
display(dataframe)
| sepal length (cm) | sepal width (cm) | petal length (cm) | petal width (cm) | |
|---|---|---|---|---|
| 0 | 5.1 | 3.5 | 1.4 | 0.2 |
| 1 | 4.9 | 3.0 | 1.4 | 0.2 |
| inputs | |
|---|---|
| 0 | [5.1, 3.5, 1.4, 0.2] |
| 1 | [4.9, 3.0, 1.4, 0.2] |
pipeline.infer(dataframe)
| time | in.inputs | out.predictions | check_failures | |
|---|---|---|---|---|
| 0 | 2023-07-13 18:17:07.199 | [5.1, 3.5, 1.4, 0.2] | 0 | 0 |
| 1 | 2023-07-13 18:17:07.199 | [4.9, 3.0, 1.4, 0.2] | 0 | 0 |
Undeploy Pipelines
With the tutorial complete, the pipeline is undeployed to return the resources back to the cluster.
pipeline.undeploy()
| name | sklearn-clustering-svm |
|---|---|
| created | 2023-07-13 18:14:58.440836+00:00 |
| last_updated | 2023-07-13 18:16:50.545217+00:00 |
| deployed | False |
| tags | |
| versions | 749e5f51-376e-4b09-a0e2-8c47c69eba53, 09ef9b6a-912a-4ca8-9b82-09837cdccdb6 |
| steps | sklearn-clustering-svm |
6.3 - Wallaroo SDK Upload Tutorial: SKLearn Linear Regression
How to upload a SKLearn Linear Regression model to Wallaroo
This tutorial can be downloaded as part of the Wallaroo Tutorials repository.
Wallaroo Model Upload via the Wallaroo SDK: SKLearn Linear Regression
The following tutorial demonstrates how to upload a SKLearn Linear Regression model to a Wallaroo instance.
Tutorial Goals
Demonstrate the following:
- Upload a SKLearn Linear Regression model to a Wallaroo instance.
- Create a pipeline and add the model as a pipeline step.
- Perform a sample inference.
Prerequisites
- A Wallaroo version 2023.2.1 or above instance.
References
- Wallaroo MLOps API Essentials Guide: Model Upload and Registrations
- Wallaroo API Connection Guide
- DNS Integration Guide
Tutorial Steps
Import Libraries
The first step is to import the libraries we’ll be using. These are included by default in the Wallaroo instance’s JupyterHub service.
import json
import os
import pickle
import wallaroo
from wallaroo.pipeline import Pipeline
from wallaroo.deployment_config import DeploymentConfigBuilder
from wallaroo.object import EntityNotFoundError
from wallaroo.framework import Framework
import os
os.environ["MODELS_ENABLED"] = "true"
import pyarrow as pa
import numpy as np
import pandas as pd
Open a Connection to Wallaroo
The next step is connect to Wallaroo through the Wallaroo client. The Python library is included in the Wallaroo install and available through the Jupyter Hub interface provided with your Wallaroo environment.
This is accomplished using the wallaroo.Client() command, which provides a URL to grant the SDK permission to your specific Wallaroo environment. When displayed, enter the URL into a browser and confirm permissions. Store the connection into a variable that can be referenced later.
If logging into the Wallaroo instance through the internal JupyterHub service, use wl = wallaroo.Client(). If logging in externally, update the wallarooPrefix and wallarooSuffix variables with the proper DNS information. For more information on Wallaroo DNS settings, see the Wallaroo DNS Integration Guide.
wl = wallaroo.Client()
Set Variables and Helper Functions
We’ll set the name of our workspace, pipeline, models and files. Workspace names must be unique across the Wallaroo workspace. For this, we’ll add in a randomly generated 4 characters to the workspace name to prevent collisions with other users’ workspaces. If running this tutorial, we recommend hard coding the workspace name so it will function in the same workspace each time it’s run.
We’ll set up some helper functions that will either use existing workspaces and pipelines, or create them if they do not already exist.
def get_workspace(name):
workspace = None
for ws in wl.list_workspaces():
if ws.name() == name:
workspace= ws
if(workspace == None):
workspace = wl.create_workspace(name)
return workspace
def get_pipeline(name):
try:
pipeline = wl.pipelines_by_name(name)[0]
except EntityNotFoundError:
pipeline = wl.build_pipeline(name)
return pipeline
import string
import random
# make a random 4 character suffix to prevent overwriting other user's workspaces
suffix= ''.join(random.choice(string.ascii_lowercase) for i in range(4))
workspace_name = f'sklearn-linear-regression{suffix}'
pipeline_name = f'sklearn-linear-regression'
model_name = 'sklearn-linear-regression'
model_file_name = 'models/model-auto-conversion_sklearn_linreg_diabetes.pkl'
Create Workspace and Pipeline
We will now create the Wallaroo workspace to store our model and set it as the current workspace. Future commands will default to this workspace for pipeline creation, model uploads, etc. We’ll create our Wallaroo pipeline to deploy our model.
workspace = get_workspace(workspace_name)
wl.set_current_workspace(workspace)
pipeline = get_pipeline(pipeline_name)
Configure Data Schemas
SKLearn models are uploaded to Wallaroo through the Wallaroo Client upload_model method.
Upload SKLearn Model Parameters
The following parameters are required for SKLearn models. Note that while some fields are considered as optional for the upload_model method, they are required for proper uploading of a SKLearn model to Wallaroo.
| Parameter | Type | Description |
|---|---|---|
name | string (Required) | The name of the model. Model names are unique per workspace. Models that are uploaded with the same name are assigned as a new version of the model. |
path | string (Required) | The path to the model file being uploaded. |
framework | string (Upload Method Optional, SKLearn model Required) | Set as the Framework.SKLEARN. |
input_schema | pyarrow.lib.Schema (Upload Method Optional, SKLearn model Required) | The input schema in Apache Arrow schema format. |
output_schema | pyarrow.lib.Schema (Upload Method Optional, SKLearn model Required) | The output schema in Apache Arrow schema format. |
convert_wait | bool (Upload Method Optional, SKLearn model Optional) (Default: True) |
|
Once the upload process starts, the model is containerized by the Wallaroo instance. This process may take up to 10 minutes.
input_schema = pa.schema([
pa.field('inputs', pa.list_(pa.float64(), list_size=10))
])
output_schema = pa.schema([
pa.field('predictions', pa.float64())
])
Upload Model
The model will be uploaded with the framework set as Framework.SKLEARN.
model = wl.upload_model(model_name,
model_file_name,
framework=Framework.SKLEARN,
input_schema=input_schema,
output_schema=output_schema)
model
Waiting for model conversion... It may take up to 10.0min.
Model is Pending conversion.Converting..Pending conversion.Converting......Ready.
| Name | sklearn-linear-regression |
| Version | aa2741c1-1099-4856-8581-a011a8bfc584 |
| File Name | model-auto-conversion_sklearn_linreg_diabetes.pkl |
| SHA | 6a9085e2d65bf0379934651d2272d3c6c4e020e36030933d85df3a8d15135a45 |
| Status | ready |
| Image Path | proxy.replicated.com/proxy/wallaroo/ghcr.io/wallaroolabs/mlflow-deploy:v2023.3.0-main-3509 |
| Updated At | 2023-13-Jul 18:20:33 |
model.config().runtime()
'mlflow'
Deploy Pipeline
The model is uploaded and ready for use. We’ll add it as a step in our pipeline, then deploy the pipeline. For this example we’re allocated 0.25 cpu and 4 Gi RAM to the pipeline through the pipeline’s deployment configuration.
deployment_config = DeploymentConfigBuilder() \
.cpus(0.25).memory('1Gi') \
.build()
# clear the pipeline if it was used before
pipeline.undeploy()
pipeline.clear()
pipeline.add_model_step(model)
pipeline.deploy(deployment_config=deployment_config)
pipeline.status()
{'status': 'Running',
'details': [],
'engines': [{'ip': '10.244.9.204',
'name': 'engine-747f8b6656-6bd92',
'status': 'Running',
'reason': None,
'details': [],
'pipeline_statuses': {'pipelines': [{'id': 'sklearn-linear-regression',
'status': 'Running'}]},
'model_statuses': {'models': [{'name': 'sklearn-linear-regression',
'version': 'aa2741c1-1099-4856-8581-a011a8bfc584',
'sha': '6a9085e2d65bf0379934651d2272d3c6c4e020e36030933d85df3a8d15135a45',
'status': 'Running'}]}}],
'engine_lbs': [{'ip': '10.244.9.205',
'name': 'engine-lb-584f54c899-fbznx',
'status': 'Running',
'reason': None,
'details': []}],
'sidekicks': [{'ip': '10.244.9.203',
'name': 'engine-sidekick-sklearn-linear-regression-272-cf6f55ff8-j2z2f',
'status': 'Running',
'reason': None,
'details': [],
'statuses': '\n'}]}
Inference
SKLearn models must have all of the data as one line to prevent columns from being read out of order when submitting in JSON. The following will take in the data, convert the rows into a single inputs for the table, then perform the inference. From the output_schema we have defined the output as predictions which will be displayed in our inference result output as out.predictions.
data = pd.read_json('data/test_linear_regression_data.json')
display(data)
# move the column values to a single array input
dataframe = pd.DataFrame({"inputs": data[:2].values.tolist()})
display(dataframe)
| age | sex | bmi | bp | s1 | s2 | s3 | s4 | s5 | s6 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.038076 | 0.050680 | 0.061696 | 0.021872 | -0.044223 | -0.034821 | -0.043401 | -0.002592 | 0.019907 | -0.017646 |
| 1 | -0.001882 | -0.044642 | -0.051474 | -0.026328 | -0.008449 | -0.019163 | 0.074412 | -0.039493 | -0.068332 | -0.092204 |
| inputs | |
|---|---|
| 0 | [0.0380759064, 0.0506801187, 0.0616962065, 0.0... |
| 1 | [-0.0018820165, -0.0446416365, -0.051474061200... |
pipeline.infer(dataframe)
| time | in.inputs | out.predictions | check_failures | |
|---|---|---|---|---|
| 0 | 2023-07-13 18:20:51.820 | [0.0380759064, 0.0506801187, 0.0616962065, 0.0... | 206.116677 | 0 |
| 1 | 2023-07-13 18:20:51.820 | [-0.0018820165, -0.0446416365, -0.0514740612, ... | 68.071033 | 0 |
Undeploy Pipelines
With the tutorial complete, the pipeline is undeployed to return the resources back to the cluster.
pipeline.undeploy()
| name | sklearn-linear-regression |
|---|---|
| created | 2023-07-13 18:19:38.157202+00:00 |
| last_updated | 2023-07-13 18:20:35.237728+00:00 |
| deployed | False |
| tags | |
| versions | 72782c06-edb6-4cca-8598-a3103e39c24b, 7e8403a9-41e1-42b9-ba36-2523634105d0 |
| steps | sklearn-linear-regression |
6.4 - Wallaroo SDK Upload Tutorial: SKLearn Logistic Regression
How to upload a SKLearn Logistic Regression to Wallaroo
This tutorial can be downloaded as part of the Wallaroo Tutorials repository.
Wallaroo Model Upload via the Wallaroo SDK: SKLearn Logistic Regression
The following tutorial demonstrates how to upload a SKLearn Logistic Regression model to a Wallaroo instance.
Tutorial Goals
Demonstrate the following:
- Upload a SKLearn Logistic Regression model to a Wallaroo instance.
- Create a pipeline and add the model as a pipeline step.
- Perform a sample inference.
Prerequisites
- A Wallaroo version 2023.2.1 or above instance.
References
- Wallaroo MLOps API Essentials Guide: Model Upload and Registrations
- Wallaroo API Connection Guide
- DNS Integration Guide
Tutorial Steps
Import Libraries
The first step is to import the libraries we’ll be using. These are included by default in the Wallaroo instance’s JupyterHub service.
import json
import os
import pickle
import wallaroo
from wallaroo.pipeline import Pipeline
from wallaroo.deployment_config import DeploymentConfigBuilder
from wallaroo.object import EntityNotFoundError
from wallaroo.framework import Framework
import os
os.environ["MODELS_ENABLED"] = "true"
import pyarrow as pa
import numpy as np
import pandas as pd
Open a Connection to Wallaroo
The next step is connect to Wallaroo through the Wallaroo client. The Python library is included in the Wallaroo install and available through the Jupyter Hub interface provided with your Wallaroo environment.
This is accomplished using the wallaroo.Client() command, which provides a URL to grant the SDK permission to your specific Wallaroo environment. When displayed, enter the URL into a browser and confirm permissions. Store the connection into a variable that can be referenced later.
If logging into the Wallaroo instance through the internal JupyterHub service, use wl = wallaroo.Client(). If logging in externally, update the wallarooPrefix and wallarooSuffix variables with the proper DNS information. For more information on Wallaroo DNS settings, see the Wallaroo DNS Integration Guide.
wl = wallaroo.Client()
Set Variables and Helper Functions
We’ll set the name of our workspace, pipeline, models and files. Workspace names must be unique across the Wallaroo workspace. For this, we’ll add in a randomly generated 4 characters to the workspace name to prevent collisions with other users’ workspaces. If running this tutorial, we recommend hard coding the workspace name so it will function in the same workspace each time it’s run.
We’ll set up some helper functions that will either use existing workspaces and pipelines, or create them if they do not already exist.
def get_workspace(name):
workspace = None
for ws in wl.list_workspaces():
if ws.name() == name:
workspace= ws
if(workspace == None):
workspace = wl.create_workspace(name)
return workspace
def get_pipeline(name):
try:
pipeline = wl.pipelines_by_name(name)[0]
except EntityNotFoundError:
pipeline = wl.build_pipeline(name)
return pipeline
import string
import random
# make a random 4 character suffix to prevent overwriting other user's workspaces
suffix= ''.join(random.choice(string.ascii_lowercase) for i in range(4))
workspace_name = f'sklearn-logistic-regression{suffix}'
pipeline_name = f'sklearn-logistic-regression'
model_name = 'sklearn-logistic-regression'
model_file_name = 'models/logreg.pkl'
Create Workspace and Pipeline
We will now create the Wallaroo workspace to store our model and set it as the current workspace. Future commands will default to this workspace for pipeline creation, model uploads, etc. We’ll create our Wallaroo pipeline to deploy our model.
workspace = get_workspace(workspace_name)
wl.set_current_workspace(workspace)
pipeline = get_pipeline(pipeline_name)
Configure Data Schemas
SKLearn models are uploaded to Wallaroo through the Wallaroo Client upload_model method.
Upload SKLearn Model Parameters
The following parameters are required for SKLearn models. Note that while some fields are considered as optional for the upload_model method, they are required for proper uploading of a SKLearn model to Wallaroo.
| Parameter | Type | Description |
|---|---|---|
name | string (Required) | The name of the model. Model names are unique per workspace. Models that are uploaded with the same name are assigned as a new version of the model. |
path | string (Required) | The path to the model file being uploaded. |
framework | string (Upload Method Optional, SKLearn model Required) | Set as the Framework.SKLEARN. |
input_schema | pyarrow.lib.Schema (Upload Method Optional, SKLearn model Required) | The input schema in Apache Arrow schema format. |
output_schema | pyarrow.lib.Schema (Upload Method Optional, SKLearn model Required) | The output schema in Apache Arrow schema format. |
convert_wait | bool (Upload Method Optional, SKLearn model Optional) (Default: True) |
|
Once the upload process starts, the model is containerized by the Wallaroo instance. This process may take up to 10 minutes.
input_schema = pa.schema([
pa.field('inputs', pa.list_(pa.float64(), list_size=4))
])
output_schema = pa.schema([
pa.field('predictions', pa.int32()),
pa.field('probabilities', pa.list_(pa.float64(), list_size=3))
])
Upload Model
The model will be uploaded with the framework set as Framework.SKLEARN.
model = wl.upload_model(model_name,
model_file_name,
framework=Framework.SKLEARN,
input_schema=input_schema,
output_schema=output_schema)
model
Waiting for model conversion... It may take up to 10.0min.
Model is Pending conversion.Converting..Pending conversion.Converting......Ready.
| Name | sklearn-logistic-regression |
| Version | ae956bce-4791-4093-8f6e-a71a2ac60350 |
| File Name | logreg.pkl |
| SHA | 9302df6cc64a2c0d12daa257657f07f9db0bb2072bb3fb92396500b21358e0b9 |
| Status | ready |
| Image Path | proxy.replicated.com/proxy/wallaroo/ghcr.io/wallaroolabs/mlflow-deploy:v2023.3.0-main-3509 |
| Updated At | 2023-13-Jul 18:24:06 |
model.config().runtime()
'mlflow'
Deploy Pipeline
The model is uploaded and ready for use. We’ll add it as a step in our pipeline, then deploy the pipeline. For this example we’re allocated 0.25 cpu and 4 Gi RAM to the pipeline through the pipeline’s deployment configuration.
deployment_config = DeploymentConfigBuilder() \
.cpus(0.25).memory('1Gi') \
.build()
# clear the pipeline if it was used before
pipeline.undeploy()
pipeline.clear()
pipeline.add_model_step(model)
pipeline.deploy(deployment_config=deployment_config)
pipeline.status()
{'status': 'Running',
'details': [],
'engines': [{'ip': '10.244.9.209',
'name': 'engine-74bc88dc9b-bmwn9',
'status': 'Running',
'reason': None,
'details': [],
'pipeline_statuses': {'pipelines': [{'id': 'sklearn-logistic-regression',
'status': 'Running'}]},
'model_statuses': {'models': [{'name': 'sklearn-logistic-regression',
'version': 'ae956bce-4791-4093-8f6e-a71a2ac60350',
'sha': '9302df6cc64a2c0d12daa257657f07f9db0bb2072bb3fb92396500b21358e0b9',
'status': 'Running'}]}}],
'engine_lbs': [{'ip': '10.244.9.210',
'name': 'engine-lb-584f54c899-zsb9l',
'status': 'Running',
'reason': None,
'details': []}],
'sidekicks': [{'ip': '10.244.9.211',
'name': 'engine-sidekick-sklearn-logistic-regression-273-b4b54f497-glkts',
'status': 'Running',
'reason': None,
'details': [],
'statuses': '\n'}]}
Inference
SKLearn models must have all of the data as one line to prevent columns from being read out of order when submitting in JSON. The following will take in the data, convert the rows into a single inputs for the table, then perform the inference. From the output_schema we have defined the output as predictions which will be displayed in our inference result output as out.predictions.
data = pd.read_json('data/test_logreg_data.json')
display(data)
# move the column values to a single array input
dataframe = pd.DataFrame({"inputs": data[:2].values.tolist()})
display(dataframe)
| sepal length (cm) | sepal width (cm) | petal length (cm) | petal width (cm) | |
|---|---|---|---|---|
| 0 | 5.1 | 3.5 | 1.4 | 0.2 |
| 1 | 4.9 | 3.0 | 1.4 | 0.2 |
| inputs | |
|---|---|
| 0 | [5.1, 3.5, 1.4, 0.2] |
| 1 | [4.9, 3.0, 1.4, 0.2] |
pipeline.infer(dataframe)
| time | in.inputs | out.predictions | out.probabilities | check_failures | |
|---|---|---|---|---|---|
| 0 | 2023-07-13 18:24:26.268 | [5.1, 3.5, 1.4, 0.2] | 0 | [0.9815821465852236, 0.018417838912958125, 1.4... | 0 |
| 1 | 2023-07-13 18:24:26.268 | [4.9, 3.0, 1.4, 0.2] | 0 | [0.9713374799347873, 0.028662489870060148, 3.0... | 0 |
Undeploy Pipelines
With the tutorial complete, the pipeline is undeployed to return the resources back to the cluster.
pipeline.undeploy()
| name | sklearn-logistic-regression |
|---|---|
| created | 2023-07-13 18:23:10.490850+00:00 |
| last_updated | 2023-07-13 18:24:07.723159+00:00 |
| deployed | False |
| tags | |
| versions | ef89df8f-4748-4c4d-b838-b0faa2b1b4ec, 7218317a-1df8-4d4a-8fbf-dbba19ac2853 |
| steps | sklearn-logistic-regression |
6.5 - Wallaroo SDK Upload Tutorial: SKLearn SVM PCA
How to upload a SKLearn SVM PCA to Wallaroo
This tutorial can be downloaded as part of the Wallaroo Tutorials repository.
Wallaroo Model Upload via the Wallaroo SDK: Sklearn Clustering SVM PCA
The following tutorial demonstrates how to upload a SKLearn Clustering Support Vector Machine(SVM) Principal Component Analysis (PCA) model to a Wallaroo instance.
Tutorial Goals
Demonstrate the following:
- Upload a Sklearn Clustering SVM PCA model to a Wallaroo instance.
- Create a pipeline and add the model as a pipeline step.
- Perform a sample inference.
Prerequisites
- A Wallaroo version 2023.2.1 or above instance.
References
- Wallaroo MLOps API Essentials Guide: Model Upload and Registrations
- Wallaroo API Connection Guide
- DNS Integration Guide
Tutorial Steps
Import Libraries
The first step is to import the libraries we’ll be using. These are included by default in the Wallaroo instance’s JupyterHub service.
import json
import os
import pickle
import wallaroo
from wallaroo.pipeline import Pipeline
from wallaroo.deployment_config import DeploymentConfigBuilder
from wallaroo.object import EntityNotFoundError
from wallaroo.framework import Framework
import os
os.environ["MODELS_ENABLED"] = "true"
import pyarrow as pa
import numpy as np
import pandas as pd
Open a Connection to Wallaroo
The next step is connect to Wallaroo through the Wallaroo client. The Python library is included in the Wallaroo install and available through the Jupyter Hub interface provided with your Wallaroo environment.
This is accomplished using the wallaroo.Client() command, which provides a URL to grant the SDK permission to your specific Wallaroo environment. When displayed, enter the URL into a browser and confirm permissions. Store the connection into a variable that can be referenced later.
If logging into the Wallaroo instance through the internal JupyterHub service, use wl = wallaroo.Client(). If logging in externally, update the wallarooPrefix and wallarooSuffix variables with the proper DNS information. For more information on Wallaroo DNS settings, see the Wallaroo DNS Integration Guide.
wl = wallaroo.Client()
Set Variables and Helper Functions
We’ll set the name of our workspace, pipeline, models and files. Workspace names must be unique across the Wallaroo workspace. For this, we’ll add in a randomly generated 4 characters to the workspace name to prevent collisions with other users’ workspaces. If running this tutorial, we recommend hard coding the workspace name so it will function in the same workspace each time it’s run.
We’ll set up some helper functions that will either use existing workspaces and pipelines, or create them if they do not already exist.
def get_workspace(name):
workspace = None
for ws in wl.list_workspaces():
if ws.name() == name:
workspace= ws
if(workspace == None):
workspace = wl.create_workspace(name)
return workspace
def get_pipeline(name):
try:
pipeline = wl.pipelines_by_name(name)[0]
except EntityNotFoundError:
pipeline = wl.build_pipeline(name)
return pipeline
import string
import random
# make a random 4 character suffix to prevent overwriting other user's workspaces
suffix= ''.join(random.choice(string.ascii_lowercase) for i in range(4))
workspace_name = f'sklearn-clustering-svm-pca{suffix}'
pipeline_name = f'sklearn-clustering-svm-pca'
model_name = 'sklearn-clustering-svm-pca'
model_file_name = 'models/model-auto-conversion_sklearn_svm_pca_pipeline.pkl'
Create Workspace and Pipeline
We will now create the Wallaroo workspace to store our model and set it as the current workspace. Future commands will default to this workspace for pipeline creation, model uploads, etc. We’ll create our Wallaroo pipeline to deploy our model.
workspace = get_workspace(workspace_name)
wl.set_current_workspace(workspace)
pipeline = get_pipeline(pipeline_name)
Configure Data Schemas
SKLearn models are uploaded to Wallaroo through the Wallaroo Client upload_model method.
Upload SKLearn Model Parameters
The following parameters are required for SKLearn models. Note that while some fields are considered as optional for the upload_model method, they are required for proper uploading of a SKLearn model to Wallaroo.
| Parameter | Type | Description |
|---|---|---|
name | string (Required) | The name of the model. Model names are unique per workspace. Models that are uploaded with the same name are assigned as a new version of the model. |
path | string (Required) | The path to the model file being uploaded. |
framework | string (Upload Method Optional, SKLearn model Required) | Set as the Framework.SKLEARN. |
input_schema | pyarrow.lib.Schema (Upload Method Optional, SKLearn model Required) | The input schema in Apache Arrow schema format. |
output_schema | pyarrow.lib.Schema (Upload Method Optional, SKLearn model Required) | The output schema in Apache Arrow schema format. |
convert_wait | bool (Upload Method Optional, SKLearn model Optional) (Default: True) |
|
Once the upload process starts, the model is containerized by the Wallaroo instance. This process may take up to 10 minutes.
input_schema = pa.schema([
pa.field('inputs', pa.list_(pa.float64(), list_size=4))
])
output_schema = pa.schema([
pa.field('predictions', pa.int32())
])
Upload Model
The model will be uploaded with the framework set as Framework.SKLEARN.
model = wl.upload_model(model_name,
model_file_name,
framework=Framework.SKLEARN,
input_schema=input_schema,
output_schema=output_schema)
model
Waiting for model conversion... It may take up to 10.0min.
Model is Pending conversion.Converting..Pending conversion..Converting.......Ready.
| Name | sklearn-clustering-svm-pca |
| Version | 863c32cb-b7aa-4e8a-b473-7b0bf7f10258 |
| File Name | model-auto-conversion_sklearn_svm_pca_pipeline.pkl |
| SHA | 524b05d22f13fa4ce5feaf07b86710b447f0c80a02601be86ee5b6bc748fe7fd |
| Status | ready |
| Image Path | proxy.replicated.com/proxy/wallaroo/ghcr.io/wallaroolabs/mlflow-deploy:v2023.3.0-main-3509 |
| Updated At | 2023-13-Jul 18:10:51 |
model.config().runtime()
'mlflow'
Deploy Pipeline
The model is uploaded and ready for use. We’ll add it as a step in our pipeline, then deploy the pipeline. For this example we’re allocated 0.25 cpu and 4 Gi RAM to the pipeline through the pipeline’s deployment configuration.
deployment_config = DeploymentConfigBuilder() \
.cpus(0.25).memory('1Gi') \
.build()
# clear the pipeline if it was used before
pipeline.undeploy()
pipeline.clear()
pipeline.add_model_step(model)
pipeline.deploy(deployment_config=deployment_config)
pipeline.status()
{'status': 'Running',
'details': [],
'engines': [{'ip': '10.244.9.193',
'name': 'engine-6bbc4c5f5f-xw5nb',
'status': 'Running',
'reason': None,
'details': [],
'pipeline_statuses': {'pipelines': [{'id': 'sklearn-clustering-svm-pca',
'status': 'Running'}]},
'model_statuses': {'models': [{'name': 'sklearn-clustering-svm-pca',
'version': '863c32cb-b7aa-4e8a-b473-7b0bf7f10258',
'sha': '524b05d22f13fa4ce5feaf07b86710b447f0c80a02601be86ee5b6bc748fe7fd',
'status': 'Running'}]}}],
'engine_lbs': [{'ip': '10.244.9.192',
'name': 'engine-lb-584f54c899-r8mxl',
'status': 'Running',
'reason': None,
'details': []}],
'sidekicks': [{'ip': '10.244.9.191',
'name': 'engine-sidekick-sklearn-clustering-svm-pca-270-54cd5fcbb5-c42bx',
'status': 'Running',
'reason': None,
'details': [],
'statuses': '\n'}]}
Inference
SKLearn models must have all of the data as one line to prevent columns from being read out of order when submitting in JSON. The following will take in the data, convert the rows into a single inputs for the table, then perform the inference. From the output_schema we have defined the output as predictions which will be displayed in our inference result output as out.predictions.
data = pd.read_json('data/test-sklearn-kmeans.json')
display(data)
# move the column values to a single array input
dataframe = pd.DataFrame({"inputs": data[:2].values.tolist()})
display(dataframe)
| sepal length (cm) | sepal width (cm) | petal length (cm) | petal width (cm) | |
|---|---|---|---|---|
| 0 | 5.1 | 3.5 | 1.4 | 0.2 |
| 1 | 4.9 | 3.0 | 1.4 | 0.2 |
| inputs | |
|---|---|
| 0 | [5.1, 3.5, 1.4, 0.2] |
| 1 | [4.9, 3.0, 1.4, 0.2] |
pipeline.infer(dataframe)
| time | in.inputs | out.predictions | check_failures | |
|---|---|---|---|---|
| 0 | 2023-07-13 18:11:14.856 | [5.1, 3.5, 1.4, 0.2] | 0 | 0 |
| 1 | 2023-07-13 18:11:14.856 | [4.9, 3.0, 1.4, 0.2] | 0 | 0 |
Undeploy Pipelines
With the tutorial complete, the pipeline is undeployed to return the resources back to the cluster.
pipeline.undeploy()
| name | sklearn-clustering-svm-pca |
|---|---|
| created | 2023-07-13 18:09:46.085151+00:00 |
| last_updated | 2023-07-13 18:10:54.850527+00:00 |
| deployed | False |
| tags | |
| versions | 1cd17197-b4ee-472a-9ccf-b0fb6bd150b8, 8b24f044-7115-451a-8614-eaf4b4068737 |
| steps | sklearn-clustering-svm-pca |
7 - Wallaroo SDK Upload Tutorials: Tensorflow
How to upload different Tensorflow models to Wallaroo.
The following tutorials cover how to upload sample Tensorflow models.
| Parameter | Description |
|---|---|
| Web Site | https://www.tensorflow.org/ |
| Supported Libraries | tensorflow==2.9.1 |
| Framework | Framework.TENSORFLOW aka tensorflow |
| Runtime | Native aka tensorflow |
| Supported File Types | SavedModel format as .zip file |
IMPORTANT NOTE
These requirements are not for Tensorflow Keras models, only for non-Keras Tensorflow models in the SavedModel format. For Tensorflow Keras deployment in Wallaroo, see the Tensorflow Keras requirements.TensorFlow File Format
TensorFlow models are .zip file of the SavedModel format. For example, the Aloha sample TensorFlow model is stored in the directory alohacnnlstm:
├── saved_model.pb
└── variables
├── variables.data-00000-of-00002
├── variables.data-00001-of-00002
└── variables.index
This is compressed into the .zip file alohacnnlstm.zip with the following command:
zip -r alohacnnlstm.zip alohacnnlstm/
ML models that meet the Tensorflow and SavedModel format will run as Wallaroo Native runtimes by default.
See the SavedModel guide for full details.
7.1 - Wallaroo SDK Upload Tutorial: Tensorflow Aloha
How to upload the Tensorflow Aloha model to Wallaroo
This tutorial and the assets can be downloaded as part of the Wallaroo Tutorials repository.
Wallaroo SDK Upload Tutorial: Tensorflow
In this notebook we will walk through uploading a Tensorflow model to a Wallaroo instance and performing sample inferences. For this example we will be using an open source model that uses an Aloha CNN LSTM model for classifying Domain names as being either legitimate or being used for nefarious purposes such as malware distribution.
Prerequisites
- An installed Wallaroo instance.
- The following Python libraries installed:
Tutorial Goals
For our example, we will perform the following:
- Create a workspace for our work.
- Upload the Aloha model.
- Create a pipeline that can ingest our submitted data, submit it to the model, and export the results.
All sample data and models are available through the Wallaroo Quick Start Guide Samples repository.
Connect to the Wallaroo Instance
The first step is to connect to Wallaroo through the Wallaroo client. The Python library is included in the Wallaroo install and available through the Jupyter Hub interface provided with your Wallaroo environment.
This is accomplished using the wallaroo.Client() command, which provides a URL to grant the SDK permission to your specific Wallaroo environment. When displayed, enter the URL into a browser and confirm permissions. Store the connection into a variable that can be referenced later.
If logging into the Wallaroo instance through the internal JupyterHub service, use wl = wallaroo.Client(). For more information on Wallaroo Client settings, see the Client Connection guide.e/wallaroo-sdk-essentials-client/).
import wallaroo
from wallaroo.object import EntityNotFoundError
from wallaroo.framework import Framework
# to display dataframe tables
from IPython.display import display
# used to display dataframe information without truncating
import os
os.environ["MODELS_ENABLED"] = "true"
import pandas as pd
pd.set_option('display.max_colwidth', None)
import pyarrow as pa
# Login through local Wallaroo instance
wl = wallaroo.Client()
wallarooPrefix = ""
wallarooSuffix = "autoscale-uat-ee.wallaroo.dev"
wl = wallaroo.Client(api_endpoint=f"https://{wallarooPrefix}api.{wallarooSuffix}",
auth_endpoint=f"https://{wallarooPrefix}keycloak.{wallarooSuffix}",
auth_type="sso")
Create the Workspace
We will create a workspace to work in and call it the “alohaworkspace”, then set it as current workspace environment. We’ll also create our pipeline in advance as alohapipeline. The model name and the model file will be specified for use in later steps.
To allow this tutorial to be run multiple times or by multiple users in the same Wallaroo instance, a random 4 character prefix will be added to the workspace, pipeline, and model.
import string
import random
# make a random 4 character suffix to verify uniqueness in tutorials
suffix= ''.join(random.choice(string.ascii_lowercase) for i in range(4))
workspace_name = f'tensorflowuploadexampleworkspace{suffix}'
pipeline_name = f'tensorflowuploadexample{suffix}'
model_name = f'tensorflowuploadexample{suffix}'
model_file_name = './models/alohacnnlstm.zip'
def get_workspace(name):
workspace = None
for ws in wl.list_workspaces():
if ws.name() == name:
workspace= ws
if(workspace == None):
workspace = wl.create_workspace(name)
return workspace
def get_pipeline(name):
try:
pipeline = wl.pipelines_by_name(name)[0]
except EntityNotFoundError:
pipeline = wl.build_pipeline(name)
return pipeline
workspace = get_workspace(workspace_name)
wl.set_current_workspace(workspace)
aloha_pipeline = get_pipeline(pipeline_name)
aloha_pipeline
| name | tensorflowuploadexampletxdg |
|---|---|
| created | 2023-07-13 18:29:16.306846+00:00 |
| last_updated | 2023-07-13 18:29:16.306846+00:00 |
| deployed | (none) |
| tags | |
| versions | 755813ea-cb7f-4e9e-9075-2f5eea0f883f |
| steps |
We can verify the workspace is created the current default workspace with the get_current_workspace() command.
wl.get_current_workspace()
{'name': 'tensorflowuploadexampleworkspacetxdg', 'id': 435, 'archived': False, 'created_by': 'd9a72bd9-2a1c-44dd-989f-3c7c15130885', 'created_at': '2023-07-13T18:29:15.359159+00:00', 'models': [], 'pipelines': [{'name': 'tensorflowuploadexampletxdg', 'create_time': datetime.datetime(2023, 7, 13, 18, 29, 16, 306846, tzinfo=tzutc()), 'definition': '[]'}]}
Upload the Models
Now we will upload our models. Note that for this example we are applying the model from a .ZIP file. The Aloha model is a protobuf file that has been defined for evaluating web pages, and we will configure it to use data in the tensorflow format.
The following parameters are required for TensorFlow models. Tensorflow models are native runtimes in Wallaroo, so the input_schema and output_schema parameters are optional.
| Parameter | Type | Description |
|---|---|---|
name | string (Required) | The name of the model. Model names are unique per workspace. Models that are uploaded with the same name are assigned as a new version of the model. |
path | string (Required) | The path to the model file being uploaded. |
framework | string (Required) | Set as the Framework.TENSORFLOW. |
input_schema | pyarrow.lib.Schema (Optional) | The input schema in Apache Arrow schema format. |
output_schema | pyarrow.lib.Schema (Optional) | The output schema in Apache Arrow schema format. |
convert_wait | bool (Optional) (Default: True) | Not required for native runtimes.
|
TensorFlow File Format
TensorFlow models are .zip file of the SavedModel format. For example, the Aloha sample TensorFlow model is stored in the directory alohacnnlstm:
├── saved_model.pb
└── variables
├── variables.data-00000-of-00002
├── variables.data-00001-of-00002
└── variables.index
This is compressed into the .zip file alohacnnlstm.zip with the following command:
zip -r alohacnnlstm.zip alohacnnlstm/
model = wl.upload_model(model_name, model_file_name, Framework.TENSORFLOW).configure("tensorflow")
Deploy a model
Now that we have a model that we want to use we will create a deployment for it.
We will tell the deployment we are using a tensorflow model and give the deployment name and the configuration we want for the deployment.
aloha_pipeline.add_model_step(model)
| name | tensorflowuploadexampletxdg |
|---|---|
| created | 2023-07-13 18:29:16.306846+00:00 |
| last_updated | 2023-07-13 18:29:16.306846+00:00 |
| deployed | (none) |
| tags | |
| versions | 755813ea-cb7f-4e9e-9075-2f5eea0f883f |
| steps |
aloha_pipeline.deploy()
| name | tensorflowuploadexampletxdg |
|---|---|
| created | 2023-07-13 18:29:16.306846+00:00 |
| last_updated | 2023-07-13 18:29:21.045528+00:00 |
| deployed | True |
| tags | |
| versions | ea2f9aba-a21f-46c1-8dc6-677147af6e1e, 755813ea-cb7f-4e9e-9075-2f5eea0f883f |
| steps | tensorflowuploadexampletxdg |
We can verify that the pipeline is running and list what models are associated with it.
aloha_pipeline.status()
{'status': 'Running',
'details': [],
'engines': [{'ip': '10.244.9.216',
'name': 'engine-57fb6bd474-tm9xr',
'status': 'Running',
'reason': None,
'details': [],
'pipeline_statuses': {'pipelines': [{'id': 'tensorflowuploadexampletxdg',
'status': 'Running'}]},
'model_statuses': {'models': [{'name': 'tensorflowuploadexampletxdg',
'version': 'd3e73b1e-31d0-4f27-89d0-a135814c4cfe',
'sha': 'd71d9ffc61aaac58c2b1ed70a2db13d1416fb9d3f5b891e5e4e2e97180fe22f8',
'status': 'Running'}]}}],
'engine_lbs': [{'ip': '10.244.9.217',
'name': 'engine-lb-584f54c899-9bf5d',
'status': 'Running',
'reason': None,
'details': []}],
'sidekicks': []}
Interferences
Infer 1 row
Now that the pipeline is deployed and our Aloha model is in place, we’ll perform a smoke test to verify the pipeline is up and running properly. We’ll use the infer_from_file command to load a single encoded URL into the inference engine and print the results back out.
The result should tell us that the tokenized URL is legitimate (0) or fraud (1). This sample data should return close to 1 in out.main.
smoke_test = pd.DataFrame.from_records(
[
{
"text_input":[
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
28,
16,
32,
23,
29,
32,
30,
19,
26,
17
]
}
]
)
result = aloha_pipeline.infer(smoke_test)
display(result.loc[:, ["time","out.main"]])
| time | out.main | |
|---|---|---|
| 0 | 2023-07-13 18:29:32.824 | [0.997564] |
Undeploy Pipeline
When finished with our tests, we will undeploy the pipeline so we have the Kubernetes resources back for other tasks. Note that if the deployment variable is unchanged aloha_pipeline.deploy() will restart the inference engine in the same configuration as before.
aloha_pipeline.undeploy()
| name | tensorflowuploadexampletxdg |
|---|---|
| created | 2023-07-13 18:29:16.306846+00:00 |
| last_updated | 2023-07-13 18:29:21.045528+00:00 |
| deployed | False |
| tags | |
| versions | ea2f9aba-a21f-46c1-8dc6-677147af6e1e, 755813ea-cb7f-4e9e-9075-2f5eea0f883f |
| steps | tensorflowuploadexampletxdg |
8 - Wallaroo SDK Upload Tutorials: Tensorflow Keras
How to upload different Tensorflow Keras models to Wallaroo.
The following tutorials cover how to upload sample Tensorflow Keras models.
| Parameter | Description |
|---|---|
| Web Site | https://www.tensorflow.org/api_docs/python/tf/keras/Model |
| Supported Libraries |
|
| Framework | Framework.KERAS aka keras |
| Supported File Types | SavedModel format as .zip file and HDF5 format |
| Runtime | Containerized aka mlflow |
TensorFlow Keras SavedModel Format
TensorFlow Keras SavedModel models are .zip file of the SavedModel format. For example, the Aloha sample TensorFlow model is stored in the directory alohacnnlstm:
├── saved_model.pb
└── variables
├── variables.data-00000-of-00002
├── variables.data-00001-of-00002
└── variables.index
This is compressed into the .zip file alohacnnlstm.zip with the following command:
zip -r alohacnnlstm.zip alohacnnlstm/
See the SavedModel guide for full details.
TensorFlow Keras H5 Format
Wallaroo supports the H5 for Tensorflow Keras models.
8.1 - Wallaroo SDK Upload Tutorial: Keras Sequential Single IO
How to upload a Keras Sequential Single IO model to Wallaroo via the Wallaroo SDK
This tutorial can be downloaded as part of the Wallaroo Tutorials repository.
Wallaroo Model Upload via the Wallaroo SDK: TensorFlow keras Sequential Single IO
The following tutorial demonstrates how to upload a TensorFlow keras Sequential Single IO model to a Wallaroo instance.
Tutorial Goals
Demonstrate the following:
- Upload a TensorFlow keras Sequential Single IO to a Wallaroo instance.
- Create a pipeline and add the model as a pipeline step.
- Perform a sample inference.
Prerequisites
- A Wallaroo version 2023.2.1 or above instance.
References
- Wallaroo MLOps API Essentials Guide: Model Upload and Registrations
- Wallaroo API Connection Guide
- DNS Integration Guide
Tutorial Steps
Import Libraries
The first step is to import the libraries we’ll be using. These are included by default in the Wallaroo instance’s JupyterHub service.
import json
import os
import pickle
import wallaroo
from wallaroo.pipeline import Pipeline
from wallaroo.deployment_config import DeploymentConfigBuilder
from wallaroo.framework import Framework
from wallaroo.object import EntityNotFoundError
import os
os.environ["MODELS_ENABLED"] = "true"
import pyarrow as pa
import numpy as np
import pandas as pd
from sklearn.datasets import load_iris
from sklearn.linear_model import LogisticRegression
import datetime
Open a Connection to Wallaroo
The next step is connect to Wallaroo through the Wallaroo client. The Python library is included in the Wallaroo install and available through the Jupyter Hub interface provided with your Wallaroo environment.
This is accomplished using the wallaroo.Client() command, which provides a URL to grant the SDK permission to your specific Wallaroo environment. When displayed, enter the URL into a browser and confirm permissions. Store the connection into a variable that can be referenced later.
If logging into the Wallaroo instance through the internal JupyterHub service, use wl = wallaroo.Client(). If logging in externally, update the wallarooPrefix and wallarooSuffix variables with the proper DNS information. For more information on Wallaroo DNS settings, see the Wallaroo DNS Integration Guide.
wl = wallaroo.Client()
wallarooPrefix = ""
wallarooSuffix = "autoscale-uat-ee.wallaroo.dev"
wl = wallaroo.Client(api_endpoint=f"https://{wallarooPrefix}api.{wallarooSuffix}",
auth_endpoint=f"https://{wallarooPrefix}keycloak.{wallarooSuffix}",
auth_type="sso")
Set Variables and Helper Functions
We’ll set the name of our workspace, pipeline, models and files. Workspace names must be unique across the Wallaroo workspace. For this, we’ll add in a randomly generated 4 characters to the workspace name to prevent collisions with other users’ workspaces. If running this tutorial, we recommend hard coding the workspace name so it will function in the same workspace each time it’s run.
We’ll set up some helper functions that will either use existing workspaces and pipelines, or create them if they do not already exist.
def get_workspace(name):
workspace = None
for ws in wl.list_workspaces():
if ws.name() == name:
workspace= ws
if(workspace == None):
workspace = wl.create_workspace(name)
return workspace
def get_pipeline(name):
try:
pipeline = wl.pipelines_by_name(name)[0]
except EntityNotFoundError:
pipeline = wl.build_pipeline(name)
return pipeline
import string
import random
# make a random 4 character suffix to prevent overwriting other user's workspaces
suffix= ''.join(random.choice(string.ascii_lowercase) for i in range(4))
workspace_name = f'keras-sequential-single-io{suffix}'
pipeline_name = f'keras-sequential-single-io'
model_name = 'keras-sequential-single-io'
model_file_name = 'models/model-auto-conversion_keras_single_io_keras_sequential_model.h5'
Create Workspace and Pipeline
We will now create the Wallaroo workspace to store our model and set it as the current workspace. Future commands will default to this workspace for pipeline creation, model uploads, etc. We’ll create our Wallaroo pipeline to deploy our model.
workspace = get_workspace(workspace_name)
wl.set_current_workspace(workspace)
pipeline = get_pipeline(pipeline_name)
Configure Data Schemas
The following parameters are required for TensorFlow keras models. Note that while some fields are considered as optional for the upload_model method, they are required for proper uploading of a TensorFlow Keras model to Wallaroo.
| Parameter | Type | Description |
|---|---|---|
name | string (Required) | The name of the model. Model names are unique per workspace. Models that are uploaded with the same name are assigned as a new version of the model. |
path | string (Required) | The path to the model file being uploaded. |
framework | string (Upload Method Optional, TensorFlow keras model Required) | Set as the Framework.KERAS. |
input_schema | pyarrow.lib.Schema (Upload Method Optional, TensorFlow Keras model Required) | The input schema in Apache Arrow schema format. |
output_schema | pyarrow.lib.Schema (Upload Method Optional, TensorFlow Keras model Required) | The output schema in Apache Arrow schema format. |
convert_wait | bool (Upload Method Optional, TensorFlow model Optional) (Default: True) |
|
Once the upload process starts, the model is containerized by the Wallaroo instance. This process may take up to 10 minutes.
input_schema = pa.schema([
pa.field('input', pa.list_(pa.float64(), list_size=10))
])
output_schema = pa.schema([
pa.field('output', pa.list_(pa.float64(), list_size=32))
])
Upload Model
The model will be uploaded with the framework set as Framework.KERAS.
framework=Framework.KERAS
model = wl.upload_model(model_name,
model_file_name,
framework=framework,
input_schema=input_schema,
output_schema=output_schema)
model
Waiting for model conversion... It may take up to 10.0min.
Model is Pending conversion.Converting..Pending conversion.Converting.............Ready.
| Name | keras-sequential-single-io |
| Version | 79e34aa4-ce71-4c3a-90fc-79bfa0a40052 |
| File Name | model-auto-conversion_keras_single_io_keras_sequential_model.h5 |
| SHA | f7e49538e38bebe066ce8df97bac8be239ae8c7d2733e500c8cd633706ae95a8 |
| Status | ready |
| Image Path | proxy.replicated.com/proxy/wallaroo/ghcr.io/wallaroolabs/mlflow-deploy:v2023.3.0-main-3509 |
| Updated At | 2023-13-Jul 17:50:07 |
model.config().runtime()
'mlflow'
Deploy Pipeline
The model is uploaded and ready for use. We’ll add it as a step in our pipeline, then deploy the pipeline. For this example we’re allocated 0.25 cpu and 4 Gi RAM to the pipeline through the pipeline’s deployment configuration.
deployment_config = DeploymentConfigBuilder() \
.cpus(0.25).memory('1Gi') \
.build()
# clear the pipeline if used in a previous tutorial
pipeline.undeploy()
pipeline.clear()
pipeline.add_model_step(model)
pipeline.deploy(deployment_config=deployment_config)
pipeline.status()
{'status': 'Running',
'details': [],
'engines': [{'ip': '10.244.9.178',
'name': 'engine-75cb64bc94-lc74f',
'status': 'Running',
'reason': None,
'details': [],
'pipeline_statuses': {'pipelines': [{'id': 'keras-sequential-single-io',
'status': 'Running'}]},
'model_statuses': {'models': [{'name': 'keras-sequential-single-io',
'version': '79e34aa4-ce71-4c3a-90fc-79bfa0a40052',
'sha': 'f7e49538e38bebe066ce8df97bac8be239ae8c7d2733e500c8cd633706ae95a8',
'status': 'Running'}]}}],
'engine_lbs': [{'ip': '10.244.9.179',
'name': 'engine-lb-584f54c899-96vb6',
'status': 'Running',
'reason': None,
'details': []}],
'sidekicks': [{'ip': '10.244.9.180',
'name': 'engine-sidekick-keras-sequential-single-io-268-84cff895cf-bm2tl',
'status': 'Running',
'reason': None,
'details': [],
'statuses': '\n'}]}
Run Inference
A sample inference will be run. First the pandas DataFrame used for the inference is created, then the inference run through the pipeline’s infer method.
input_data = np.random.rand(10, 10)
mock_dataframe = pd.DataFrame({
"input": input_data.tolist()
})
mock_dataframe
| input | |
|---|---|
| 0 | [0.5809853116232783, 0.14701285145269583, 0.58... |
| 1 | [0.7257919427827948, 0.7589800713851653, 0.297... |
| 2 | [0.3764542634917982, 0.5494748793973108, 0.485... |
| 3 | [0.5025570851921953, 0.8837007217828465, 0.406... |
| 4 | [0.0866396068940275, 0.10670979528669655, 0.09... |
| 5 | [0.8860315511881905, 0.6706861365257704, 0.412... |
| 6 | [0.37994954016981175, 0.7429705751348403, 0.12... |
| 7 | [0.49027013691203447, 0.7105289734919781, 0.99... |
| 8 | [0.4446469438043267, 0.09139454740740094, 0.24... |
| 9 | [0.932824358657356, 0.3388034065847041, 0.0416... |
pipeline.infer(mock_dataframe)
| time | in.input | out.output | check_failures | |
|---|---|---|---|---|
| 0 | 2023-07-13 17:50:42.609 | [0.5809853116, 0.1470128515, 0.5859677386, 0.2... | [0.025315184146165848, 0.023196307942271233, 0... | 0 |
| 1 | 2023-07-13 17:50:42.609 | [0.7257919428, 0.7589800714, 0.297258173, 0.39... | [0.022579584270715714, 0.026824792847037315, 0... | 0 |
| 2 | 2023-07-13 17:50:42.609 | [0.3764542635, 0.5494748794, 0.4852001553, 0.8... | [0.02744304947555065, 0.03327963128685951, 0.0... | 0 |
| 3 | 2023-07-13 17:50:42.609 | [0.5025570852, 0.8837007218, 0.4064710644, 0.5... | [0.03851581737399101, 0.021599330008029938, 0.... | 0 |
| 4 | 2023-07-13 17:50:42.609 | [0.0866396069, 0.1067097953, 0.0918865633, 0.2... | [0.020835522562265396, 0.034067943692207336, 0... | 0 |
| 5 | 2023-07-13 17:50:42.609 | [0.8860315512, 0.6706861365, 0.4123840879, 0.2... | [0.034137945622205734, 0.01922944001853466, 0.... | 0 |
| 6 | 2023-07-13 17:50:42.609 | [0.3799495402, 0.7429705751, 0.1207460912, 0.3... | [0.03986137732863426, 0.019290560856461525, 0.... | 0 |
| 7 | 2023-07-13 17:50:42.609 | [0.4902701369, 0.7105289735, 0.9948842471, 0.2... | [0.026285773143172264, 0.02646280638873577, 0.... | 0 |
| 8 | 2023-07-13 17:50:42.609 | [0.4446469438, 0.0913945474, 0.24660973, 0.456... | [0.023244783282279968, 0.033836156129837036, 0... | 0 |
| 9 | 2023-07-13 17:50:42.609 | [0.9328243587, 0.3388034066, 0.0416730168, 0.4... | [0.02200852520763874, 0.027223799377679825, 0.... | 0 |
Undeploy Pipelines
With the tutorial complete, the pipeline is undeployed to return the resources back to the cluster.
pipeline.undeploy()
| name | keras-sequential-single-io |
|---|---|
| created | 2023-07-13 17:50:13.553180+00:00 |
| last_updated | 2023-07-13 17:50:13.553180+00:00 |
| deployed | False |
| tags | |
| versions | e04712da-19d6-40d1-88d3-2dab8ab950e1 |
| steps | keras-sequential-single-io |
9 - Wallaroo SDK Upload Tutorials: XGBoost
How to upload different XGBoost models to Wallaroo.
The following tutorials cover how to upload sample XGBoost models.
| Parameter | Description |
|---|---|
| Web Site | https://xgboost.ai/ |
| Supported Libraries | xgboost==1.7.4 |
| Framework | Framework.XGBOOST aka xgboost |
| Supported File Types | pickle (XGB files are not supported.) |
| Runtime | Containerized aka tensorflow / mlflow |
XGBoost Schema Inputs
XGBoost schema follows a different format than other models. To prevent inputs from being out of order, the inputs should be submitted in a single row in the order the model is trained to accept, with all of the data types being the same. If a model is originally trained to accept inputs of different data types, it will need to be retrained to only accept one data type for each column - typically pa.float64() is a good choice.
For example, the following DataFrame has 4 columns, each column a float.
| sepal length (cm) | sepal width (cm) | petal length (cm) | petal width (cm) | |
|---|---|---|---|---|
| 0 | 5.1 | 3.5 | 1.4 | 0.2 |
| 1 | 4.9 | 3.0 | 1.4 | 0.2 |
For submission to an XGBoost model, the data input schema will be a single array with 4 float values.
input_schema = pa.schema([
pa.field('inputs', pa.list_(pa.float64(), list_size=4))
])
When submitting as an inference, the DataFrame is converted to rows with the column data expressed as a single array. The data must be in the same order as the model expects, which is why the data is submitted as a single array rather than JSON labeled columns: this insures that the data is submitted in the exact order as the model is trained to accept.
Original DataFrame:
| sepal length (cm) | sepal width (cm) | petal length (cm) | petal width (cm) | |
|---|---|---|---|---|
| 0 | 5.1 | 3.5 | 1.4 | 0.2 |
| 1 | 4.9 | 3.0 | 1.4 | 0.2 |
Converted DataFrame:
| inputs | |
|---|---|
| 0 | [5.1, 3.5, 1.4, 0.2] |
| 1 | [4.9, 3.0, 1.4, 0.2] |
XGBoost Schema Outputs
Outputs for XGBoost are labeled based on the trained model outputs. For this example, the output is simply a single output listed as output. In the Wallaroo inference result, it is grouped with the metadata out as out.output.
output_schema = pa.schema([
pa.field('output', pa.int32())
])
pipeline.infer(dataframe)
| time | in.inputs | out.output | check_failures | |
|---|---|---|---|---|
| 0 | 2023-07-05 15:11:29.776 | [5.1, 3.5, 1.4, 0.2] | 0 | 0 |
| 1 | 2023-07-05 15:11:29.776 | [4.9, 3.0, 1.4, 0.2] | 0 | 0 |
9.1 - Wallaroo SDK Upload Tutorial: RF Regressor Tutorial
How to upload a RF Regressor Tutorial to Wallaroo
This tutorial can be downloaded as part of the Wallaroo Tutorials repository.
Wallaroo Model Upload via the Wallaroo SDK: XGBoost RF Regressor
The following tutorial demonstrates how to upload a XGBoost RF Regressor model to a Wallaroo instance.
Tutorial Goals
Demonstrate the following:
- Upload a XGBoost RF Regressor model to a Wallaroo instance.
- Create a pipeline and add the model as a pipeline step.
- Perform a sample inference.
Prerequisites
- A Wallaroo version 2023.2.1 or above instance.
References
- Wallaroo MLOps API Essentials Guide: Model Upload and Registrations
- Wallaroo API Connection Guide
- DNS Integration Guide
Tutorial Steps
Import Libraries
The first step is to import the libraries we’ll be using. These are included by default in the Wallaroo instance’s JupyterHub service.
import json
import os
import pickle
import wallaroo
from wallaroo.pipeline import Pipeline
from wallaroo.deployment_config import DeploymentConfigBuilder
from wallaroo.object import EntityNotFoundError
from wallaroo.framework import Framework
import os
os.environ["MODELS_ENABLED"] = "true"
import pyarrow as pa
import numpy as np
import pandas as pd
Open a Connection to Wallaroo
The next step is connect to Wallaroo through the Wallaroo client. The Python library is included in the Wallaroo install and available through the Jupyter Hub interface provided with your Wallaroo environment.
This is accomplished using the wallaroo.Client() command, which provides a URL to grant the SDK permission to your specific Wallaroo environment. When displayed, enter the URL into a browser and confirm permissions. Store the connection into a variable that can be referenced later.
If logging into the Wallaroo instance through the internal JupyterHub service, use wl = wallaroo.Client(). If logging in externally, update the wallarooPrefix and wallarooSuffix variables with the proper DNS information. For more information on Wallaroo DNS settings, see the Wallaroo DNS Integration Guide.
wl = wallaroo.Client()
wallarooPrefix = ""
wallarooSuffix = "autoscale-uat-ee.wallaroo.dev"
wl = wallaroo.Client(api_endpoint=f"https://{wallarooPrefix}api.{wallarooSuffix}",
auth_endpoint=f"https://{wallarooPrefix}keycloak.{wallarooSuffix}",
auth_type="sso")
Set Variables and Helper Functions
We’ll set the name of our workspace, pipeline, models and files. Workspace names must be unique across the Wallaroo workspace. For this, we’ll add in a randomly generated 4 characters to the workspace name to prevent collisions with other users’ workspaces. If running this tutorial, we recommend hard coding the workspace name so it will function in the same workspace each time it’s run.
We’ll set up some helper functions that will either use existing workspaces and pipelines, or create them if they do not already exist.
def get_workspace(name):
workspace = None
for ws in wl.list_workspaces():
if ws.name() == name:
workspace= ws
if(workspace == None):
workspace = wl.create_workspace(name)
return workspace
def get_pipeline(name):
try:
pipeline = wl.pipelines_by_name(name)[0]
except EntityNotFoundError:
pipeline = wl.build_pipeline(name)
return pipeline
import string
import random
# make a random 4 character suffix to prevent overwriting other user's workspaces
suffix= ''.join(random.choice(string.ascii_lowercase) for i in range(4))
workspace_name = f'xgboost-rf-regressor{suffix}'
pipeline_name = f'xgboost-rf-regressor'
model_name = 'xgboost-rf-regressor'
model_file_name = 'models/model-auto-conversion_xgboost_xgb_rf_regressor_diabetes.pkl'
Create Workspace and Pipeline
We will now create the Wallaroo workspace to store our model and set it as the current workspace. Future commands will default to this workspace for pipeline creation, model uploads, etc. We’ll create our Wallaroo pipeline to deploy our model.
workspace = get_workspace(workspace_name)
wl.set_current_workspace(workspace)
pipeline = get_pipeline(pipeline_name)
Configure Data Schemas
XGBoost models are uploaded to Wallaroo through the Wallaroo Client upload_model method.
Upload XGBoost Model Parameters
The following parameters are required for XGBoost models. Note that while some fields are considered as optional for the upload_model method, they are required for proper uploading of a XGBoost model to Wallaroo.
| Parameter | Type | Description |
|---|---|---|
name | string (Required) | The name of the model. Model names are unique per workspace. Models that are uploaded with the same name are assigned as a new version of the model. |
path | string (Required) | The path to the model file being uploaded. |
framework | string (Upload Method Optional, SKLearn model Required) | Set as the Framework.XGBOOST. |
input_schema | pyarrow.lib.Schema (Upload Method Optional, SKLearn model Required) | The input schema in Apache Arrow schema format. |
output_schema | pyarrow.lib.Schema (Upload Method Optional, SKLearn model Required) | The output schema in Apache Arrow schema format. |
convert_wait | bool (Upload Method Optional, SKLearn model Optional) (Default: True) |
|
Once the upload process starts, the model is containerized by the Wallaroo instance. This process may take up to 10 minutes.
XGBoost Schema Inputs
XGBoost schema follows a different format than other models. To prevent inputs from being out of order, the inputs should be submitted in a single row in the order the model is trained to accept, with all of the data types being the same. If a model is originally trained to accept inputs of different data types, it will need to be retrained to only accept one data type for each column - typically pa.float64() is a good choice.
For example, the following DataFrame has 4 columns, each column a float.
| sepal length (cm) | sepal width (cm) | petal length (cm) | petal width (cm) | |
|---|---|---|---|---|
| 0 | 5.1 | 3.5 | 1.4 | 0.2 |
| 1 | 4.9 | 3.0 | 1.4 | 0.2 |
For submission to an XGBoost model, the data input schema will be a single array with 4 float values.
input_schema = pa.schema([
pa.field('inputs', pa.list_(pa.float64(), list_size=4))
])
When submitting as an inference, the DataFrame is converted to rows with the column data expressed as a single array. The data must be in the same order as the model expects, which is why the data is submitted as a single array rather than JSON labeled columns: this insures that the data is submitted in the exact order as the model is trained to accept.
Original DataFrame:
| sepal length (cm) | sepal width (cm) | petal length (cm) | petal width (cm) | |
|---|---|---|---|---|
| 0 | 5.1 | 3.5 | 1.4 | 0.2 |
| 1 | 4.9 | 3.0 | 1.4 | 0.2 |
Converted DataFrame:
| inputs | |
|---|---|
| 0 | [5.1, 3.5, 1.4, 0.2] |
| 1 | [4.9, 3.0, 1.4, 0.2] |
XGBoost Schema Outputs
Outputs for XGBoost are labeled based on the trained model outputs. For this example, the output is simply a single output listed as output. In the Wallaroo inference result, it is grouped with the metadata out as out.output.
output_schema = pa.schema([
pa.field('output', pa.int32())
])
pipeline.infer(dataframe)
| time | in.inputs | out.output | check_failures | |
|---|---|---|---|---|
| 0 | 2023-07-05 15:11:29.776 | [5.1, 3.5, 1.4, 0.2] | 0 | 0 |
| 1 | 2023-07-05 15:11:29.776 | [4.9, 3.0, 1.4, 0.2] | 0 | 0 |
input_schema = pa.schema([
pa.field('inputs', pa.list_(pa.float64(), list_size=10))
])
output_schema = pa.schema([
pa.field('output', pa.float64())
])
Upload Model
The model will be uploaded with the framework set as Framework.XGBOOST.
model = wl.upload_model(model_name,
model_file_name,
framework=Framework.XGBOOST,
input_schema=input_schema,
output_schema=output_schema)
model
Waiting for model conversion... It may take up to 10.0min.
Model is Pending conversion.Converting..Pending conversion.Converting........Ready.
| Name | xgboost-rf-regressor |
| Version | 18786ea1-2964-4406-ad1b-2eea413326d8 |
| File Name | model-auto-conversion_xgboost_xgb_rf_regressor_diabetes.pkl |
| SHA | 461341d78d54a9bfc8e4faa94be6037aef15217974ba59bad92d31ef48e6bd99 |
| Status | ready |
| Image Path | proxy.replicated.com/proxy/wallaroo/ghcr.io/wallaroolabs/mlflow-deploy:v2023.3.0-main-3509 |
| Updated At | 2023-13-Jul 20:02:19 |
model.config().runtime()
'mlflow'
Deploy Pipeline
The model is uploaded and ready for use. We’ll add it as a step in our pipeline, then deploy the pipeline. For this example we’re allocated 0.25 cpu and 4 Gi RAM to the pipeline through the pipeline’s deployment configuration.
deployment_config = DeploymentConfigBuilder() \
.cpus(0.25).memory('1Gi') \
.build()
# clear the pipeline if it was used before
pipeline.undeploy()
pipeline.clear()
pipeline.add_model_step(model)
pipeline.deploy(deployment_config=deployment_config)
pipeline.status()
{'status': 'Running',
'details': [],
'engines': [{'ip': '10.244.9.3',
'name': 'engine-68746578dc-zh47j',
'status': 'Running',
'reason': None,
'details': [],
'pipeline_statuses': {'pipelines': [{'id': 'xgboost-rf-regressor',
'status': 'Running'}]},
'model_statuses': {'models': [{'name': 'xgboost-rf-regressor',
'version': '18786ea1-2964-4406-ad1b-2eea413326d8',
'sha': '461341d78d54a9bfc8e4faa94be6037aef15217974ba59bad92d31ef48e6bd99',
'status': 'Running'}]}}],
'engine_lbs': [{'ip': '10.244.9.5',
'name': 'engine-lb-584f54c899-kxfbn',
'status': 'Running',
'reason': None,
'details': []}],
'sidekicks': [{'ip': '10.244.9.6',
'name': 'engine-sidekick-xgboost-rf-regressor-288-cfcc58bb4-b47cl',
'status': 'Running',
'reason': None,
'details': [],
'statuses': '\n'}]}
Run Inference
A sample inference will be run. First the pandas DataFrame used for the inference is created, then the inference run through the pipeline’s infer method.
data = pd.read_json('./data/test_xgb_rf-regressor.json')
display(data)
dataframe = pd.DataFrame({"inputs": data[:2].values.tolist()})
display(dataframe)
pipeline.infer(dataframe)
| age | sex | bmi | bp | s1 | s2 | s3 | s4 | s5 | s6 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.038076 | 0.050680 | 0.061696 | 0.021872 | -0.044223 | -0.034821 | -0.043401 | -0.002592 | 0.019907 | -0.017646 |
| 1 | -0.001882 | -0.044642 | -0.051474 | -0.026328 | -0.008449 | -0.019163 | 0.074412 | -0.039493 | -0.068332 | -0.092204 |
| inputs | |
|---|---|
| 0 | [0.0380759064, 0.0506801187, 0.0616962065, 0.0... |
| 1 | [-0.0018820165, -0.0446416365, -0.051474061200... |
| time | in.inputs | out.output | check_failures | |
|---|---|---|---|---|
| 0 | 2023-07-13 20:02:41.843 | [0.0380759064, 0.0506801187, 0.0616962065, 0.0... | 166.618774 | 0 |
| 1 | 2023-07-13 20:02:41.843 | [-0.0018820165, -0.0446416365, -0.0514740612, ... | 76.189583 | 0 |
Undeploy Pipelines
With the tutorial complete, the pipeline is undeployed to return the resources back to the cluster.
pipeline.undeploy()
| name | xgboost-rf-regressor |
|---|---|
| created | 2023-07-13 20:01:14.889724+00:00 |
| last_updated | 2023-07-13 20:02:25.945653+00:00 |
| deployed | False |
| tags | |
| versions | c9d392fa-96d7-4709-810f-beae105c879f, cb4f88e6-2c8c-4fef-beb5-5718bc64a2ea |
| steps | xgboost-rf-regressor |
9.2 - Wallaroo SDK Upload Tutorial: XGBoost Classification
How to upload a XGBoost Classification to Wallaroo
This tutorial can be downloaded as part of the Wallaroo Tutorials repository.
Wallaroo Model Upload via the Wallaroo SDK: XGBoost Classification
The following tutorial demonstrates how to upload a XGBoost Classification model to a Wallaroo instance.
Tutorial Goals
Demonstrate the following:
- Upload a XGBoost Classification model to a Wallaroo instance.
- Create a pipeline and add the model as a pipeline step.
- Perform a sample inference.
Prerequisites
- A Wallaroo version 2023.2.1 or above instance.
References
- Wallaroo MLOps API Essentials Guide: Model Upload and Registrations
- Wallaroo API Connection Guide
- DNS Integration Guide
Tutorial Steps
Import Libraries
The first step is to import the libraries we’ll be using. These are included by default in the Wallaroo instance’s JupyterHub service.
import json
import os
import pickle
import wallaroo
from wallaroo.pipeline import Pipeline
from wallaroo.deployment_config import DeploymentConfigBuilder
from wallaroo.object import EntityNotFoundError
from wallaroo.framework import Framework
import os
os.environ["MODELS_ENABLED"] = "true"
import pyarrow as pa
import numpy as np
import pandas as pd
Open a Connection to Wallaroo
The next step is connect to Wallaroo through the Wallaroo client. The Python library is included in the Wallaroo install and available through the Jupyter Hub interface provided with your Wallaroo environment.
This is accomplished using the wallaroo.Client() command, which provides a URL to grant the SDK permission to your specific Wallaroo environment. When displayed, enter the URL into a browser and confirm permissions. Store the connection into a variable that can be referenced later.
If logging into the Wallaroo instance through the internal JupyterHub service, use wl = wallaroo.Client(). If logging in externally, update the wallarooPrefix and wallarooSuffix variables with the proper DNS information. For more information on Wallaroo DNS settings, see the Wallaroo DNS Integration Guide.
wl = wallaroo.Client()
Set Variables and Helper Functions
We’ll set the name of our workspace, pipeline, models and files. Workspace names must be unique across the Wallaroo workspace. For this, we’ll add in a randomly generated 4 characters to the workspace name to prevent collisions with other users’ workspaces. If running this tutorial, we recommend hard coding the workspace name so it will function in the same workspace each time it’s run.
We’ll set up some helper functions that will either use existing workspaces and pipelines, or create them if they do not already exist.
def get_workspace(name):
workspace = None
for ws in wl.list_workspaces():
if ws.name() == name:
workspace= ws
if(workspace == None):
workspace = wl.create_workspace(name)
return workspace
def get_pipeline(name):
try:
pipeline = wl.pipelines_by_name(name)[0]
except EntityNotFoundError:
pipeline = wl.build_pipeline(name)
return pipeline
import string
import random
# make a random 4 character suffix to prevent overwriting other user's workspaces
suffix= ''.join(random.choice(string.ascii_lowercase) for i in range(4))
workspace_name = f'xgboost-classification{suffix}'
pipeline_name = f'xgboost-classification'
model_name = 'xgboost-classification'
model_file_name = './models/model-auto-conversion_xgboost_xgb_classification_iris.pkl'
Create Workspace and Pipeline
We will now create the Wallaroo workspace to store our model and set it as the current workspace. Future commands will default to this workspace for pipeline creation, model uploads, etc. We’ll create our Wallaroo pipeline to deploy our model.
workspace = get_workspace(workspace_name)
wl.set_current_workspace(workspace)
pipeline = get_pipeline(pipeline_name)
Configure Data Schemas
XGBoost models are uploaded to Wallaroo through the Wallaroo Client upload_model method.
Upload XGBoost Model Parameters
The following parameters are required for XGBoost models. Note that while some fields are considered as optional for the upload_model method, they are required for proper uploading of a XGBoost model to Wallaroo.
| Parameter | Type | Description |
|---|---|---|
name | string (Required) | The name of the model. Model names are unique per workspace. Models that are uploaded with the same name are assigned as a new version of the model. |
path | string (Required) | The path to the model file being uploaded. |
framework | string (Upload Method Optional, SKLearn model Required) | Set as the Framework.XGBOOST. |
input_schema | pyarrow.lib.Schema (Upload Method Optional, SKLearn model Required) | The input schema in Apache Arrow schema format. |
output_schema | pyarrow.lib.Schema (Upload Method Optional, SKLearn model Required) | The output schema in Apache Arrow schema format. |
convert_wait | bool (Upload Method Optional, SKLearn model Optional) (Default: True) |
|
Once the upload process starts, the model is containerized by the Wallaroo instance. This process may take up to 10 minutes.
XGBoost Schema Inputs
XGBoost schema follows a different format than other models. To prevent inputs from being out of order, the inputs should be submitted in a single row in the order the model is trained to accept, with all of the data types being the same. If a model is originally trained to accept inputs of different data types, it will need to be retrained to only accept one data type for each column - typically pa.float64() is a good choice.
For example, the following DataFrame has 4 columns, each column a float.
| sepal length (cm) | sepal width (cm) | petal length (cm) | petal width (cm) | |
|---|---|---|---|---|
| 0 | 5.1 | 3.5 | 1.4 | 0.2 |
| 1 | 4.9 | 3.0 | 1.4 | 0.2 |
For submission to an XGBoost model, the data input schema will be a single array with 4 float values.
input_schema = pa.schema([
pa.field('inputs', pa.list_(pa.float64(), list_size=4))
])
When submitting as an inference, the DataFrame is converted to rows with the column data expressed as a single array. The data must be in the same order as the model expects, which is why the data is submitted as a single array rather than JSON labeled columns: this insures that the data is submitted in the exact order as the model is trained to accept.
Original DataFrame:
| sepal length (cm) | sepal width (cm) | petal length (cm) | petal width (cm) | |
|---|---|---|---|---|
| 0 | 5.1 | 3.5 | 1.4 | 0.2 |
| 1 | 4.9 | 3.0 | 1.4 | 0.2 |
Converted DataFrame:
| inputs | |
|---|---|
| 0 | [5.1, 3.5, 1.4, 0.2] |
| 1 | [4.9, 3.0, 1.4, 0.2] |
XGBoost Schema Outputs
Outputs for XGBoost are labeled based on the trained model outputs. For this example, the output is simply a single output listed as output. In the Wallaroo inference result, it is grouped with the metadata out as out.output.
output_schema = pa.schema([
pa.field('output', pa.int32())
])
pipeline.infer(dataframe)
| time | in.inputs | out.output | check_failures | |
|---|---|---|---|---|
| 0 | 2023-07-05 15:11:29.776 | [5.1, 3.5, 1.4, 0.2] | 0 | 0 |
| 1 | 2023-07-05 15:11:29.776 | [4.9, 3.0, 1.4, 0.2] | 0 | 0 |
input_schema = pa.schema([
pa.field('inputs', pa.list_(pa.float64(), list_size=4))
])
output_schema = pa.schema([
pa.field('output', pa.float64())
])
Upload Model
The model will be uploaded with the framework set as Framework.XGBOOST.
model = wl.upload_model(model_name,
model_file_name,
framework=Framework.XGBOOST,
input_schema=input_schema,
output_schema=output_schema)
model
Waiting for model conversion... It may take up to 10.0min.
Model is Pending conversion........Converting.............Ready.
| Name | xgboost-classification |
| Version | 35b2bba5-cfe5-46f0-8a17-242e022fa9d1 |
| File Name | model-auto-conversion_xgboost_xgb_classification_iris.pkl |
| SHA | 4a1844c460e8c8503207305fb807e3a28e788062588925021807c54ee80cc7f9 |
| Status | ready |
| Image Path | proxy.replicated.com/proxy/wallaroo/ghcr.io/wallaroolabs/mlflow-deploy:v2023.3.0-main-3509 |
| Updated At | 2023-13-Jul 19:29:33 |
model.config().runtime()
'mlflow'
Deploy Pipeline
The model is uploaded and ready for use. We’ll add it as a step in our pipeline, then deploy the pipeline. For this example we’re allocated 0.25 cpu and 4 Gi RAM to the pipeline through the pipeline’s deployment configuration.
deployment_config = DeploymentConfigBuilder() \
.cpus(0.25).memory('1Gi') \
.build()
# clear the pipeline if it was used before
pipeline.undeploy()
pipeline.clear()
pipeline.add_model_step(model)
pipeline.deploy(deployment_config=deployment_config)
pipeline.status()
{'status': 'Running',
'details': [],
'engines': [{'ip': '10.244.9.234',
'name': 'engine-cf56c9c99-l76rt',
'status': 'Running',
'reason': None,
'details': [],
'pipeline_statuses': {'pipelines': [{'id': 'xgboost-classification',
'status': 'Running'}]},
'model_statuses': {'models': [{'name': 'xgboost-classification',
'version': '35b2bba5-cfe5-46f0-8a17-242e022fa9d1',
'sha': '4a1844c460e8c8503207305fb807e3a28e788062588925021807c54ee80cc7f9',
'status': 'Running'}]}}],
'engine_lbs': [{'ip': '10.244.9.235',
'name': 'engine-lb-584f54c899-c29jw',
'status': 'Running',
'reason': None,
'details': []}],
'sidekicks': [{'ip': '10.244.9.233',
'name': 'engine-sidekick-xgboost-classification-284-5fddbdc4c8-6vttd',
'status': 'Running',
'reason': None,
'details': [],
'statuses': '\n'}]}
Run Inference
A sample inference will be run. First the pandas DataFrame used for the inference is created, then the inference run through the pipeline’s infer method.
data = pd.read_json('data/test-xgboost-classification-data.json')
display(data)
dataframe = pd.DataFrame({"inputs": data[:2].values.tolist()})
display(dataframe)
results = pipeline.infer(dataframe)
display(results)
| sepal length (cm) | sepal width (cm) | petal length (cm) | petal width (cm) | |
|---|---|---|---|---|
| 0 | 5.1 | 3.5 | 1.4 | 0.2 |
| 1 | 4.9 | 3.0 | 1.4 | 0.2 |
| inputs | |
|---|---|
| 0 | [5.1, 3.5, 1.4, 0.2] |
| 1 | [4.9, 3.0, 1.4, 0.2] |
| time | in.inputs | out.output | check_failures | |
|---|---|---|---|---|
| 0 | 2023-07-13 19:29:51.614 | [5.1, 3.5, 1.4, 0.2] | 0.0 | 0 |
| 1 | 2023-07-13 19:29:51.614 | [4.9, 3.0, 1.4, 0.2] | 0.0 | 0 |
Undeploy Pipelines
With the tutorial complete, the pipeline is undeployed to return the resources back to the cluster.
pipeline.undeploy()
| name | xgboost-classification |
|---|---|
| created | 2023-07-13 19:27:34.750372+00:00 |
| last_updated | 2023-07-13 19:29:35.910554+00:00 |
| deployed | False |
| tags | |
| versions | 4d693511-388f-48a5-b0d1-e5aa5b11538a, 20e79a32-0739-413a-84c3-6695adc901ec |
| steps | xgboost-classification |
9.3 - Wallaroo SDK Upload Tutorial: XGBoost Regressor
How to upload a XGBoost Regressor to Wallaroo
This tutorial can be downloaded as part of the Wallaroo Tutorials repository.
Wallaroo Model Upload via the Wallaroo SDK: XGBoost Regressor
The following tutorial demonstrates how to upload a XGBoost Regressor model to a Wallaroo instance.
Tutorial Goals
Demonstrate the following:
- Upload a XGBoost Regressor model to a Wallaroo instance.
- Create a pipeline and add the model as a pipeline step.
- Perform a sample inference.
Prerequisites
- A Wallaroo version 2023.2.1 or above instance.
References
- Wallaroo MLOps API Essentials Guide: Model Upload and Registrations
- Wallaroo API Connection Guide
- DNS Integration Guide
Tutorial Steps
Import Libraries
The first step is to import the libraries we’ll be using. These are included by default in the Wallaroo instance’s JupyterHub service.
import json
import os
import pickle
import wallaroo
from wallaroo.pipeline import Pipeline
from wallaroo.deployment_config import DeploymentConfigBuilder
from wallaroo.object import EntityNotFoundError
from wallaroo.framework import Framework
import os
os.environ["MODELS_ENABLED"] = "true"
import pyarrow as pa
import numpy as np
import pandas as pd
Open a Connection to Wallaroo
The next step is connect to Wallaroo through the Wallaroo client. The Python library is included in the Wallaroo install and available through the Jupyter Hub interface provided with your Wallaroo environment.
This is accomplished using the wallaroo.Client() command, which provides a URL to grant the SDK permission to your specific Wallaroo environment. When displayed, enter the URL into a browser and confirm permissions. Store the connection into a variable that can be referenced later.
If logging into the Wallaroo instance through the internal JupyterHub service, use wl = wallaroo.Client(). If logging in externally, update the wallarooPrefix and wallarooSuffix variables with the proper DNS information. For more information on Wallaroo DNS settings, see the Wallaroo DNS Integration Guide.
wl = wallaroo.Client()
wl = wallaroo.Client()
wallarooPrefix = ""
wallarooSuffix = "autoscale-uat-ee.wallaroo.dev"
wl = wallaroo.Client(api_endpoint=f"https://{wallarooPrefix}api.{wallarooSuffix}",
auth_endpoint=f"https://{wallarooPrefix}keycloak.{wallarooSuffix}",
auth_type="sso")
Set Variables and Helper Functions
We’ll set the name of our workspace, pipeline, models and files. Workspace names must be unique across the Wallaroo workspace. For this, we’ll add in a randomly generated 4 characters to the workspace name to prevent collisions with other users’ workspaces. If running this tutorial, we recommend hard coding the workspace name so it will function in the same workspace each time it’s run.
We’ll set up some helper functions that will either use existing workspaces and pipelines, or create them if they do not already exist.
def get_workspace(name):
workspace = None
for ws in wl.list_workspaces():
if ws.name() == name:
workspace= ws
if(workspace == None):
workspace = wl.create_workspace(name)
return workspace
def get_pipeline(name):
try:
pipeline = wl.pipelines_by_name(name)[0]
except EntityNotFoundError:
pipeline = wl.build_pipeline(name)
return pipeline
import string
import random
# make a random 4 character suffix to prevent overwriting other user's workspaces
suffix= ''.join(random.choice(string.ascii_lowercase) for i in range(4))
workspace_name = f'xgboost-regressor{suffix}'
pipeline_name = f'xgboost-regressor'
model_name = 'xgboost-regressor'
model_file_name = 'models/model-auto-conversion_xgboost_xgb_regressor_diabetes.pkl'
Create Workspace and Pipeline
We will now create the Wallaroo workspace to store our model and set it as the current workspace. Future commands will default to this workspace for pipeline creation, model uploads, etc. We’ll create our Wallaroo pipeline to deploy our model.
workspace = get_workspace(workspace_name)
wl.set_current_workspace(workspace)
pipeline = get_pipeline(pipeline_name)
Configure Data Schemas
XGBoost models are uploaded to Wallaroo through the Wallaroo Client upload_model method.
Upload XGBoost Model Parameters
The following parameters are required for XGBoost models. Note that while some fields are considered as optional for the upload_model method, they are required for proper uploading of a XGBoost model to Wallaroo.
| Parameter | Type | Description |
|---|---|---|
name | string (Required) | The name of the model. Model names are unique per workspace. Models that are uploaded with the same name are assigned as a new version of the model. |
path | string (Required) | The path to the model file being uploaded. |
framework | string (Upload Method Optional, SKLearn model Required) | Set as the Framework.XGBOOST. |
input_schema | pyarrow.lib.Schema (Upload Method Optional, SKLearn model Required) | The input schema in Apache Arrow schema format. |
output_schema | pyarrow.lib.Schema (Upload Method Optional, SKLearn model Required) | The output schema in Apache Arrow schema format. |
convert_wait | bool (Upload Method Optional, SKLearn model Optional) (Default: True) |
|
Once the upload process starts, the model is containerized by the Wallaroo instance. This process may take up to 10 minutes.
XGBoost Schema Inputs
XGBoost schema follows a different format than other models. To prevent inputs from being out of order, the inputs should be submitted in a single row in the order the model is trained to accept, with all of the data types being the same. If a model is originally trained to accept inputs of different data types, it will need to be retrained to only accept one data type for each column - typically pa.float64() is a good choice.
For example, the following DataFrame has 4 columns, each column a float.
| sepal length (cm) | sepal width (cm) | petal length (cm) | petal width (cm) | |
|---|---|---|---|---|
| 0 | 5.1 | 3.5 | 1.4 | 0.2 |
| 1 | 4.9 | 3.0 | 1.4 | 0.2 |
For submission to an XGBoost model, the data input schema will be a single array with 4 float values.
input_schema = pa.schema([
pa.field('inputs', pa.list_(pa.float64(), list_size=4))
])
When submitting as an inference, the DataFrame is converted to rows with the column data expressed as a single array. The data must be in the same order as the model expects, which is why the data is submitted as a single array rather than JSON labeled columns: this insures that the data is submitted in the exact order as the model is trained to accept.
Original DataFrame:
| sepal length (cm) | sepal width (cm) | petal length (cm) | petal width (cm) | |
|---|---|---|---|---|
| 0 | 5.1 | 3.5 | 1.4 | 0.2 |
| 1 | 4.9 | 3.0 | 1.4 | 0.2 |
Converted DataFrame:
| inputs | |
|---|---|
| 0 | [5.1, 3.5, 1.4, 0.2] |
| 1 | [4.9, 3.0, 1.4, 0.2] |
XGBoost Schema Outputs
Outputs for XGBoost are labeled based on the trained model outputs. For this example, the output is simply a single output listed as output. In the Wallaroo inference result, it is grouped with the metadata out as out.output.
output_schema = pa.schema([
pa.field('output', pa.int32())
])
pipeline.infer(dataframe)
| time | in.inputs | out.output | check_failures | |
|---|---|---|---|---|
| 0 | 2023-07-05 15:11:29.776 | [5.1, 3.5, 1.4, 0.2] | 0 | 0 |
| 1 | 2023-07-05 15:11:29.776 | [4.9, 3.0, 1.4, 0.2] | 0 | 0 |
input_schema = pa.schema([
pa.field('inputs', pa.list_(pa.float64(), list_size=10))
])
output_schema = pa.schema([
pa.field('output', pa.float64())
])
Upload Model
The model will be uploaded with the framework set as Framework.XGBOOST.
model = wl.upload_model(model_name,
model_file_name,
framework=Framework.XGBOOST,
input_schema=input_schema,
output_schema=output_schema)
model
Waiting for model conversion... It may take up to 10.0min.
Model is Pending conversion.Converting..Pending conversion..Converting.........Ready.
| Name | xgboost-regressor |
| Version | bfa8afd7-6a57-4325-a538-01663d37d430 |
| File Name | model-auto-conversion_xgboost_xgb_regressor_diabetes.pkl |
| SHA | 17e2e4e635b287f1234ed7c59a8447faebf4d69d7974749113233d0007b08e29 |
| Status | ready |
| Image Path | proxy.replicated.com/proxy/wallaroo/ghcr.io/wallaroolabs/mlflow-deploy:v2023.3.0-main-3509 |
| Updated At | 2023-13-Jul 19:40:21 |
model.config().runtime()
'mlflow'
Deploy Pipeline
The model is uploaded and ready for use. We’ll add it as a step in our pipeline, then deploy the pipeline. For this example we’re allocated 0.25 cpu and 4 Gi RAM to the pipeline through the pipeline’s deployment configuration.
deployment_config = DeploymentConfigBuilder() \
.cpus(0.25).memory('1Gi') \
.build()
# clear the pipeline if it was used before
pipeline.undeploy()
pipeline.clear()
pipeline.add_model_step(model)
pipeline.deploy(deployment_config=deployment_config)
pipeline.status()
{'status': 'Running',
'details': [],
'engines': [{'ip': '10.244.9.240',
'name': 'engine-69c69947d8-zm6wv',
'status': 'Running',
'reason': None,
'details': [],
'pipeline_statuses': {'pipelines': [{'id': 'xgboost-regressor',
'status': 'Running'}]},
'model_statuses': {'models': [{'name': 'xgboost-regressor',
'version': 'bfa8afd7-6a57-4325-a538-01663d37d430',
'sha': '17e2e4e635b287f1234ed7c59a8447faebf4d69d7974749113233d0007b08e29',
'status': 'Running'}]}}],
'engine_lbs': [{'ip': '10.244.9.242',
'name': 'engine-lb-584f54c899-82tpj',
'status': 'Running',
'reason': None,
'details': []}],
'sidekicks': [{'ip': '10.244.9.241',
'name': 'engine-sidekick-xgboost-regressor-285-9b997df5c-dszld',
'status': 'Running',
'reason': None,
'details': [],
'statuses': '\n'}]}
Run Inference
A sample inference will be run. First the pandas DataFrame used for the inference is created, then the inference run through the pipeline’s infer method.
data = pd.read_json('./data/test_xgb_regressor.json')
display(data)
dataframe = pd.DataFrame({"inputs": data[:2].values.tolist()})
display(dataframe)
results = pipeline.infer(dataframe)
display(results)
| age | sex | bmi | bp | s1 | s2 | s3 | s4 | s5 | s6 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.038076 | 0.050680 | 0.061696 | 0.021872 | -0.044223 | -0.034821 | -0.043401 | -0.002592 | 0.019907 | -0.017646 |
| 1 | -0.001882 | -0.044642 | -0.051474 | -0.026328 | -0.008449 | -0.019163 | 0.074412 | -0.039493 | -0.068332 | -0.092204 |
| inputs | |
|---|---|
| 0 | [0.0380759064, 0.0506801187, 0.0616962065, 0.0... |
| 1 | [-0.0018820165, -0.0446416365, -0.051474061200... |
| time | in.inputs | out.output | check_failures | |
|---|---|---|---|---|
| 0 | 2023-07-13 19:41:07.855 | [0.0380759064, 0.0506801187, 0.0616962065, 0.0... | 151.001358 | 0 |
| 1 | 2023-07-13 19:41:07.855 | [-0.0018820165, -0.0446416365, -0.0514740612, ... | 74.999573 | 0 |
Undeploy Pipelines
With the tutorial complete, the pipeline is undeployed to return the resources back to the cluster.
pipeline.undeploy()
| name | xgboost-regressor |
|---|---|
| created | 2023-07-13 19:39:02.980261+00:00 |
| last_updated | 2023-07-13 19:40:25.981813+00:00 |
| deployed | False |
| tags | |
| versions | 4b8b79bc-e3d1-4204-a58c-5c604dd9a0c6, e20c1212-406b-4384-8308-93437b3f17f4 |
| steps | xgboost-regressor |
9.4 - Wallaroo SDK Upload Tutorial: XGBoost RF Classification
How to upload a XGBoost RF Classification to Wallaroo
This tutorial can be downloaded as part of the Wallaroo Tutorials repository.
Wallaroo Model Upload via the Wallaroo SDK: XGBoost RF Classification
The following tutorial demonstrates how to upload a XGBoost RF Classification model to a Wallaroo instance.
Tutorial Goals
Demonstrate the following:
- Upload a XGBoost RF Classification model to a Wallaroo instance.
- Create a pipeline and add the model as a pipeline step.
- Perform a sample inference.
Prerequisites
- A Wallaroo version 2023.2.1 or above instance.
References
- Wallaroo MLOps API Essentials Guide: Model Upload and Registrations
- Wallaroo API Connection Guide
- DNS Integration Guide
Tutorial Steps
Import Libraries
The first step is to import the libraries we’ll be using. These are included by default in the Wallaroo instance’s JupyterHub service.
import json
import os
import pickle
import wallaroo
from wallaroo.pipeline import Pipeline
from wallaroo.deployment_config import DeploymentConfigBuilder
from wallaroo.object import EntityNotFoundError
from wallaroo.framework import Framework
import os
os.environ["MODELS_ENABLED"] = "true"
import pyarrow as pa
import numpy as np
import pandas as pd
Open a Connection to Wallaroo
The next step is connect to Wallaroo through the Wallaroo client. The Python library is included in the Wallaroo install and available through the Jupyter Hub interface provided with your Wallaroo environment.
This is accomplished using the wallaroo.Client() command, which provides a URL to grant the SDK permission to your specific Wallaroo environment. When displayed, enter the URL into a browser and confirm permissions. Store the connection into a variable that can be referenced later.
If logging into the Wallaroo instance through the internal JupyterHub service, use wl = wallaroo.Client(). If logging in externally, update the wallarooPrefix and wallarooSuffix variables with the proper DNS information. For more information on Wallaroo DNS settings, see the Wallaroo DNS Integration Guide.
wl = wallaroo.Client()
Set Variables and Helper Functions
We’ll set the name of our workspace, pipeline, models and files. Workspace names must be unique across the Wallaroo workspace. For this, we’ll add in a randomly generated 4 characters to the workspace name to prevent collisions with other users’ workspaces. If running this tutorial, we recommend hard coding the workspace name so it will function in the same workspace each time it’s run.
We’ll set up some helper functions that will either use existing workspaces and pipelines, or create them if they do not already exist.
def get_workspace(name):
workspace = None
for ws in wl.list_workspaces():
if ws.name() == name:
workspace= ws
if(workspace == None):
workspace = wl.create_workspace(name)
return workspace
def get_pipeline(name):
try:
pipeline = wl.pipelines_by_name(name)[0]
except EntityNotFoundError:
pipeline = wl.build_pipeline(name)
return pipeline
import string
import random
# make a random 4 character suffix to prevent overwriting other user's workspaces
suffix= ''.join(random.choice(string.ascii_lowercase) for i in range(4))
workspace_name = f'xgboost-rf-classification{suffix}'
pipeline_name = f'xgboost-rf-classification'
model_name = 'xgboost-rf-classification'
model_file_name = './models/model-auto-conversion_xgboost_xgb_rf_classification_iris.pkl'
Create Workspace and Pipeline
We will now create the Wallaroo workspace to store our model and set it as the current workspace. Future commands will default to this workspace for pipeline creation, model uploads, etc. We’ll create our Wallaroo pipeline to deploy our model.
workspace = get_workspace(workspace_name)
wl.set_current_workspace(workspace)
pipeline = get_pipeline(pipeline_name)
Configure Data Schemas
XGBoost models are uploaded to Wallaroo through the Wallaroo Client upload_model method.
Upload XGBoost Model Parameters
The following parameters are required for XGBoost models. Note that while some fields are considered as optional for the upload_model method, they are required for proper uploading of a XGBoost model to Wallaroo.
| Parameter | Type | Description |
|---|---|---|
name | string (Required) | The name of the model. Model names are unique per workspace. Models that are uploaded with the same name are assigned as a new version of the model. |
path | string (Required) | The path to the model file being uploaded. |
framework | string (Upload Method Optional, SKLearn model Required) | Set as the Framework.XGBOOST. |
input_schema | pyarrow.lib.Schema (Upload Method Optional, SKLearn model Required) | The input schema in Apache Arrow schema format. |
output_schema | pyarrow.lib.Schema (Upload Method Optional, SKLearn model Required) | The output schema in Apache Arrow schema format. |
convert_wait | bool (Upload Method Optional, SKLearn model Optional) (Default: True) |
|
Once the upload process starts, the model is containerized by the Wallaroo instance. This process may take up to 10 minutes.
XGBoost Schema Inputs
XGBoost schema follows a different format than other models. To prevent inputs from being out of order, the inputs should be submitted in a single row in the order the model is trained to accept, with all of the data types being the same. If a model is originally trained to accept inputs of different data types, it will need to be retrained to only accept one data type for each column - typically pa.float64() is a good choice.
For example, the following DataFrame has 4 columns, each column a float.
| sepal length (cm) | sepal width (cm) | petal length (cm) | petal width (cm) | |
|---|---|---|---|---|
| 0 | 5.1 | 3.5 | 1.4 | 0.2 |
| 1 | 4.9 | 3.0 | 1.4 | 0.2 |
For submission to an XGBoost model, the data input schema will be a single array with 4 float values.
input_schema = pa.schema([
pa.field('inputs', pa.list_(pa.float64(), list_size=4))
])
When submitting as an inference, the DataFrame is converted to rows with the column data expressed as a single array. The data must be in the same order as the model expects, which is why the data is submitted as a single array rather than JSON labeled columns: this insures that the data is submitted in the exact order as the model is trained to accept.
Original DataFrame:
| sepal length (cm) | sepal width (cm) | petal length (cm) | petal width (cm) | |
|---|---|---|---|---|
| 0 | 5.1 | 3.5 | 1.4 | 0.2 |
| 1 | 4.9 | 3.0 | 1.4 | 0.2 |
Converted DataFrame:
| inputs | |
|---|---|
| 0 | [5.1, 3.5, 1.4, 0.2] |
| 1 | [4.9, 3.0, 1.4, 0.2] |
XGBoost Schema Outputs
Outputs for XGBoost are labeled based on the trained model outputs. For this example, the output is simply a single output listed as output. In the Wallaroo inference result, it is grouped with the metadata out as out.output.
output_schema = pa.schema([
pa.field('output', pa.int32())
])
pipeline.infer(dataframe)
| time | in.inputs | out.output | check_failures | |
|---|---|---|---|---|
| 0 | 2023-07-05 15:11:29.776 | [5.1, 3.5, 1.4, 0.2] | 0 | 0 |
| 1 | 2023-07-05 15:11:29.776 | [4.9, 3.0, 1.4, 0.2] | 0 | 0 |
input_schema = pa.schema([
pa.field('inputs', pa.list_(pa.float64(), list_size=4))
])
output_schema = pa.schema([
pa.field('output', pa.float64())
])
Upload Model
The model will be uploaded with the framework set as Framework.XGBOOST.
model = wl.upload_model(model_name,
model_file_name,
framework=Framework.XGBOOST,
input_schema=input_schema,
output_schema=output_schema)
model
Waiting for model conversion... It may take up to 10.0min.
Model is Pending conversion.Converting..Pending conversion.Converting........Ready.
| Name | xgboost-rf-classification |
| Version | b8c761bc-abeb-4105-988b-da1e73b609ee |
| File Name | model-auto-conversion_xgboost_xgb_rf_classification_iris.pkl |
| SHA | 2aeb56c084a279770abdd26d14caba949159698c1a5d260d2aafe73090e6cb03 |
| Status | ready |
| Image Path | proxy.replicated.com/proxy/wallaroo/ghcr.io/wallaroolabs/mlflow-deploy:v2023.3.0-main-3509 |
| Updated At | 2023-13-Jul 19:50:13 |
model.config().runtime()
'mlflow'
Deploy Pipeline
The model is uploaded and ready for use. We’ll add it as a step in our pipeline, then deploy the pipeline. For this example we’re allocated 0.25 cpu and 4 Gi RAM to the pipeline through the pipeline’s deployment configuration.
deployment_config = DeploymentConfigBuilder() \
.cpus(0.25).memory('1Gi') \
.build()
# clear the pipeline if it was used before
pipeline.undeploy()
pipeline.clear()
pipeline.add_model_step(model)
pipeline.deploy(deployment_config=deployment_config)
pipeline.status()
{'status': 'Running',
'details': [],
'engines': [{'ip': '10.244.9.251',
'name': 'engine-597bc987fb-kzvhv',
'status': 'Running',
'reason': None,
'details': [],
'pipeline_statuses': {'pipelines': [{'id': 'xgboost-rf-classification',
'status': 'Running'}]},
'model_statuses': {'models': [{'name': 'xgboost-rf-classification',
'version': 'b8c761bc-abeb-4105-988b-da1e73b609ee',
'sha': '2aeb56c084a279770abdd26d14caba949159698c1a5d260d2aafe73090e6cb03',
'status': 'Running'}]}}],
'engine_lbs': [{'ip': '10.244.9.250',
'name': 'engine-lb-584f54c899-xjmbp',
'status': 'Running',
'reason': None,
'details': []}],
'sidekicks': [{'ip': '10.244.9.249',
'name': 'engine-sidekick-xgboost-rf-classification-287-556b5c5d98-fbqr2',
'status': 'Running',
'reason': None,
'details': [],
'statuses': '\n'}]}
Run Inference
A sample inference will be run. First the pandas DataFrame used for the inference is created, then the inference run through the pipeline’s infer method.
data = pd.read_json('./data/test-xgboost-rf-classification-data.json')
data
dataframe = pd.DataFrame({"inputs": data[:2].values.tolist()})
dataframe
pipeline.infer(dataframe)
| time | in.inputs | out.output | check_failures | |
|---|---|---|---|---|
| 0 | 2023-07-13 19:50:34.747 | [5.1, 3.5, 1.4, 0.2] | 0.0 | 0 |
| 1 | 2023-07-13 19:50:34.747 | [4.9, 3.0, 1.4, 0.2] | 0.0 | 0 |
Undeploy Pipelines
With the tutorial complete, the pipeline is undeployed to return the resources back to the cluster.
pipeline.undeploy()
| name | xgboost-rf-classification |
|---|---|
| created | 2023-07-13 19:49:09.300062+00:00 |
| last_updated | 2023-07-13 19:50:17.818961+00:00 |
| deployed | False |
| tags | |
| versions | 19d76345-8bd8-4e2a-9c2a-3fa2550baf4d, cc753e7a-62e1-4750-80c8-3cbfb688b1e8 |
| steps | xgboost-rf-classification |