The following ML Model versions and Python libraries are supported by Wallaroo. When using the Wallaroo autoconversion library or working with a local version of the Wallaroo SDK, use the following versions for maximum compatibility.
The following data types are supported for transporting data to and from Wallaroo in the following run times:
ONNX
TensorFlow
MLFlow
Data Type Conditions
The following conditions apply to data types used in inference requests.
None or Null data types are not submitted. All fields must have submitted values that match their data type. For example, if the schema expects a float value, then some value of type float must be submitted and can not be None or Null. If a schema expects a string value, then some value of type string must be submitted, etc.
datetime data types must be converted to string.
ONNX models support multiple inputs only of the same data type.
Runtime
BFloat16*
Float16
Float32
Float64
ONNX
X
X
TensorFlow
X
X
X
MLFlow
X
X
X
* (Brain Float 16, represented internally as a f32)
Runtime
Int8
Int16
Int32
Int64
ONNX
X
X
X
X
TensorFlow
X
X
X
X
MLFlow
X
X
X
X
Runtime
Uint8
Uint16
Uint32
Uint64
ONNX
X
X
X
X
TensorFlow
X
X
X
X
MLFlow
X
X
X
X
Runtime
Boolean
Utf8 (String)
Complex 64
Complex 128
FixedSizeList*
ONNX
X
Tensor
X
X
X
MLFlow
X
X
X
* Fixed sized lists of any of the previously supported data types.
Wallaroo JupyterHub Python Libraries
When using the Wallaroo SDK, it is recommended that the Python modules used are the same as those used in the Wallaroo JupyterHub environments to ensure maximum compatibility. When installing modules in the Wallaroo JupyterHub environments, do not override the following modules or versions, as that may impact how the JupyterHub environments performance.
appdirs==1.4.4gql==3.4.0ipython==7.24.1matplotlib==3.5.0numpy==1.22.3orjson==3.8.0pandas==1.3.4pyarrow==9.0.0PyJWT==2.4.0python_dateutil==2.8.2PyYAML==6.0requests==2.25.1scipy==1.8.0seaborn==0.11.2tenacity==8.0.1# Required by gql?requests_toolbelt>=0.9.1<1# Required by the autogenerated ML Ops clienthttpx>=0.15.4<0.24.0attrs>=21.3.0# These are documented as part of the autogenerated ML Ops requirements# python = ^3.7# python-dateutil = ^2.8.0
1 - Wallaroo SDK Install Guides
How to install the Wallaroo SDK
The following guides demonstrate how to install the Wallaroo SDK in different environments. The Wallaroo SDK is installed by default into a Wallaroo instance for use with the JupyterHub service.
The Wallaroo SDK requires Python 3.8.6 and above and is available through the Wallaroo SDK Page.
Wallaroo JupyterHub Python Libraries
When using the Wallaroo SDK, it is recommended that the Python modules used are the same as those used in the Wallaroo JupyterHub environments to ensure maximum compatibility. When installing modules in the Wallaroo JupyterHub environments, do not override the following modules or versions, as that may impact how the JupyterHub environments performance.
appdirs==1.4.4gql==3.4.0ipython==7.24.1matplotlib==3.5.0numpy==1.22.3orjson==3.8.0pandas==1.3.4pyarrow==9.0.0PyJWT==2.4.0python_dateutil==2.8.2PyYAML==6.0requests==2.25.1scipy==1.8.0seaborn==0.11.2tenacity==8.0.1# Required by gql?requests_toolbelt>=0.9.1<1# Required by the autogenerated ML Ops clienthttpx>=0.15.4<0.24.0attrs>=21.3.0# These are documented as part of the autogenerated ML Ops requirements# python = ^3.7# python-dateutil = ^2.8.0
Supported Model Versions and Libraries
The following ML Model versions and Python libraries are supported by Wallaroo. When using the Wallaroo autoconversion library or working with a local version of the Wallaroo SDK, use the following versions for maximum compatibility.
The following data types are supported for transporting data to and from Wallaroo in the following run times:
ONNX
TensorFlow
MLFlow
Data Type Conditions
The following conditions apply to data types used in inference requests.
None or Null data types are not submitted. All fields must have submitted values that match their data type. For example, if the schema expects a float value, then some value of type float must be submitted and can not be None or Null. If a schema expects a string value, then some value of type string must be submitted, etc.
datetime data types must be converted to string.
ONNX models support multiple inputs only of the same data type.
Runtime
BFloat16*
Float16
Float32
Float64
ONNX
X
X
TensorFlow
X
X
X
MLFlow
X
X
X
* (Brain Float 16, represented internally as a f32)
Runtime
Int8
Int16
Int32
Int64
ONNX
X
X
X
X
TensorFlow
X
X
X
X
MLFlow
X
X
X
X
Runtime
Uint8
Uint16
Uint32
Uint64
ONNX
X
X
X
X
TensorFlow
X
X
X
X
MLFlow
X
X
X
X
Runtime
Boolean
Utf8 (String)
Complex 64
Complex 128
FixedSizeList*
ONNX
X
Tensor
X
X
X
MLFlow
X
X
X
* Fixed sized lists of any of the previously supported data types.
Organizations that develop machine learning models can deploy models to Wallaroo from AWS Sagemaker to a Wallaroo instance through the Wallaroo SDK. The following guide is created to assist users with installing the Wallaroo SDK and making a standard connection to a Wallaroo instance.
aloha-cnn-lstm.zip: A pre-trained open source model that uses an Aloha CNN LSTM model for classifying Domain names as being either legitimate or being used for nefarious purposes such as malware distribution.
Test Data Files:
data_1k.arrow: 1,000 records
data_25k.arrow: 25,000 records
For this example, a virtual python environment will be used. This will set the necessary libraries and specific Python version required.
Prerequisites
The following is required for this tutorial:
A Wallaroo instance version 2023.1 or later.
A AWS Sagemaker domain with a Notebook Instance.
Python 3.8.6 or later.
The following Python libraries installed:
os
wallaroo: The Wallaroo SDK. Included with the Wallaroo JupyterHub service by default.
polars: Polars for DataFrame with native Apache Arrow support
General Steps
For our example, we will perform the following:
Install Wallaroo SDK
Set up a Python virtual environment through conda with the libraries that enable the virtual environment for use in a Jupyter Hub environment.
Install the Wallaroo SDK.
Wallaroo SDK from remote JupyterHub Demonstration (Optional): The following steps are an optional exercise to demonstrate using the Wallaroo SDK from a remote connection. The entire tutorial can be found on the Wallaroo Tutorials repository.
Connect to a remote Wallaroo instance.
Create a workspace for our work.
Upload the Aloha model.
Create a pipeline that can ingest our submitted data, submit it to the model, and export the results
Run a sample inference through our pipeline by loading a file
Retrieve the external deployment URL. This sample Wallaroo instance has been configured to create external inference URLs for pipelines. For more information, see the External Inference URL Guide.
Run a sample inference through our pipeline’s external URL and store the results in a file. This assumes that the External Inference URLs have been enabled for the target Wallaroo instance.
Undeploy the pipeline and return resources back to the Wallaroo instance’s Kubernetes environment.
Install Wallaroo SDK
Set Up Virtual Python Environment
To set up the Python virtual environment for use of the Wallaroo SDK:
From AWS Sagemaker, select the Notebook instances.
For the list of notebook instances, select Open JupyterLab for the notebook instance to be used.
From the Launcher, select Terminal.
From a terminal shell, create the Python virtual environment with conda. Replace wallaroosdk with the name of the virtual environment as required by your organization. Note that Python 3.8.6 and above is specified as a requirement for Python libraries used with the Wallaroo SDK. The following will install the latest version of Python 3.8.
conda create -n wallaroosdk python=3.8
(Optional) If the shells have not been initialized with conda, use the following to initialize it. The following examples will use the bash shell.
Initialize the bash shell with conda with the command:
conda init bash
Launch the bash shell that has been initialized for conda:
bash
Activate the new environment.
conda activate wallaroosdk
Install the ipykernel library. This allows the JupyterHub notebooks to access the Python virtual environment as a kernel, and it required for the second part of this tutorial.
conda install ipykernel
Install the new virtual environment as a python kernel.
ipython kernel install --user --name=wallaroosdk
Install the Wallaroo SDK. This process may take several minutes while the other required Python libraries are added to the virtual environment.
IMPORTANT NOTE: The version of the Wallaroo SDK should match the Wallaroo instance. For example, this example connects to a Wallaroo Enterprise version 2023.1 instance, so the SDK version should be wallaroo==2023.1.0.
pip install wallaroo==2023.1.0
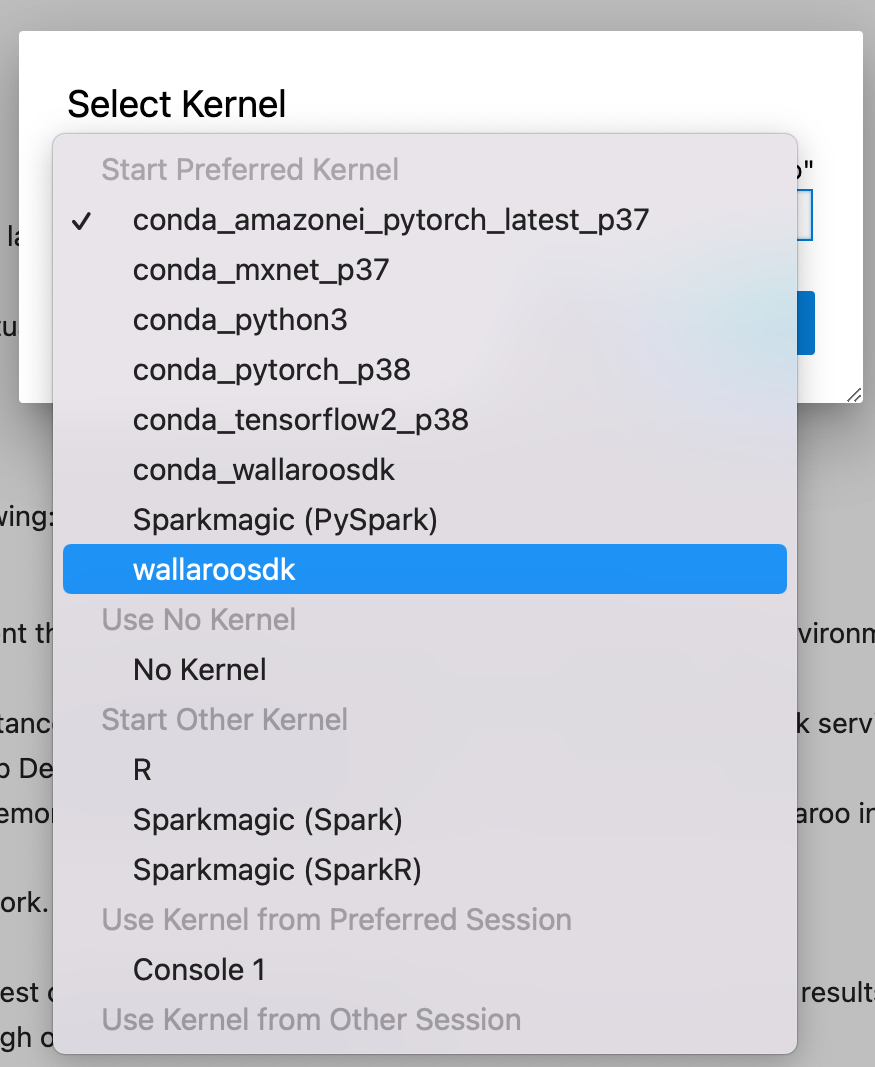
For organizations who will be using the Wallaroo SDK with Jupyter or similar services, the conda virtual environment has been installed, it can either be selected as a new Jupyter Notebook kernel, or the Notebook’s kernel can be set to an existing Jupyter notebook.
To use a new Notebook:
From the main menu, select File->New-Notebook.
From the Kernel selection dropbox, select the new virtual environment - in this case, wallaroosdk.
To update an existing Notebook to use the new virtual environment as a kernel:
From the main menu, select Kernel->Change Kernel.
Select the new kernel.
Sample Wallaroo Connection
With the Wallaroo Python SDK installed, remote commands and inferences can be performed through the following steps.
Open a Connection to Wallaroo
The first step is to connect to Wallaroo through the Wallaroo client.
This is accomplished using the wallaroo.Client(api_endpoint, auth_endpoint, auth_type command) command that connects to the Wallaroo instance services.
The Client method takes the following parameters:
api_endpoint (String): The URL to the Wallaroo instance API service.
auth_endpoint (String): The URL to the Wallaroo instance Keycloak service.
auth_type command (String): The authorization type. In this case, SSO.
The URLs are based on the Wallaroo Prefix and Wallaroo Suffix for the Wallaroo instance. For more information, see the DNS Integration Guide. In the example below, replace “YOUR PREFIX” and “YOUR SUFFIX” with the Wallaroo Prefix and Suffix, respectively.
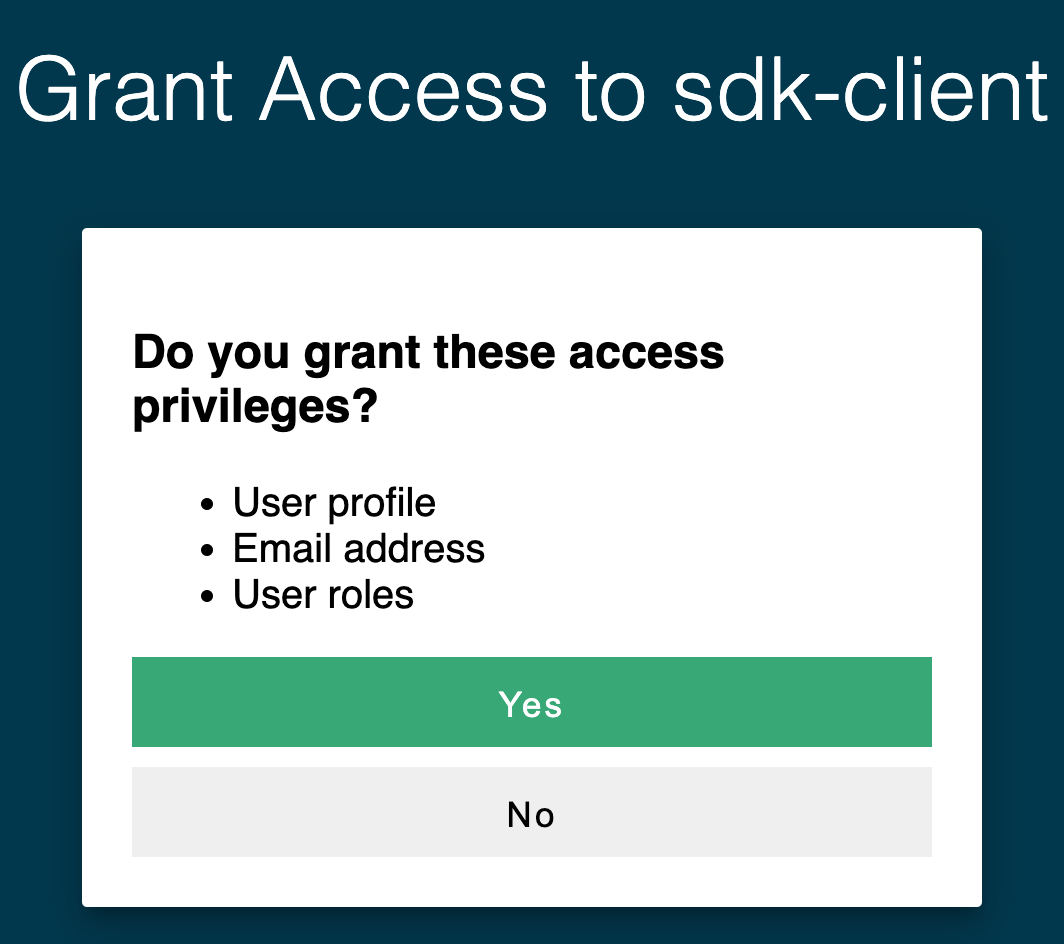
Once run, the wallaroo.Client command provides a URL to grant the SDK permission to your specific Wallaroo environment. When displayed, enter the URL into a browser and confirm permissions. Depending on the configuration of the Wallaroo instance, the user will either be presented with a login request to the Wallaroo instance or be authenticated through a broker such as Google, Github, etc. To use the broker, select it from the list under the username/password login forms. For more information on Wallaroo authentication configurations, see the Wallaroo Authentication Configuration Guides.
Once authenticated, the user will verify adding the device the user is establishing the connection from. Once both steps are complete, then the connection is granted.
The connection is stored in the variable wl for use in all other Wallaroo calls.
importwallaroofromwallaroo.objectimportEntityNotFoundError# to display dataframe tablesfromIPython.displayimportdisplay# used to display dataframe information without truncatingimportpandasaspdpd.set_option('display.max_colwidth', None)
importpyarrowaspa
For wallarooPrefix = "YOUR PREFIX." and wallarooSuffix = "YOUR SUFFIX", enter the prefix and suffix for your Wallaroo instance DNS name. If the prefix instance is blank, then it can be wallarooPrefix = "". Note that the prefix includes the . for proper formatting. For example, if the prefix is empty and the suffix is wallaroo.example.com, then the settings would be:
# SSO login through keycloakwallarooPrefix="YOUR PREFIX"wallarooSuffix="YOUR SUFFIX"wl=wallaroo.Client(api_endpoint=f"https://{wallarooPrefix}api.{wallarooSuffix}",
auth_endpoint=f"https://{wallarooPrefix}keycloak.{wallarooSuffix}",
auth_type="sso")
Wallaroo Remote SDK Examples
The following examples can be used by an organization to test using the Wallaroo SDK from a remote location from their Wallaroo instance. These examples show how to create workspaces, deploy pipelines, and perform inferences through the SDK and API.
Create the Workspace
We will create a workspace to work in and call it the sdkworkspace, then set it as current workspace environment. We’ll also create our pipeline in advance as sdkpipeline.
IMPORTANT NOTE: For this example, the Aloha model is stored in the file alohacnnlstm.zip. When using tensor based models, the zip file must match the name of the tensor directory. For example, if the tensor directory is alohacnnlstm, then the .zip file must be named alohacnnlstm.zip.
Now we will upload our model. Note that for this example we are applying the model from a .ZIP file. The Aloha model is a protobuf file that has been defined for evaluating web pages, and we will configure it to use data in the tensorflow format.
Now that we have a model that we want to use we will create a deployment for it.
We will tell the deployment we are using a tensorflow model and give the deployment name and the configuration we want for the deployment.
To do this, we’ll create our pipeline that can ingest the data, pass the data to our Aloha model, and give us a final output. We’ll call our pipeline externalsdkpipeline, then deploy it so it’s ready to receive data. The deployment process usually takes about 45 seconds.
Now that the pipeline is deployed and our Aloha model is in place, we’ll perform a smoke test to verify the pipeline is up and running properly. We’ll use the infer_from_file command to load a single encoded URL into the inference engine and print the results back out.
The result should tell us that the tokenized URL is legitimate (0) or fraud (1). This sample data should return close to 1.
We can also infer an entire batch as one request either with the Pipeline infer method with multiple rows, or loaded from a file using the Pipeline infer_from_file method. For this example, we will run a batch on 1,000 records using the file data_1k.arrow. This is an Apache Arrow table, which gives the added benefit of speed and lower file size as a binary file rather than a text JSON file.
We’ll infer the 1,000 records, then convert it to a DataFrame and display the first 5 to save space in our Jupyter Notebook.
Now that our smoke test is successful, let’s really give it some data. We have two inference files we can use:
data-1k.arrow: Contains 10,000 inferences
data-25k.arrow: Contains 25,000 inferences
These inference inputs are Apache Arrow tables, which Wallaroo can ingest natively. These are binary files, and are faster to transmit because of their smaller size compared to JSON.
We’ll pipe the data-25k.arrow file through the pipeline deployment URL, and place the results in a file named response.df. Note that for larger batches of 1,000 inferences or more can be difficult to view in Jupyter Hub because of its size, so we’ll only display the first 5 results of the inference.
When retrieving the pipeline inference URL through an external SDK connection, the External Inference URL will be returned. This URL will function provided that the Enable external URL inference endpoints is enabled. For more information, see the Wallaroo Model Endpoints Guide.
The API connection details can be retrieved through the Wallaroo client mlops() command. This will display the connection URL, bearer token, and other information. The bearer token is available for one hour before it expires.
For this example, the API connection details will be retrieved, then used to submit an inference request through the external inference URL retrieved earlier.
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 25.6M 100 20.8M 100 4874k 1123k 256k 0:00:19 0:00:19 --:--:-- 2278k
When finished with our tests, we will undeploy the pipeline so we have the Kubernetes resources back for other tasks. Note that if the deployment variable is unchanged pipeline.deploy() will restart the inference engine in the same configuration as before.
Installing the Wallaroo SDK into Azure ML Workspace
Organizations that use Azure ML for model training and development can deploy models to Wallaroo through the Wallaroo SDK. The following guide is created to assist users with installing the Wallaroo SDK, setting up authentication through Azure ML, and making a standard connection to a Wallaroo instance through Azure ML Workspace.
aloha-cnn-lstm.zip: A pre-trained open source model that uses an Aloha CNN LSTM model for classifying Domain names as being either legitimate or being used for nefarious purposes such as malware distribution.
Test Data Files:
data_1k.arrow: 1,000 records
data_25k.arrow: 25,000 records
To use the Wallaroo SDK within Azure ML Workspace, a virtual environment will be used. This will set the necessary libraries and specific Python version required.
Prerequisites
The following is required for this tutorial:
A Wallaroo instance version 2023.1 or later.
Python 3.8.6 or later installed locally
Conda: Used for managing python virtual environments. This is automatically included in Azure ML Workspace.
An Azure ML workspace is created with a compute configured.
The following Python libraries installed:
os
wallaroo: The Wallaroo SDK. Included with the Wallaroo JupyterHub service by default.
polars: Polars for DataFrame with native Apache Arrow support
General Steps
For our example, we will perform the following:
Wallaroo SDK Install
Set up a Python virtual environment through conda with the libraries that enable the virtual environment for use in a Jupyter Hub environment.
Install the Wallaroo SDK.
Wallaroo SDK from remote JupyterHub Demonstration (Optional): The following steps are an optional exercise to demonstrate using the Wallaroo SDK from a remote connection. The entire tutorial can be found on the Wallaroo Tutorials repository).
Connect to a remote Wallaroo instance.
Create a workspace for our work.
Upload the Aloha model.
Create a pipeline that can ingest our submitted data, submit it to the model, and export the results
Run a sample inference through our pipeline by loading a file
Retrieve the external deployment URL. This sample Wallaroo instance has been configured to create external inference URLs for pipelines. For more information, see the External Inference URL Guide.
Run a sample inference through our pipeline’s external URL and store the results in a file. This assumes that the External Inference URLs have been enabled for the target Wallaroo instance.
Undeploy the pipeline and return resources back to the Wallaroo instance’s Kubernetes environment.
Install Wallaroo SDK
Set Up Virtual Python Environment
To set up the virtual environment in Azure ML for using the Wallaroo SDK with Azure ML Workspace:
Select Notebooks.
Create a new folder where the Jupyter Notebooks for Wallaroo will be installed.
From this repository, upload sdk-install-guides/azure-ml-sdk-install.zip, or upload the entire folder sdk-install-guides/azure-ml-sdk-install. This tutorial will assume the .zip file was uploaded.
Select Open Terminal. Navigate to the target directory.
Run unzip azure-ml-sdk-install.zip to unzip the directory, then cd into it with cd azure-ml-sdk-install.
Create the Python virtual environment with conda. Replace wallaroosdk with the name of the virtual environment as required by your organization. Note that Python 3.8.6 and above is specified as a requirement for Python libraries used with the Wallaroo SDK. The following will install the latest version of Python 3.8, which as of this time is 3.8.15.
conda create -n wallaroosdk python=3.8
Activate the new environment.
conda activate wallaroosdk
Install the ipykernel library. This allows the JupyterHub notebooks to access the Python virtual environment as a kernel.
conda install ipykernel
Install the new virtual environment as a python kernel.
ipython kernel install --user --name=wallaroosdk
Install the Wallaroo SDK. This process may take several minutes while the other required Python libraries are added to the virtual environment.
IMPORTANT NOTE: The version of the Wallaroo SDK should match the Wallaroo instance. For example, this example connects to a Wallaroo Enterprise version 2023.1 instance, so the SDK version should be wallaroo==2023.1.0.
pip install wallaroo==2023.2.1
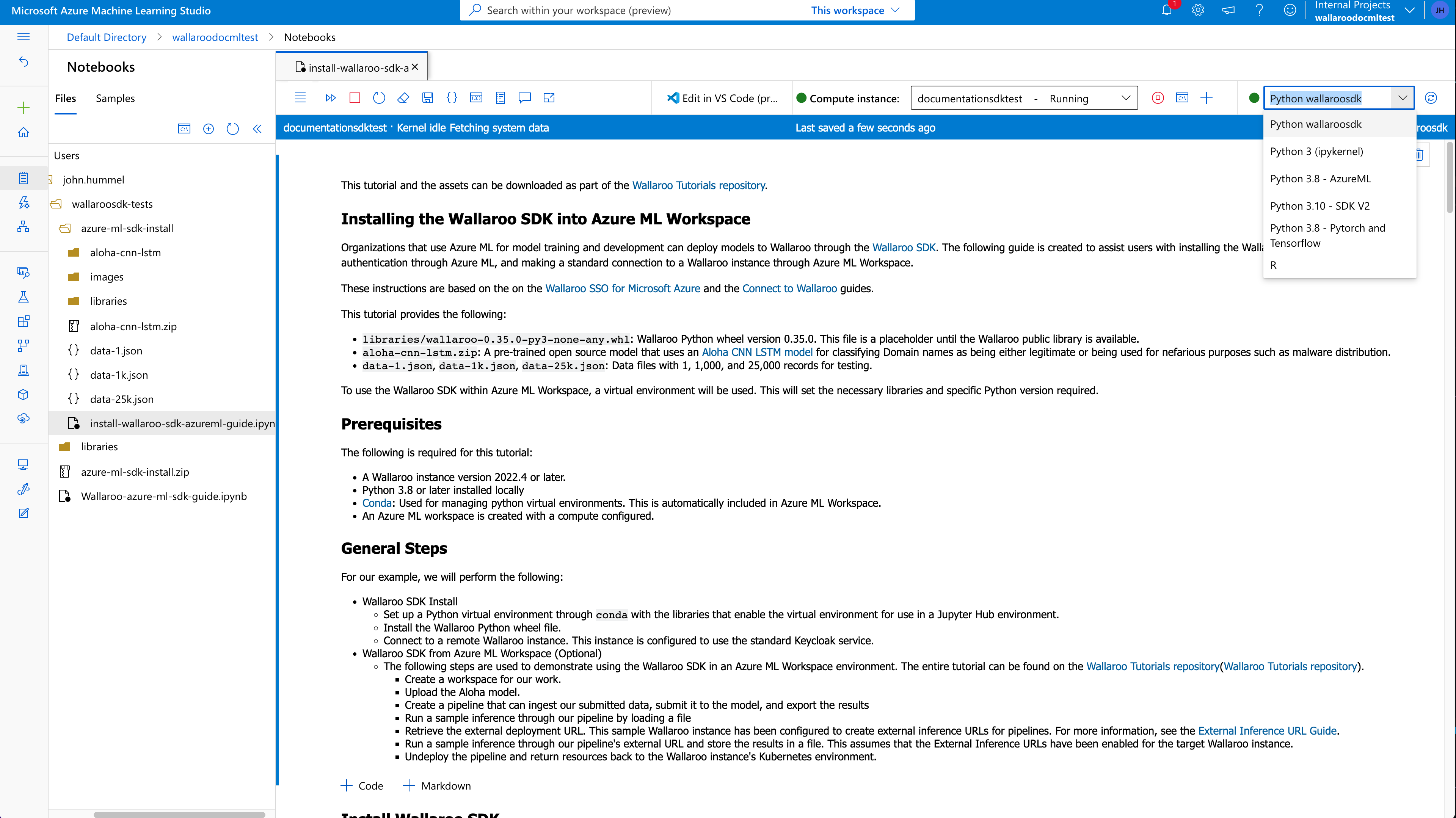
Once the conda virtual environment has been installed, it can either be selected as a new Jupyter Notebook kernel, or the Notebook’s kernel can be set to an existing Jupyter notebook. If a notebook is existing, close it then reopen to select the new Wallaroo SDK environment.
To use a new Notebook:
From the left navigation panel, select +->Notebook.
From the Kernel selection dropbox on the upper right side, select the new virtual environment - in this case, wallaroosdk.
To update an existing Notebook to use the new virtual environment as a kernel:
From the main menu, select Kernel->Change Kernel.
Select the new kernel.
Sample Wallaroo Connection
With the Wallaroo Python SDK installed, remote commands and inferences can be performed through the following steps.
Open a Connection to Wallaroo
The first step is to connect to Wallaroo through the Wallaroo client.
This is accomplished using the wallaroo.Client(api_endpoint, auth_endpoint, auth_type command) command that connects to the Wallaroo instance services.
The Client method takes the following parameters:
api_endpoint (String): The URL to the Wallaroo instance API service.
auth_endpoint (String): The URL to the Wallaroo instance Keycloak service.
auth_type command (String): The authorization type. In this case, SSO.
The URLs are based on the Wallaroo Prefix and Wallaroo Suffix for the Wallaroo instance. For more information, see the DNS Integration Guide. In the example below, replace “YOUR PREFIX” and “YOUR SUFFIX” with the Wallaroo Prefix and Suffix, respectively.
Once run, the wallaroo.Client command provides a URL to grant the SDK permission to your specific Wallaroo environment. When displayed, enter the URL into a browser and confirm permissions. Depending on the configuration of the Wallaroo instance, the user will either be presented with a login request to the Wallaroo instance or be authenticated through a broker such as Google, Github, etc. To use the broker, select it from the list under the username/password login forms. For more information on Wallaroo authentication configurations, see the Wallaroo Authentication Configuration Guides.
Once authenticated, the user will verify adding the device the user is establishing the connection from. Once both steps are complete, then the connection is granted.
The connection is stored in the variable wl for use in all other Wallaroo calls.
importwallaroofromwallaroo.objectimportEntityNotFoundError# to display dataframe tablesfromIPython.displayimportdisplay# used to display dataframe information without truncatingimportpandasaspdpd.set_option('display.max_colwidth', None)
importpyarrowaspa
For wallarooPrefix = "YOUR PREFIX." and wallarooSuffix = "YOUR SUFFIX", enter the prefix and suffix for your Wallaroo instance DNS name. If the prefix instance is blank, then it can be wallarooPrefix = "". Note that the prefix includes the . for proper formatting. For example, if the prefix is empty and the suffix is wallaroo.example.com, then the settings would be:
# SSO login through keycloakwallarooPrefix="YOUR PREFIX"wallarooSuffix="YOUR SUFFIX"wl=wallaroo.Client(api_endpoint=f"https://{wallarooPrefix}api.{wallarooSuffix}",
auth_endpoint=f"https://{wallarooPrefix}keycloak.{wallarooSuffix}",
auth_type="sso")
Create the Workspace
We will create a workspace to work in and call it the azuremlsdkworkspace, then set it as current workspace environment. We’ll also create our pipeline in advance as azuremlsdkpipeline.
IMPORTANT NOTE: For this example, the Aloha model is stored in the file alohacnnlstm.zip. When using tensor based models, the zip file must match the name of the tensor directory. For example, if the tensor directory is alohacnnlstm, then the .zip file must be named alohacnnlstm.zip.
Now we will upload our model. Note that for this example we are applying the model from a .ZIP file. The Aloha model is a protobuf file that has been defined for evaluating web pages, and we will configure it to use data in the tensorflow format.
Now that we have a model that we want to use we will create a deployment for it.
We will tell the deployment we are using a tensorflow model and give the deployment name and the configuration we want for the deployment.
To do this, we’ll create our pipeline that can ingest the data, pass the data to our Aloha model, and give us a final output. We’ll call our pipeline externalsdkpipeline, then deploy it so it’s ready to receive data. The deployment process usually takes about 45 seconds.
Now that the pipeline is deployed and our Aloha model is in place, we’ll perform a smoke test to verify the pipeline is up and running properly. We’ll use the infer_from_file command to load a single encoded URL into the inference engine and print the results back out.
The result should tell us that the tokenized URL is legitimate (0) or fraud (1). This sample data should return close to 1.
We can also infer an entire batch as one request either with the Pipeline infer method with multiple rows, or loaded from a file using the Pipeline infer_from_file method. For this example, we will run a batch on 1,000 records using the file data_1k.arrow. This is an Apache Arrow table, which gives the added benefit of speed and lower file size as a binary file rather than a text JSON file.
We’ll infer the 1,000 records, then convert it to a DataFrame and display the first 5 to save space in our Jupyter Notebook.
Now that our smoke test is successful, let’s really give it some data. We have two inference files we can use:
data-1k.arrow: Contains 10,000 inferences
data-25k.arrow: Contains 25,000 inferences
These inference inputs are Apache Arrow tables, which Wallaroo can ingest natively. These are binary files, and are faster to transmit because of their smaller size compared to JSON.
We’ll pipe the data-25k.arrow file through the pipeline deployment URL, and place the results in a file named response.df. Note that for larger batches of 1,000 inferences or more can be difficult to view in Jupyter Hub because of its size, so we’ll only display the first 5 results of the inference.
When retrieving the pipeline inference URL through an external SDK connection, the External Inference URL will be returned. This URL will function provided that the Enable external URL inference endpoints is enabled. For more information, see the Wallaroo Model Endpoints Guide.
The API connection details can be retrieved through the Wallaroo client mlops() command. This will display the connection URL, bearer token, and other information. The bearer token is available for one hour before it expires.
For this example, the API connection details will be retrieved, then used to submit an inference request through the external inference URL retrieved earlier.
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 24.8M 100 20.0M 100 4874k 1926k 457k 0:00:10 0:00:10 --:--:-- 4735k2k 1537k 499k 0:00:13 0:00:09 0:00:04 3379k
When finished with our tests, we will undeploy the pipeline so we have the Kubernetes resources back for other tasks. Note that if the deployment variable is unchanged pipeline.deploy() will restart the inference engine in the same configuration as before.
Organizations that use Azure Databricks for model training and development can deploy models to Wallaroo through the Wallaroo SDK. The following guide is created to assist users with installing the Wallaroo SDK, setting up authentication through Azure Databricks, and making a standard connection to a Wallaroo instance through Azure Databricks Workspace.
ccfraud.onnx: A pretrained model from the Machine Learning Group’s demonstration on Credit Card Fraud detection.
Sample inference test data:
cc_data_1k.arrow: Sample input file with 1,000 records.
cc_data_10k.arrow: Sample input file with 10,000 records.
To use the Wallaroo SDK within Azure Databricks Workspace, a virtual environment will be used. This will set the necessary libraries and specific Python version required.
polars: Polars for DataFrame with native Apache Arrow support
General Steps
For our example, we will perform the following:
Wallaroo SDK Install
Install the Wallaroo SDK into the Azure Databricks cluster.
Install the Wallaroo Python SDK.
Connect to a remote Wallaroo instance. This instance is configured to use the standard Keycloak service.
Wallaroo SDK from Azure Databricks Workspace (Optional)
The following steps are used to demonstrate using the Wallaroo SDK in an Azure Databricks Workspace environment. The entire tutorial can be found on the Wallaroo Tutorials repository.
Create a workspace for our work.
Upload the CCFraud model.
Create a pipeline that can ingest our submitted data, submit it to the model, and export the results
Run a sample inference through our pipeline by loading a file
Undeploy the pipeline and return resources back to the Wallaroo instance’s Kubernetes environment.
Install Wallaroo SDK
Add Wallaroo SDK to Cluster
To install the Wallaroo SDK in a Azure Databricks environment:
From the Azure Databricks dashboard, select Computer, then the cluster to use.
Select Libraries.
Select Install new.
Select PyPI. In the Package field, enter the current version of the Wallaroo SDK. It is recommended to specify the version, which as of this writing is wallaroo==2023.2.0.
Select Install.
Once the Status shows Installed, it will be available in Azure Databricks notebooks and other tools that use the cluster.
Add Tutorial Files
The following instructions can be used to upload this tutorial and it’s files into Databricks. Depending on how your Azure Databricks is configured and your organizations standards, there are multiple ways of uploading files to your Azure Databricks environment. The following example is used for the tutorial and makes it easy to reference data files from within this Notebook. Adjust based on your requirements.
IMPORTANT NOTE: Importing a repo from a Git repository may not convert the included Jupyter Notebooks into the Databricks format. This method
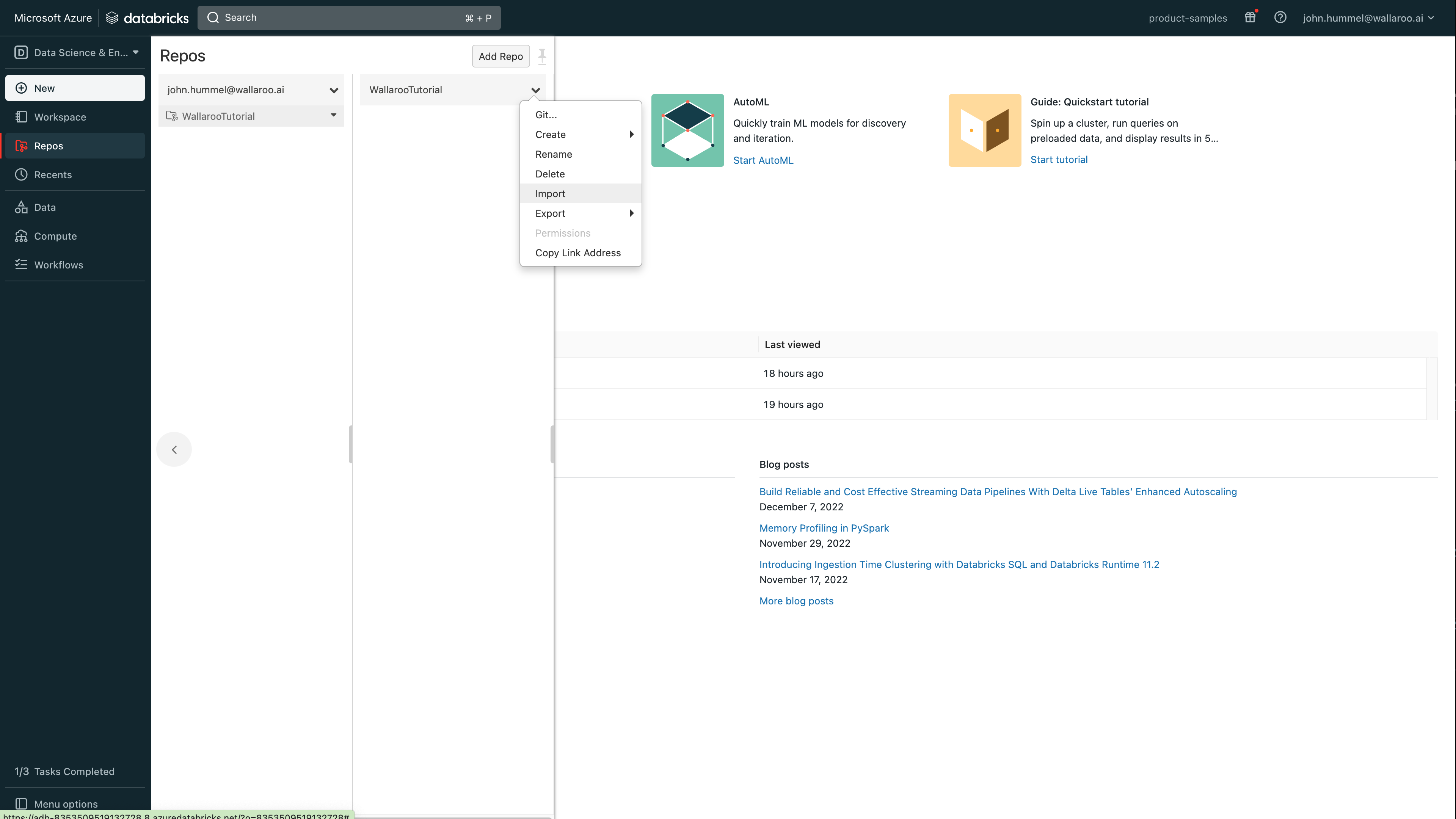
From the Azure Databricks dashboard, select Repos.
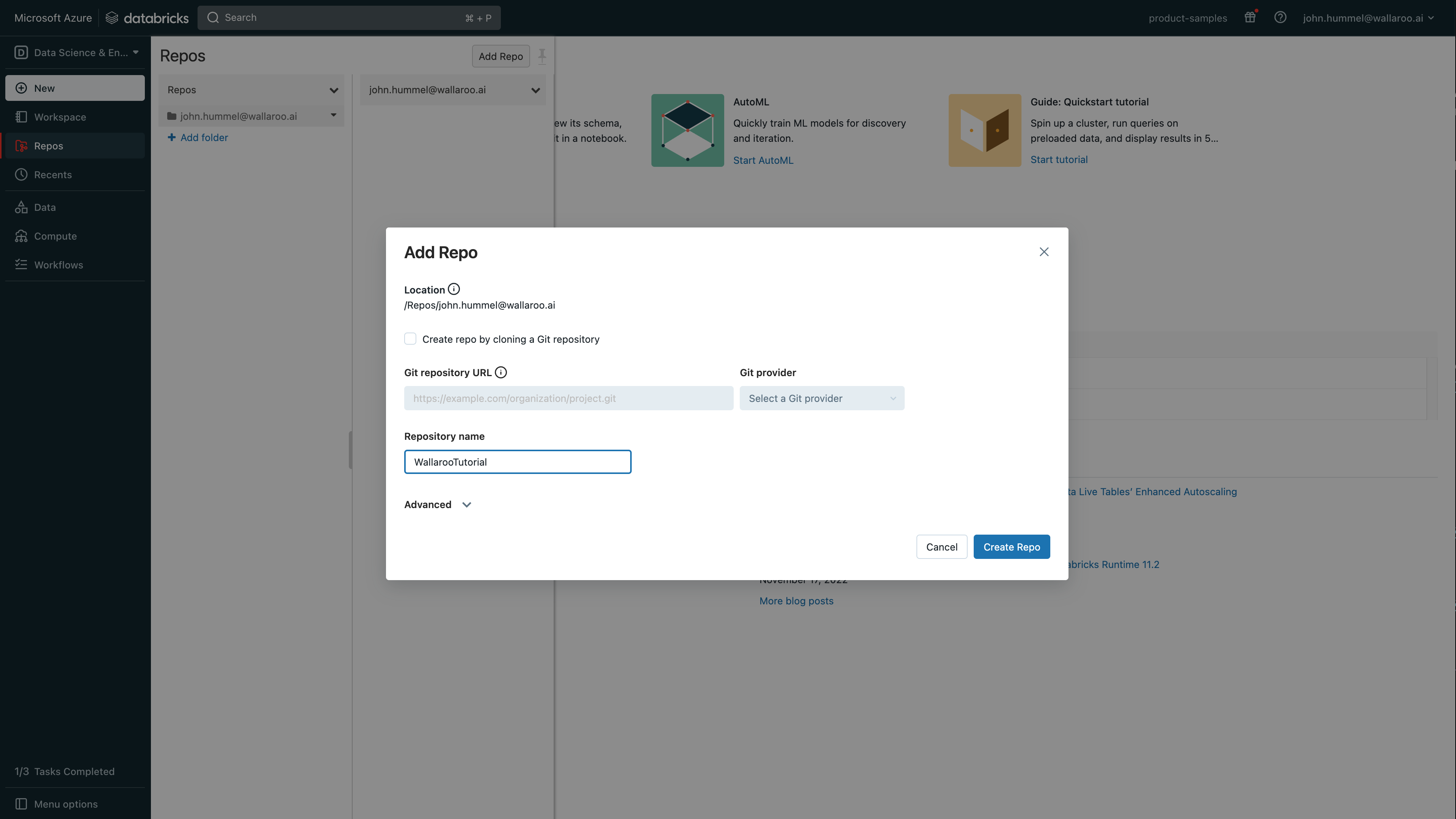
Select where to place the repo, then select Add Repo.
Set the following:
Create repo by cloning a Git repository: Uncheck
Repository name: Set any name based on the Databricks standard (no spaces, etc).
Select Create Repo.
Select the new tutorial, then from the repo menu dropdown, select Import.
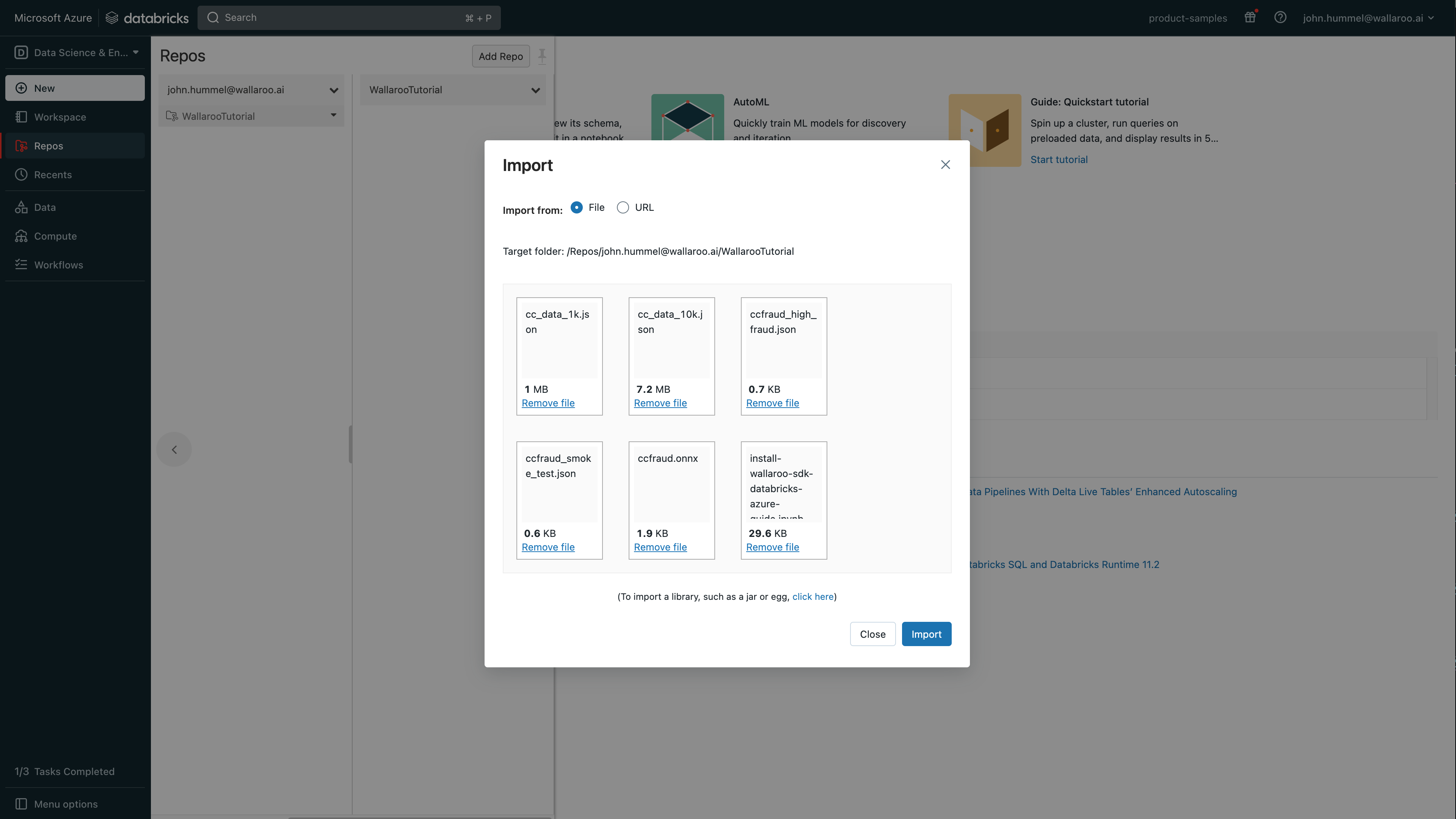
Select the files to upload. For this example, the following files are uploaded:
ccfraud.onnx: A pretrained model from the Machine Learning Group’s demonstration on Credit Card Fraud detection.
Sample inference test data:
ccfraud_high_fraud.json: Test input file that returns a high likelihood of credit card fraud.
ccfraud_smoke_test.json: Test input file that returns a low likelihood of credit card fraud.
cc_data_1k.json: Sample input file with 1,000 records.
cc_data_10k.json: Sample input file with 10,000 records.
install-wallaroo-sdk-databricks-azure-guide.ipynb: This notebook.
Select Import.
The Jupyter Notebook can be opened from this new Azure Databricks repository, and relative files it references will be accessible with the exceptions listed below.
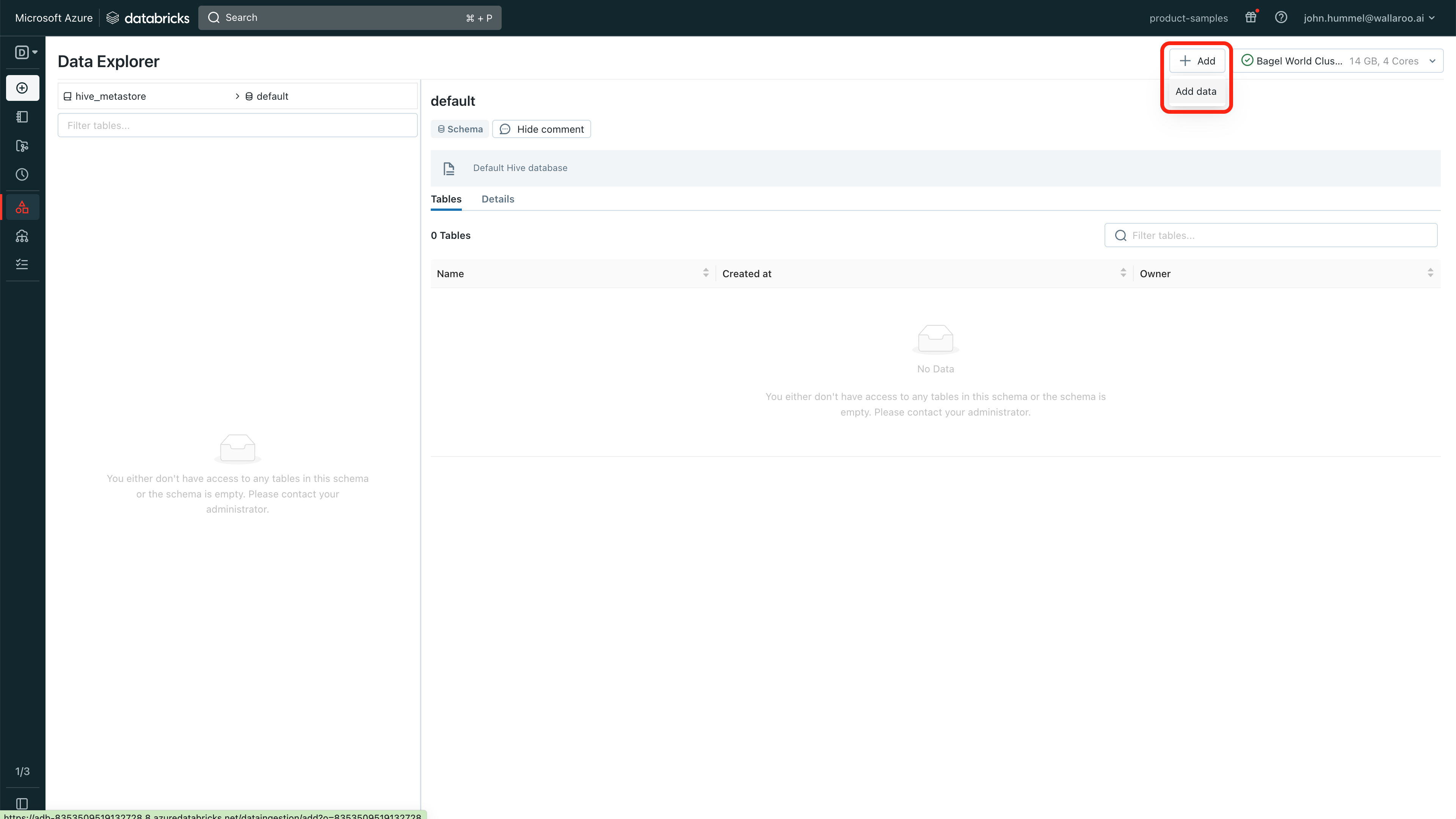
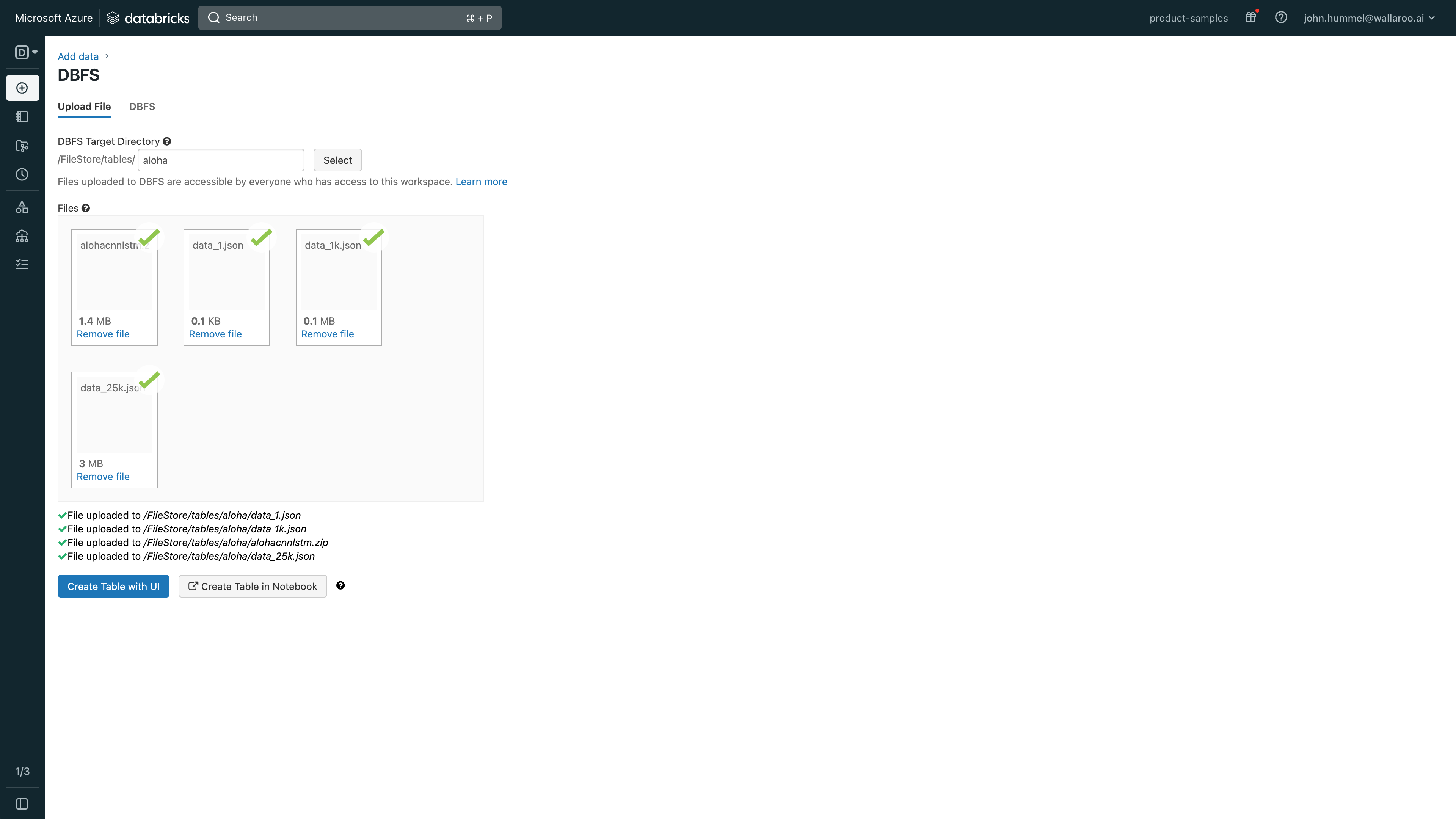
Zip files added via the method above are automatically decompressed, so can not be used as model files. For example, tensor based models such as the Wallaroo Aloha Demo. Zip files can be uploaded using DBFS and used through the following process:
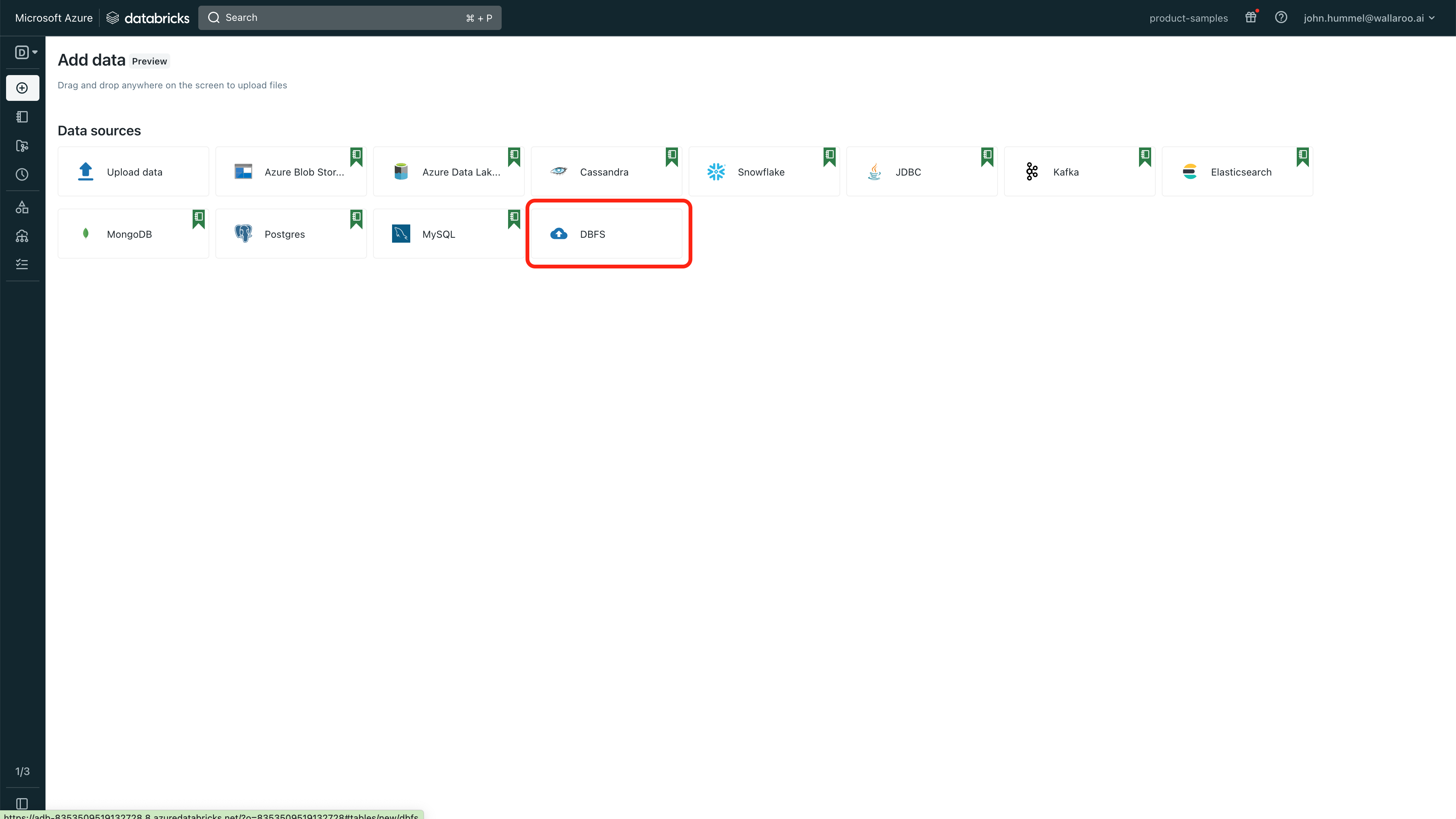
To upload model files to Azure Databricks using DBFS:
From the Azure Databricks dashboard, select Data.
Select Add->Add data.
Select DBFS.
Select Upload File and enter the following:
DBFS Target Directory (Optional): Optional step: Set the directory where the files will be uploaded.
Select the files to upload. Note that each file will be given a location and they can be access with /dbfs/PATH. For example, the file alohacnnlstm.zip uploaded to the directory aloha would be referenced with `/dbfs/FileStore/tables/aloha/alohacnnlstm.zip
Sample Wallaroo Connection
With the Wallaroo Python SDK installed, remote commands and inferences can be performed through the following steps.
Open a Connection to Wallaroo
The first step is to connect to Wallaroo through the Wallaroo client.
This is accomplished using the wallaroo.Client(api_endpoint, auth_endpoint, auth_type command) command that connects to the Wallaroo instance services.
The Client method takes the following parameters:
api_endpoint (String): The URL to the Wallaroo instance API service.
auth_endpoint (String): The URL to the Wallaroo instance Keycloak service.
auth_type command (String): The authorization type. In this case, SSO.
The URLs are based on the Wallaroo Prefix and Wallaroo Suffix for the Wallaroo instance. For more information, see the DNS Integration Guide. In the example below, replace “YOUR PREFIX” and “YOUR SUFFIX” with the Wallaroo Prefix and Suffix, respectively. In the example below, replace “YOUR PREFIX” and “YOUR SUFFIX” with the Wallaroo Prefix and Suffix, respectively.
Once run, the wallaroo.Client command provides a URL to grant the SDK permission to your specific Wallaroo environment. When displayed, enter the URL into a browser and confirm permissions.
Depending on the configuration of the Wallaroo instance, the user will either be presented with a login request to the Wallaroo instance or be authenticated through a broker such as Google, Github, etc. To use the broker, select it from the list under the username/password login forms. For more information on Wallaroo authentication configurations, see the Wallaroo Authentication Configuration Guides.
Once authenticated, the user will verify adding the device the user is establishing the connection from. Once both steps are complete, then the connection is granted.
The connection is stored in the variable wl for use in all other Wallaroo calls.
Replace YOUR PREFIX and YOUR SUFFIX with the DNS prefix and suffix for the Wallaroo instance. For more information, see the DNS Integration Guide.
importwallaroofromwallaroo.objectimportEntityNotFoundError# used to display dataframe information without truncatingfromIPython.displayimportdisplayimportpandasaspdpd.set_option('display.max_colwidth', None)
# For Apache Arrow functionsimportpyarrow
For wallarooPrefix = "YOUR PREFIX." and wallarooSuffix = "YOUR SUFFIX", enter the prefix and suffix for your Wallaroo instance DNS name. If the prefix instance is blank, then it can be wallarooPrefix = "". Note that the prefix includes the . for proper formatting. For example, if the prefix is empty and the suffix is wallaroo.example.com, then the settings would be:
# SSO login through keycloakwallarooPrefix="YOUR PREFIX."wallarooSuffix="YOUR SUFFIX"wl=wallaroo.Client(api_endpoint=f"https://{wallarooPrefix}api.{wallarooSuffix}",
auth_endpoint=f"https://{wallarooPrefix}keycloak.{wallarooSuffix}",
auth_type="sso")
Create the Workspace
We will create a workspace to work in and call it the databricksazuresdkworkspace, then set it as current workspace environment. We’ll also create our pipeline in advance as databricksazuresdkpipeline.
IMPORTANT NOTE: For this example, the CCFraud model is stored in the file ccfraud.onnx and is referenced from a relative link. For platforms such as Databricks, the files may need to be in a universal file format. For those, the example file location below may be:
Now that we have a model that we want to use we will create a deployment for it.
To do this, we’ll create our pipeline that can ingest the data, pass the data to our CCFraud model, and give us a final output. We’ll call our pipeline databricksazuresdkpipeline, then deploy it so it’s ready to receive data. The deployment process usually takes about 45 seconds.
Now that the pipeline is deployed and our CCfraud model is in place, we’ll perform a smoke test to verify the pipeline is up and running properly. We’ll use the infer_from_file command to load a single transaction and determine if it is flagged for fraud. If it returns correctly, a small value should be returned indicating a low likelihood that the transaction was fraudulent.
Now that our smoke test is successful, let’s really give it some data. We’ll use the cc_data_1k.jarrowson file that contains 1,000 inferences to be performed, then convert that to a DataFrame and display the first 5 rows.
When finished with our tests, we will undeploy the pipeline so we have the Kubernetes resources back for other tasks. Note that if the deployment variable is unchanged pipeline.deploy() will restart the inference engine in the same configuration as before.
Installing the Wallaroo SDK into Google Vertex Workbench
Organizations that use Google Vertex for model training and development can deploy models to Wallaroo through the Wallaroo SDK. The following guide is created to assist users with installing the Wallaroo SDK, setting up authentication through Google Cloud Platform (GCP), and making a standard connection to a Wallaroo instance through Google Workbench.
aloha-cnn-lstm.zip: A pre-trained open source model that uses an Aloha CNN LSTM model for classifying Domain names as being either legitimate or being used for nefarious purposes such as malware distribution.
Test Data Files:
data_1k.arrow: 1,000 records
data_25k.arrow: 25,000 records
To use the Wallaroo SDK within Google Workbench, a virtual environment will be used. This will set the necessary libraries and specific Python version required.
Prerequisites
The following is required for this tutorial:
A Wallaroo instance version 2023.1 or later.
Python 3.8.6 or later installed locally
Conda: Used for managing python virtual environments.
The following Python libraries installed:
os
wallaroo: The Wallaroo SDK. Included with the Wallaroo JupyterHub service by default.
polars: Polars for DataFrame with native Apache Arrow support
General Steps
For our example, we will perform the following:
Wallaroo SDK Install
Set up a Python virtual environment through conda with the libraries that enable the virtual environment for use in a Jupyter Hub environment.
Install the Wallaroo SDK.
Wallaroo SDK from remote JupyterHub Demonstration (Optional): The following steps are an optional exercise to demonstrate using the Wallaroo SDK from a remote connection. The entire tutorial can be found on the Wallaroo Tutorials repository.
Connect to a remote Wallaroo instance.
Create a workspace for our work.
Upload the Aloha model.
Create a pipeline that can ingest our submitted data, submit it to the model, and export the results
Run a sample inference through our pipeline by loading a file
Retrieve the external deployment URL. This sample Wallaroo instance has been configured to create external inference URLs for pipelines. For more information, see the External Inference URL Guide.
Run a sample inference through our pipeline’s external URL and store the results in a file. This assumes that the External Inference URLs have been enabled for the target Wallaroo instance.
Undeploy the pipeline and return resources back to the Wallaroo instance’s Kubernetes environment.
Install Wallaroo SDK
Set Up Virtual Python Environment
To set up the virtual environment in Google Workbench for using the Wallaroo SDK with Google Workbench:
Start a separate terminal by selecting File->New->Terminal.
Create the Python virtual environment with conda. Replace wallaroosdk with the name of the virtual environment as required by your organization. Note that Python 3.8.6 and above is specified as a requirement for Python libraries used with the Wallaroo SDK. The following will install the latest version of Python 3.8, which as of this time is 3.8.15.
conda create -n wallaroosdk python=3.8
Activate the new environment.
conda activate wallaroosdk
Install the ipykernel library. This allows the JupyterHub notebooks to access the Python virtual environment as a kernel.
conda install ipykernel
Install the new virtual environment as a python kernel.
ipython kernel install --user --name=wallaroosdk
Install the Wallaroo SDK. This process may take several minutes while the other required Python libraries are added to the virtual environment.
IMPORTANT NOTE: The version of the Wallaroo SDK should match the Wallaroo instance. For example, this example connects to a Wallaroo Enterprise version 2023.1 instance, so the SDK version should be wallaroo==2023.1.0.
pip install wallaroo==2023.2.1
Once the conda virtual environment has been installed, it can either be selected as a new Jupyter Notebook kernel, or the Notebook’s kernel can be set to an existing Jupyter notebook.
To use a new Notebook:
From the main menu, select File->New-Notebook.
From the Kernel selection dropbox, select the new virtual environment - in this case, wallaroosdk.
To update an existing Notebook to use the new virtual environment as a kernel:
From the main menu, select Kernel->Change Kernel.
Select the new kernel.
Sample Wallaroo Connection
With the Wallaroo Python SDK installed, remote commands and inferences can be performed through the following steps.
Open a Connection to Wallaroo
The first step is to connect to Wallaroo through the Wallaroo client.
This is accomplished using the wallaroo.Client(api_endpoint, auth_endpoint, auth_type command) command that connects to the Wallaroo instance services.
The Client method takes the following parameters:
api_endpoint (String): The URL to the Wallaroo instance API service.
auth_endpoint (String): The URL to the Wallaroo instance Keycloak service.
auth_type command (String): The authorization type. In this case, SSO.
The URLs are based on the Wallaroo Prefix and Wallaroo Suffix for the Wallaroo instance. For more information, see the DNS Integration Guide. In the example below, replace “YOUR PREFIX” and “YOUR SUFFIX” with the Wallaroo Prefix and Suffix, respectively.
Once run, the wallaroo.Client command provides a URL to grant the SDK permission to your specific Wallaroo environment. When displayed, enter the URL into a browser and confirm permissions. Depending on the configuration of the Wallaroo instance, the user will either be presented with a login request to the Wallaroo instance or be authenticated through a broker such as Google, Github, etc. To use the broker, select it from the list under the username/password login forms. For more information on Wallaroo authentication configurations, see the Wallaroo Authentication Configuration Guides.
Once authenticated, the user will verify adding the device the user is establishing the connection from. Once both steps are complete, then the connection is granted.
The connection is stored in the variable wl for use in all other Wallaroo calls.
importwallaroofromwallaroo.objectimportEntityNotFoundError# to display dataframe tablesfromIPython.displayimportdisplay# used to display dataframe information without truncatingimportpandasaspdpd.set_option('display.max_colwidth', None)
importpyarrowaspa
For wallarooPrefix = "YOUR PREFIX." and wallarooSuffix = "YOUR SUFFIX", enter the prefix and suffix for your Wallaroo instance DNS name. If the prefix instance is blank, then it can be wallarooPrefix = "". Note that the prefix includes the . for proper formatting. For example, if the prefix is empty and the suffix is wallaroo.example.com, then the settings would be:
# SSO login through keycloakwallarooPrefix="YOUR PREFIX."wallarooSuffix="YOUR SUFFIX."wl=wallaroo.Client(api_endpoint=f"https://{wallarooPrefix}api.{wallarooSuffix}",
auth_endpoint=f"https://{wallarooPrefix}keycloak.{wallarooSuffix}",
auth_type="sso")
Create the Workspace
We will create a workspace to work in and call it the gcpsdkworkspace, then set it as current workspace environment. We’ll also create our pipeline in advance as gcpsdkpipeline.
IMPORTANT NOTE: For this example, the Aloha model is stored in the file alohacnnlstm.zip. When using tensor based models, the zip file must match the name of the tensor directory. For example, if the tensor directory is alohacnnlstm, then the .zip file must be named alohacnnlstm.zip.
Now we will upload our model. Note that for this example we are applying the model from a .ZIP file. The Aloha model is a protobuf file that has been defined for evaluating web pages, and we will configure it to use data in the tensorflow format.
Now that we have a model that we want to use we will create a deployment for it.
We will tell the deployment we are using a tensorflow model and give the deployment name and the configuration we want for the deployment.
To do this, we’ll create our pipeline that can ingest the data, pass the data to our Aloha model, and give us a final output. We’ll call our pipeline externalsdkpipeline, then deploy it so it’s ready to receive data. The deployment process usually takes about 45 seconds.
Now that the pipeline is deployed and our Aloha model is in place, we’ll perform a smoke test to verify the pipeline is up and running properly. We’ll use the infer_from_file command to load a single encoded URL into the inference engine and print the results back out.
The result should tell us that the tokenized URL is legitimate (0) or fraud (1). This sample data should return close to 1.
We can also infer an entire batch as one request either with the Pipeline infer method with multiple rows, or loaded from a file using the Pipeline infer_from_file method. For this example, we will run a batch on 1,000 records using the file data_1k.arrow. This is an Apache Arrow table, which gives the added benefit of speed and lower file size as a binary file rather than a text JSON file.
We’ll infer the 1,000 records, then convert it to a DataFrame and display the first 5 to save space in our Jupyter Notebook.
Now that our smoke test is successful, let’s really give it some data. We have two inference files we can use:
data-1k.arrow: Contains 10,000 inferences
data-25k.arrow: Contains 25,000 inferences
These inference inputs are Apache Arrow tables, which Wallaroo can ingest natively. These are binary files, and are faster to transmit because of their smaller size compared to JSON.
We’ll pipe the data-25k.arrow file through the pipeline deployment URL, and place the results in a file named response.df. Note that for larger batches of 1,000 inferences or more can be difficult to view in Jupyter Hub because of its size, so we’ll only display the first 5 results of the inference.
When retrieving the pipeline inference URL through an external SDK connection, the External Inference URL will be returned. This URL will function provided that the Enable external URL inference endpoints is enabled. For more information, see the Wallaroo Model Endpoints Guide.
The API connection details can be retrieved through the Wallaroo client mlops() command. This will display the connection URL, bearer token, and other information. The bearer token is available for one hour before it expires.
For this example, the API connection details will be retrieved, then used to submit an inference request through the external inference URL retrieved earlier.
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 25.5M 100 20.8M 100 4874k 2151k 492k 0:00:09 0:00:09 --:--:-- 4494k
When finished with our tests, we will undeploy the pipeline so we have the Kubernetes resources back for other tasks. Note that if the deployment variable is unchanged pipeline.deploy() will restart the inference engine in the same configuration as before.
Organizations that develop machine learning models can deploy models to Wallaroo from their local systems to a Wallaroo instance through the Wallaroo SDK. The following guide is created to assist users with installing the Wallaroo SDK and making a standard connection to a Wallaroo instance.
aloha-cnn-lstm.zip: A pre-trained open source model that uses an Aloha CNN LSTM model for classifying Domain names as being either legitimate or being used for nefarious purposes such as malware distribution.
Test Data Files:
data_1k.arrow: 1,000 records
data_25k.arrow: 25,000 records
For this example, a virtual python environment will be used. This will set the necessary libraries and specific Python version required.
Prerequisites
The following is required for this tutorial:
A Wallaroo instance version 2023.1 or later.
Python 3.8.6 or later installed locally.
Conda: Used for managing python virtual environments.
The following Python libraries installed:
os
wallaroo: The Wallaroo SDK. Included with the Wallaroo JupyterHub service by default.
polars: Polars for DataFrame with native Apache Arrow support
General Steps
For our example, we will perform the following:
Wallaroo SDK Install
Set up a Python virtual environment through conda with the libraries that enable the virtual environment for use in a Jupyter Hub environment.
Install the Wallaroo SDK.
Wallaroo SDK from remote JupyterHub Demonstration (Optional): The following steps are an optional exercise to demonstrate using the Wallaroo SDK from a remote connection. The entire tutorial can be found on the Wallaroo Tutorials repository.
Connect to a remote Wallaroo instance.
Create a workspace for our work.
Upload the Aloha model.
Create a pipeline that can ingest our submitted data, submit it to the model, and export the results
Run a sample inference through our pipeline by loading a file
Retrieve the external deployment URL. This sample Wallaroo instance has been configured to create external inference URLs for pipelines. For more information, see the External Inference URL Guide.
Run a sample inference through our pipeline’s external URL and store the results in a file. This assumes that the External Inference URLs have been enabled for the target Wallaroo instance.
Undeploy the pipeline and return resources back to the Wallaroo instance’s Kubernetes environment.
Install Wallaroo SDK
Set Up Virtual Python Environment
To set up the Python virtual environment for use of the Wallaroo SDK:
From a terminal shell, create the Python virtual environment with conda. Replace wallaroosdk with the name of the virtual environment as required by your organization. Note that Python 3.8.6 and above is specified as a requirement for Python libraries used with the Wallaroo SDK. The following will install the latest version of Python 3.8.
conda create -n wallaroosdk python=3.8
Activate the new environment.
conda activate wallaroosdk
(Optional) For organizations who want to use the Wallaroo SDk from within Jupyter and similar environments:
Install the ipykernel library. This allows the JupyterHub notebooks to access the Python virtual environment as a kernel, and it required for the second part of this tutorial.
conda install ipykernel
Install the new virtual environment as a python kernel.
ipython kernel install --user --name=wallaroosdk
Install the Wallaroo SDK. This process may take several minutes while the other required Python libraries are added to the virtual environment.
IMPORTANT NOTE: The version of the Wallaroo SDK should match the Wallaroo instance. For example, this example connects to a Wallaroo Enterprise version 2023.1 instance, so the SDK version should be wallaroo==2023.1.0.
pip install wallaroo==2023.2.1
For organizations who will be using the Wallaroo SDK with Jupyter or similar services, the conda virtual environment has been installed, it can either be selected as a new Jupyter Notebook kernel, or the Notebook’s kernel can be set to an existing Jupyter notebook.
To use a new Notebook:
From the main menu, select File->New-Notebook.
From the Kernel selection dropbox, select the new virtual environment - in this case, wallaroosdk.
To update an existing Notebook to use the new virtual environment as a kernel:
From the main menu, select Kernel->Change Kernel.
Select the new kernel.
Sample Wallaroo Connection
With the Wallaroo Python SDK installed, remote commands and inferences can be performed through the following steps.
Open a Connection to Wallaroo
The first step is to connect to Wallaroo through the Wallaroo client.
This is accomplished using the wallaroo.Client(api_endpoint, auth_endpoint, auth_type command) command that connects to the Wallaroo instance services.
The Client method takes the following parameters:
api_endpoint (String): The URL to the Wallaroo instance API service.
auth_endpoint (String): The URL to the Wallaroo instance Keycloak service.
auth_type command (String): The authorization type. In this case, SSO.
The URLs are based on the Wallaroo Prefix and Wallaroo Suffix for the Wallaroo instance. For more information, see the DNS Integration Guide. In the example below, replace “YOUR PREFIX” and “YOUR SUFFIX” with the Wallaroo Prefix and Suffix, respectively.
Once run, the wallaroo.Client command provides a URL to grant the SDK permission to your specific Wallaroo environment. When displayed, enter the URL into a browser and confirm permissions. Depending on the configuration of the Wallaroo instance, the user will either be presented with a login request to the Wallaroo instance or be authenticated through a broker such as Google, Github, etc. To use the broker, select it from the list under the username/password login forms. For more information on Wallaroo authentication configurations, see the Wallaroo Authentication Configuration Guides.
Once authenticated, the user will verify adding the device the user is establishing the connection from. Once both steps are complete, then the connection is granted.
The connection is stored in the variable wl for use in all other Wallaroo calls.
importwallaroofromwallaroo.objectimportEntityNotFoundError# to display dataframe tablesfromIPython.displayimportdisplay# used to display dataframe information without truncatingimportpandasaspdpd.set_option('display.max_colwidth', None)
importpyarrowaspa
For wallarooPrefix = "YOUR PREFIX." and wallarooSuffix = "YOUR SUFFIX", enter the prefix and suffix for your Wallaroo instance DNS name. If the prefix instance is blank, then it can be wallarooPrefix = "". Note that the prefix includes the . for proper formatting. For example, if the prefix is empty and the suffix is wallaroo.example.com, then the settings would be:
# SSO login through keycloakwallarooPrefix="YOUR PREFIX."wallarooSuffix="YOUR SUFFIX"wl=wallaroo.Client(api_endpoint=f"https://{wallarooPrefix}api.{wallarooSuffix}",
auth_endpoint=f"https://{wallarooPrefix}keycloak.{wallarooSuffix}",
auth_type="sso")
Wallaroo Remote SDK Examples
The following examples can be used by an organization to test using the Wallaroo SDK from a remote location from their Wallaroo instance. These examples show how to create workspaces, deploy pipelines, and perform inferences through the SDK and API.
Create the Workspace
We will create a workspace to work in and call it the sdkworkspace, then set it as current workspace environment. We’ll also create our pipeline in advance as sdkpipeline.
IMPORTANT NOTE: For this example, the Aloha model is stored in the file alohacnnlstm.zip. When using tensor based models, the zip file must match the name of the tensor directory. For example, if the tensor directory is alohacnnlstm, then the .zip file must be named alohacnnlstm.zip.
Now we will upload our model. Note that for this example we are applying the model from a .ZIP file. The Aloha model is a protobuf file that has been defined for evaluating web pages, and we will configure it to use data in the tensorflow format.
Now that we have a model that we want to use we will create a deployment for it.
We will tell the deployment we are using a tensorflow model and give the deployment name and the configuration we want for the deployment.
To do this, we’ll create our pipeline that can ingest the data, pass the data to our Aloha model, and give us a final output. We’ll call our pipeline externalsdkpipeline, then deploy it so it’s ready to receive data. The deployment process usually takes about 45 seconds.
Now that the pipeline is deployed and our Aloha model is in place, we’ll perform a smoke test to verify the pipeline is up and running properly. We’ll use the infer_from_file command to load a single encoded URL into the inference engine and print the results back out.
The result should tell us that the tokenized URL is legitimate (0) or fraud (1). This sample data should return close to 1.
We can also infer an entire batch as one request either with the Pipeline infer method with multiple rows, or loaded from a file using the Pipeline infer_from_file method. For this example, we will run a batch on 1,000 records using the file data_1k.arrow. This is an Apache Arrow table, which gives the added benefit of speed and lower file size as a binary file rather than a text JSON file.
We’ll infer the 1,000 records, then convert it to a DataFrame and display the first 5 to save space in our Jupyter Notebook.
Now that our smoke test is successful, let’s really give it some data. We have two inference files we can use:
data_1k.arrow: Contains 10,000 inferences
data_25k.arrow: Contains 25,000 inferences
We’ll pipe the data-25k.json file through the pipeline deployment URL, and place the results in a file named response.txt. We’ll also display the time this takes. Note that for larger batches of 50,000 inferences or more can be difficult to view in Jupyter Hub because of its size.
When retrieving the pipeline inference URL through an external SDK connection, the External Inference URL will be returned. This URL will function provided that the Enable external URL inference endpoints is enabled. For more information, see the Wallaroo Model Endpoints Guide.
The API connection details can be retrieved through the Wallaroo client mlops() command. This will display the connection URL, bearer token, and other information. The bearer token is available for one hour before it expires.
For this example, the API connection details will be retrieved, then used to submit an inference request through the external inference URL retrieved earlier.
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 25.6M 100 20.8M 100 4874k 771k 176k 0:00:27 0:00:27 --:--:-- 1161k0:00:35 0:00:19 0:00:16 1079k
When finished with our tests, we will undeploy the pipeline so we have the Kubernetes resources back for other tasks. Note that if the deployment variable is unchanged pipeline.deploy() will restart the inference engine in the same configuration as before.
Reference Guide for the most essential Wallaroo SDK Commands
The following guides detail how to use the Wallaroo SDK. These include detailed instructions on classes, methods, and code examples.
Wallaroo JupyterHub Python Libraries
When using the Wallaroo SDK, it is recommended that the Python modules used are the same as those used in the Wallaroo JupyterHub environments to ensure maximum compatibility. When installing modules in the Wallaroo JupyterHub environments, do not override the following modules or versions, as that may impact how the JupyterHub environments performance.
appdirs==1.4.4gql==3.4.0ipython==7.24.1matplotlib==3.5.0numpy==1.22.3orjson==3.8.0pandas==1.3.4pyarrow==9.0.0PyJWT==2.4.0python_dateutil==2.8.2PyYAML==6.0requests==2.25.1scipy==1.8.0seaborn==0.11.2tenacity==8.0.1# Required by gql?requests_toolbelt>=0.9.1<1# Required by the autogenerated ML Ops clienthttpx>=0.15.4<0.24.0attrs>=21.3.0# These are documented as part of the autogenerated ML Ops requirements# python = ^3.7# python-dateutil = ^2.8.0
Model and Framework Support
Supported Models
The following frameworks are supported. Frameworks fall under either Native or Containerized runtimes in the Wallaroo engine. For more details, see the specific framework what runtime a specific model framework runs in.
The supported frameworks include the specific version of the model framework supported by Wallaroo. It is highly recommended to verify that models uploaded to Wallaroo meet the library and version requirements to ensure proper functioning.
After April 2022 until release 2022.4 (December 2022)
1.10.*
7
15
2
Before April 2022
1.6.*
7
13
2
For the most recent release of Wallaroo 2023.2.1, the following native runtimes are supported:
If converting another ML Model to ONNX (PyTorch, XGBoost, etc) using the onnxconverter-common library, the supported DEFAULT_OPSET_NUMBER is 17.
Using different versions or settings outside of these specifications may result in inference issues and other unexpected behavior.
ONNX models always run in the native runtime space.
Data Schemas
ONNX models deployed to Wallaroo have the following data requirements.
Equal rows constraint: The number of input rows and output rows must match.
All inputs are tensors: The inputs are tensor arrays with the same shape.
Data Type Consistency: Data types within each tensor are of the same type.
Equal Rows Constraint
Inference performed through ONNX models are assumed to be in batch format, where each input row corresponds to an output row. This is reflected in the in fields returned for an inference. In the following example, each input row for an inference is related directly to the inference output.
For models that require ragged tensor or other shapes, see other data formatting options such as Bring Your Own Predict models.
Data Type Consistency
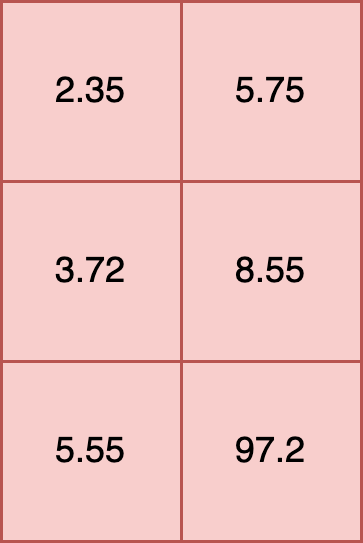
All inputs into an ONNX model must have the same internal data type. For example, the following is valid because all of the data types within each element are float32.
t= [
[2.35, 5.75],
[3.72, 8.55],
[5.55, 97.2]
]
The following is invalid, as it mixes floats and strings in each element:
These requirements are <strong>not</strong> for Tensorflow Keras models, only for non-Keras Tensorflow models in the SavedModel format. For Tensorflow Keras deployment in Wallaroo, see the Tensorflow Keras requirements.
TensorFlow File Format
TensorFlow models are .zip file of the SavedModel format. For example, the Aloha sample TensorFlow model is stored in the directory alohacnnlstm:
Python models uploaded to Wallaroo are executed as a native runtime.
Note that Python models - aka “Python steps” - are standalone python scripts that use the python libraries natively supported by the Wallaroo platform. These are used for either simple model deployment (such as ARIMA Statsmodels), or data formatting such as the postprocessing steps. A Wallaroo Python model will be composed of one Python script that matches the Wallaroo requirements.
This is contrasted with Arbitrary Python models, also known as Bring Your Own Predict (BYOP) allow for custom model deployments with supporting scripts and artifacts. These are used with pre-trained models (PyTorch, Tensorflow, etc) along with whatever supporting artifacts they require. Supporting artifacts can include other Python modules, model files, etc. These are zipped with all scripts, artifacts, and a requirements.txt file that indicates what other Python models need to be imported that are outside of the typical Wallaroo platform.
Python Models Requirements
Python models uploaded to Wallaroo are Python scripts that must include the wallaroo_json method as the entry point for the Wallaroo engine to use it as a Pipeline step.
This method receives the results of the previous Pipeline step, and its return value will be used in the next Pipeline step.
If the Python model is the first step in the pipeline, then it will be receiving the inference request data (for example: a preprocessing step). If it is the last step in the pipeline, then it will be the data returned from the inference request.
In the example below, the Python model is used as a post processing step for another ML model. The Python model expects to receive data from a ML Model who’s output is a DataFrame with the column dense_2. It then extracts the values of that column as a list, selects the first element, and returns a DataFrame with that element as the value of the column output.
In line with other Wallaroo inference results, the outputs of a Python step that returns a pandas DataFrame or Arrow Table will be listed in the out. metadata, with all inference outputs listed as out.{variable 1}, out.{variable 2}, etc. In the example above, this results the output field as the out.output field in the Wallaroo inference result.
Input and output schemas for each Hugging Face pipeline are defined below. Note that adding additional inputs not specified below will raise errors, except for the following:
Framework.HUGGING-FACE-IMAGE-TO-TEXT
Framework.HUGGING-FACE-TEXT-CLASSIFICATION
Framework.HUGGING-FACE-SUMMARIZATION
Framework.HUGGING-FACE-TRANSLATION
Additional inputs added to these Hugging Face pipelines will be added as key/pair value arguments to the model’s generate method. If the argument is not required, then the model will default to the values coded in the original Hugging Face model’s source code.
Any parameter that is not part of the required inputs list will be forwarded to the model as a key/pair value to the underlying models generate method. If the additional input is not supported by the model, an error will be returned.
Any parameter that is not part of the required inputs list will be forwarded to the model as a key/pair value to the underlying models generate method. If the additional input is not supported by the model, an error will be returned.
Schemas:
input_schema=pa.schema([
pa.field('inputs', pa.string()),
pa.field('return_text', pa.bool_()),
pa.field('return_tensors', pa.bool_()),
pa.field('clean_up_tokenization_spaces', pa.bool_()),
# pa.field('extra_field', pa.int64()), # every extra field you specify will be forwarded as a key/value pair])
output_schema=pa.schema([
pa.field('summary_text', pa.string()),
])
input_schema=pa.schema([
pa.field('inputs', pa.string()), # requiredpa.field('top_k', pa.int64()), # optionalpa.field('function_to_apply', pa.string()), # optional])
output_schema=pa.schema([
pa.field('label', pa.list_(pa.string(), list_size=2)), # list with a number of items same as top_k, list_size can be skipped but may lead in worse performancepa.field('score', pa.list_(pa.float64(), list_size=2)), # list with a number of items same as top_k, list_size can be skipped but may lead in worse performance])
Any parameter that is not part of the required inputs list will be forwarded to the model as a key/pair value to the underlying models generate method. If the additional input is not supported by the model, an error will be returned.
Schemas:
input_schema=pa.schema([
pa.field('inputs', pa.string()), # requiredpa.field('return_tensors', pa.bool_()), # optionalpa.field('return_text', pa.bool_()), # optionalpa.field('clean_up_tokenization_spaces', pa.bool_()), # optionalpa.field('src_lang', pa.string()), # optionalpa.field('tgt_lang', pa.string()), # optional# pa.field('extra_field', pa.int64()), # every extra field you specify will be forwarded as a key/value pair])
output_schema=pa.schema([
pa.field('translation_text', pa.string()),
])
input_schema=pa.schema([
pa.field('inputs', pa.string()), # requiredpa.field('candidate_labels', pa.list_(pa.string(), list_size=2)), # requiredpa.field('hypothesis_template', pa.string()), # optionalpa.field('multi_label', pa.bool_()), # optional])
output_schema=pa.schema([
pa.field('sequence', pa.string()),
pa.field('scores', pa.list_(pa.float64(), list_size=2)), # same as number of candidate labels, list_size can be skipped by may result in slightly worse performancepa.field('labels', pa.list_(pa.string(), list_size=2)), # same as number of candidate labels, list_size can be skipped by may result in slightly worse performance])
input_schema=pa.schema([
pa.field('images',
pa.list_(
pa.list_(
pa.list_(
pa.int64(),
list_size=3 ),
list_size=640 ),
list_size=480 )),
pa.field('candidate_labels', pa.list_(pa.string(), list_size=3)),
pa.field('threshold', pa.float64()),
# pa.field('top_k', pa.int64()), # we want the model to return exactly the number of predictions, we shouldn't specify this])
output_schema=pa.schema([
pa.field('score', pa.list_(pa.float64())), # variable output, depending on detected objectspa.field('label', pa.list_(pa.string())), # variable output, depending on detected objectspa.field('box',
pa.list_( # dynamic output, i.e. dynamic number of boxes per input image, each sublist contains the 4 box coordinates pa.list_(
pa.int64(),
list_size=4 ),
),
),
])
Any parameter that is not part of the required inputs list will be forwarded to the model as a key/pair value to the underlying models generate method. If the additional input is not supported by the model, an error will be returned.
input_schema=pa.schema([
pa.field('inputs', pa.string()),
pa.field('return_tensors', pa.bool_()), # optionalpa.field('return_text', pa.bool_()), # optionalpa.field('return_full_text', pa.bool_()), # optionalpa.field('clean_up_tokenization_spaces', pa.bool_()), # optionalpa.field('prefix', pa.string()), # optionalpa.field('handle_long_generation', pa.string()), # optional# pa.field('extra_field', pa.int64()), # every extra field you specify will be forwarded as a key/value pair])
output_schema=pa.schema([
pa.field('generated_text', pa.list_(pa.string(), list_size=1))
])
SKLearn schema follows a different format than other models. To prevent inputs from being out of order, the inputs should be submitted in a single row in the order the model is trained to accept, with all of the data types being the same. For example, the following DataFrame has 4 columns, each column a float.
sepal length (cm)
sepal width (cm)
petal length (cm)
petal width (cm)
0
5.1
3.5
1.4
0.2
1
4.9
3.0
1.4
0.2
For submission to an SKLearn model, the data input schema will be a single array with 4 float values.
When submitting as an inference, the DataFrame is converted to rows with the column data expressed as a single array. The data must be in the same order as the model expects, which is why the data is submitted as a single array rather than JSON labeled columns: this insures that the data is submitted in the exact order as the model is trained to accept.
Original DataFrame:
sepal length (cm)
sepal width (cm)
petal length (cm)
petal width (cm)
0
5.1
3.5
1.4
0.2
1
4.9
3.0
1.4
0.2
Converted DataFrame:
inputs
0
[5.1, 3.5, 1.4, 0.2]
1
[4.9, 3.0, 1.4, 0.2]
SKLearn Schema Outputs
Outputs for SKLearn that are meant to be predictions or probabilities when output by the model are labeled in the output schema for the model when uploaded to Wallaroo. For example, a model that outputs either 1 or 0 as its output would have the output schema as follows:
TensorFlow Keras SavedModel models are .zip file of the SavedModel format. For example, the Aloha sample TensorFlow model is stored in the directory alohacnnlstm:
XGBoost schema follows a different format than other models. To prevent inputs from being out of order, the inputs should be submitted in a single row in the order the model is trained to accept, with all of the data types being the same. If a model is originally trained to accept inputs of different data types, it will need to be retrained to only accept one data type for each column - typically pa.float64() is a good choice.
For example, the following DataFrame has 4 columns, each column a float.
sepal length (cm)
sepal width (cm)
petal length (cm)
petal width (cm)
0
5.1
3.5
1.4
0.2
1
4.9
3.0
1.4
0.2
For submission to an XGBoost model, the data input schema will be a single array with 4 float values.
When submitting as an inference, the DataFrame is converted to rows with the column data expressed as a single array. The data must be in the same order as the model expects, which is why the data is submitted as a single array rather than JSON labeled columns: this insures that the data is submitted in the exact order as the model is trained to accept.
Original DataFrame:
sepal length (cm)
sepal width (cm)
petal length (cm)
petal width (cm)
0
5.1
3.5
1.4
0.2
1
4.9
3.0
1.4
0.2
Converted DataFrame:
inputs
0
[5.1, 3.5, 1.4, 0.2]
1
[4.9, 3.0, 1.4, 0.2]
XGBoost Schema Outputs
Outputs for XGBoost are labeled based on the trained model outputs. For this example, the output is simply a single output listed as output. In the Wallaroo inference result, it is grouped with the metadata out as out.output.
Arbitrary Python models, also known as Bring Your Own Predict (BYOP) allow for custom model deployments with supporting scripts and artifacts. These are used with pre-trained models (PyTorch, Tensorflow, etc) along with whatever supporting artifacts they require. Supporting artifacts can include other Python modules, model files, etc. These are zipped with all scripts, artifacts, and a requirements.txt file that indicates what other Python models need to be imported that are outside of the typical Wallaroo platform.
Contrast this with Wallaroo Python models - aka “Python steps”. These are standalone python scripts that use the python libraries natively supported by the Wallaroo platform. These are used for either simple model deployment (such as ARIMA Statsmodels), or data formatting such as the postprocessing steps. A Wallaroo Python model will be composed of one Python script that matches the Wallaroo requirements.
Arbitrary Python File Requirements
Arbitrary Python (BYOP) models are uploaded to Wallaroo via a ZIP file with the following components:
Artifact
Type
Description
Python scripts aka .py files with classes that extend mac.inference.Inference and mac.inference.creation.InferenceBuilder
Python Script
Extend the classes mac.inference.Inference and mac.inference.creation.InferenceBuilder. These are included with the Wallaroo SDK. Further details are in Arbitrary Python Script Requirements. Note that there is no specified naming requirements for the classes that extend mac.inference.Inference and mac.inference.creation.InferenceBuilder - any qualified class name is sufficient as long as these two classes are extended as defined below.
requirements.txt
Python requirements file
This sets the Python libraries used for the arbitrary python model. These libraries should be targeted for Python 3.8 compliance. These requirements and the versions of libraries should be exactly the same between creating the model and deploying it in Wallaroo. This insures that the script and methods will function exactly the same as during the model creation process.
Other artifacts
Files
Other models, files, and other artifacts used in support of this model.
For example, the if the arbitrary python model will be known as vgg_clustering, the contents may be in the following structure, with vgg_clustering as the storage directory:
Note the inclusion of the custom_inference.py file. This file name is not required - any Python script or scripts that extend the classes listed above are sufficient. This Python script could have been named vgg_custom_model.py or any other name as long as it includes the extension of the classes listed above.
The sample arbitrary python model file is created with the command zip -r vgg_clustering.zip vgg_clustering/.
Wallaroo Arbitrary Python uses the Wallaroo SDK mac module, included in the Wallaroo SDK 2023.2.1 and above. See the Wallaroo SDK Install Guides for instructions on installing the Wallaroo SDK.
Arbitrary Python Script Requirements
The entry point of the arbitrary python model is any python script that extends the following classes. These are included with the Wallaroo SDK. The required methods that must be overridden are specified in each section below.
mac.inference.Inference interface serves model inferences based on submitted input some input. Its purpose is to serve inferences for any supported arbitrary model framework (e.g. scikit, keras etc.).
classDiagram
class Inference {
<<Abstract>>
+model Optional[Any]
+expected_model_types()* Set
+predict(input_data: InferenceData)* InferenceData
-raise_error_if_model_is_not_assigned() None
-raise_error_if_model_is_wrong_type() None
}
mac.inference.creation.InferenceBuilder builds a concrete Inference, i.e. instantiates an Inference object, loads the appropriate model and assigns the model to to the Inference object.
classDiagram
class InferenceBuilder {
+create(config InferenceConfig) * Inference
-inference()* Any
}
mac.inference.Inference
mac.inference.Inference Objects
Object
Type
Description
model Optional[Any]
An optional list of models that match the supported frameworks from wallaroo.framework.Framework included in the arbitrary python script. Note that this is optional - no models are actually required. A BYOP can refer to a specific model(s) used, be used for data processing and reshaping for later pipeline steps, or other needs.
mac.inference.Inference Methods
Method
Returns
Description
expected_model_types (Required)
Set
Returns a Set of models expected for the inference as defined by the developer. Typically this is a set of one. Wallaroo checks the expected model types to verify that the model submitted through the InferenceBuilder method matches what this Inference class expects.
The entry point for the Wallaroo inference with the following input and output parameters that are defined when the model is updated.
mac.types.InferenceData: The inputInferenceData is a dictionary of numpy arrays derived from the input_schema detailed when the model is uploaded, defined in PyArrow.Schema format.
mac.types.InferenceData: The output is a dictionary of numpy arrays as defined by the output parameters defined in PyArrow.Schema format.
The InferenceDataValidationError exception is raised when the input data does not match mac.types.InferenceData.
raise_error_if_model_is_not_assigned
N/A
Error when expected_model_types is not set.
raise_error_if_model_is_wrong_type
N/A
Error when the model does not match the expected_model_types.
mac.inference.creation.InferenceBuilder
InferenceBuilder builds a concrete Inference, i.e. instantiates an Inference object, loads the appropriate model and assigns the model to the Inference.
classDiagram
class InferenceBuilder {
+create(config InferenceConfig) * Inference
-inference()* Any
}
Each model that is included requires its own InferenceBuilder. InferenceBuilder loads one model, then submits it to the Inference class when created. The Inference class checks this class against its expected_model_types() Set.
Creates an Inference subclass, then assigns a model and attributes. The CustomInferenceConfig is used to retrieve the config.model_path, which is a pathlib.Path object pointing to the folder where the model artifacts are saved. Every artifact loaded must be relative to config.model_path. This is set when the arbitrary python .zip file is uploaded and the environment for running it in Wallaroo is set. For example: loading the artifact vgg_clustering\feature_extractor.h5 would be set with config.model_path \ feature_extractor.h5. The model loaded must match an existing module. For our example, this is from sklearn.cluster import KMeans, and this must match the Inferenceexpected_model_types.
inference
custom Inference instance.
Returns the instantiated custom Inference object created from the create method.
Arbitrary Python Runtime
Arbitrary Python always run in the containerized model runtime.
Wallaroo users can register their trained MLFlow ML Models from a containerized model container registry into their Wallaroo instance and perform inferences with it through a Wallaroo pipeline.
As of this time, Wallaroo only supports MLFlow 1.30.0 containerized models. For information on how to containerize an MLFlow model, see the MLFlow Documentation.
The following data types are supported for transporting data to and from Wallaroo in the following run times:
ONNX
TensorFlow
MLFlow
Data Type Conditions
The following conditions apply to data types used in inference requests.
None or Null data types are not submitted. All fields must have submitted values that match their data type. For example, if the schema expects a float value, then some value of type float must be submitted and can not be None or Null. If a schema expects a string value, then some value of type string must be submitted, etc.
datetime data types must be converted to string.
ONNX models support multiple inputs only of the same data type.
Runtime
BFloat16*
Float16
Float32
Float64
ONNX
X
X
TensorFlow
X
X
X
MLFlow
X
X
X
* (Brain Float 16, represented internally as a f32)
Runtime
Int8
Int16
Int32
Int64
ONNX
X
X
X
X
TensorFlow
X
X
X
X
MLFlow
X
X
X
X
Runtime
Uint8
Uint16
Uint32
Uint64
ONNX
X
X
X
X
TensorFlow
X
X
X
X
MLFlow
X
X
X
X
Runtime
Boolean
Utf8 (String)
Complex 64
Complex 128
FixedSizeList*
ONNX
X
Tensor
X
X
X
MLFlow
X
X
X
* Fixed sized lists of any of the previously supported data types.
How to connect to a Wallaroo instance through the Wallaroo SDK
Users connect to a Wallaroo instance with the Wallaroo Client class. This connection can be made from within the Wallaroo instance, or external from the Wallaroo instance via the Wallaroo SDK.
The following methods are supported in connecting to the Wallaroo instance:
Connect from Within the Wallaroo Instance: Connect within the JupyterHub service or other method within the Kubernetes cluster hosting the Wallaroo instance. This requires confirming the connections with the Wallaroo instance through a browser link.
Connect from Outside the Wallaroo Instance: Connect via the Wallaroo SDK via an external connection to the Kubernetes cluster hosting the Wallaroo instance. This requires confirming the connections with the Wallaroo instance through a browser link.
Automated Connection: Connect to the Wallaroo instance by providing the username and password directly into the request. This bypasses confirming the connections with the Wallaroo instance through a browser link.
Once run, the wallaroo.Client command provides a URL to grant the SDK permission to your specific Wallaroo environment. When displayed, enter the URL into a browser and confirm permissions. Depending on the configuration of the Wallaroo instance, the user will either be presented with a login request to the Wallaroo instance or be authenticated through a broker such as Google, Github, etc. To use the broker, select it from the list under the username/password login forms. For more information on Wallaroo authentication configurations, see the Wallaroo Authentication Configuration Guides.
Once authenticated, the user will verify adding the device the user is establishing the connection from. Once both steps are complete, then the connection is granted.
Connect from Within the Wallaroo Instance
Users who connect from within their Wallaroo instance’s Kubernetes environment, such as through the Wallaroo provided JupyterHub service, will be authenticated with the Wallaroo Client() method.
The first step in using Wallaroo is creating a connection. To connect to your Wallaroo environment:
Import the wallaroo library:
importwallaroo
Open a connection to the Wallaroo environment with the wallaroo.Client() command and save it to a variable.
In this example, the Wallaroo connection is saved to the variable wl.
wl=wallaroo.Client()
A verification URL will be displayed. Enter it into your browser and grant access to the SDK client.
Once this is complete, you will be able to continue with your Wallaroo commands.
Connect from Outside the Wallaroo Instance
Users who have installed the Wallaroo SDK from an external location, such as their own JupyterHub service, Google Workbench, or other services can connect via Single-Sign On (SSO). This is accomplished using the wallaroo.Client(api_endpoint, auth_endpoint, auth_type command="sso") command that connects to the Wallaroo instance services. For more information on the DNS names of Wallaroo services, see the DNS Integration Guide.
api_endpoint (String): The URL to the Wallaroo instance API service.
auth_endpoint (String): The URL to the Wallaroo instance Keycloak service.
auth_type command (String): The authorization type. In this case, SSO.
Once run, the wallaroo.Client command provides a URL to grant the SDK permission to your specific Wallaroo environment. When displayed, enter the URL into a browser and confirm permissions. This connection is stored into a variable that can be referenced later.
In this example, a connection will be made to the Wallaroo instance shadowy-unicorn-5555.wallaroo.ai through SSO authentication.
importwallaroofromwallaroo.objectimportEntityNotFoundError# SSO login through keycloakwl=wallaroo.Client(api_endpoint="https://shadowy-unicorn-5555.api.wallaroo.ai",
auth_endpoint="https://shadowy-unicorn-5555.keycloak.wallaroo.ai",
auth_type="sso")
Users can connect either internally or externally without confirming the connection via a browser link using the wallaroo.Client(api_endpoint, auth_endpoint, auth_type="user_password") command for external connections, and wallaroo.Client(auth_type="user_password") with internal connections.
IMPORTANT NOTE
Using the parameter auth_type="user_password" does not require the verification of the connection’s permissions through a browser link. This is useful in automated environments.
IMPORTANT NOTE
Organizations using an identity providermust have both a username and password already stored in the Wallaroo Keycloak service for this method. By default, users who only use identity providers for authentication will not have a password set. See Wallaroo User Management for more information.
The auth_type="user_password" parameter requires either the environment parameter WALLAROO_SDK_CREDENTIALS with the following settings:
In typical installations, the username and email settings will both be the user’s email address.
For example, if the username is steve, the password is hello and the email is steve@ex.co then the ``WALLAROO_SDK_CREDENTIALS` can be set in the following ways:
# Import via fileos.environ["WALLAROO_SDK_CREDENTIALS"] ='creds.json'wl=wallaroo.Client(auth_type="user_password")
The other method:
# Set directlyos.environ["WALLAROO_USER"] ='username@company.com'os.environ["WALLAROO_PASSWORD"] ='password'wl=wallaroo.Client(auth_type="user_password")
For automated connections, using the environment options tied into a specific file with minimum access is recommended.
The following example shows connecting to a remote Wallaroo instance via the auth_type="user_password" parameter with the credentials stored in the creds.json file using the format above:
2.2 - Wallaroo SDK Essentials Guide: Data Connections Management
How to create and manage Wallaroo Data Connections through the Wallaroo SDK
Wallaroo Data Connections are provided to establish connections to external data stores for requesting or submitting information. They provide a source of truth for data source connection information to enable repeatability and access control within your ecosystem. The actual implementation of data connections are managed through other means, such as Wallaroo Pipeline Orchestrators and Tasks, where the libraries and other tools used for the data connection can be stored.
Wallaroo Data Connections have the following properties:
Available across the Wallaroo Instance: Data Connections are created at the Wallaroo instance level.
Tied to a Wallaroo Workspace: Data Connections, like pipeline and models, are tied to a workspace. This allows organizations to limit data connection access by restricting users to specific workspaces.
Support different types: Data Connections support various types of connections such as ODBC, Kafka, etc.
Create Data Connection
Data Connections are created through the Wallaroo Client create_connection(name, type, details) method.
Parameter
Type
Description
name
string (Required)
The name of the connection. Names must be unique. Attempting to create a connection with the same name as an existing connection will cause an error.
type
string (Required)
The user defined type of connection.
details
Dict (Required)
User defined configuration details for the data connection. These can be {'username':'dataperson', 'password':'datapassword', 'port': 3339}, or {'token':'abcde123==', 'host':'example.com', 'port:1234'}, or other user defined combinations.
The SDK allows the data connections to be fully defined and stored for later use. This allows whatever type of data connection the organization uses to be defined, then applied to a workspace for other Wallaroo users to integrate into their code.
When data connections are displayed via the Wallaroo Client list_connections, the details field is removed to not show sensitive information by default.
The Wallaroo client get_connection(name) method retrieves the connection with the Connection name matching the name parameter.
Parameter
Type
Description
name
string (Required)
The name of the connection.
In the following example, the connection name external_inference_connection will be retrieved and stored into the variable inference_source_connection.
The Wallaroo Client list_connections() method lists all connections for the Wallaroo instance. When data connections are displayed via the Wallaroo Client list_connections, the details field is removed to not show sensitive information by default.
wl.list_connections()
name
connection type
details
created at
houseprice_arrow_table
HTTPFILE
*****
2023-05-04T17:52:32.249322+00:00
Add Data Connection to Workspace
The method Workspace add_connection(connection_name) adds a Data Connection to a workspace, and takes the following parameters.
Parameter
Type
Description
name
string (Required)
The name of the Data Connection
Connection Details
The Connection method details() retrieves a the connection details() as a dict.
The Workspace method remove_connection(connection_name) removes the connection from the workspace, but does not delete the connection from the Wallaroo instance. This method takes the following parameters.
Parameter
Type
Description
name
String (Required)
The name of the connection to be removed from the workspace.
Delete Connection
The Connection method delete_connection() removes the connection from the Wallaroo instance.
Before deleting a connection, it must be removed from all workspaces that it is attached to.
How to create and use Wallaroo Workspaces through the Wallaroo SDK
Workspace Management
Workspaces are used to segment groups of models into separate environments. This allows different users to either manage or have access to each workspace, controlling the models and pipelines assigned to the workspace.
Workspace Naming Requirements
Workspace names map onto Kubernetes objects, and must be DNS compliant. Workspace names must be ASCII alpha-numeric characters or dash (-) only. . and _ are not allowed.
Workspace names are not forced to be unique. You can have 50 workspaces all named my-amazing-workspace, which can cause confusion in determining which workspace to use.
It is recommended that organizations agree on a naming convention and select the workspace to use rather than creating a new one each time.
To create a workspace, use the create_workspace("{WORKSPACE NAME}") command through an established Wallaroo connection and store the workspace settings into a new variable. Once the new workspace is created, the user who created the workspace is assigned as its owner. The following template is an example:
For example, if the connection is stored in the variable wl and the new workspace will be named imdb, then the command to store it in the new_workspace variable would be:
The command list_workspaces() displays the workspaces that are part of the current Wallaroo connection. The following details are returned as an array:
Parameter
Type
Description
Name
String
The name of the workspace. Note that workspace names are not unique.
Created At
DateTime
The date and time the workspace was created.
Users
Array[Users]
A list of all users assigned to this workspace.
Models
Integer
The number of models uploaded to the workspace.
Pipelines
Integer
The number of pipelines in the environment.
For example, for the Wallaroo connection wl the following workspaces are returned:
The current workspace can be set through set_current_workspace for the Wallaroo connection through the following call, and returns the workspace details as a JSON object:
The following example creates the workspace imdb-workspace through the Wallaroo connection stored in the variable wl, then sets it as the current workspace:
To set the current workspace from an established workspace, the easiest method is to use list_workspaces() then set the current workspace as the array value displayed. For example, from the following list_workspaces() command the 3rd workspace element demandcurve-workspace can be assigned as the current workspace:
Users are added to the workspace via their email address through the wallaroo.workspace.Workspace.add_user({email address}) command. The email address must be assigned to a current user in the Wallaroo platform before they can be assigned to the workspace.
For example, the following workspace imdb-workspace has the user steve@ex.co. We will add the user john@ex.co to this workspace:
Removing a user from a workspace is performed through the wallaroo.workspace.Workspace.remove_user({email address}) command, where the {email address} matches a user in the workspace.
In the following example, the user john@ex.co is removed from the workspace imdb-workspace.
To update the owner of workspace, or promote an existing user of a workspace to the owner of workspace, use the wallaroo.workspace.Workspace.add_owner({email address}) command. The email address must be assigned to a current user in the Wallaroo platform before they can be assigned as the owner to the workspace.
The following example shows assigning the user john@ex.co as an owner to the workspace imdb-workspace:
2.4 - Wallaroo SDK Essentials Guide: Model Uploads and Registrations
How to create and manage Wallaroo Models Uploads through the Wallaroo SDK
Models are uploaded or registered to a Wallaroo workspace depending on the model framework and version.
Wallaroo Engine Runtimes
Pipeline deployment configurations provide two runtimes to run models in the Wallaroo engine:
Native Runtimes: Models that are deployed “as is” with the Wallaroo engine. These are:
ONNX
Python step
Tensorflow 2.9.1 in SavedModel format
Containerized Runtimes: Containerized models such as MLFlow or Arbitrary Python. These are run in the Wallaroo engine in their containerized form.
Non-Native Runtimes: Models that when uploaded are either converted to a native Wallaroo runtime, or are containerized so they can be run in the Wallaroo engine. When uploaded, Wallaroo will attempt to convert it to a native runtime. If it can not be converted, then it will be packed in a Wallaroo containerized model based on its framework type.
Pipeline Deployment Configurations
Pipeline configurations are dependent on whether the model is converted to the Native Runtime space, or Containerized Model Runtime space.
This model will always run in the native runtime space.
Native Runtime Pipeline Deployment Configuration Example
The following configuration allocates 0.25 CPU and 1 Gi RAM to the native runtime models for a pipeline.
The following frameworks are supported. Frameworks fall under either Native or Containerized runtimes in the Wallaroo engine. For more details, see the specific framework what runtime a specific model framework runs in.
The supported frameworks include the specific version of the model framework supported by Wallaroo. It is highly recommended to verify that models uploaded to Wallaroo meet the library and version requirements to ensure proper functioning.
After April 2022 until release 2022.4 (December 2022)
1.10.*
7
15
2
Before April 2022
1.6.*
7
13
2
For the most recent release of Wallaroo 2023.2.1, the following native runtimes are supported:
If converting another ML Model to ONNX (PyTorch, XGBoost, etc) using the onnxconverter-common library, the supported DEFAULT_OPSET_NUMBER is 17.
Using different versions or settings outside of these specifications may result in inference issues and other unexpected behavior.
ONNX models always run in the native runtime space.
Data Schemas
ONNX models deployed to Wallaroo have the following data requirements.
Equal rows constraint: The number of input rows and output rows must match.
All inputs are tensors: The inputs are tensor arrays with the same shape.
Data Type Consistency: Data types within each tensor are of the same type.
Equal Rows Constraint
Inference performed through ONNX models are assumed to be in batch format, where each input row corresponds to an output row. This is reflected in the in fields returned for an inference. In the following example, each input row for an inference is related directly to the inference output.
For models that require ragged tensor or other shapes, see other data formatting options such as Bring Your Own Predict models.
Data Type Consistency
All inputs into an ONNX model must have the same internal data type. For example, the following is valid because all of the data types within each element are float32.
t= [
[2.35, 5.75],
[3.72, 8.55],
[5.55, 97.2]
]
The following is invalid, as it mixes floats and strings in each element:
These requirements are <strong>not</strong> for Tensorflow Keras models, only for non-Keras Tensorflow models in the SavedModel format. For Tensorflow Keras deployment in Wallaroo, see the Tensorflow Keras requirements.
TensorFlow File Format
TensorFlow models are .zip file of the SavedModel format. For example, the Aloha sample TensorFlow model is stored in the directory alohacnnlstm:
Python models uploaded to Wallaroo are executed as a native runtime.
Note that Python models - aka “Python steps” - are standalone python scripts that use the python libraries natively supported by the Wallaroo platform. These are used for either simple model deployment (such as ARIMA Statsmodels), or data formatting such as the postprocessing steps. A Wallaroo Python model will be composed of one Python script that matches the Wallaroo requirements.
This is contrasted with Arbitrary Python models, also known as Bring Your Own Predict (BYOP) allow for custom model deployments with supporting scripts and artifacts. These are used with pre-trained models (PyTorch, Tensorflow, etc) along with whatever supporting artifacts they require. Supporting artifacts can include other Python modules, model files, etc. These are zipped with all scripts, artifacts, and a requirements.txt file that indicates what other Python models need to be imported that are outside of the typical Wallaroo platform.
Python Models Requirements
Python models uploaded to Wallaroo are Python scripts that must include the wallaroo_json method as the entry point for the Wallaroo engine to use it as a Pipeline step.
This method receives the results of the previous Pipeline step, and its return value will be used in the next Pipeline step.
If the Python model is the first step in the pipeline, then it will be receiving the inference request data (for example: a preprocessing step). If it is the last step in the pipeline, then it will be the data returned from the inference request.
In the example below, the Python model is used as a post processing step for another ML model. The Python model expects to receive data from a ML Model who’s output is a DataFrame with the column dense_2. It then extracts the values of that column as a list, selects the first element, and returns a DataFrame with that element as the value of the column output.
In line with other Wallaroo inference results, the outputs of a Python step that returns a pandas DataFrame or Arrow Table will be listed in the out. metadata, with all inference outputs listed as out.{variable 1}, out.{variable 2}, etc. In the example above, this results the output field as the out.output field in the Wallaroo inference result.
Input and output schemas for each Hugging Face pipeline are defined below. Note that adding additional inputs not specified below will raise errors, except for the following:
Framework.HUGGING-FACE-IMAGE-TO-TEXT
Framework.HUGGING-FACE-TEXT-CLASSIFICATION
Framework.HUGGING-FACE-SUMMARIZATION
Framework.HUGGING-FACE-TRANSLATION
Additional inputs added to these Hugging Face pipelines will be added as key/pair value arguments to the model’s generate method. If the argument is not required, then the model will default to the values coded in the original Hugging Face model’s source code.
Any parameter that is not part of the required inputs list will be forwarded to the model as a key/pair value to the underlying models generate method. If the additional input is not supported by the model, an error will be returned.
Any parameter that is not part of the required inputs list will be forwarded to the model as a key/pair value to the underlying models generate method. If the additional input is not supported by the model, an error will be returned.
Schemas:
input_schema=pa.schema([
pa.field('inputs', pa.string()),
pa.field('return_text', pa.bool_()),
pa.field('return_tensors', pa.bool_()),
pa.field('clean_up_tokenization_spaces', pa.bool_()),
# pa.field('extra_field', pa.int64()), # every extra field you specify will be forwarded as a key/value pair])
output_schema=pa.schema([
pa.field('summary_text', pa.string()),
])
input_schema=pa.schema([
pa.field('inputs', pa.string()), # requiredpa.field('top_k', pa.int64()), # optionalpa.field('function_to_apply', pa.string()), # optional])
output_schema=pa.schema([
pa.field('label', pa.list_(pa.string(), list_size=2)), # list with a number of items same as top_k, list_size can be skipped but may lead in worse performancepa.field('score', pa.list_(pa.float64(), list_size=2)), # list with a number of items same as top_k, list_size can be skipped but may lead in worse performance])
Any parameter that is not part of the required inputs list will be forwarded to the model as a key/pair value to the underlying models generate method. If the additional input is not supported by the model, an error will be returned.
Schemas:
input_schema=pa.schema([
pa.field('inputs', pa.string()), # requiredpa.field('return_tensors', pa.bool_()), # optionalpa.field('return_text', pa.bool_()), # optionalpa.field('clean_up_tokenization_spaces', pa.bool_()), # optionalpa.field('src_lang', pa.string()), # optionalpa.field('tgt_lang', pa.string()), # optional# pa.field('extra_field', pa.int64()), # every extra field you specify will be forwarded as a key/value pair])
output_schema=pa.schema([
pa.field('translation_text', pa.string()),
])
input_schema=pa.schema([
pa.field('inputs', pa.string()), # requiredpa.field('candidate_labels', pa.list_(pa.string(), list_size=2)), # requiredpa.field('hypothesis_template', pa.string()), # optionalpa.field('multi_label', pa.bool_()), # optional])
output_schema=pa.schema([
pa.field('sequence', pa.string()),
pa.field('scores', pa.list_(pa.float64(), list_size=2)), # same as number of candidate labels, list_size can be skipped by may result in slightly worse performancepa.field('labels', pa.list_(pa.string(), list_size=2)), # same as number of candidate labels, list_size can be skipped by may result in slightly worse performance])
input_schema=pa.schema([
pa.field('images',
pa.list_(
pa.list_(
pa.list_(
pa.int64(),
list_size=3 ),
list_size=640 ),
list_size=480 )),
pa.field('candidate_labels', pa.list_(pa.string(), list_size=3)),
pa.field('threshold', pa.float64()),
# pa.field('top_k', pa.int64()), # we want the model to return exactly the number of predictions, we shouldn't specify this])
output_schema=pa.schema([
pa.field('score', pa.list_(pa.float64())), # variable output, depending on detected objectspa.field('label', pa.list_(pa.string())), # variable output, depending on detected objectspa.field('box',
pa.list_( # dynamic output, i.e. dynamic number of boxes per input image, each sublist contains the 4 box coordinates pa.list_(
pa.int64(),
list_size=4 ),
),
),
])
Any parameter that is not part of the required inputs list will be forwarded to the model as a key/pair value to the underlying models generate method. If the additional input is not supported by the model, an error will be returned.
input_schema=pa.schema([
pa.field('inputs', pa.string()),
pa.field('return_tensors', pa.bool_()), # optionalpa.field('return_text', pa.bool_()), # optionalpa.field('return_full_text', pa.bool_()), # optionalpa.field('clean_up_tokenization_spaces', pa.bool_()), # optionalpa.field('prefix', pa.string()), # optionalpa.field('handle_long_generation', pa.string()), # optional# pa.field('extra_field', pa.int64()), # every extra field you specify will be forwarded as a key/value pair])
output_schema=pa.schema([
pa.field('generated_text', pa.list_(pa.string(), list_size=1))
])
SKLearn schema follows a different format than other models. To prevent inputs from being out of order, the inputs should be submitted in a single row in the order the model is trained to accept, with all of the data types being the same. For example, the following DataFrame has 4 columns, each column a float.
sepal length (cm)
sepal width (cm)
petal length (cm)
petal width (cm)
0
5.1
3.5
1.4
0.2
1
4.9
3.0
1.4
0.2
For submission to an SKLearn model, the data input schema will be a single array with 4 float values.
When submitting as an inference, the DataFrame is converted to rows with the column data expressed as a single array. The data must be in the same order as the model expects, which is why the data is submitted as a single array rather than JSON labeled columns: this insures that the data is submitted in the exact order as the model is trained to accept.
Original DataFrame:
sepal length (cm)
sepal width (cm)
petal length (cm)
petal width (cm)
0
5.1
3.5
1.4
0.2
1
4.9
3.0
1.4
0.2
Converted DataFrame:
inputs
0
[5.1, 3.5, 1.4, 0.2]
1
[4.9, 3.0, 1.4, 0.2]
SKLearn Schema Outputs
Outputs for SKLearn that are meant to be predictions or probabilities when output by the model are labeled in the output schema for the model when uploaded to Wallaroo. For example, a model that outputs either 1 or 0 as its output would have the output schema as follows:
TensorFlow Keras SavedModel models are .zip file of the SavedModel format. For example, the Aloha sample TensorFlow model is stored in the directory alohacnnlstm:
XGBoost schema follows a different format than other models. To prevent inputs from being out of order, the inputs should be submitted in a single row in the order the model is trained to accept, with all of the data types being the same. If a model is originally trained to accept inputs of different data types, it will need to be retrained to only accept one data type for each column - typically pa.float64() is a good choice.
For example, the following DataFrame has 4 columns, each column a float.
sepal length (cm)
sepal width (cm)
petal length (cm)
petal width (cm)
0
5.1
3.5
1.4
0.2
1
4.9
3.0
1.4
0.2
For submission to an XGBoost model, the data input schema will be a single array with 4 float values.
When submitting as an inference, the DataFrame is converted to rows with the column data expressed as a single array. The data must be in the same order as the model expects, which is why the data is submitted as a single array rather than JSON labeled columns: this insures that the data is submitted in the exact order as the model is trained to accept.
Original DataFrame:
sepal length (cm)
sepal width (cm)
petal length (cm)
petal width (cm)
0
5.1
3.5
1.4
0.2
1
4.9
3.0
1.4
0.2
Converted DataFrame:
inputs
0
[5.1, 3.5, 1.4, 0.2]
1
[4.9, 3.0, 1.4, 0.2]
XGBoost Schema Outputs
Outputs for XGBoost are labeled based on the trained model outputs. For this example, the output is simply a single output listed as output. In the Wallaroo inference result, it is grouped with the metadata out as out.output.
Arbitrary Python models, also known as Bring Your Own Predict (BYOP) allow for custom model deployments with supporting scripts and artifacts. These are used with pre-trained models (PyTorch, Tensorflow, etc) along with whatever supporting artifacts they require. Supporting artifacts can include other Python modules, model files, etc. These are zipped with all scripts, artifacts, and a requirements.txt file that indicates what other Python models need to be imported that are outside of the typical Wallaroo platform.
Contrast this with Wallaroo Python models - aka “Python steps”. These are standalone python scripts that use the python libraries natively supported by the Wallaroo platform. These are used for either simple model deployment (such as ARIMA Statsmodels), or data formatting such as the postprocessing steps. A Wallaroo Python model will be composed of one Python script that matches the Wallaroo requirements.
Arbitrary Python File Requirements
Arbitrary Python (BYOP) models are uploaded to Wallaroo via a ZIP file with the following components:
Artifact
Type
Description
Python scripts aka .py files with classes that extend mac.inference.Inference and mac.inference.creation.InferenceBuilder
Python Script
Extend the classes mac.inference.Inference and mac.inference.creation.InferenceBuilder. These are included with the Wallaroo SDK. Further details are in Arbitrary Python Script Requirements. Note that there is no specified naming requirements for the classes that extend mac.inference.Inference and mac.inference.creation.InferenceBuilder - any qualified class name is sufficient as long as these two classes are extended as defined below.
requirements.txt
Python requirements file
This sets the Python libraries used for the arbitrary python model. These libraries should be targeted for Python 3.8 compliance. These requirements and the versions of libraries should be exactly the same between creating the model and deploying it in Wallaroo. This insures that the script and methods will function exactly the same as during the model creation process.
Other artifacts
Files
Other models, files, and other artifacts used in support of this model.
For example, the if the arbitrary python model will be known as vgg_clustering, the contents may be in the following structure, with vgg_clustering as the storage directory:
Note the inclusion of the custom_inference.py file. This file name is not required - any Python script or scripts that extend the classes listed above are sufficient. This Python script could have been named vgg_custom_model.py or any other name as long as it includes the extension of the classes listed above.
The sample arbitrary python model file is created with the command zip -r vgg_clustering.zip vgg_clustering/.
Wallaroo Arbitrary Python uses the Wallaroo SDK mac module, included in the Wallaroo SDK 2023.2.1 and above. See the Wallaroo SDK Install Guides for instructions on installing the Wallaroo SDK.
Arbitrary Python Script Requirements
The entry point of the arbitrary python model is any python script that extends the following classes. These are included with the Wallaroo SDK. The required methods that must be overridden are specified in each section below.
mac.inference.Inference interface serves model inferences based on submitted input some input. Its purpose is to serve inferences for any supported arbitrary model framework (e.g. scikit, keras etc.).
classDiagram
class Inference {
<<Abstract>>
+model Optional[Any]
+expected_model_types()* Set
+predict(input_data: InferenceData)* InferenceData
-raise_error_if_model_is_not_assigned() None
-raise_error_if_model_is_wrong_type() None
}
mac.inference.creation.InferenceBuilder builds a concrete Inference, i.e. instantiates an Inference object, loads the appropriate model and assigns the model to to the Inference object.
classDiagram
class InferenceBuilder {
+create(config InferenceConfig) * Inference
-inference()* Any
}
mac.inference.Inference
mac.inference.Inference Objects
Object
Type
Description
model Optional[Any]
An optional list of models that match the supported frameworks from wallaroo.framework.Framework included in the arbitrary python script. Note that this is optional - no models are actually required. A BYOP can refer to a specific model(s) used, be used for data processing and reshaping for later pipeline steps, or other needs.
mac.inference.Inference Methods
Method
Returns
Description
expected_model_types (Required)
Set
Returns a Set of models expected for the inference as defined by the developer. Typically this is a set of one. Wallaroo checks the expected model types to verify that the model submitted through the InferenceBuilder method matches what this Inference class expects.
The entry point for the Wallaroo inference with the following input and output parameters that are defined when the model is updated.
mac.types.InferenceData: The inputInferenceData is a dictionary of numpy arrays derived from the input_schema detailed when the model is uploaded, defined in PyArrow.Schema format.
mac.types.InferenceData: The output is a dictionary of numpy arrays as defined by the output parameters defined in PyArrow.Schema format.
The InferenceDataValidationError exception is raised when the input data does not match mac.types.InferenceData.
raise_error_if_model_is_not_assigned
N/A
Error when expected_model_types is not set.
raise_error_if_model_is_wrong_type
N/A
Error when the model does not match the expected_model_types.
mac.inference.creation.InferenceBuilder
InferenceBuilder builds a concrete Inference, i.e. instantiates an Inference object, loads the appropriate model and assigns the model to the Inference.
classDiagram
class InferenceBuilder {
+create(config InferenceConfig) * Inference
-inference()* Any
}
Each model that is included requires its own InferenceBuilder. InferenceBuilder loads one model, then submits it to the Inference class when created. The Inference class checks this class against its expected_model_types() Set.
Creates an Inference subclass, then assigns a model and attributes. The CustomInferenceConfig is used to retrieve the config.model_path, which is a pathlib.Path object pointing to the folder where the model artifacts are saved. Every artifact loaded must be relative to config.model_path. This is set when the arbitrary python .zip file is uploaded and the environment for running it in Wallaroo is set. For example: loading the artifact vgg_clustering\feature_extractor.h5 would be set with config.model_path \ feature_extractor.h5. The model loaded must match an existing module. For our example, this is from sklearn.cluster import KMeans, and this must match the Inferenceexpected_model_types.
inference
custom Inference instance.
Returns the instantiated custom Inference object created from the create method.
Arbitrary Python Runtime
Arbitrary Python always run in the containerized model runtime.
Wallaroo users can register their trained MLFlow ML Models from a containerized model container registry into their Wallaroo instance and perform inferences with it through a Wallaroo pipeline.
As of this time, Wallaroo only supports MLFlow 1.30.0 containerized models. For information on how to containerize an MLFlow model, see the MLFlow Documentation.
2.4.1 - Wallaroo SDK Essentials Guide: Model Uploads and Registrations: ONNX
How to upload and use ONNX ML Models with Wallaroo
Model Naming Requirements
Model names map onto Kubernetes objects, and must be DNS compliant. The strings for model names must be ASCII alpha-numeric characters or dash (-) only. . and _ are not allowed.
After April 2022 until release 2022.4 (December 2022)
1.10.*
7
15
2
Before April 2022
1.6.*
7
13
2
For the most recent release of Wallaroo 2023.2.1, the following native runtimes are supported:
If converting another ML Model to ONNX (PyTorch, XGBoost, etc) using the onnxconverter-common library, the supported DEFAULT_OPSET_NUMBER is 17.
Using different versions or settings outside of these specifications may result in inference issues and other unexpected behavior.
ONNX models always run in the native runtime space.
Data Schemas
ONNX models deployed to Wallaroo have the following data requirements.
Equal rows constraint: The number of input rows and output rows must match.
All inputs are tensors: The inputs are tensor arrays with the same shape.
Data Type Consistency: Data types within each tensor are of the same type.
Equal Rows Constraint
Inference performed through ONNX models are assumed to be in batch format, where each input row corresponds to an output row. This is reflected in the in fields returned for an inference. In the following example, each input row for an inference is related directly to the inference output.
For models that require ragged tensor or other shapes, see other data formatting options such as Bring Your Own Predict models.
Data Type Consistency
All inputs into an ONNX model must have the same internal data type. For example, the following is valid because all of the data types within each element are float32.
t= [
[2.35, 5.75],
[3.72, 8.55],
[5.55, 97.2]
]
The following is invalid, as it mixes floats and strings in each element:
Open Neural Network eXchange(ONNX) is the default model runtime supported by Wallaroo. ONNX models are uploaded to the current workspace through the Wallaroo Client upload_model(name, path, framework, input_schema, output_schema).configure(options). When uploading a default ML Model that matches the default Wallaroo runtime, the configure(options) can be left empty or the framework onnx specified.
Uploading ONNX Models
ONNX models are uploaded to Wallaroo through the Wallaroo Client upload_model method.
Upload ONNX Model Parameters
The following parameters are required for ONNX models. Note that while some fields are considered as optional for the upload_model method, they are required for proper uploading of a ONNX model to Wallaroo.
For ONNX models, the input_schema and output_schema are not required so are not listed here.
Parameter
Type
Description
name
string (Required)
The name of the model. Model names are unique per workspace. Models that are uploaded with the same name are assigned as a new version of the model.
path
string (Required)
The path to the model file being uploaded.
framework
string (Required)
Set as the Framework.ONNX.
input_schema
pyarrow.lib.Schema (Optional)
The input schema in Apache Arrow schema format.
output_schema
pyarrow.lib.Schema (Optional)
The output schema in Apache Arrow schema format.
convert_wait
bool (Optional) (Default: True)
Not required for native runtimes.
True: Waits in the script for the model conversion completion.
False: Proceeds with the script without waiting for the model conversion process to display complete.
Once the upload process starts, the model is containerized by the Wallaroo instance. This process may take up to 10 minutes.
Upload ONNX Model Return
The following is returned with a successful model upload and conversion.
Field
Type
Description
name
string
The name of the model.
version
string
The model version as a unique UUID.
file_name
string
The file name of the model as stored in Wallaroo.
SHA
string
The hash value of the model file.
Status
string
The status of the model. Values include:
image_path
string
The image used to deploy the model in the Wallaroo engine.
When converting from one ML model type to an ONNX ML model, the input and output fields should be specified so users anticipate the exact field names used in their code. This prevents conversion naming formats from creating unintended names, and sets consistent field names that can be relied upon in future code updates.
The following example shows naming the input and output names when converting from a PyTorch model to an ONNX model. Note that the input fields are set to data, and the output fields are set to output_names = ["bounding-box", "classification","confidence"].
2.4.2 - Wallaroo SDK Essentials Guide: Model Uploads and Registrations: Arbitrary Python
How to upload and use Containerized MLFlow with Wallaroo
Arbitrary Python or BYOP (Bring Your Own Predict) allows organizations to use Python scripts and supporting libraries as it’s own model. Similar to using a Python step, arbitrary python is an even more robust and flexible tool for working with ML Models in Wallaroo pipelines.
Arbitrary Python models, also known as Bring Your Own Predict (BYOP) allow for custom model deployments with supporting scripts and artifacts. These are used with pre-trained models (PyTorch, Tensorflow, etc) along with whatever supporting artifacts they require. Supporting artifacts can include other Python modules, model files, etc. These are zipped with all scripts, artifacts, and a requirements.txt file that indicates what other Python models need to be imported that are outside of the typical Wallaroo platform.
Contrast this with Wallaroo Python models - aka “Python steps”. These are standalone python scripts that use the python libraries natively supported by the Wallaroo platform. These are used for either simple model deployment (such as ARIMA Statsmodels), or data formatting such as the postprocessing steps. A Wallaroo Python model will be composed of one Python script that matches the Wallaroo requirements.
Arbitrary Python File Requirements
Arbitrary Python (BYOP) models are uploaded to Wallaroo via a ZIP file with the following components:
Artifact
Type
Description
Python scripts aka .py files with classes that extend mac.inference.Inference and mac.inference.creation.InferenceBuilder
Python Script
Extend the classes mac.inference.Inference and mac.inference.creation.InferenceBuilder. These are included with the Wallaroo SDK. Further details are in Arbitrary Python Script Requirements. Note that there is no specified naming requirements for the classes that extend mac.inference.Inference and mac.inference.creation.InferenceBuilder - any qualified class name is sufficient as long as these two classes are extended as defined below.
requirements.txt
Python requirements file
This sets the Python libraries used for the arbitrary python model. These libraries should be targeted for Python 3.8 compliance. These requirements and the versions of libraries should be exactly the same between creating the model and deploying it in Wallaroo. This insures that the script and methods will function exactly the same as during the model creation process.
Other artifacts
Files
Other models, files, and other artifacts used in support of this model.
For example, the if the arbitrary python model will be known as vgg_clustering, the contents may be in the following structure, with vgg_clustering as the storage directory:
Note the inclusion of the custom_inference.py file. This file name is not required - any Python script or scripts that extend the classes listed above are sufficient. This Python script could have been named vgg_custom_model.py or any other name as long as it includes the extension of the classes listed above.
The sample arbitrary python model file is created with the command zip -r vgg_clustering.zip vgg_clustering/.
Wallaroo Arbitrary Python uses the Wallaroo SDK mac module, included in the Wallaroo SDK 2023.2.1 and above. See the Wallaroo SDK Install Guides for instructions on installing the Wallaroo SDK.
Arbitrary Python Script Requirements
The entry point of the arbitrary python model is any python script that extends the following classes. These are included with the Wallaroo SDK. The required methods that must be overridden are specified in each section below.
mac.inference.Inference interface serves model inferences based on submitted input some input. Its purpose is to serve inferences for any supported arbitrary model framework (e.g. scikit, keras etc.).
classDiagram
class Inference {
<<Abstract>>
+model Optional[Any]
+expected_model_types()* Set
+predict(input_data: InferenceData)* InferenceData
-raise_error_if_model_is_not_assigned() None
-raise_error_if_model_is_wrong_type() None
}
mac.inference.creation.InferenceBuilder builds a concrete Inference, i.e. instantiates an Inference object, loads the appropriate model and assigns the model to to the Inference object.
classDiagram
class InferenceBuilder {
+create(config InferenceConfig) * Inference
-inference()* Any
}
mac.inference.Inference
mac.inference.Inference Objects
Object
Type
Description
model Optional[Any]
An optional list of models that match the supported frameworks from wallaroo.framework.Framework included in the arbitrary python script. Note that this is optional - no models are actually required. A BYOP can refer to a specific model(s) used, be used for data processing and reshaping for later pipeline steps, or other needs.
mac.inference.Inference Methods
Method
Returns
Description
expected_model_types (Required)
Set
Returns a Set of models expected for the inference as defined by the developer. Typically this is a set of one. Wallaroo checks the expected model types to verify that the model submitted through the InferenceBuilder method matches what this Inference class expects.
The entry point for the Wallaroo inference with the following input and output parameters that are defined when the model is updated.
mac.types.InferenceData: The inputInferenceData is a dictionary of numpy arrays derived from the input_schema detailed when the model is uploaded, defined in PyArrow.Schema format.
mac.types.InferenceData: The output is a dictionary of numpy arrays as defined by the output parameters defined in PyArrow.Schema format.
The InferenceDataValidationError exception is raised when the input data does not match mac.types.InferenceData.
raise_error_if_model_is_not_assigned
N/A
Error when expected_model_types is not set.
raise_error_if_model_is_wrong_type
N/A
Error when the model does not match the expected_model_types.
mac.inference.creation.InferenceBuilder
InferenceBuilder builds a concrete Inference, i.e. instantiates an Inference object, loads the appropriate model and assigns the model to the Inference.
classDiagram
class InferenceBuilder {
+create(config InferenceConfig) * Inference
-inference()* Any
}
Each model that is included requires its own InferenceBuilder. InferenceBuilder loads one model, then submits it to the Inference class when created. The Inference class checks this class against its expected_model_types() Set.
Creates an Inference subclass, then assigns a model and attributes. The CustomInferenceConfig is used to retrieve the config.model_path, which is a pathlib.Path object pointing to the folder where the model artifacts are saved. Every artifact loaded must be relative to config.model_path. This is set when the arbitrary python .zip file is uploaded and the environment for running it in Wallaroo is set. For example: loading the artifact vgg_clustering\feature_extractor.h5 would be set with config.model_path \ feature_extractor.h5. The model loaded must match an existing module. For our example, this is from sklearn.cluster import KMeans, and this must match the Inferenceexpected_model_types.
inference
custom Inference instance.
Returns the instantiated custom Inference object created from the create method.
Arbitrary Python Runtime
Arbitrary Python always run in the containerized model runtime.
Upload Arbitrary Python Model
Arbitrary Python models are uploaded to Wallaroo through the Wallaroo Client upload_model method.
Upload Arbitrary Python Model Parameters
The following parameters are required for Arbitrary Python models. Note that while some fields are considered as optional for the upload_model method, they are required for proper uploading of a Arbitrary Python model to Wallaroo.
Parameter
Type
Description
name
string (Required)
The name of the model. Model names are unique per workspace. Models that are uploaded with the same name are assigned as a new version of the model.
path
string (Required)
The path to the model file being uploaded.
framework
string (Upload Method Optional, Arbitrary Python model Required)
Set as Framework.CUSTOM.
input_schema
pyarrow.lib.Schema (Upload Method Optional, Arbitrary Python model Required)
The input schema in Apache Arrow schema format.
output_schema
pyarrow.lib.Schema (Upload Method Optional, Arbitrary Python model Required)
The output schema in Apache Arrow schema format.
convert_wait
bool (Upload Method Optional, Arbitrary Python model Optional) (Default: True)
True: Waits in the script for the model conversion completion.
False: Proceeds with the script without waiting for the model conversion process to display complete.
Once the upload process starts, the model is containerized by the Wallaroo instance. This process may take up to 10 minutes.
Upload Arbitrary Python Model Return
The following is returned with a successful model upload and conversion.
Field
Type
Description
name
string
The name of the model.
version
string
The model version as a unique UUID.
file_name
string
The file name of the model as stored in Wallaroo.
image_path
string
The image used to deploy the model in the Wallaroo engine.
last_update_time
DateTime
When the model was last updated.
Upload Arbitrary Python Model Example
The following example is of uploading a Arbitrary Python VGG16 Clustering ML Model to a Wallaroo instance.
Arbitrary Python Script Example
The following is an example script that fulfills the requirements for a Wallaroo Arbitrary Python Model, and would be saved as custom_inference.py.
"""This module features an example implementation of a custom Inference and its
corresponding InferenceBuilder."""importpathlibimportpicklefromtypingimportAny, Setimporttensorflowastffrommac.config.inferenceimportCustomInferenceConfigfrommac.inferenceimportInferencefrommac.inference.creationimportInferenceBuilderfrommac.typesimportInferenceDatafromsklearn.clusterimportKMeansclassImageClustering(Inference):
"""Inference class for image clustering, that uses
a pre-trained VGG16 model on cifar10 as a feature extractor
and performs clustering on a trained KMeans model.
Attributes:
- feature_extractor: The embedding model we will use
as a feature extractor (i.e. a trained VGG16).
- expected_model_types: A set of model instance types that are expected by this inference.
- model: The model on which the inference is calculated.
"""def__init__(self, feature_extractor: tf.keras.Model):
self.feature_extractor=feature_extractorsuper().__init__()
@propertydefexpected_model_types(self) ->Set[Any]:
return {KMeans}
@Inference.model.setter# type: ignoredefmodel(self, model) ->None:
"""Sets the model on which the inference is calculated.
:param model: A model instance on which the inference is calculated.
:raises TypeError: If the model is not an instance of expected_model_types
(i.e. KMeans).
"""self._raise_error_if_model_is_wrong_type(model) # this will make sure an error will be raised if the model is of wrong typeself._model=modeldef_predict(self, input_data: InferenceData) ->InferenceData:
"""Calculates the inference on the given input data.
This is the core function that each subclass needs to implement
in order to calculate the inference.
:param input_data: The input data on which the inference is calculated.
It is of type InferenceData, meaning it comes as a dictionary of numpy
arrays.
:raises InferenceDataValidationError: If the input data is not valid.
Ideally, every subclass should raise this error if the input data is not valid.
:return: The output of the model, that is a dictionary of numpy arrays.
"""# input_data maps to the input_schema we have defined# with PyArrow, coming as a dictionary of numpy arraysinputs=input_data["images"]
# Forward inputs to the modelsembeddings=self.feature_extractor(inputs)
predictions=self.model.predict(embeddings.numpy())
# Return predictions as dictionary of numpy arraysreturn {"predictions": predictions}
classImageClusteringBuilder(InferenceBuilder):
"""InferenceBuilder subclass for ImageClustering, that loads
a pre-trained VGG16 model on cifar10 as a feature extractor
and a trained KMeans model, and creates an ImageClustering object."""@propertydefinference(self) ->ImageClustering:
returnImageClusteringdefcreate(self, config: CustomInferenceConfig) ->ImageClustering:
"""Creates an Inference subclass and assigns a model and additionally
needed attributes to it.
:param config: Custom inference configuration. In particular, we're
interested in `config.model_path` that is a pathlib.Path object
pointing to the folder where the model artifacts are saved.
Every artifact we need to load from this folder has to be
relative to `config.model_path`.
:return: A custom Inference instance.
"""feature_extractor=self._load_feature_extractor(
config.model_path/"feature_extractor.h5" )
inference=self.inference(feature_extractor)
model=self._load_model(config.model_path/"kmeans.pkl")
inference.model=modelreturninferencedef_load_feature_extractor(
self, file_path: pathlib.Path ) ->tf.keras.Model:
returntf.keras.models.load_model(file_path)
def_load_model(self, file_path: pathlib.Path) ->KMeans:
withopen(file_path.as_posix(), "rb") asfp:
model=pickle.load(fp)
returnmodel
The following is the requirements.txt file that would be included in the arbitrary python ZIP file. It is highly recommended to use the same requirements.txt file for setting the libraries and versions used to create the model in the arbitrary python ZIP file.
tensorflow==2.8.0scikit-learn==1.2.2
Upload Upload Arbitrary Python Example
The following example demonstrates uploading the arbitrary python model as vgg_clustering.zip with the following input and output schemas defined.
Pipeline deployment configurations are dependent on whether the model is converted to the Native Runtime space, or Containerized Model Runtime space. This model will always run in the containerized runtime space.
Containerized Runtime Deployment Example
The following configuration allocates 0.25 CPU and 1 Gi RAM to a specific containerized model in the containerized runtime, along with other environmental variables for the containerized model. Note that for containerized models, resources must be allocated per specific model.
Wallaroo users can register their trained MLFlow ML Models from a containerized model container registry into their Wallaroo instance and perform inferences with it through a Wallaroo pipeline.
As of this time, Wallaroo only supports MLFlow 1.30.0 containerized models. For information on how to containerize an MLFlow model, see the MLFlow Documentation.
Model names map onto Kubernetes objects, and must be DNS compliant. The strings for model names must be ASCII alpha-numeric characters or dash (-) only. . and _ are not allowed.
Register a Containerized MLFlow Model
Containerized MLFlow models are not uploaded, but registered from a container registry service. This is performed through the Wallaroo Client .register_model_image(name, image).configure(options) method. For the options, the following must be defined:
runtime: Set as mlflow.
input_schema: The input schema from the Apache Arrow pyarrow.lib.Schema format.
output_schema: The output schema from the Apache Arrow pyarrow.lib.Schema format.
Pipeline deployment configurations are dependent on whether the model is converted to the Native Runtime space, or Containerized Model Runtime space. This model will always run in the containerized runtime space.
Containerized Runtime Deployment Example
The following configuration allocates 0.25 CPU and 1 Gi RAM to a specific containerized model in the containerized runtime, along with other environmental variables for the containerized model. Note that for containerized models, resources must be allocated per specific model.
2.4.4 - Wallaroo SDK Essentials Guide: Model Uploads and Registrations: Model Registry Services
How to upload and use Registry ML Models with Wallaroo
Wallaroo users can register their trained machine learning models from a model registry into their Wallaroo instance and perform inferences with it through a Wallaroo pipeline.
This guide details how to add ML Models from a model registry service into a Wallaroo instance.
Artifact Requirements
Models are uploaded to the Wallaroo instance as the specific artifact - the “file” or other data that represents the file itself. This must comply with the Wallaroo model requirements framework and version or it will not be deployed. Note that for models that fall outside of the supported model types, they can be registered to a Wallaroo workspace as MLFlow 1.30.0 containerized models.
Supported Models
The following frameworks are supported. Frameworks fall under either Native or Containerized runtimes in the Wallaroo engine. For more details, see the specific framework what runtime a specific model framework runs in.
The supported frameworks include the specific version of the model framework supported by Wallaroo. It is highly recommended to verify that models uploaded to Wallaroo meet the library and version requirements to ensure proper functioning.
After April 2022 until release 2022.4 (December 2022)
1.10.*
7
15
2
Before April 2022
1.6.*
7
13
2
For the most recent release of Wallaroo 2023.2.1, the following native runtimes are supported:
If converting another ML Model to ONNX (PyTorch, XGBoost, etc) using the onnxconverter-common library, the supported DEFAULT_OPSET_NUMBER is 17.
Using different versions or settings outside of these specifications may result in inference issues and other unexpected behavior.
ONNX models always run in the native runtime space.
Data Schemas
ONNX models deployed to Wallaroo have the following data requirements.
Equal rows constraint: The number of input rows and output rows must match.
All inputs are tensors: The inputs are tensor arrays with the same shape.
Data Type Consistency: Data types within each tensor are of the same type.
Equal Rows Constraint
Inference performed through ONNX models are assumed to be in batch format, where each input row corresponds to an output row. This is reflected in the in fields returned for an inference. In the following example, each input row for an inference is related directly to the inference output.
For models that require ragged tensor or other shapes, see other data formatting options such as Bring Your Own Predict models.
Data Type Consistency
All inputs into an ONNX model must have the same internal data type. For example, the following is valid because all of the data types within each element are float32.
t= [
[2.35, 5.75],
[3.72, 8.55],
[5.55, 97.2]
]
The following is invalid, as it mixes floats and strings in each element:
These requirements are <strong>not</strong> for Tensorflow Keras models, only for non-Keras Tensorflow models in the SavedModel format. For Tensorflow Keras deployment in Wallaroo, see the Tensorflow Keras requirements.
TensorFlow File Format
TensorFlow models are .zip file of the SavedModel format. For example, the Aloha sample TensorFlow model is stored in the directory alohacnnlstm:
Python models uploaded to Wallaroo are executed as a native runtime.
Note that Python models - aka “Python steps” - are standalone python scripts that use the python libraries natively supported by the Wallaroo platform. These are used for either simple model deployment (such as ARIMA Statsmodels), or data formatting such as the postprocessing steps. A Wallaroo Python model will be composed of one Python script that matches the Wallaroo requirements.
This is contrasted with Arbitrary Python models, also known as Bring Your Own Predict (BYOP) allow for custom model deployments with supporting scripts and artifacts. These are used with pre-trained models (PyTorch, Tensorflow, etc) along with whatever supporting artifacts they require. Supporting artifacts can include other Python modules, model files, etc. These are zipped with all scripts, artifacts, and a requirements.txt file that indicates what other Python models need to be imported that are outside of the typical Wallaroo platform.
Python Models Requirements
Python models uploaded to Wallaroo are Python scripts that must include the wallaroo_json method as the entry point for the Wallaroo engine to use it as a Pipeline step.
This method receives the results of the previous Pipeline step, and its return value will be used in the next Pipeline step.
If the Python model is the first step in the pipeline, then it will be receiving the inference request data (for example: a preprocessing step). If it is the last step in the pipeline, then it will be the data returned from the inference request.
In the example below, the Python model is used as a post processing step for another ML model. The Python model expects to receive data from a ML Model who’s output is a DataFrame with the column dense_2. It then extracts the values of that column as a list, selects the first element, and returns a DataFrame with that element as the value of the column output.
In line with other Wallaroo inference results, the outputs of a Python step that returns a pandas DataFrame or Arrow Table will be listed in the out. metadata, with all inference outputs listed as out.{variable 1}, out.{variable 2}, etc. In the example above, this results the output field as the out.output field in the Wallaroo inference result.
Input and output schemas for each Hugging Face pipeline are defined below. Note that adding additional inputs not specified below will raise errors, except for the following:
Framework.HUGGING-FACE-IMAGE-TO-TEXT
Framework.HUGGING-FACE-TEXT-CLASSIFICATION
Framework.HUGGING-FACE-SUMMARIZATION
Framework.HUGGING-FACE-TRANSLATION
Additional inputs added to these Hugging Face pipelines will be added as key/pair value arguments to the model’s generate method. If the argument is not required, then the model will default to the values coded in the original Hugging Face model’s source code.
Any parameter that is not part of the required inputs list will be forwarded to the model as a key/pair value to the underlying models generate method. If the additional input is not supported by the model, an error will be returned.
Any parameter that is not part of the required inputs list will be forwarded to the model as a key/pair value to the underlying models generate method. If the additional input is not supported by the model, an error will be returned.
Schemas:
input_schema=pa.schema([
pa.field('inputs', pa.string()),
pa.field('return_text', pa.bool_()),
pa.field('return_tensors', pa.bool_()),
pa.field('clean_up_tokenization_spaces', pa.bool_()),
# pa.field('extra_field', pa.int64()), # every extra field you specify will be forwarded as a key/value pair])
output_schema=pa.schema([
pa.field('summary_text', pa.string()),
])
input_schema=pa.schema([
pa.field('inputs', pa.string()), # requiredpa.field('top_k', pa.int64()), # optionalpa.field('function_to_apply', pa.string()), # optional])
output_schema=pa.schema([
pa.field('label', pa.list_(pa.string(), list_size=2)), # list with a number of items same as top_k, list_size can be skipped but may lead in worse performancepa.field('score', pa.list_(pa.float64(), list_size=2)), # list with a number of items same as top_k, list_size can be skipped but may lead in worse performance])
Any parameter that is not part of the required inputs list will be forwarded to the model as a key/pair value to the underlying models generate method. If the additional input is not supported by the model, an error will be returned.
Schemas:
input_schema=pa.schema([
pa.field('inputs', pa.string()), # requiredpa.field('return_tensors', pa.bool_()), # optionalpa.field('return_text', pa.bool_()), # optionalpa.field('clean_up_tokenization_spaces', pa.bool_()), # optionalpa.field('src_lang', pa.string()), # optionalpa.field('tgt_lang', pa.string()), # optional# pa.field('extra_field', pa.int64()), # every extra field you specify will be forwarded as a key/value pair])
output_schema=pa.schema([
pa.field('translation_text', pa.string()),
])
input_schema=pa.schema([
pa.field('inputs', pa.string()), # requiredpa.field('candidate_labels', pa.list_(pa.string(), list_size=2)), # requiredpa.field('hypothesis_template', pa.string()), # optionalpa.field('multi_label', pa.bool_()), # optional])
output_schema=pa.schema([
pa.field('sequence', pa.string()),
pa.field('scores', pa.list_(pa.float64(), list_size=2)), # same as number of candidate labels, list_size can be skipped by may result in slightly worse performancepa.field('labels', pa.list_(pa.string(), list_size=2)), # same as number of candidate labels, list_size can be skipped by may result in slightly worse performance])
input_schema=pa.schema([
pa.field('images',
pa.list_(
pa.list_(
pa.list_(
pa.int64(),
list_size=3 ),
list_size=640 ),
list_size=480 )),
pa.field('candidate_labels', pa.list_(pa.string(), list_size=3)),
pa.field('threshold', pa.float64()),
# pa.field('top_k', pa.int64()), # we want the model to return exactly the number of predictions, we shouldn't specify this])
output_schema=pa.schema([
pa.field('score', pa.list_(pa.float64())), # variable output, depending on detected objectspa.field('label', pa.list_(pa.string())), # variable output, depending on detected objectspa.field('box',
pa.list_( # dynamic output, i.e. dynamic number of boxes per input image, each sublist contains the 4 box coordinates pa.list_(
pa.int64(),
list_size=4 ),
),
),
])
Any parameter that is not part of the required inputs list will be forwarded to the model as a key/pair value to the underlying models generate method. If the additional input is not supported by the model, an error will be returned.
input_schema=pa.schema([
pa.field('inputs', pa.string()),
pa.field('return_tensors', pa.bool_()), # optionalpa.field('return_text', pa.bool_()), # optionalpa.field('return_full_text', pa.bool_()), # optionalpa.field('clean_up_tokenization_spaces', pa.bool_()), # optionalpa.field('prefix', pa.string()), # optionalpa.field('handle_long_generation', pa.string()), # optional# pa.field('extra_field', pa.int64()), # every extra field you specify will be forwarded as a key/value pair])
output_schema=pa.schema([
pa.field('generated_text', pa.list_(pa.string(), list_size=1))
])
SKLearn schema follows a different format than other models. To prevent inputs from being out of order, the inputs should be submitted in a single row in the order the model is trained to accept, with all of the data types being the same. For example, the following DataFrame has 4 columns, each column a float.
sepal length (cm)
sepal width (cm)
petal length (cm)
petal width (cm)
0
5.1
3.5
1.4
0.2
1
4.9
3.0
1.4
0.2
For submission to an SKLearn model, the data input schema will be a single array with 4 float values.
When submitting as an inference, the DataFrame is converted to rows with the column data expressed as a single array. The data must be in the same order as the model expects, which is why the data is submitted as a single array rather than JSON labeled columns: this insures that the data is submitted in the exact order as the model is trained to accept.
Original DataFrame:
sepal length (cm)
sepal width (cm)
petal length (cm)
petal width (cm)
0
5.1
3.5
1.4
0.2
1
4.9
3.0
1.4
0.2
Converted DataFrame:
inputs
0
[5.1, 3.5, 1.4, 0.2]
1
[4.9, 3.0, 1.4, 0.2]
SKLearn Schema Outputs
Outputs for SKLearn that are meant to be predictions or probabilities when output by the model are labeled in the output schema for the model when uploaded to Wallaroo. For example, a model that outputs either 1 or 0 as its output would have the output schema as follows:
TensorFlow Keras SavedModel models are .zip file of the SavedModel format. For example, the Aloha sample TensorFlow model is stored in the directory alohacnnlstm:
XGBoost schema follows a different format than other models. To prevent inputs from being out of order, the inputs should be submitted in a single row in the order the model is trained to accept, with all of the data types being the same. If a model is originally trained to accept inputs of different data types, it will need to be retrained to only accept one data type for each column - typically pa.float64() is a good choice.
For example, the following DataFrame has 4 columns, each column a float.
sepal length (cm)
sepal width (cm)
petal length (cm)
petal width (cm)
0
5.1
3.5
1.4
0.2
1
4.9
3.0
1.4
0.2
For submission to an XGBoost model, the data input schema will be a single array with 4 float values.
When submitting as an inference, the DataFrame is converted to rows with the column data expressed as a single array. The data must be in the same order as the model expects, which is why the data is submitted as a single array rather than JSON labeled columns: this insures that the data is submitted in the exact order as the model is trained to accept.
Original DataFrame:
sepal length (cm)
sepal width (cm)
petal length (cm)
petal width (cm)
0
5.1
3.5
1.4
0.2
1
4.9
3.0
1.4
0.2
Converted DataFrame:
inputs
0
[5.1, 3.5, 1.4, 0.2]
1
[4.9, 3.0, 1.4, 0.2]
XGBoost Schema Outputs
Outputs for XGBoost are labeled based on the trained model outputs. For this example, the output is simply a single output listed as output. In the Wallaroo inference result, it is grouped with the metadata out as out.output.
Arbitrary Python models, also known as Bring Your Own Predict (BYOP) allow for custom model deployments with supporting scripts and artifacts. These are used with pre-trained models (PyTorch, Tensorflow, etc) along with whatever supporting artifacts they require. Supporting artifacts can include other Python modules, model files, etc. These are zipped with all scripts, artifacts, and a requirements.txt file that indicates what other Python models need to be imported that are outside of the typical Wallaroo platform.
Contrast this with Wallaroo Python models - aka “Python steps”. These are standalone python scripts that use the python libraries natively supported by the Wallaroo platform. These are used for either simple model deployment (such as ARIMA Statsmodels), or data formatting such as the postprocessing steps. A Wallaroo Python model will be composed of one Python script that matches the Wallaroo requirements.
Arbitrary Python File Requirements
Arbitrary Python (BYOP) models are uploaded to Wallaroo via a ZIP file with the following components:
Artifact
Type
Description
Python scripts aka .py files with classes that extend mac.inference.Inference and mac.inference.creation.InferenceBuilder
Python Script
Extend the classes mac.inference.Inference and mac.inference.creation.InferenceBuilder. These are included with the Wallaroo SDK. Further details are in Arbitrary Python Script Requirements. Note that there is no specified naming requirements for the classes that extend mac.inference.Inference and mac.inference.creation.InferenceBuilder - any qualified class name is sufficient as long as these two classes are extended as defined below.
requirements.txt
Python requirements file
This sets the Python libraries used for the arbitrary python model. These libraries should be targeted for Python 3.8 compliance. These requirements and the versions of libraries should be exactly the same between creating the model and deploying it in Wallaroo. This insures that the script and methods will function exactly the same as during the model creation process.
Other artifacts
Files
Other models, files, and other artifacts used in support of this model.
For example, the if the arbitrary python model will be known as vgg_clustering, the contents may be in the following structure, with vgg_clustering as the storage directory:
Note the inclusion of the custom_inference.py file. This file name is not required - any Python script or scripts that extend the classes listed above are sufficient. This Python script could have been named vgg_custom_model.py or any other name as long as it includes the extension of the classes listed above.
The sample arbitrary python model file is created with the command zip -r vgg_clustering.zip vgg_clustering/.
Wallaroo Arbitrary Python uses the Wallaroo SDK mac module, included in the Wallaroo SDK 2023.2.1 and above. See the Wallaroo SDK Install Guides for instructions on installing the Wallaroo SDK.
Arbitrary Python Script Requirements
The entry point of the arbitrary python model is any python script that extends the following classes. These are included with the Wallaroo SDK. The required methods that must be overridden are specified in each section below.
mac.inference.Inference interface serves model inferences based on submitted input some input. Its purpose is to serve inferences for any supported arbitrary model framework (e.g. scikit, keras etc.).
classDiagram
class Inference {
<<Abstract>>
+model Optional[Any]
+expected_model_types()* Set
+predict(input_data: InferenceData)* InferenceData
-raise_error_if_model_is_not_assigned() None
-raise_error_if_model_is_wrong_type() None
}
mac.inference.creation.InferenceBuilder builds a concrete Inference, i.e. instantiates an Inference object, loads the appropriate model and assigns the model to to the Inference object.
classDiagram
class InferenceBuilder {
+create(config InferenceConfig) * Inference
-inference()* Any
}
mac.inference.Inference
mac.inference.Inference Objects
Object
Type
Description
model Optional[Any]
An optional list of models that match the supported frameworks from wallaroo.framework.Framework included in the arbitrary python script. Note that this is optional - no models are actually required. A BYOP can refer to a specific model(s) used, be used for data processing and reshaping for later pipeline steps, or other needs.
mac.inference.Inference Methods
Method
Returns
Description
expected_model_types (Required)
Set
Returns a Set of models expected for the inference as defined by the developer. Typically this is a set of one. Wallaroo checks the expected model types to verify that the model submitted through the InferenceBuilder method matches what this Inference class expects.
The entry point for the Wallaroo inference with the following input and output parameters that are defined when the model is updated.
mac.types.InferenceData: The inputInferenceData is a dictionary of numpy arrays derived from the input_schema detailed when the model is uploaded, defined in PyArrow.Schema format.
mac.types.InferenceData: The output is a dictionary of numpy arrays as defined by the output parameters defined in PyArrow.Schema format.
The InferenceDataValidationError exception is raised when the input data does not match mac.types.InferenceData.
raise_error_if_model_is_not_assigned
N/A
Error when expected_model_types is not set.
raise_error_if_model_is_wrong_type
N/A
Error when the model does not match the expected_model_types.
mac.inference.creation.InferenceBuilder
InferenceBuilder builds a concrete Inference, i.e. instantiates an Inference object, loads the appropriate model and assigns the model to the Inference.
classDiagram
class InferenceBuilder {
+create(config InferenceConfig) * Inference
-inference()* Any
}
Each model that is included requires its own InferenceBuilder. InferenceBuilder loads one model, then submits it to the Inference class when created. The Inference class checks this class against its expected_model_types() Set.
Creates an Inference subclass, then assigns a model and attributes. The CustomInferenceConfig is used to retrieve the config.model_path, which is a pathlib.Path object pointing to the folder where the model artifacts are saved. Every artifact loaded must be relative to config.model_path. This is set when the arbitrary python .zip file is uploaded and the environment for running it in Wallaroo is set. For example: loading the artifact vgg_clustering\feature_extractor.h5 would be set with config.model_path \ feature_extractor.h5. The model loaded must match an existing module. For our example, this is from sklearn.cluster import KMeans, and this must match the Inferenceexpected_model_types.
inference
custom Inference instance.
Returns the instantiated custom Inference object created from the create method.
Arbitrary Python Runtime
Arbitrary Python always run in the containerized model runtime.
Wallaroo users can register their trained MLFlow ML Models from a containerized model container registry into their Wallaroo instance and perform inferences with it through a Wallaroo pipeline.
As of this time, Wallaroo only supports MLFlow 1.30.0 containerized models. For information on how to containerize an MLFlow model, see the MLFlow Documentation.
The following steps create an Access Token used to authenticate to an Azure Databricks Model Registry.
Log into the Azure Databricks workspace.
From the upper right corner access the User Settings.
From the Access tokens, select Generate new token.
Specify any token description and lifetime. Once complete, select Generate.
Copy the token and store in a secure place. Once the Generate New Token module is closed, the token will not be retrievable.
The MLflow Model Registry provides a method of setting up a model registry service. Full details can be found at the MLflow Registry Quick Start Guide.
A generic MLFlow model registry requires no token.
Wallaroo Registry Operations
Connect Model Registry to Wallaroo: This details the link and connection information to a existing MLFlow registry service. Note that this does not create a MLFlow registry service, but adds the connection and credentials to Wallaroo to allow that MLFlow registry service to be used by other entities in the Wallaroo instance.
Add a Registry to a Workspace: Add the created Wallaroo Model Registry so make it available to other workspace members.
Remove a Registry from a Workspace: Remove the link between a Wallaroo Model Registry and a Wallaroo workspace.
Connect Model Registry to Wallaroo
MLFlow Registry connection information is added to a Wallaroo instance through the Wallaroo.Client.create_model_registry method.
Connect Model Registry to Wallaroo Parameters
Parameter
Type
Description
name
string (Required)
The name of the MLFlow Registry service.
token
string (Required)
The authentication token used to authenticate to the MLFlow Registry.
url
string (Required)
The URL of the MLFlow registry service.
Connect Model Registry to Wallaroo Return
The following is returned when a MLFlow Registry is successfully created.
Field
Type
Description
Name
string
The name of the MLFlow Registry service.
URL
string
The URL for connecting to the service.
Workspaces
List[string]
The name of all workspaces this registry was added to.
Created At
DateTime
When the registry was added to the Wallaroo instance.
Updated At
DateTime
When the registry was last updated.
Note that the token is not displayed for security reasons.
Connect Model Registry to Wallaroo Example
The following example creates a Wallaroo MLFlow Registry with the name ExampleNotebook stored in a sample Azure DataBricks environment.
Registries are assigned to a Wallaroo workspace with the Wallaroo.registry.add_registry_to_workspace method. This allows members of the workspace to access the registry connection. A registry can be associated with one or more workspaces.
Add Registry to Workspace Parameters
Parameter
Type
Description
name
string (Required)
The numerical identifier of the workspace.
Add Registry to Workspace Returns
The following is returned when a MLFlow Registry is successfully added to a workspace.
Field
Type
Description
Name
string
The name of the MLFlow Registry service.
URL
string
The URL for connecting to the service.
Workspaces
List[string]
The name of all workspaces this registry was added to.
Created At
DateTime
When the registry was added to the Wallaroo instance.
List Registries in a Workspace: List the available registries in the current workspace.
List Models: List Models in a Registry
Upload Model: Upload a version of a ML Model from the Registry to a Wallaroo workspace.
List Model Versions: List the versions of a particular model.
Remove Registry from Workspace: Remove a specific Registry configuration from a specific workspace.
List Registries in a Workspace
Registries associated with a workspace are listed with the Wallaroo.Client.list_model_registries() method. This lists all registries associated with the current workspace.
List Registries in a Workspace Parameters
None
List Registries in a Workspace Returns
A List of Registries with the following fields.
Field
Type
Description
Name
string
The name of the MLFlow Registry service.
URL
string
The URL for connecting to the service.
Created At
DateTime
When the registry was added to the Wallaroo instance.
Model details are retrieved by assigning a MLFlow Registry Model to an object with the Wallaroo.Registry.list_models(), then specifying the element in the list to save it to a Registered Model object.
The following will return the most recent model added to the MLFlow Registry service.
The user account that is tied to the registry service for this model.
Versions
int
The number of versions for the model, starting at 0.
Created At
DateTime
When the registry was added to the Wallaroo instance.
Updated At
DateTime
When the registry was last updated.
List Model Versions of Registered Model
MLFlow registries can contain multiple versions of a ML Model. These are listed and are listed with the Registered Model versions attribute. The versions are listed in reverse order of insertion, with the most recent model version in position 0.
List Model Versions of Registered Model Parameters
None
List Model Versions of Registered Model Returns
A List of the Registered Model Versions with the following fields.
Field
Type
Description
Name
string
The name of the model.
Version
int
The version number. The higher numbers are the most recent.
Description
string
The registered model’s description from the MLFlow Registry service.
List Model Versions of Registered Model Example
The following will return the most recent model added to the MLFlow Registry service and list its versions.
Models uploaded to the Wallaroo workspace are uploaded from a MLFlow Registry with the Wallaroo.Registry.upload method.
Upload a Model from a Registry Parameters
Parameter
Type
Description
name
string (Required)
The name to assign the model once uploaded. Model names are unique within a workspace. Models assigned the same name as an existing model will be uploaded as a new model version.
path
string (Required)
The full path to the model artifact in the registry.
Pipeline deployment configurations are dependent on whether the model is converted to the Native Runtime space, or Containerized Model Runtime space. This is determined when the model is uploaded based on the size, complexity, and other factors.
Once uploaded, the Model method config().runtime() will display which space the model is in.
The following configuration allocates 0.25 CPU and 1 Gi RAM to a specific containerized model in the containerized runtime, along with other environmental variables for the containerized model. Note that for containerized models, resources must be allocated per specific model.
2.4.5 - Wallaroo SDK Essentials Guide: Model Uploads and Registrations: Python Models
How to upload and use Python Models as Wallaroo Pipeline Steps
Model Naming Requirements
Model names map onto Kubernetes objects, and must be DNS compliant. The strings for model names must be ASCII alpha-numeric characters or dash (-) only. . and _ are not allowed.
Python scripts are uploaded to Wallaroo and and treated like an ML Models in Pipeline steps. These will be referred to as Python steps.
Python steps can include:
Preprocessing steps to prepare the data received to be handed to ML Model deployed as another Pipeline step.
Postprocessing steps to take data output by a ML Model as part of a Pipeline step, and prepare the data to be received by some other data store or entity.
A model contained within a Python script.
In all of these, the requirements for uploading a Python step as a ML Model in Wallaroo are the same.
Python models uploaded to Wallaroo are executed as a native runtime.
Note that Python models - aka “Python steps” - are standalone python scripts that use the python libraries natively supported by the Wallaroo platform. These are used for either simple model deployment (such as ARIMA Statsmodels), or data formatting such as the postprocessing steps. A Wallaroo Python model will be composed of one Python script that matches the Wallaroo requirements.
This is contrasted with Arbitrary Python models, also known as Bring Your Own Predict (BYOP) allow for custom model deployments with supporting scripts and artifacts. These are used with pre-trained models (PyTorch, Tensorflow, etc) along with whatever supporting artifacts they require. Supporting artifacts can include other Python modules, model files, etc. These are zipped with all scripts, artifacts, and a requirements.txt file that indicates what other Python models need to be imported that are outside of the typical Wallaroo platform.
Python Models Requirements
Python models uploaded to Wallaroo are Python scripts that must include the wallaroo_json method as the entry point for the Wallaroo engine to use it as a Pipeline step.
This method receives the results of the previous Pipeline step, and its return value will be used in the next Pipeline step.
If the Python model is the first step in the pipeline, then it will be receiving the inference request data (for example: a preprocessing step). If it is the last step in the pipeline, then it will be the data returned from the inference request.
In the example below, the Python model is used as a post processing step for another ML model. The Python model expects to receive data from a ML Model who’s output is a DataFrame with the column dense_2. It then extracts the values of that column as a list, selects the first element, and returns a DataFrame with that element as the value of the column output.
In line with other Wallaroo inference results, the outputs of a Python step that returns a pandas DataFrame or Arrow Table will be listed in the out. metadata, with all inference outputs listed as out.{variable 1}, out.{variable 2}, etc. In the example above, this results the output field as the out.output field in the Wallaroo inference result.
time
in.tensor
out.output
check_failures
0
2023-06-20 20:23:28.395
[0.6878518042, 0.1760734021, -0.869514083, 0.3..
[12.886651039123535]
0
Upload Python Models
Python step models are uploaded to Wallaroo through the Wallaroo Client upload_model(name, path, framework).configure(options).
Upload Python Model Parameters
Parameter
Type
Description
name
string (Required)
The name of the model. Model names are unique per workspace. Models that are uploaded with the same name are assigned as a new version of the model.
path
string (Required)
The path to the model file being uploaded.
framework
string (Required)
Set as the Framework.Python.
input_schema
pyarrow.lib.Schema (Optional)
The input schema in Apache Arrow schema format.
output_schema
pyarrow.lib.Schema (Optional)
The output schema in Apache Arrow schema format.
convert_wait
bool (Optional) (Default: True)
Not required for native runtimes.
True: Waits in the script for the model conversion completion.
False: Proceeds with the script without waiting for the model conversion process to display complete.
Upload Python Models Example
The following example is of uploading a Python step ML Model to a Wallaroo instance.
2.4.6 - Wallaroo SDK Essentials Guide: Model Uploads and Registrations: PyTorch
How to upload and use PyTorch ML Models with Wallaroo
Model Naming Requirements
Model names map onto Kubernetes objects, and must be DNS compliant. The strings for model names must be ASCII alpha-numeric characters or dash (-) only. . and _ are not allowed.
Wallaroo supports PyTorch models by containerizing the model and running as an image.
PyTorch models are uploaded to Wallaroo through the Wallaroo Client upload_model method.
Upload PyTorch Model Parameters
The following parameters are required for PyTorch models. Note that while some fields are considered as optional for the upload_model method, they are required for proper uploading of a PyTorch model to Wallaroo.
Parameter
Type
Description
name
string (Required)
The name of the model. Model names are unique per workspace. Models that are uploaded with the same name are assigned as a new version of the model.
path
string (Required)
The path to the model file being uploaded.
framework
string (Upload Method Optional, PyTorch model Required)
Set as the Framework.PyTorch.
input_schema
pyarrow.lib.Schema (Upload Method Optional, PyTorch model Required)
The input schema in Apache Arrow schema format.
output_schema
pyarrow.lib.Schema (Upload Method Optional, PyTorch model Required)
The output schema in Apache Arrow schema format.
convert_wait
bool (Upload Method Optional, PyTorch model Optional) (Default: True)
True: Waits in the script for the model conversion completion.
False: Proceeds with the script without waiting for the model conversion process to display complete.
Once the upload process starts, the model is containerized by the Wallaroo instance. This process may take up to 10 minutes.
Upload PyTorch Model Return
The following is returned with a successful model upload and conversion.
Field
Type
Description
name
string
The name of the model.
version
string
The model version as a unique UUID.
file_name
string
The file name of the model as stored in Wallaroo.
image_path
string
The image used to deploy the model in the Wallaroo engine.
last_update_time
DateTime
When the model was last updated.
Upload PyTorch Model Example
The following example is of uploading a PyTorch ML Model to a Wallaroo instance.
Pipeline deployment configurations are dependent on whether the model is converted to the Native Runtime space, or Containerized Model Runtime space. This is determined when the model is uploaded based on the size, complexity, and other factors.
Once uploaded, the Model method config().runtime() will display which space the model is in.
The following configuration allocates 0.25 CPU and 1 Gi RAM to a specific containerized model in the containerized runtime, along with other environmental variables for the containerized model. Note that for containerized models, resources must be allocated per specific model.
2.4.7 - Wallaroo SDK Essentials Guide: Model Uploads and Registrations: SKLearn
How to upload and use SKLearn ML Models with Wallaroo
Model Naming Requirements
Model names map onto Kubernetes objects, and must be DNS compliant. The strings for model names must be ASCII alpha-numeric characters or dash (-) only. . and _ are not allowed.
Wallaroo supports SKLearn models by containerizing the model and running as an image.
SKLearn schema follows a different format than other models. To prevent inputs from being out of order, the inputs should be submitted in a single row in the order the model is trained to accept, with all of the data types being the same. For example, the following DataFrame has 4 columns, each column a float.
sepal length (cm)
sepal width (cm)
petal length (cm)
petal width (cm)
0
5.1
3.5
1.4
0.2
1
4.9
3.0
1.4
0.2
For submission to an SKLearn model, the data input schema will be a single array with 4 float values.
When submitting as an inference, the DataFrame is converted to rows with the column data expressed as a single array. The data must be in the same order as the model expects, which is why the data is submitted as a single array rather than JSON labeled columns: this insures that the data is submitted in the exact order as the model is trained to accept.
Original DataFrame:
sepal length (cm)
sepal width (cm)
petal length (cm)
petal width (cm)
0
5.1
3.5
1.4
0.2
1
4.9
3.0
1.4
0.2
Converted DataFrame:
inputs
0
[5.1, 3.5, 1.4, 0.2]
1
[4.9, 3.0, 1.4, 0.2]
SKLearn Schema Outputs
Outputs for SKLearn that are meant to be predictions or probabilities when output by the model are labeled in the output schema for the model when uploaded to Wallaroo. For example, a model that outputs either 1 or 0 as its output would have the output schema as follows:
When used in Wallaroo, the inference result is contained in the out metadata as out.predictions.
pipeline.infer(dataframe)
time
in.inputs
out.predictions
check_failures
0
2023-07-05 15:11:29.776
[5.1, 3.5, 1.4, 0.2]
0
0
1
2023-07-05 15:11:29.776
[4.9, 3.0, 1.4, 0.2]
0
0
Uploading SKLearn Models
SKLearn models are uploaded to Wallaroo through the Wallaroo Client upload_model method.
Upload SKLearn Model Parameters
The following parameters are required for SKLearn models. Note that while some fields are considered as optional for the upload_model method, they are required for proper uploading of a SKLearn model to Wallaroo.
Parameter
Type
Description
name
string (Required)
The name of the model. Model names are unique per workspace. Models that are uploaded with the same name are assigned as a new version of the model.
path
string (Required)
The path to the model file being uploaded.
framework
string (Upload Method Optional, SKLearn model Required)
Set as the Framework.SKLEARN.
input_schema
pyarrow.lib.Schema (Upload Method Optional, SKLearn model Required)
The input schema in Apache Arrow schema format.
output_schema
pyarrow.lib.Schema (Upload Method Optional, SKLearn model Required)
The output schema in Apache Arrow schema format.
convert_wait
bool (Upload Method Optional, SKLearn model Optional) (Default: True)
True: Waits in the script for the model conversion completion.
False: Proceeds with the script without waiting for the model conversion process to display complete.
Once the upload process starts, the model is containerized by the Wallaroo instance. This process may take up to 10 minutes.
Upload SKLearn Model Return
The following is returned with a successful model upload and conversion.
Field
Type
Description
name
string
The name of the model.
version
string
The model version as a unique UUID.
file_name
string
The file name of the model as stored in Wallaroo.
image_path
string
The image used to deploy the model in the Wallaroo engine.
last_update_time
DateTime
When the model was last updated.
Upload SKLearn Model Example
The following example is of uploading a pickled SKLearn ML Model to a Wallaroo instance.
Pipeline deployment configurations are dependent on whether the model is converted to the Native Runtime space, or Containerized Model Runtime space. This is determined when the model is uploaded based on the size, complexity, and other factors.
Once uploaded, the Model method config().runtime() will display which space the model is in.
The following configuration allocates 0.25 CPU and 1 Gi RAM to a specific containerized model in the containerized runtime, along with other environmental variables for the containerized model. Note that for containerized models, resources must be allocated per specific model.
2.4.8 - Wallaroo SDK Essentials Guide: Model Uploads and Registrations: Hugging Face
How to upload and use Hugging Face ML Models with Wallaroo
Model Naming Requirements
Model names map onto Kubernetes objects, and must be DNS compliant. The strings for model names must be ASCII alpha-numeric characters or dash (-) only. . and _ are not allowed.
Wallaroo supports Hugging Face models by containerizing the model and running as an image.
Input and output schemas for each Hugging Face pipeline are defined below. Note that adding additional inputs not specified below will raise errors, except for the following:
Framework.HUGGING-FACE-IMAGE-TO-TEXT
Framework.HUGGING-FACE-TEXT-CLASSIFICATION
Framework.HUGGING-FACE-SUMMARIZATION
Framework.HUGGING-FACE-TRANSLATION
Additional inputs added to these Hugging Face pipelines will be added as key/pair value arguments to the model’s generate method. If the argument is not required, then the model will default to the values coded in the original Hugging Face model’s source code.
Any parameter that is not part of the required inputs list will be forwarded to the model as a key/pair value to the underlying models generate method. If the additional input is not supported by the model, an error will be returned.
Any parameter that is not part of the required inputs list will be forwarded to the model as a key/pair value to the underlying models generate method. If the additional input is not supported by the model, an error will be returned.
Schemas:
input_schema=pa.schema([
pa.field('inputs', pa.string()),
pa.field('return_text', pa.bool_()),
pa.field('return_tensors', pa.bool_()),
pa.field('clean_up_tokenization_spaces', pa.bool_()),
# pa.field('extra_field', pa.int64()), # every extra field you specify will be forwarded as a key/value pair])
output_schema=pa.schema([
pa.field('summary_text', pa.string()),
])
input_schema=pa.schema([
pa.field('inputs', pa.string()), # requiredpa.field('top_k', pa.int64()), # optionalpa.field('function_to_apply', pa.string()), # optional])
output_schema=pa.schema([
pa.field('label', pa.list_(pa.string(), list_size=2)), # list with a number of items same as top_k, list_size can be skipped but may lead in worse performancepa.field('score', pa.list_(pa.float64(), list_size=2)), # list with a number of items same as top_k, list_size can be skipped but may lead in worse performance])
Any parameter that is not part of the required inputs list will be forwarded to the model as a key/pair value to the underlying models generate method. If the additional input is not supported by the model, an error will be returned.
Schemas:
input_schema=pa.schema([
pa.field('inputs', pa.string()), # requiredpa.field('return_tensors', pa.bool_()), # optionalpa.field('return_text', pa.bool_()), # optionalpa.field('clean_up_tokenization_spaces', pa.bool_()), # optionalpa.field('src_lang', pa.string()), # optionalpa.field('tgt_lang', pa.string()), # optional# pa.field('extra_field', pa.int64()), # every extra field you specify will be forwarded as a key/value pair])
output_schema=pa.schema([
pa.field('translation_text', pa.string()),
])
input_schema=pa.schema([
pa.field('inputs', pa.string()), # requiredpa.field('candidate_labels', pa.list_(pa.string(), list_size=2)), # requiredpa.field('hypothesis_template', pa.string()), # optionalpa.field('multi_label', pa.bool_()), # optional])
output_schema=pa.schema([
pa.field('sequence', pa.string()),
pa.field('scores', pa.list_(pa.float64(), list_size=2)), # same as number of candidate labels, list_size can be skipped by may result in slightly worse performancepa.field('labels', pa.list_(pa.string(), list_size=2)), # same as number of candidate labels, list_size can be skipped by may result in slightly worse performance])
input_schema=pa.schema([
pa.field('images',
pa.list_(
pa.list_(
pa.list_(
pa.int64(),
list_size=3 ),
list_size=640 ),
list_size=480 )),
pa.field('candidate_labels', pa.list_(pa.string(), list_size=3)),
pa.field('threshold', pa.float64()),
# pa.field('top_k', pa.int64()), # we want the model to return exactly the number of predictions, we shouldn't specify this])
output_schema=pa.schema([
pa.field('score', pa.list_(pa.float64())), # variable output, depending on detected objectspa.field('label', pa.list_(pa.string())), # variable output, depending on detected objectspa.field('box',
pa.list_( # dynamic output, i.e. dynamic number of boxes per input image, each sublist contains the 4 box coordinates pa.list_(
pa.int64(),
list_size=4 ),
),
),
])
Any parameter that is not part of the required inputs list will be forwarded to the model as a key/pair value to the underlying models generate method. If the additional input is not supported by the model, an error will be returned.
input_schema=pa.schema([
pa.field('inputs', pa.string()),
pa.field('return_tensors', pa.bool_()), # optionalpa.field('return_text', pa.bool_()), # optionalpa.field('return_full_text', pa.bool_()), # optionalpa.field('clean_up_tokenization_spaces', pa.bool_()), # optionalpa.field('prefix', pa.string()), # optionalpa.field('handle_long_generation', pa.string()), # optional# pa.field('extra_field', pa.int64()), # every extra field you specify will be forwarded as a key/value pair])
output_schema=pa.schema([
pa.field('generated_text', pa.list_(pa.string(), list_size=1))
])
Uploading Hugging Face Models
Hugging Face models are uploaded to Wallaroo through the Wallaroo Client upload_model method.
Upload Hugging Face Model Parameters
The following parameters are required for Hugging Face models. Note that while some fields are considered as optional for the upload_model method, they are required for proper uploading of a Hugging Face model to Wallaroo.
Parameter
Type
Description
name
string (Required)
The name of the model. Model names are unique per workspace. Models that are uploaded with the same name are assigned as a new version of the model.
path
string (Required)
The path to the model file being uploaded.
framework
string (Upload Method Optional, Hugging Face model Required)
Set as the framework - see the list above for all supported Hugging Face frameworks.
input_schema
pyarrow.lib.Schema (Upload Method Optional, Hugging Face model Required)
The input schema in Apache Arrow schema format.
output_schema
pyarrow.lib.Schema (Upload Method Optional, Hugging Face model Required)
The output schema in Apache Arrow schema format.
convert_wait
bool (Upload Method Optional, Hugging Face model Optional) (Default: True)
True: Waits in the script for the model conversion completion.
False: Proceeds with the script without waiting for the model conversion process to display complete.
Once the upload process starts, the model is containerized by the Wallaroo instance. This process may take up to 10 minutes.
Upload Hugging Face Model Return
The following is returned with a successful model upload and conversion.
Field
Type
Description
name
string
The name of the model.
version
string
The model version as a unique UUID.
file_name
string
The file name of the model as stored in Wallaroo.
image_path
string
The image used to deploy the model in the Wallaroo engine.
last_update_time
DateTime
When the model was last updated.
Upload Hugging Face Model Example
The following example is of uploading a Hugging Face Zero Shot Classification ML Model to a Wallaroo instance.
input_schema=pa.schema([
pa.field('inputs', pa.string()), # requiredpa.field('candidate_labels', pa.list_(pa.string(), list_size=2)), # requiredpa.field('hypothesis_template', pa.string()), # optionalpa.field('multi_label', pa.bool_()), # optional])
output_schema=pa.schema([
pa.field('sequence', pa.string()),
pa.field('scores', pa.list_(pa.float64(), list_size=2)), # same as number of candidate labels, list_size can be skipped by may result in slightly worse performancepa.field('labels', pa.list_(pa.string(), list_size=2)), # same as number of candidate labels, list_size can be skipped by may result in slightly worse performance])
model=wl.upload_model(f"hugging-face-zero-model",
'./models/model-auto-conversion_hugging-face_dummy-pipelines_zero-shot-classification-pipeline.zip',
framework=Framework.HUGGING_FACE_ZERO_SHOT_CLASSIFICATION,
input_schema=input_schema,
output_schema=output_schema)
Pipeline Deployment Configurations
Pipeline deployment configurations are dependent on whether the model is converted to the Native Runtime space, or Containerized Model Runtime space. This is determined when the model is uploaded based on the size, complexity, and other factors.
Once uploaded, the Model method config().runtime() will display which space the model is in.
The following configuration allocates 0.25 CPU and 1 Gi RAM to a specific containerized model in the containerized runtime, along with other environmental variables for the containerized model. Note that for containerized models, resources must be allocated per specific model.
2.4.9 - Wallaroo SDK Essentials Guide: Model Uploads and Registrations: TensorFlow
How to upload and use TensorFlow ML Models with Wallaroo
Model Naming Requirements
Model names map onto Kubernetes objects, and must be DNS compliant. The strings for model names must be ASCII alpha-numeric characters or dash (-) only. . and _ are not allowed.
Wallaroo supports TensorFlow models by containerizing the model and running as an image.
These requirements are not for Tensorflow Keras models, only for non-Keras Tensorflow models in the SavedModel format. For Tensorflow Keras deployment in Wallaroo, see the Tensorflow Keras requirements.
TensorFlow File Format
TensorFlow models are .zip file of the SavedModel format. For example, the Aloha sample TensorFlow model is stored in the directory alohacnnlstm:
TensorFlow models are uploaded to Wallaroo through the Wallaroo Client upload_model method.
Upload TensorFlow Model Parameters
The following parameters are required for TensorFlow models. Tensorflow models are native runtimes in Wallaroo, so the input_schema and output_schema parameters are optional.
Parameter
Type
Description
name
string (Required)
The name of the model. Model names are unique per workspace. Models that are uploaded with the same name are assigned as a new version of the model.
path
string (Required)
The path to the model file being uploaded.
framework
string (Required)
Set as the Framework.TENSORFLOW.
input_schema
pyarrow.lib.Schema (Optional)
The input schema in Apache Arrow schema format.
output_schema
pyarrow.lib.Schema (Optional)
The output schema in Apache Arrow schema format.
convert_wait
bool (Optional) (Default: True)
Not required for native runtimes.
True: Waits in the script for the model conversion completion.
False: Proceeds with the script without waiting for the model conversion process to display complete.
Once the upload process starts, the model is containerized by the Wallaroo instance. This process may take up to 10 minutes.
Upload TensorFlow Model Return
For example, the following example is of uploading a TensorFlow ML Model to a Wallaroo instance.
2.4.10 - Wallaroo SDK Essentials Guide: Model Uploads and Registrations: TensorFlow Keras
How to upload and use TensorFlow Keras ML Models with Wallaroo
Model Naming Requirements
Model names map onto Kubernetes objects, and must be DNS compliant. The strings for model names must be ASCII alpha-numeric characters or dash (-) only. . and _ are not allowed.
Wallaroo supports TensorFlow/Keras models by containerizing the model and running as an image.
TensorFlow Keras SavedModel models are .zip file of the SavedModel format. For example, the Aloha sample TensorFlow model is stored in the directory alohacnnlstm:
Wallaroo supports the H5 for Tensorflow Keras models.
Uploading TensorFlow Models
TensorFlow Keras models are uploaded to Wallaroo through the Wallaroo Client upload_model method.
Upload TensorFlow Model Parameters
The following parameters are required for TensorFlow keras models. Note that while some fields are considered as optional for the upload_model method, they are required for proper uploading of a TensorFlow Keras model to Wallaroo.
Parameter
Type
Description
name
string (Required)
The name of the model. Model names are unique per workspace. Models that are uploaded with the same name are assigned as a new version of the model.
path
string (Required)
The path to the model file being uploaded.
framework
string (Upload Method Optional, TensorFlow keras model Required)
Set as the Framework.KERAS.
input_schema
pyarrow.lib.Schema (Upload Method Optional, TensorFlow Keras model Required)
The input schema in Apache Arrow schema format.
output_schema
pyarrow.lib.Schema (Upload Method Optional, TensorFlow Keras model Required)
The output schema in Apache Arrow schema format.
convert_wait
bool (Upload Method Optional, TensorFlow model Optional) (Default: True)
True: Waits in the script for the model conversion completion.
False: Proceeds with the script without waiting for the model conversion process to display complete.
Once the upload process starts, the model is containerized by the Wallaroo instance. This process may take up to 10 minutes.
Upload TensorFlow Model Return
For example, the following example is of uploading a PyTorch ML Model to a Wallaroo instance.
Pipeline deployment configurations are dependent on whether the model is converted to the Native Runtime space, or Containerized Model Runtime space. This is determined when the model is uploaded based on the size, complexity, and other factors.
Once uploaded, the Model method config().runtime() will display which space the model is in.
The following configuration allocates 0.25 CPU and 1 Gi RAM to a specific containerized model in the containerized runtime, along with other environmental variables for the containerized model. Note that for containerized models, resources must be allocated per specific model.
2.4.11 - Wallaroo SDK Essentials Guide: Model Uploads and Registrations: XGBoost
How to upload and use XGBoost ML Models with Wallaroo
Model Naming Requirements
Model names map onto Kubernetes objects, and must be DNS compliant. The strings for model names must be ASCII alpha-numeric characters or dash (-) only. . and _ are not allowed.
Wallaroo supports XGBoost models by containerizing the model and running as an image.
XGBoost schema follows a different format than other models. To prevent inputs from being out of order, the inputs should be submitted in a single row in the order the model is trained to accept, with all of the data types being the same. If a model is originally trained to accept inputs of different data types, it will need to be retrained to only accept one data type for each column - typically pa.float64() is a good choice.
For example, the following DataFrame has 4 columns, each column a float.
sepal length (cm)
sepal width (cm)
petal length (cm)
petal width (cm)
0
5.1
3.5
1.4
0.2
1
4.9
3.0
1.4
0.2
For submission to an XGBoost model, the data input schema will be a single array with 4 float values.
When submitting as an inference, the DataFrame is converted to rows with the column data expressed as a single array. The data must be in the same order as the model expects, which is why the data is submitted as a single array rather than JSON labeled columns: this insures that the data is submitted in the exact order as the model is trained to accept.
Original DataFrame:
sepal length (cm)
sepal width (cm)
petal length (cm)
petal width (cm)
0
5.1
3.5
1.4
0.2
1
4.9
3.0
1.4
0.2
Converted DataFrame:
inputs
0
[5.1, 3.5, 1.4, 0.2]
1
[4.9, 3.0, 1.4, 0.2]
XGBoost Schema Outputs
Outputs for XGBoost are labeled based on the trained model outputs. For this example, the output is simply a single output listed as output. In the Wallaroo inference result, it is grouped with the metadata out as out.output.
XGBoost models are uploaded to Wallaroo through the Wallaroo Client upload_model method.
Upload XGBoost Model Parameters
The following parameters are required for XGBoost models. Note that while some fields are considered as optional for the upload_model method, they are required for proper uploading of a XGBoost model to Wallaroo.
Parameter
Type
Description
name
string (Required)
The name of the model. Model names are unique per workspace. Models that are uploaded with the same name are assigned as a new version of the model.
path
string (Required)
The path to the model file being uploaded.
framework
string (Upload Method Optional, SKLearn model Required)
Set as the Framework.XGBOOST.
input_schema
pyarrow.lib.Schema (Upload Method Optional, SKLearn model Required)
The input schema in Apache Arrow schema format.
output_schema
pyarrow.lib.Schema (Upload Method Optional, SKLearn model Required)
The output schema in Apache Arrow schema format.
convert_wait
bool (Upload Method Optional, SKLearn model Optional) (Default: True)
True: Waits in the script for the model conversion completion.
False: Proceeds with the script without waiting for the model conversion process to display complete.
Once the upload process starts, the model is containerized by the Wallaroo instance. This process may take up to 10 minutes.
Upload XGBoost Model Return
The following is returned with a successful model upload and conversion.
Field
Type
Description
name
string
The name of the model.
version
string
The model version as a unique UUID.
file_name
string
The file name of the model as stored in Wallaroo.
image_path
string
The image used to deploy the model in the Wallaroo engine.
last_update_time
DateTime
When the model was last updated.
Upload XGBoost Model Example
The following example is of uploading a PyTorch ML Model to a Wallaroo instance.
Pipeline deployment configurations are dependent on whether the model is converted to the Native Runtime space, or Containerized Model Runtime space. This is determined when the model is uploaded based on the size, complexity, and other factors.
Once uploaded, the Model method config().runtime() will display which space the model is in.
The following configuration allocates 0.25 CPU and 1 Gi RAM to a specific containerized model in the containerized runtime, along with other environmental variables for the containerized model. Note that for containerized models, resources must be allocated per specific model.
The get_user_by_email({email}) command finds the user who’s email address matches the submitted {email} field. If no email address matches then the return will be null.
For example, the user steve with the email address steve@ex.co returns the following:
To remove a user’s access to the Wallaroo instance, use the Wallaroo Client deactivate_user("{User Email Address}) method, replacing the {User Email Address} with the email address of the user to deactivate.
To activate a user, use the Wallaroo Client active_user("{User Email Address}) method, replacing the {User Email Address} with the email address of the user to activate.
This feature impacts Wallaroo Community’s license count. Wallaroo Community only allows a total of 5 users per Wallaroo Community instance. Deactivated users does not count to this total - this allows organizations to add users, then activate/deactivate them as needed to stay under the total number of licensed users count.
Wallaroo Enterprise has no limits on the number of users who can be added or active in a Wallaroo instance.
In this example, the user testuser@wallaroo.ai will be deactivated then reactivated.
When a new user logs in for the first time, they get an error when uploading a model or issues when they attempt to log in. How do I correct that?
When a new registered user attempts to upload a model, they may see the following error:
TransportQueryError:
{'extensions':
{'path':
'$.selectionSet.insert_workspace_one.args.object[0]', 'code': 'not-supported' },
'message':
'cannot proceed to insert array relations since insert to table "workspace" affects zero rows'
Or if they log into the Wallaroo Dashboard, they may see a Page not found error.
This is caused when a user has been registered without an appropriate email address. See the user guides here on inviting a user, or the Wallaroo Enterprise User Management on how to log into the Keycloak service and update users. Verify that the username and email address are both the same, and they are valid confirmed email addresses for the user.
2.6 - Wallaroo SDK Essentials Guide: Pipelines
The classes and methods for managing Wallaroo pipelines and configurations.
How to create and manage Wallaroo Pipelines through the Wallaroo SDK
Pipelines are the method of taking submitting data and processing that data through the models. Each pipeline can have one or more steps that submit the data from the previous step to the next one. Information can be submitted to a pipeline as a file, or through the pipeline’s URL.
Pipeline names map onto Kubernetes objects, and must be DNS compliant. Pipeline names must be ASCII alpha-numeric characters or dash (-) only. . and _ are not allowed.
Create a Pipeline
New pipelines are created in the current workspace.
NOTICE
Pipeline names are not forced to be unique. You can have 50 pipelines all named my-pipeline, which can cause confusion in determining which workspace to use.
It is recommended that organizations agree on a naming convention and select pipeline to use rather than creating a new one each time.
To create a new pipeline, use the Wallaroo Client build_pipeline("{Pipeline Name}") command.
The following example creates a new pipeline imdb-pipeline through a Wallaroo Client connection wl:
imdb_pipeline=wl.build_pipeline("imdb-pipeline")
imdb_pipeline.status()
{'status': 'Pipeline imdb-pipeline is not deployed'}
List All Pipelines
The Wallaroo Client method list_pipelines() lists all pipelines in a Wallaroo Instance.
The following example lists all pipelines in the wl Wallaroo Client connection:
Rather than creating a new pipeline each time, an existing pipeline can be selected by using the list_pipelines() command and assigning one of the array members to a variable.
The following example sets the pipeline ccfraud-pipeline to the variable current_pipeline:
Once a pipeline has been created, or during its creation process, a pipeline step can be added. The pipeline step refers to the model that will perform an inference off of the data submitted to it. Each time a step is added, it is added to the pipeline’s models array.
Pipeline steps are not saved until the pipeline is deployed. Until then, pipeline steps are stored in local memory as a potential pipeline configuration until the pipeline is deployed.
Add a Step to a Pipeline
A pipeline step is added through the pipeline add_model_step({Model}) command.
In the following example, two models uploaded to the workspace are added as pipeline step:
Pipeline steps can be replaced while a pipeline is deployed. This allows organizations to have pipelines deployed in a production environment and hot-swap out models for new versions without impacting performance or inferencing downtime.
The following parameters are used for replacing a pipeline step:
Parameter
Default Value
Purpose
index
null
The pipeline step to be replaced. Pipeline steps follow array numbering, where the first step is 0, etc.
model
null
The new model to be used in the pipeline step.
In the following example, a deployed pipeline will have the initial model step replaced with a new one. A status of the pipeline will be displayed after deployment and after the pipeline swap to show the model has been replaced from ccfraudoriginal to ccfraudreplacement, each with their own versions.
A Pipeline Step can be more than models - they can also be pre processing and post processing steps. For example, the Demand Curve Tutorial has both a pre and post processing steps that are added to the pipeline. The preprocessing step uses the following code:
importnumpyimportpandasimportjson# add interaction terms for the modeldefactual_preprocess(pdata):
pd=pdata.copy()
# convert boolean cust_known to 0/1pd.cust_known=numpy.where(pd.cust_known, 1, 0)
# interact UnitPrice and cust_knownpd['UnitPriceXcust_known'] =pd.UnitPrice*pd.cust_knownreturnpd.loc[:, ['UnitPrice', 'cust_known', 'UnitPriceXcust_known']]
# If the data is a json string, call this wrapper instead# Expected input:# a dictionary with fields 'colnames', 'data'# test that the code works heredefwallaroo_json(data):
obj=json.loads(data)
pdata=pandas.DataFrame(obj['query'],
columns=obj['colnames'])
pprocessed=actual_preprocess(pdata)
# return a dictionary, with the fields the model expectreturn {
'tensor_fields': ['model_input'],
'model_input': pprocessed.to_numpy().tolist()
}
It is added as a Python module by uploading it as a model:
# load the preprocess modulemodule_pre=wl.upload_model("preprocess", "./preprocess.py").configure('python')
And then added to the pipeline as a step:
# now make a pipelinedemandcurve_pipeline= (wl.build_pipeline("demand-curve-pipeline")
.add_model_step(module_pre)
.add_model_step(demand_curve_model)
.add_model_step(module_post))
Remove a Pipeline Step
To remove a step from the pipeline, use the Pipeline remove_step(index) command, where the index is the array index for the pipeline’s steps.
In the following example the pipeline imdb_pipeline will have the step with the model smodel-o removed.
When a pipeline step is added or removed, the pipeline must be deployed through the pipeline deploy(). This allocates resources to the pipeline from the Kubernetes environment and make it available to submit information to perform inferences. This process typically takes 45 seconds.
Once complete, the pipeline status() command will show 'status':'Running'.
Pipeline deployments can be modified to enable auto-scaling to allow pipelines to allocate more or fewer resources based on need by setting the pipeline’s This will then be applied to the deployment of the pipelineccfraudPipelineby specifying it'sdeployment_config` optional parameter. If this optional parameter is not passed, then the deployment will defer to default values. For more information, see Manage Pipeline Deployment Configuration.
In the following example, the pipeline imdb-pipeline that contains two steps will be deployed with default deployment configuration:
If you deploy more pipelines than your environment can handle, or if you deploy more pipelines than your license allows, you may see an error like the following:
When a pipeline is not currently needed, it can be undeployed and its resources turned back to the Kubernetes environment. To undeploy a pipeline, use the pipeline undeploy() command.
In this example, the aloha_pipeline will be undeployed:
Anomaly detection allows organizations to set validation parameters. A validation is added to a pipeline to test data based on a specific expression. If the expression is returned as False, this is detected as an anomaly and added to the InferenceResult object’s check_failures array and the pipeline logs.
Anomaly detection consists of the following steps:
Set a validation: Add a validation to a pipeline that, when returned False, adds an entry to the InferenceResult object’s check_failures attribute with the expression that caused the failure.
Display anomalies: Anomalies detected through a Pipeline’s validation attribute are displayed either through the InferenceResult object’s check_failures attribute, or through the pipeline’s logs.
Set A Validation
Validations are added to a pipeline through the wallaroo.pipelineadd_validation method. The following parameters are required:
The validation expression that adds the result InferenceResult object’s check_failures attribute when expression result is False. The validation checks the expression against both the data value and the data type.
Validation expressions take the format value Expression, with the expression being in the form of a :py:Expression:. For example, if the model housing_model is part of the pipeline steps, then a validation expression may be housing_model.outputs[0][0] < 100.0: If the output of the housing_model inference is less than 100, then the validation is True and no action is taken. Any values over 100, the validation is False which triggers adding the anomaly to the InferenceResult object’s check_failures attribute.
IMPORTANT NOTE
Validations test for the expression value and the data type. For example: 100 is considered an integer data type, while 100.0 is considered a float data type.
If the data type is an integer, and the value the expression is testing against is a float, then the validation check will always be triggered. Verify that the data type is properly set in the validation expression to ensure correct validation check results.
Note that multiple validations can be created to allow for multiple anomalies detection.
In the following example, a validation is added to the pipeline to detect housing prices that are below 100 (represented as $100 million), and trigger an anomaly for values above that level. When an inference is performed that triggers a validation failure, the results are displayed in the InferenceResult object’s check_failures attribute.
Anomalies detected through a Pipeline’s validation attribute are displayed either through the InferenceResult object’s check_failures attribute, or through the pipeline’s logs.
To display an anomaly through the InferenceResult object, display the check_failures attribute.
In the following example, the an InferenceResult where the validation failed will display the failure in the check_failures attribute:
A/B testing is a method that provides the ability to test competing ML models for performance, accuracy or other useful benchmarks. Different models are added to the same pipeline steps as follows:
Control or Champion model: The model currently used for inferences.
Challenger model(s): The model or set of models compared to the challenger model.
A/B testing splits a portion of the inference requests between the champion model and the one or more challengers through the add_random_split method. This method splits the inferences submitted to the model through a randomly weighted step.
Each model receives inputs that are approximately proportional to the weight it is assigned. For example, with two models having weights 1 and 1, each will receive roughly equal amounts of inference inputs. If the weights were changed to 1 and 2, the models would receive roughly 33% and 66% respectively instead.
When choosing the model to use, a random number between 0.0 and 1.0 is generated. The weighted inputs are mapped to that range, and the random input is then used to select the model to use. For example, for the two-models equal-weight case, a random key of 0.4 would route to the first model, 0.6 would route to the second.
Add Random Split
A random split step can be added to a pipeline through the add_random_split method.
The following parameters are used when adding a random split step to a pipeline:
Parameter
Type
Description
champion_weight
Float (Required)
The weight for the champion model.
champion_model
Wallaroo.Model (Required)
The uploaded champion model.
challenger_weight
Float (Required)
The weight of the challenger model.
challenger_model
Wallaroo.Model (Required)
The uploaded challenger model.
hash_key
String(Optional)
A key used instead of a random number for model selection. This must be between 0.0 and 1.0.
Note that multiple challenger models with different weights can be added as the random split step.
If a pipeline already had steps as detailed in Add a Step to a Pipeline, this step can be replaced with a random split with the replace_with_random_split method.
The following parameters are used when adding a random split step to a pipeline:
Parameter
Type
Description
index
Integer (Required)
The pipeline step being replaced.
champion_weight
Float (Required)
The weight for the champion model.
champion_model
Wallaroo.Model (Required)
The uploaded champion model.
**challenger_weight
Float (Required)
The weight of the challenger model.
challenger_model
Wallaroo.Model (Required)
The uploaded challenger model.
hash_key
String(Optional)
A key used instead of a random number for model selection. This must be between 0.0 and 1.0.
Note that one or more challenger models can be added for the random split step:
Wallaroo provides a method of testing the same data against two different models or sets of models at the same time through shadow deployments otherwise known as parallel deployments or A/B test. This allows data to be submitted to a pipeline with inferences running on several different sets of models. Typically this is performed on a model that is known to provide accurate results - the champion - and a model or set of models that is being tested to see if it provides more accurate or faster responses depending on the criteria known as the challenger(s). Multiple challengers can be tested against a single champion to determine which is “better” based on the organization’s criteria.
In data science, A/B tests can also be used to choose between two models in production, by measuring which model performs better in the real world. In this formulation, the control is often an existing model that is currently in production, sometimes called the champion. The treatment is a new model being considered to replace the old one. This new model is sometimes called the challenger…. Keep in mind that in machine learning, the terms experiments and trials also often refer to the process of finding a training configuration that works best for the problem at hand (this is sometimes called hyperparameter optimization).
When a shadow deployment is created, only the inference from the champion is returned in the InferenceResult Object data, while the result data for the shadow deployments is stored in the InferenceResult Object shadow_data.
Create Shadow Deployment
Create a parallel or shadow deployment for a pipeline with the pipeline.add_shadow_deploy(champion, challengers[]) method, where the champion is a Wallaroo Model object, and challengers[] is one or more Wallaroo Model objects.
Each inference request sent to the pipeline is sent to all the models. The prediction from the champion is returned by the pipeline, while the predictions from the challengers are not part of the standard output, but are kept stored in the shadow_data attribute and in the logs for later comparison.
In this example, a shadow deployment is created with the champion versus two challenger models.
Model outputs are listed by column based on the model’s outputs. The output data is set by the term out, followed by the name of the model. For the default model, this is out.{variable_name}, while the shadow deployed models are in the format out_{model name}.variable, where {model name} is the name of the shadow deployed model.
Shadow deploy results are part of the Pipeline.logs() method. The output data is set by the term out, followed by the name of the model. For the default model, this is out.dense_1, while the shadow deployed models are in the format out_{model name}.variable, where {model name} is the name of the shadow deployed model.
The Pipeline URL Endpoint or the Pipeline Deploy URL is used to submit data to a pipeline to use for an inference. This is done through the pipeline _deployment._url() method.
In this example, the pipeline URL endpoint for the pipeline ccfraud_pipeline will be displayed:
Pipeline deployments configurations allow tailoring of a pipeline’s resources to match an organization’s and model’s requirements. Pipelines may require more memory, CPU cores, or GPUs to run to run all its steps efficiently. Pipeline deployment configurations also allow for multiple replicas of a model in a pipeline to provide scalability.
Create Pipeline Configuration
Setting a pipeline deployment configuration follows this process:
Pipeline deployment configurations are created through the wallaroo ‘deployment_config.DeploymentConfigBuilder()](https://docs.wallaroo.ai/20230201/wallaroo-developer-guides/wallaroo-sdk-guides/wallaroo-sdk-reference-guide/deployment_config/#DeploymentConfigBuilder) class.
Once the configuration options are set the pipeline deployment configuration is set with the deployment_config.build() method.
The pipeline deployment configuration is then applied when the pipeline is deployed.
The following example shows a pipeline deployment configuration with 1 replica, 1 cpu, and 2Gi of memory set to be allocated to the pipeline.
Pipeline resources can be configured with autoscaling. Autoscaling allows the user to define how many engines a pipeline starts with, the minimum amount of engines a pipeline uses, and the maximum amount of engines a pipeline can scale to. The pipeline scales up and down based on the average CPU utilization across the engines in a given pipeline as the user’s workload increases and decreases.
Pipeline Resource Configurations
Pipeline deployment configurations deal with two major components:
Native Runtimes: Models that are deployed “as is” with the Wallaroo engine (Onnx, etc).
Containerized Runtimes: Models that are packaged into a container then deployed as a container with the Wallaroo engine (MLFlow, etc).
These configurations can be mixed - both native runtimes and containerized runtimes deployed to the same pipeline, with resources allocated to each runtimes in different configurations.
CPUs are allocated in fractions of total CPU power similar to the Kubernetes CPU definitions. cpus(0.25), cpus(1.0), etc are valid values.
GPUs can only be allocated by entire integer units from the GPU enabled nodepools. gpus(1), gpus(2), etc are valid values, while gpus(0.25) are not.
Organizations should be aware of how many GPUs are allocated to the cluster. If all GPUs are already allocated to other pipelines, or if there are not enough GPUs to fulfill the request, the pipeline deployment will fail and return an error message.
GPU Support
Wallaroo 2023.2.1 and above supports Kubernetes nodepools with Nvidia Cuda GPUs.
If allocating GPUs to a Wallaroo pipeline, the deployment_label configuration option must be used.
Native Runtime Configuration Methods
Method
Parameters
Description
Enterprise Only Feature
replica_count
(count: int)
The number of replicas of the pipeline to deploy. This allows for multiple deployments of the same models to be deployed to increase inferences through parallelization.
√
replica_autoscale_min_max
(maximum: int, minimum: int = 0)
Provides replicas to be scaled from 0 to some maximum number of replicas. This allows pipelines to spin up additional replicas as more resources are required, then spin them back down to save on resources and costs.
√
autoscale_cpu_utilization
(cpu_utilization_percentage: int)
Sets the average CPU percentage metric for when to load or unload another replica.
√
disable_autoscale
Disables autoscaling in the deployment configuration.
cpus
(core_count: float)
Sets the number or fraction of CPUs to use for the pipeline, for example: 0.25, 1, 1.5, etc. The units are similar to the Kubernetes CPU definitions.
gpus
(core_count: int)
Sets the number of GPUs to allocate for native runtimes. GPUs are only allocated in whole units, not as fractions. Organizations should be aware of the total number of GPUs available to the cluster, and monitor which pipeline deployment configurations have gpus allocated to ensure they do not run out. If there are not enough gpus to allocate to a pipeline deployment configuration, and error message will be deployed when the pipeline is deployed. If gpus is called, then the deployment_label must be called and match the GPU Nodepool for the Wallaroo Cluster hosting the Wallaroo instance.
√
memory
memory_spec: str
Sets the amount of RAM to allocate the pipeline. The memory_spec string is in the format “{size as number}{unit value}”. The accepted unit values are:
Sets the number or fraction of CPUs to use for the pipeline’s load balancer, for example: 0.25, 1, 1.5, etc. The units, similar to the Kubernetes CPU definitions.
lb_memory
memory_spec: str
Sets the amount of RAM to allocate the pipeline’s load balancer. The memory_spec string is in the format “{size as number}{unit value}”. The accepted unit values are:
Label used for Kubernetes labels. Required if gpus are set and must match the GPU nodepool label.
√
Containerized Runtime Configuration Methods
Method
Parameters
Description
Enterprise Only Feature
sidekick_cpus
(model: wallaroo.model.Model, core_count: float)
Sets the number of CPUs to be used for the model’s sidekick container. Only affects image-based models (e.g. MLFlow models) in a deployment. The parameters are as follows:
Model model: The sidekick model to configure.
float core_count: Number of CPU cores to use in this sidekick.
sidekick_memory
(model: wallaroo.model.Model, memory_spec: str)
Sets the memory available to for the model’s sidekick container. Only affects image-based models (e.g. MLFlow models) in a deployment. The parameters are as follows:
Model model: The sidekick model to configure.
memory_spec: The amount of memory to allocated as memory unit values. The accepted unit values are:
Environment variables submitted to the model’s sidekick container. Only affects image-based models (e.g. MLFlow models) in a deployment. These are used specifically for containerized models that have environment variables that effect their performance.
sidekick_gpus
(model: wallaroo.model.Model, core_count: int)
Sets the number of GPUs to allocate for containerized runtimes. GPUs are only allocated in whole units, not as fractions. Organizations should be aware of the total number of GPUs available to the cluster, and monitor which pipeline deployment configurations have gpus allocated to ensure they do not run out. If there are not enough gpus to allocate to a pipeline deployment configuration, and error message will be deployed when the pipeline is deployed. If called, then the deployment_label must be called and match the GPU Nodepool for the Wallaroo Cluster hosting the Wallaroo instance.
√
Examples
Native Runtime Deployment
The following will set native runtime deployment to one quarter of a CPU with 1 Gi of Ram:
This example sets the replica count to 1, then sets the auto-scale to vary between 2 to 5 replicas depending on need, with 1 CPU and 1 GI RAM allocated per replica.
The following configuration allocates 0.25 CPU and 1Gi RAM to the containerized runtime sm_model, and passes that runtime environmental variables used for timeout settings.
The following configuration allocates 1 gpu to the pipeline for native runtimes, then another gpu to the containerized runtime sm_model for a total of 2 gpus allocated to the pipeline: one gpu for native runtimes, another gpu for the containerized runtime model sm_model.
How to create and manage Wallaroo Pipelines through the Wallaroo SDK
Pipeline have their own set of log files that are retrieved and analyzed as needed with the either through:
The Pipeline logs method (returns either a DataFrame or Apache Arrow).
The Pipeline export_logs method (saves either a DataFrame file in JSON format, or an Apache Arrow file).
Get Pipeline Logs
Pipeline logs are retrieved through the Pipeline logs method. By default, logs are returned as a DataFrame in reverse chronological order of insertion, with the most recent files displayed first.
Pipeline logs are segmented by pipeline versions. For example, if a new model step is added to a pipeline, a model swapped out of a pipeline step, etc - this generated a new pipeline version. log method requests will return logs based on the parameter that match the pipeline version. To request logs of a specific pipeline version, specify the start_datetime and end_datetime parameters based on the pipeline version logs requested.
IMPORTANT NOTE
Pipeline logs are returned either in reverse or forward chronological order of record insertion; depending on when a specific inference request completes, one inference record may be inserted out of chronological order by the Timestamp value, but still be in chronological order of insertion.
This command takes the following parameters.
Parameter
Type
Description
limit
Int (Optional) (Default: 100)
Limits how many log records to display. If there are more pipeline logs than are being displayed, the Warning message Pipeline log record limit exceeded will be displayed. For example, if 100 log files were requested and there are a total of 1,000, the warning message will be displayed.
start_datetime and end_datetime
DateTime (Optional)
Limits logs to all logs between the start_datetime and end_datetime DateTime parameters. These comply with the Python datetime library for formats such as:
datetime.datetime.now()
datetime.datetime(2023, 3, 28, 14, 25, 51, 660058, tzinfo=tzutc()) (March 28, 2023 14:25:51:660058 UTC time zone)
Both parameters must be provided. Submitting a logs() request with only start_datetime or end_datetime will generate an exception. If start_datetime and end_datetime are provided as parameters even with any other parameter, then the records are returned in chronological order, with the oldest record displayed first.
dataset
List[String] (OPTIONAL)
The datasets to be returned. The datasets available are:
*: Default. This translates to ["time", "in", "out", "check_failures"].
time: The DateTime of the inference request.
in: All inputs listed as in_{variable_name}.
out: All outputs listed as out_variable_name.
check_failures: Flags whether an Anomaly or Validation Check was triggered. 0 indicates no checks weretriggers, 1 or greater indicates a check was triggered.
meta: Returns metadata. IMPORTANT NOTE: See Metadata RequestsRestrictions for specifications on how this dataset can be used with otherdatasets.
Returns in the metadata.elapsed field:
A list of time in nanoseconds for:
The time to serialize the input.
How long each step took.
Returns in the metadata.last_model field:
A dict with each Python step as:
model_name: The name of the model in the pipeline step.
model_sha : The sha hash of the model in the pipeline step.
Returns in the metadata.pipeline_version field:
The pipeline version as a UUID value.
metadata.elapsed: IMPORTANT NOTE: See Metadata Requests Restrictionsfor specifications on how this dataset can be used with other datasets.
Returns in the metadata.elapsed field:
A list of time in nanoseconds for:
The time to serialize the input.
How long each step took.
dataset_exclude
List[String] (OPTIONAL)
Exclude specified datasets.
dataset_separator
Sequence[[String], string] (OPTIONAL)
If set to “.”, return dataset will be flattened.
arrow
Boolean (Optional) (Default: False)
If arrow is set to True, then the logs are returned as an Apache Arrow table. If arrow=False, then the logs are returned as a pandas DataFrame.
All of the parameters can be used together, but start_datetime and end_datetimemust be combined; if one is used, then so must the other. If start_datetime and end_datetime are used with any other parameter, then the log results are in chronological order of record insertion.
Log requests are limited to around 100k in size. For requests greater than 100k in size, use the Pipeline export_logs() method.
Logs include the following standard datasets:
Parameter
Type
Description
time
DateTime
The DateTime the inference request was made.
in.{variable}
The input(s) for the inference request. Each input is listed as in.{variable_name}. For example, in.text_input, in.square_foot, in.number_of_rooms, etc.
out
The outputs(s) for the inference request, based on the ML model’s outputs. Each output is listed as out.{variable_name}. For example, out.maximum_offer_price, out.minimum_asking_price, out.trade_in_value, etc.
check_failures
Int
How many validation checks were triggered by the inference. For more information, see Anomaly Testing
out_{model_name}.{variable}
Only returned when using Pipeline Shadow Deployments. For each model in the shadow deploy step, their output is listed in the format out_{model_name}.{variable}. For example, out_shadow_model_xgb.maximum_offer_price, out_shadow_model_xgb.minimum_asking_price, out_shadow_model_xgb.trade_in_value, etc.
out._model_split
Only returned when using A/B Testing, used to display the model_name, model_version, and model_sha of the model used for the inference.
In this example, the last 50 logs to the pipeline mainpipeline between two sample dates. In this case, all of the time column fields are the same since the inference request was sent as a batch.
The following restrictions are in place when requesting the datasets metadata or metadata.elapsed.
Standard Pipeline Steps
For the following Pipeline steps, metadata or metadata.elapsed must be requested with the * parameter. For example:
result = mainpipeline.infer(normal_input, dataset=["*", "metadata.elapsed"])
Effected pipeline steps:
add_model_step
replace_with_model_step
Testing Pipeline Steps
For the following Pipeline steps, meta or metadata.elapsedcan not be included with the * parameter. For example:
result = mainpipeline.infer(normal_input, dataset=["metadata.elapsed"])
Effected pipeline steps:
add_random_split
replace_with_random_split
add_shadow_deploy
replace_with_shadow_deploy
Export Pipeline Logs as File
The Pipeline method export_logs returns the Pipeline records as either by default pandas records in Newline Delimited JSON (NDJSON) format, or an Apache Arrow table files.
The output files are by default stores in the current working directory ./logs with the default prefix as the {pipeline name}-1, {pipeline name}-2, etc.
IMPORTANT NOTE
Files with the same names will be overwritten.
The suffix by default will be json for pandas records in Newline Delimited JSON (NDJSON) format files. Logs are segmented by pipeline version across the limit, data_size_limit, or start_datetime and end_datetime parameters.
By default, logs are returned as a pandas record in NDJSON in reverse chronological order of insertion, with the most recent log insertions displayed first.
Pipeline logs are segmented by pipeline versions. For example, if a new model step is added to a pipeline, a model swapped out of a pipeline step, etc - this generated a new pipeline version.
IMPORTANT NOTE
Pipeline logs are returned either in reverse or forward chronological order of record insertion; depending on when a specific inference request completes, one inference record may be inserted out of chronological order by the Timestamp value, but still be in chronological order of insertion.
This command takes the following parameters.
Parameter
Type
Description
directory
String (Optional) (Default: logs)
Logs are exported to a file from current working directory to directory.
file_prefix
String (Optional) (Default: The name of the pipeline)
The name of the exported files. By default, this will the name of the pipeline and is segmented by pipeline version between the limits or the start and end period. For example: ’logpipeline-1.json`, etc.
data_size_limit
String (Optional) (Default: 100MB)
The maximum size for the exported data in bytes. Note that file size is approximate to the request; a request of 10MiB may return 10.3MB of data. The fields are in the format “{size as number} {unit value}”, and can include a space so “10 MiB” and “10MiB” are the same. The accepted unit values are:
KiB (for KiloBytes)
MiB (for MegaBytes)
GiB (for GigaBytes)
TiB (for TeraBytes)
limit
Int (Optional) (Default: 100)
Limits how many log records to display. Defaults to 100. If there are more pipeline logs than are being displayed, the Warning message Pipeline log record limit exceeded will be displayed. For example, if 100 log files were requested and there are a total of 1,000, the warning message will be displayed.
start_datetime and end_datetime
DateTime (Optional)
Limits logs to all logs between the start_datetime and end_datetime DateTime parameters. These comply with the Python datetime library for formats such as:
datetime.datetime.now()
datetime.datetime(2023, 3, 28, 14, 25, 51, 660058, tzinfo=tzutc()) (March 28, 2023 14:25:51:660058 UTC time zone)
Both parameters must be provided. Submitting a logs() request with only start_datetime or end_datetime will generate an exception. If start_datetime and end_datetime are provided as parameters even with any other parameter, then the records are returned in chronological order, with the oldest record displayed first.
filename
String (Required)
The file name to save the log file to. The requesting user must have write access to the file location. The requesting user must have write permission to the file location, and the target directory for the file must already exist. For example: If the file is set to /var/wallaroo/logs/pipeline.json, then the directory /var/wallaroo/logs must already exist. Otherwise file names are only limited by standard file naming rules for the target environment.
dataset
List (OPTIONAL)
The datasets to be returned. The datasets available are:
*: Default. This translates to ["time", "in", "out", "check_failures"].
time: The DateTime of the inference request.
in: All inputs listed as in_{variable_name}.
out: All outputs listed as out_variable_name.
check_failures: Flags whether an Anomaly or Validation Check was triggered. 0 indicates no checks were triggered, 1 or greater indicates a check was triggered.
meta: Returns metadata. IMPORTANT NOTE: See Metadata RequestsRestrictions for specifications on how this dataset can be used with other datasets.
Returns in the metadata.elapsed field:
A list of time in nanoseconds for:
The time to serialize the input.
How long each step took.
Returns in the metadata.last_model field:
A dict with each Python step as:
model_name: The name of the model in the pipeline step.
model_sha : The sha hash of the model in the pipeline step.
Returns in the metadata.pipeline_version field:
The pipeline version as a UUID value.
metadata.elapsed: IMPORTANT NOTE: See Metadata Requests Restrictionsfor specifications on how this dataset can be used with other datasets.
Returns in the metadata.elapsed field:
A list of time in nanoseconds for:
The time to serialize the input.
How long each step took.
dataset_exclude
List[String] (OPTIONAL)
Exclude specified datasets.
dataset_separator
Sequence[[String], string] (OPTIONAL)
If set to “.”, return dataset will be flattened.
arrow
Boolean (Optional)
Defaults to False. If arrow=True, then the logs are returned as an Apache Arrow table. If arrow=False, then the logs are returned as pandas record in NDJSON that can be imported into a pandas DataFrame.
All of the parameters can be used together, but start_datetime and end_datetimemust be combined; if one is used, then so must the other. If start_datetime and end_datetime are used with any other parameter, then the log results are in chronological order of record insertion.
File sizes are limited to around 10 MB in size. If the requested log file is greater than 10 MB, a Warning will be displayed indicating the end date of the log file downloaded so the request can be adjusted to capture the requested log files.
IMPORTANT NOTE
DataFrame file exports exported as pandas record in NDJSON are read back to a DataFrame through the the pandas read_json method with the parameter lines=True. For example:
In this example, the log files are saved as both Pandas DataFrame and Apache Arrow.
# Save the DataFrame version of the log filemainpipeline.export_logs()
display(os.listdir('./logs'))
mainpipeline.export_logs(arrow=True)
display(os.listdir('./logs'))
Warning: Therearemorelogsavailable.Pleasesetalargerlimittoexportmoredata. ['pipeline-logs-1.json']
Warning: Therearemorelogsavailable.Pleasesetalargerlimittoexportmoredata. ['pipeline-logs-1.arrow', 'pipeline-logs-1.json']
Pipeline Log Storage
Pipeline logs have a set allocation of storage space and data requirements.
Pipeline Log Storage Warnings
To prevent storage and performance issues, inference result data may be dropped from pipeline logs by the following standards:
Columns are progressively removed from the row starting with the largest input data size and working to the smallest, then the same for outputs.
For example, Computer Vision ML Models typically have large inputs and output values - a single pandas DataFrame inference request may be over 13 MB in size, and the inference results nearly as large. To prevent pipeline log storage issues, the input may be dropped from the pipeline logs, and if additional space is needed, the inference outputs would follow. The time column is preserved.
IMPORTANT NOTE
Inference Requests will always return all inputs, outputs, and other metadata unless specifically requested for exclusion. It is the pipeline logs that may drop columns for space purposes.
If a pipeline has dropped columns for space purposes, this will be displayed when a log request is made with the following warning, with {columns} replaced with the dropped columns.
To review what columns are dropped from pipeline logs for storage reasons, include the dataset metadata in the request to view the column metadata.dropped. This metadata field displays a List of any columns dropped from the pipeline logs.
Data elements that do not fit the supported data types below, such as None or Null values, are not supported in pipeline logs. When present, undefined data will be written in the place of the null value, typically zeroes. Any null list values will present an empty list.
2.7 - Wallaroo SDK Essentials Guide: ML Workload Orchestration
How to create and manage ML Workload Orchestration through the Wallaroo SDK
Wallaroo provides ML Workload Orchestrations and Tasks to automate processes in a Wallaroo instance. For example:
Deploy a pipeline, retrieve data through a data connector, submit the data for inferences, undeploy the pipeline
Replace a model with a new version
Retrieve shadow deployed inference results and submit them to a database
Orchestration Flow
ML Workload Orchestration flow works within 3 tiers:
Tier
Description
ML Workload Orchestration
User created custom instructions that provide automated processes that follow the same steps every time without error. Orchestrations contain the instructions to be performed, uploaded as a .ZIP file with the instructions, requirements, and artifacts.
Task
Instructions on when to run an Orchestration as a scheduled Task. Tasks can be Run Once, where is creates a single Task Run, or Run Scheduled, where a Task Run is created on a regular schedule based on the Kubernetes cronjob specifications. If a Task is Run Scheduled, it will create a new Task Run every time the schedule parameters are met until the Task is killed.
Task Run
The execution of an task. These validate business operations are successful identify any unsuccessful task runs. If the Task is Run Once, then only one Task Run is generated. If the Task is a Run Scheduled task, then a new Task Run will be created each time the schedule parameters are met, with each Task Run having its own results and logs.
One example may be of making donuts.
The ML Workload Orchestration is the recipe.
The Task is the order to make the donuts. It might be Run Once, so only one set of donuts are made, or Run Scheduled, so donuts are made every 2nd Sunday at 6 AM. If Run Scheduled, the donuts are made every time the schedule hits until the order is cancelled (aka killed).
The Task Run are the donuts with their own receipt of creation (logs, etc).
Orchestration Requirements
Orchestrations are uploaded to the Wallaroo instance as a ZIP file with the following requirements:
Parameter
Type
Description
User Code
(Required) Python script as .py files
If main.py exists, then that will be used as the task entrypoint. Otherwise, the firstmain.py found in any subdirectory will be used as the entrypoint. If no main.py is found, the orchestration will not be accepted.
A standard Python requirements.txt for any dependencies to be provided in the task environment. The Wallaroo SDK will already be present and should not be included in the requirements.txt. Multiple requirements.txt files are not allowed.
Other artifacts
Other artifacts such as files, data, or code to support the orchestration.
Zip Instructions
In a terminal with the zip command, assemble artifacts as above and then create the archive. The zip command is included by default with the Wallaroo JupyterHub service.
zip commands take the following format, with {zipfilename}.zip as the zip file to save the artifacts to, and each file thereafter as the files to add to the archive.
zip {zipfilename}.zip file1, file2, file3....
For example, the following command will add the files main.py and requirements.txt into the file hello.zip.
The following recommendations will make using Wallaroo orchestrations.
The version of Python used should match the same version as in the Wallaroo JupyterHub service.
The same version of the Wallaroo SDK should match the server. For a 2023.2.1 Wallaroo instance, use the Wallaroo SDK version 2023.2.1.
Specify the version of pip dependencies.
The wallaroo.Client constructor auth_type argument is ignored. Using wallaroo.Client() is sufficient.
The following methods will assist with orchestrations:
wallaroo.in_task() : Returns True if the code is running within an orchestration task.
wallaroo.task_args(): Returns a Dict of invocation-specific arguments passed to the run_ calls.
Orchestrations will be run in the same way as running within the Wallaroo JupyterHub service, from the version of Python libraries (unless specifically overridden by the requirements.txt setting, which is not recommended), and running in the virtualized directory /home/jovyan/.
Orchestration Code Samples
The following demonstres using the wallaroo.in_task() and wallaroo.task_args() methods within an Orchestration. This sample code uses wallaroo.in_task() to verify whether or not the script is running as a Wallaroo Task. If true, it will gather the wallaroo.task_args() and use them to set the workspace and pipeline. If False, then it sets the pipeline and workspace manually.
# get the argumentswl=wallaroo.Client()
# if true, get the arguments passed to the taskifwl.in_task():
arguments=wl.task_args()
# arguments is a key/value pair, set the workspace and pipeline nameworkspace_name=arguments['workspace_name']
pipeline_name=arguments['pipeline_name']
# False: We're not in a Task, so set the pipeline manuallyelse:
workspace_name="bigqueryworkspace"pipeline_name="bigquerypipeline"
Orchestration Methods
The following methods are provided for creating and listing orchestrations.
Create Orchestration
An orchestration is created through the Wallaroo Client upload_orchestration(path) with the following parameters.
For the uploads, either the path to the .zip file is required, or bytes_buffer with name are required. path can not be used with bytes_buffer and name, and vice versa.
Parameter
Type
Description
path
String (Optional)
The path to the .zip file that contains the orchestration package. Can not be use with bytes_buffer and name are used.
file_name
String (Optional)
The file name to give to the zip file when uploaded.
bytes_buffer
[bytes] (Optional)
The .zip file object to be uploaded. Can not be used with path. Note that if the zip file is uploaded as from the bytes_buffer parameter and file_name is not included, then the file name in the Wallaroo orchestrations list will be -.
name
String (Optional)
Sets the name of the byte uploaded zip file.
List Orchestrations
All orchestrations for a Wallaroo instances are listed via the Wallaroo Client list_orchestrations() method. It returns an array with the following.
Parameter
Type
Description
id
String
The UUID identifier for the orchestration.
last run status
String
The last reported status the task. Valid values are:
packaging: The orchestration has been upload and is being prepared.
ready: The orchestration is available to be used as a task.
sha
String
The sha value of the uploaded orchestration.
name
String
The name of the orchestration
filename
String
The name of the uploaded orchestration file.
created at
DateTime
The date and time the orchestration was uploaded to the Wallaroo instance.
updated at
DateTime
The date and time a new version of the orchestration was uploaded.
wl.list_orchestrations()
id
name
status
filename
sha
created at
updated at
0f90e606-09f8-409b-a306-cb04ec4c011a
comprehensive sample
ready
remote_inference.zip
b88e93...2396fb
2023-22-May 19:55:15
2023-22-May 19:56:09
Task Methods
Tasks are the implementation of an orchestration. Think of the orchestration as the instructions to follow, and the Task is the unit actually doing it.
Tasks are set at the workspace level.
Create Tasks
Tasks are created from an orchestration through the following methods.
Task Type
Description
run_once
Run the task once.
run_scheduled
Run on a schedule, repeat every time the schedule fits the task until it is killed.
Tasks have the following parameters.
Parameter
Type
Description
id
String
The UUID identifier for the task.
last run status
String
The last reported status the task. Values are:
unknown: The task has not been started or is being prepared.
ready: The task is scheduled to execute.
running: The task has started.
failure: The task failed.
success: The task completed.
type
String
The type of the task. Values are:
Temporary Run: The task runs once then stop.
Scheduled Run: The task repeats on a cron like schedule.
Service Run: The task runs as a service and executes when its service port is activated.
active
Boolean
True: The task is scheduled or running. False: The task has completed or has been issued the kill command.
schedule
String
The cron style schedule for the task. If the task is not a scheduled one, then the schedule will be -.
created at
DateTime
The date and time the task was started.
updated at
DateTime
The date and time the task was updated.
Run Task Once
Temporary Run tasks are created from the Orchestration run_once(name, json_args, timeout) with the following parameters.
Parameter
Type
Description
name
String (Required)
The designated name of the task.
json_args
Dict (Required)
Arguments for the orchestration, such as { "dogs": 3.9, "cats": 8.1}
timeout
int (Optional)
Timeout period in seconds.
task=orchestration.run_once(name="house price run once 2", json_args={"workspace_name": workspace_name,
"pipeline_name":pipeline_name,
"connection_name": connection_name }
)
task
Field
Value
ID
f0e27d6a-6a98-4d26-b240-266f08560c48
Name
house price run once 2
Last Run Status
unknown
Type
Temporary Run
Active
True
Schedule
-
Created At
2023-22-May 19:58:32
Updated At
2023-22-May 19:58:32
Run Task Scheduled
A task can be scheduled via the Orchestration run_scheduled method.
Scheduled tasks are run every time the schedule period is met. This uses the same settings as the cron utility.
Scheduled tasks include the following parameters.
Parameter
Type
Description
name
String (Required)
The name of the task.
schedule
String (Required)
Schedule in the cron format of: hour, minute, day_of_week, day_of_month, month.
timeout
int (Optional)
Timeout period in seconds.
json_args
Dict (Required)
Arguments for the task, such as { "dogs": 3.9, "cats": 8.1}
The schedule uses the same method as the cron service. For example, the following schedule:
schedule={'42 * * * *'}
Runs on the 42nd minute of every hour. The following schedule:
The list of tasks in the Wallaroo instance is retrieves through the Wallaroo Client list_tasks() method that accepts the following parameters.
Parameter
Type
Description
killed
Boolean (OptionalDefault: False)
Returns tasks depending on whether they have been issued the kill command. False returns all tasks whether killed or not. True only returns killed tasks.
This returns an array list of the following in reverse chronological order from updated at.
Parameter
Type
Description
id
String
The UUID identifier for the task.
last run status
String
The last reported status the task. Values are:
unknown: The task has not been started or is being prepared.
ready: The task is scheduled to execute.
running: The task has started.
failure: The task failed.
success: The task completed.
type
String
The type of the task. Values are:
Temporary Run: The task runs once then stop.
Scheduled Run: The task repeats on a cron like schedule.
Service Run: The task runs as a service and executes when its service port is activated.
active
Boolean
True: The task is scheduled or running. False: The task has completed or has been issued the kill command.
schedule
String
The cron style schedule for the task. If the task is not a scheduled one, then the schedule will be -.
created at
DateTime
The date and time the task was started.
updated at
DateTime
The date and time the task was updated.
For example:
wl.list_tasks()
id
name
last run status
type
active
schedule
created at
updated at
f0e27d6a-6a98-4d26-b240-266f08560c48
house price run once 2
running
Temporary Run
True
-
2023-22-May 19:58:32
2023-22-May 19:58:38
36509ef8-98da-42a0-913f-e6e929dedb15
house price run once
success
Temporary Run
True
-
2023-22-May 19:56:37
2023-22-May 19:56:48
An individual task can be retrieved through the list_tasks() by specifying the task from the array returned. In this example, the first task listed from the list_tasks() method will be assigned to the task variable.
task=wl.list_tasks()[0]
Get Task Status
The status of a task is retrieved through the Task status() method and returns the following.
Parameter
Type
Description
status
String
The current status of the task. Values are:
pending: The task has not been started or is being prepared.
started: The task has started to execute.
display(task2.status())
'started'
Kill a Task
Killing a task removes the schedule or removes it from a service. Tasks are killed with the Task kill() method, and returns a message with the status of the kill procedure.
Note that a Task set to Run Scheduled will generate a new Task Run each time the schedule parameters are met until the Task is killed. A Task set to Run Once will generate only one Task Run, so does not need to be killed.
Task Runs are generated from a Task. If the Task is Run Once, then only one Task Run is generated. If the Task is a Run Scheduled task, then a new Task Run will be created each time the schedule parameters are met, with each Task Run having its own results and logs.
Task Last Runs History
The history of a task, which each deployment of the task is known as a task run is retrieved with the Task last_runs method that takes the following arguments.
Parameter
Type
Description
status
String (Optional *Default: all)
Filters the task history by the status. If all, returns all statuses. Status values are:
running: The task has started.
failure: The task failed.
success: The task completed.
limit
Integer (Optional)
Limits the number of task runs returned.
This returns the following in reverse chronological order by updated at.
Parameter
Type
Description
task id
String
Task id in UUID format.
pod id
String
Pod id in UUID format.
status
String
Status of the task. Status values are:
running: The task has started.
failure: The task failed.
success: The task completed.
created at
DateTime
Date and time the task was created at.
updated at
DateTime
Date and time the task was updated.
task.last_runs()
task id
pod id
status
created at
updated at
f0e27d6a-6a98-4d26-b240-266f08560c48
7d9d73d5-df11-44ed-90c1-db0e64c7f9b8
success
2023-22-May 19:58:35
2023-22-May 19:58:35
Task Run Logs
The output of a task is displayed with the Task Run logs() method that takes the following parameters.
Parameter
Type
Description
limit
Integer (Optional)
Limits the lines returned from the task run log. The limit parameter is based on the log tail - starting from the last line of the log file, then working up until the limit of lines is reached. This is useful for viewing final outputs, exceptions, etc.
The Task Run logs() returns the log entries as a string list, with each entry as an item in the list.
IMPORTANT NOTE: It may take around a minute for task run logs to be integrated into the Wallaroo log database.
# give time for the task to complete and the log files enteredtime.sleep(60)
recent_run=task.last_runs()[0]
display(recent_run.logs())
2.8 - Wallaroo SDK Essentials Guide: Tag Management
How to create and manage Wallaroo Tags through the Wallaroo SDK
Wallaroo SDK Tag Management
Tags are applied to either model versions or pipelines. This allows organizations to track different versions of models, and search for what pipelines have been used for specific purposes such as testing versus production use.
Create Tag
Tags are created with the Wallaroo client command create_tag(String tagname). This creates the tag and makes it available for use.
The tag will be saved to the variable currentTag to be used in the rest of these examples.
# Now we create our tagcurrentTag=wl.create_tag("My Great Tag")
List Tags
Tags are listed with the Wallaroo client command list_tags(), which shows all tags and what models and pipelines they have been assigned to.
Tags are used with pipelines to track different pipelines that are built or deployed with different features or functions.
Add Tag to Pipeline
Tags are added to a pipeline through the Wallaroo Tag add_to_pipeline(pipeline_id) method, where pipeline_id is the pipeline’s integer id.
For this example, we will add currentTag to testtest_pipeline, then verify it has been added through the list_tags command and list_pipelines command.
# add this tag to the pipelinecurrentTag.add_to_pipeline(tagtest_pipeline.id())
{'pipeline_pk_id': 1, 'tag_pk_id': 1}
Search Pipelines by Tag
Pipelines can be searched through the Wallaroo Client search_pipelines(search_term) method, where search_term is a string value for tags assigned to the pipelines.
In this example, the text “My Great Tag” that corresponds to currentTag will be searched for and displayed.
wl.search_pipelines('My Great Tag')
name
version
creation_time
last_updated_time
deployed
tags
steps
tagtestpipeline
5a4ff3c7-1a2d-4b0a-ad9f-78941e6f5677
2022-29-Nov 17:15:21
2022-29-Nov 17:15:21
(unknown)
My Great Tag
Remove Tag from Pipeline
Tags are removed from a pipeline with the Wallaroo Tag remove_from_pipeline(pipeline_id) command, where pipeline_id is the integer value of the pipeline’s id.
For this example, currentTag will be removed from tagtest_pipeline. This will be verified through the list_tags and search_pipelines command.
## remove from pipelinecurrentTag.remove_from_pipeline(tagtest_pipeline.id())
{'pipeline_pk_id': 1, 'tag_pk_id': 1}
Wallaroo Model Tag Management
Tags are used with models to track differences in model versions.
Assign Tag to a Model
Tags are assigned to a model through the Wallaroo Tag add_to_model(model_id) command, where model_id is the model’s numerical ID number. The tag is applied to the most current version of the model.
For this example, the currentTag will be applied to the tagtest_model. All tags will then be listed to show it has been assigned to this model.
# add tag to modelcurrentTag.add_to_model(tagtest_model.id())
{'model_id': 1, 'tag_id': 1}
Search Models by Tag
Model versions can be searched via tags using the Wallaroo Client method search_models(search_term), where search_term is a string value. All models versions containing the tag will be displayed. In this example, we will be using the text from our tag to list all models that have the text from currentTag in them.
# Search models by tagwl.search_models('My Great Tag')
name
version
file_name
image_path
last_update_time
tagtestmodel
70169e97-fb7e-4922-82ba-4f5d37e75253
ccfraud.onnx
None
2022-11-29 17:15:21.703465+00:00
Remove Tag from Model
Tags are removed from models using the Wallaroo Tag remove_from_model(model_id) command.
In this example, the currentTag will be removed from tagtest_model. A list of all tags will be shown with the list_tags command, followed by searching the models for the tag to verify it has been removed.
### remove tag from modelcurrentTag.remove_from_model(tagtest_model.id())
How to create and manage Wallaroo Assays through the Wallaroo SDK
Model Insights and Interactive Analysis Introduction
Wallaroo provides the ability to perform interactive analysis so organizations can explore the data from a pipeline and learn how the data is behaving. With this information and the knowledge of your particular business use case you can then choose appropriate thresholds for persistent automatic assays as desired.
IMPORTANT NOTE
Model insights operates over time and is difficult to demo in a notebook without pre-canned data. We assume you have an active pipeline that has been running and making predictions over time and show you the code you may use to analyze your pipeline.
Monitoring tasks called assays monitors a model’s predictions or the data coming into the model against an established baseline. Changes in the distribution of this data can be an indication of model drift, or of a change in the environment that the model trained for. This can provide tips on whether a model needs to be retrained or the environment data analyzed for accuracy or other needs.
Assay Details
Assays contain the following attributes:
Attribute
Default
Description
Name
The name of the assay. Assay names must be unique.
Baseline Data
Data that is known to be “typical” (typically distributed) and can be used to determine whether the distribution of new data has changed.
Schedule
Every 24 hours at 1 AM
New assays are configured to run a new analysis for every 24 hours starting at the end of the baseline period. This period can be configured through the SDK.
Group Results
Daily
Groups assay results into groups based on either Daily (the default), Weekly, or Monthly.
Metric
PSI
Population Stability Index (PSI) is an entropy-based measure of the difference between distributions. Maximum Difference of Bins measures the maximum difference between the baseline and current distributions (as estimated using the bins). Sum of the difference of bins sums up the difference of occurrences in each bin between the baseline and current distributions.
Threshold
0.1
The threshold for deciding whether the difference between distributions, as evaluated by the above metric, is large (the distributions are different) or small (the distributions are similar). The default of 0.1 is generally a good threshold when using PSI as the metric.
Number of Bins
5
Sets the number of bins that will be used to partition the baseline data for comparison against how future data falls into these bins. By default, the binning scheme is percentile (quantile) based. The binning scheme can be configured (see Bin Mode, below). Note that the total number of bins will include the set number plus the left_outlier and the right_outlier, so the total number of bins will be the total set + 2.
Bin Mode
Quantile
Set the binning scheme. Quantile binning defines the bins using percentile ranges (each bin holds the same percentage of the baseline data). Equal binning defines the bins using equally spaced data value ranges, like a histogram. Custom allows users to set the range of values for each bin, with the Left Outlier always starting at Min (below the minimum values detected from the baseline) and the Right Outlier always ending at Max (above the maximum values detected from the baseline).
Bin Weight
Equally Weighted
The bin weights can be either set to Equally Weighted (the default) where each bin is weighted equally, or Custom where the bin weights can be adjusted depending on which are considered more important for detecting model drift.
Manage Assays via the Wallaroo SDK
List Assays
Assays are listed through the Wallaroo Client list_assays method.
wl.list_assays()
name
active
status
warning_threshold
alert_threshold
pipeline_name
api_assay
True
created
0.0
0.1
housepricepipe
Interactive Baseline Runs
We can do an interactive run of just the baseline part to see how the baseline data will be put into bins. This assay uses quintiles so all 5 bins (not counting the outlier bins) have 20% of the predictions. We can see the bin boundaries along the x-axis.
baseline_run.chart()
baseline mean = 12.940910643273655
baseline median = 12.884286880493164
bin_mode = Quantile
aggregation = Density
metric = PSI
weighted = False
We can also get a dataframe with the bin/edge information.
baseline_run.baseline_bins()
b_edges
b_edge_names
b_aggregated_values
b_aggregation
0
12.00
left_outlier
0.00
Density
1
12.55
q_20
0.20
Density
2
12.81
q_40
0.20
Density
3
12.98
q_60
0.20
Density
4
13.33
q_80
0.20
Density
5
14.97
q_100
0.20
Density
6
inf
right_outlier
0.00
Density
The previous assay used quintiles so all of the bins had the same percentage/count of samples. To get bins that are divided equally along the range of values we can use BinMode.EQUAL.
baseline mean = 12.940910643273655
baseline median = 12.884286880493164
bin_mode = Equal
aggregation = Density
metric = PSI
weighted = False
We now see very different bin edges and sample percentages per bin.
equal_baseline.baseline_bins()
b_edges
b_edge_names
b_aggregated_values
b_aggregation
0
12.00
left_outlier
0.00
Density
1
12.60
p_1.26e1
0.24
Density
2
13.19
p_1.32e1
0.49
Density
3
13.78
p_1.38e1
0.22
Density
4
14.38
p_1.44e1
0.04
Density
5
14.97
p_1.50e1
0.01
Density
6
inf
right_outlier
0.00
Density
Interactive Assay Runs
By default the assay builder creates an assay with some good starting parameters. In particular the assay is configured to run a new analysis for every 24 hours starting at the end of the baseline period. Additionally, it sets the number of bins to 5 so creates quintiles, and sets the target iopath to "outputs 0 0" which means we want to monitor the first column of the first output/prediction.
We can do an interactive run of just the baseline part to see how the baseline data will be put into bins. This assay uses quintiles so all 5 bins (not counting the outlier bins) have 20% of the predictions. We can see the bin boundaries along the x-axis.
We then run it with interactive_run and convert it to a dataframe for easy analysis with to_dataframe.
Now lets do an interactive run of the first assay as it is configured. Interactive runs don’t save the assay to the database (so they won’t be scheduled in the future) nor do they save the assay results. Instead the results are returned after a short while for further analysis.
Basic functionality for creating quick charts is included.
assay_results.chart_scores()
We see that the difference scores are low for a while and then jump up to indicate there is an issue. We can examine that particular window to help us decide if that threshold is set correctly or not.
We can generate a quick chart of the results. This chart shows the 5 quantile bins (quintiles) derived from the baseline data plus one for left outliers and one for right outliers. We also see that the data from the window falls within the baseline quintiles but in a different proportion and is skewing higher. Whether this is an issue or not is specific to your use case.
First lets examine a day that is only slightly different than the baseline. We see that we do see some values that fall outside of the range from the baseline values, the left and right outliers, and that the bin values are different but similar.
assay_results[0].chart()
baseline mean = 12.940910643273655
window mean = 12.969964654406132
baseline median = 12.884286880493164
window median = 12.899214744567873
bin_mode = Quantile
aggregation = Density
metric = PSI
weighted = False
score = 0.0029273068646199748
scores = [0.0, 0.000514261205558409, 0.0002139202456922972, 0.0012617897456473992, 0.0002139202456922972, 0.0007234154220295724, 0.0]
index = None
Other days, however are significantly different.
assay_results[12].chart()
baseline mean = 12.940910643273655
window mean = 13.06380216891949
baseline median = 12.884286880493164
window median = 13.027600288391112
bin_mode = Quantile
aggregation = Density
metric = PSI
weighted = False
score = 0.15060511096978788
scores = [4.6637149189075455e-05, 0.05969428191167242, 0.00806617426854112, 0.008316273402678306, 0.07090885609902021, 0.003572888138686759, 0.0]
index = None
assay_results[13].chart()
baseline mean = 12.940910643273655
window mean = 14.004728427908038
baseline median = 12.884286880493164
window median = 14.009637832641602
bin_mode = Quantile
aggregation = Density
metric = PSI
weighted = False
score = 2.9220486095961196
scores = [0.0, 0.7090936334784107, 0.7130482300184766, 0.33500731896676245, 0.12171058214520876, 0.9038825518183468, 0.1393062931689142]
index = None
If we want to investigate further, we can run interactive assays on each of the inputs to see if any of them show anything abnormal. In this example we’ll provide the feature labels to create more understandable titles.
The current assay expects continuous data. Sometimes categorical data is encoded as 1 or 0 in a feature and sometimes in a limited number of values such as 1, 2, 3. If one value has high a percentage the analysis emits a warning so that we know the scores for that feature may not behave as we expect.
We can chart each of the iopaths and do a visual inspection. From the charts we see that if any of the input features had significant differences in the first two days which we can choose to inspect further. Here we choose to show 3 charts just to save space in this notebook.
When we are comfortable with what alert threshold should be for our specific purposes we can create and save an assay that will be automatically run on a daily basis.
In this example we’re create an assay that runs everyday against the baseline and has an alert threshold of 0.5.
Once we upload it it will be saved and scheduled for future data as well as run against past data.
After a short while, we can get the assay results for further analysis.
When we get the assay results, we see that the assays analysis is similar to the interactive run we started with though the analysis for the third day does not exceed the new alert threshold we set. And since we called upload instead of interactive_run the assay was saved to the system and will continue to run automatically on schedule from now on.
Scheduling Assays
By default assays are scheduled to run every 24 hours starting immediately after the baseline period ends.
However, you can control the start time by setting start and the frequency by setting interval on the window.
So to recap:
The window width is the size of the window. The default is 24 hours.
The interval is how often the analysis is run, how far the window is slid into the future based on the last run. The default is the window width.
The window start is when the analysis should start. The default is the end of the baseline period.
For example to run an analysis every 12 hours on the previous 24 hours of data you’d set the window width to 24 (the default) and the interval to 12.
To start a weekly analysis of the previous week on a specific day, set the start date (taking care to specify the desired timezone), and the width and interval to 1 week and of course an analysis won’t be generated till a window is complete.
The assay can be configured in a variety of ways to help customize it to your particular needs. Specifically you can:
change the BinMode to evenly spaced, quantile or user provided
change the number of bins to use
provide weights to use when scoring the bins
calculate the score using the sum of differences, maximum difference or population stability index
change the value aggregation for the bins to density, cumulative or edges
Lets take a look at these in turn.
Default configuration
First lets look at the default configuration. This is a lot of information but much of it is useful to know where it is available.
We see that the assay is broken up into 4 sections. A top level meta data section, a section for the baseline specification, a section for the window specification and a section that specifies the summarization configuration.
In the meta section we see the name of the assay, that it runs on the first column of the first output "outputs 0 0" and that there is a default threshold of 0.25.
The summarizer section shows us the defaults of Quantile, Density and PSI on 5 bins.
The baseline section shows us that it is configured as a fixed baseline with the specified start and end date times.
And the window tells us what model in the pipeline we are analyzing and how often.
We can run the assay interactively and review the first analysis. The method compare_basic_stats gives us a dataframe with basic stats for the baseline and window data.
The method compare_bins gives us a dataframe with the bin information. Such as the number of bins, the right edges, suggested bin/edge names and the values for each bin in the baseline and the window.
baseline mean = 12.940910643273655
window mean = 12.969964654406132
baseline median = 12.884286880493164
window median = 12.899214744567873
bin_mode = Equal
aggregation = Density
metric = PSI
weighted = False
score = 0.011074287819376092
scores = [0.0, 7.3591419975306595e-06, 0.000773779195360713, 8.538514991838585e-05, 0.010207597078872246, 1.6725322721660374e-07, 0.0]
index = None
User Provided Bin Edges
The values in this dataset run from ~11.6 to ~15.81. And lets say we had a business reason to use specific bin edges. We can specify them with the BinMode.PROVIDED and specifying a list of floats with the right hand / upper edge of each bin and optionally the lower edge of the smallest bin. If the lowest edge is not specified the threshold for left outliers is taken from the smallest value in the baseline dataset.
baseline mean = 12.940910643273655
window mean = 12.956829186961135
baseline median = 12.884286880493164
window median = 12.929338455200195
bin_mode = Quantile
aggregation = Density
metric = PSI
weighted = False
score = 0.16591076620684958
scores = [0.0, 0.0002571306027792045, 0.044058279699182114, 0.009441459631493015, 0.03381618572319047, 0.0027335446937028877, 0.0011792419836838435, 0.051023062424253904, 0.009441459631493015, 0.008662563542113508, 0.0052978382749576496, 0.0]
index = None
Bin Weights
Now lets say we only care about differences at the higher end of the range. We can use weights to specify that difference in the lower bins should not be counted in the score.
If we stick with 10 bins we can provide 10 a vector of 12 weights. One weight each for the original bins plus one at the front for the left outlier bin and one at the end for the right outlier bin.
Note we still show the values for the bins but the scores for the lower 5 and left outlier are 0 and only the right half is counted and reflected in the score.
baseline mean = 12.940910643273655
window mean = 12.956829186961135
baseline median = 12.884286880493164
window median = 12.929338455200195
bin_mode = Quantile
aggregation = Density
metric = PSI
weighted = True
score = 0.012600694309416988
scores = [0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.00019654033061397393, 0.00850384373737565, 0.0015735766052488358, 0.0014437605903522511, 0.000882973045826275, 0.0]
index = None
Metrics
The score is a distance or dis-similarity measure. The larger it is the less similar the two distributions are. We currently support summing the differences of each individual bin, taking the maximum difference and a modified Population Stability Index (PSI).
The following three charts use each of the metrics. Note how the scores change. The best one will depend on your particular use case.
baseline mean = 12.940910643273655
window mean = 12.969964654406132
baseline median = 12.884286880493164
window median = 12.899214744567873
bin_mode = Quantile
aggregation = Density
metric = MaxDiff
weighted = False
score = 0.01548175581324751
scores = [0.0, 0.009956893934794486, 0.006648048084512165, 0.01548175581324751, 0.006648048084512165, 0.012142553579017668, 0.0]
index = 3
Aggregation Options
Also, bin aggregation can be done in histogram Aggregation.DENSITY style (the default) where we count the number/percentage of values that fall in each bin or Empirical Cumulative Density Function style Aggregation.CUMULATIVE where we keep a cumulative count of the values/percentages that fall in each bin.
Inferences are performed on deployed pipelines. This submits data to the pipeline, where it is processed through each of the pipeline’s steps with the output of the previous step providing the input for the next step. The final step will then output the result of all of the pipeline’s steps.
Apache Arrow is the recommended method of data inputs for inferences. Wallaroo inference data is based on Apache Arrow, which will return the fastest inference results and smaller data transfer amounts on average than JSON or DataFrame tables. Arrow tables also specify the data types used in their schema, insuring that the data sent and receives are exactly what is required. Using pandas DataFrame requires inferring the data type which may lead to data type mismatch issues.
The pipeline infer(data, timeout, dataset, dataset_exclude, dataset_separator) method performs an inference as defined by the pipeline steps and takes the following arguments:
data (REQUIRED): The data submitted to the pipeline for inference. The following data inputs are supported:
pandas.DataFrame: Data submitted as a pandas DataFrame are returned as a pandas DataFrame. For models that output one column based on the models outputs.
Apache Arrow (Preferred): Data submitted as an Apache Arrow are returned as an Apache Arrow.
timeout (OPTIONAL): A timeout in seconds before the inference throws an exception. The default is 15 second per call to accommodate large, complex models. Note that for a batch inference, this is per call - with 10 inference requests, each would have a default timeout of 15 seconds.
dataset (OPTIONAL): The datasets to be returned. The datasets available are:
*: Default. This translates to ["time", "in", "out", "check_failures"].
time: The DateTime of the inference request.
in: All inputs listed as in_{variable_name}.
out: All outputs listed as out_variable_name.
check_failures: Flags whether an Anomaly or Validation Check was triggered. 0 indicates no checks were triggers, 1 or greater indicates a check was triggered.
meta: IMPORTANT NOTE: See Metadata Requests Restrictions for specifications on how to use meta or metadata dataset requests in combination with other fields.
Returns in the metadata.elapsed field:
A list of time in nanoseconds for:
The time to serialize the input.
How long each step took.
Returns in the metadata.last_model field:
A dict with each Python step as:
model_name: The name of the model in the pipeline step.
model_sha : The sha hash of the model in the pipeline step.
Returns in the metadata.pipeline_version field:
The pipeline version as a UUID value.
metadata.elapsed: See Metadata Requests Restrictions for specifications on how to use meta or metadata dataset requests in combination with other fields.
Returns in the metadata.elapsed field:
A list of time in nanoseconds for:
The time to serialize the input.
How long each step took.
dataset_exclude (OPTIONAL): Allows users to exclude parts of the dataset.
dataset_separator (OPTIONAL): Allows other types of dataset separators to be used. If set to “.”, the returned dataset will be flattened.
Outputs of the inference are based on the model’s outputs as out.{model_output}. This model only has one output - dense_1, which is listed in the out.dense_1 column. If the model has multiple outputs, they would be listed as out.output1, out.output2, etc.
The following example is an inference request using an Apache Arrow table. The inference result is returned as an Apache Arrow table, which is then converted into a Pandas DataFrame and a Polars DataFrame, with the results filtered based on results greater than 0.75.
The following restrictions are in place when requesting the datasets metadata or metadata.elapsed.
Standard Pipeline Steps
For the following Pipeline steps, metadata or metadata.elapsedmust be requested with the * parameter. For example:
result = mainpipeline.infer(normal_input, dataset=["*", "metadata.elapsed"])
Effected pipeline steps:
add_model_step
replace_with_model_step
Testing Pipeline Steps
For the following Pipeline steps, meta or metadata.elapsedcan not be included with the * parameter. For example:
result = mainpipeline.infer(normal_input, dataset=["metadata.elapsed"])
Effected pipeline steps:
add_random_split
replace_with_random_split
add_shadow_deploy
replace_with_shadow_deploy
Numpy Arrays as Inputs
Numpy arrays can be submitted as an input by containing it within a DataFrame. In this example, the input column is tensor, but can whatever the model expects.
dataframedata=pd.DataFrame({"tensor":[npArray]})
This bypasses the need to convert the npArray to a List - the object itself can be embedded into the DataFrame table and submitted. For this example, a DataFrame with the column tensor that contains a numpy array will be submitted as an inference, and from the return only the column out.2519 will be displayed.
To submit a data file directly to a pipeline, use the pipeline infer_from_file(data, timeout, dataset, dataset_exclude, dataset_separator) method. This performs an inference as defined by the pipeline steps and takes the following arguments:
data (REQUIRED): The name of the file submitted to the pipeline for inference.
pandas.DataFrame: Data submitted as a pandas DataFrame are returned as a pandas DataFrame. For models that output one column based on the models outputs.
Apache Arrow (Preferred): Data submitted as an Apache Arrow are returned as an Apache Arrow.
[Custom JSON]: Data formatted in a custom JSON format. This requires the use of the data_format="custom-json" parameter. IMPORTANT NOTE: Submitting JSON as input data can have performance repercussions compared to using either pandas DataFrame or Apache Arrow as the data input.
timeout (OPTIONAL): A timeout in seconds before the inference throws an exception. The default is 15 second per call to accommodate large, complex models. Note that for a batch inference, this is per call - with 10 inference requests, each would have a default timeout of 15 seconds. Inferences sent in a batch rather than individual inference requests are processed faster.
dataset (OPTIONAL): The datasets to be returned. By default this is set to ["*"] which returns, [“time”, “in”, “out”, “check_failures”].
dataset (OPTIONAL): The datasets to be returned. The datasets available are:
*: Default. This translates to ["time", "in", "out", "check_failures"].
time: The DateTime of the inference request.
in: All inputs listed as in_{variable_name}.
out: All outputs listed as out_variable_name.
check_failures: Flags whether an Anomaly or Validation Check was triggered. 0 indicates no checks were triggers, 1 or greater indicates a check was triggered.
meta:
Returns in the metadata.elapsed field:
A list of time in nanoseconds for:
The time to serialize the input.
How long each step took.
metadata.elapsed:
Returns in the metadata.elapsed field:
A list of time in nanoseconds for:
The time to serialize the input.
How long each step took.
Returns in the metadata.last_model field:
A dict with each Python step as:
model_name: The name of the model in the pipeline step.
model_sha : The sha hash of the model in the pipeline step.
data_format: If the input is custom JSON, then this parameter must be included as data_format="custom-json".
dataset_exclude (OPTIONAL): Allows users to exclude parts of the dataset.
dataset_separator (OPTIONAL): Allows other types of dataset separators to be used. If set to “.”, the returned dataset will be flattened.
In this example, an inference of 50K inferences as an Apache Arrow file will be submitted to a model trained for reviewing IMDB reviews, and the first 5 results displayed.
Inference request inputs are extremely large - for example, greater than 4 GB. Parallen inference requests allow that request to be split into more manageable sizes and submitted in one request, with each segment split as a separate inference request automatically.
Inference inputs come from different data sources. This allows organizations to query data from different sources, add each query result to the list, then submit the entire list as one request and receive the results fast.
Image processing, where the entire image is of a extreme size and resolution where submitting the entire image requires large memory and bandwidth. The image can be resolved into separate pieces, then all the pieces submitted in one requests to allow parallelization to examine each individual piece and return the results faster than analyzing the entire large image.
It is highly recommended that the data elements included in the parallel inference List are all of the same data type. For example: all of the elements of the list should be a pandas DataFrame OR all an Apache Arrow table. This makes processing the returned information easier rather than trying to parse what type of data is received.
For example, if the parallel inference input list should be in the format:
Data Type
0
DataFrame
1
DataFrame
2
DataFrame
3
DataFrame
And not:
Data Type
0
DataFrame
1
Apache Arrow
2
DataFrame
3
Apache Arrow
Parallel Inferences Method
The pipeline parallel_infer(tensor_list, timeout, num_parallel, retries)asynchronous method performs an inference as defined by the pipeline steps and takes the following arguments:
tensor_list (REQUIRED List): The data submitted to the pipeline for inference as a List of the supported data types:
pandas.DataFrame: Data submitted as a pandas DataFrame are returned as a pandas DataFrame. For models that output one column based on the models outputs.
Apache Arrow (Preferred): Data submitted as an Apache Arrow are returned as an Apache Arrow.
timeout (OPTIONAL int): A timeout in seconds before the inference throws an exception. The default is 15 second per call to accommodate large, complex models. Note that for a batch inference, this is per list item - with 10 inference requests, each would have a default timeout of 15 seconds.
num_parallel (OPTIONAL int): The number of parallel threads used for the submission. This should be no more than four times the number of pipeline replicas.
retries (OPTIONAL int): The number of retries per inference request submitted.
parallel_infer is an asynchronous method that returns the Python callback list of tasks. Calling parallel_infer should be called with the await keyword to retrieve the callback results.
For example, the following will split a single pandas DataFrame table into rows, and submit each row as a separate DataFrame table. Once complete, each separate table is submitted via parallel_infer, and the results collected together as a new List. For this example, there are 4 replicas set in the pipeline deployment configuration.
dataset= []
forindex, rowintest_data.head(200).iterrows():
dataset.append(row.to_frame('text_input').reset_index())
# we have a list of 200 dataframes - run as in inferenceparallel_results=awaitpipeline.parallel_infer(dataset, timeout=10, num_parallel=8, retries=1)
Parallel Inference Returns
The await pipeline.parallel_infer method asynchronously returns a List of inference results. This includes how inference requests match the input types: pandas DataFrame inputs return pandas DataFrame, and Apache Arrow inputs return Apache Arrow objects. For example: a parallel inference request with 3 DataFrame tables in the list will return a list with 3 DataFrame tables.
Inference failures are tied to the object in the List that caused the failure. For example, a List with [dataframe1, dataframe2, dataframe3] where dataframe2 is malformed, then the List returned from await pipeline.parallel_infer would be [some inference result, error inference result, some inference result]. Results are returned in the same order of the data submitted.
Output Formats
DataFrame and Arrow
Output formats are based on the input types: pandas DataFrame inputs return pandas DataFrame, and Apache Arrow inputs return Apache Arrow objects.
The default columns returned are:
time: The DateTime of the inference request.
in: The input data.
out: The output data. Outputs of the inference are based on the model’s outputs as out.{model_output}. This model only has one output - dense_1, which is listed in the out.dense_1 column. If the model has multiple outputs, they would be listed as out.{outputname1}, out.{outputname2}, etc.
Columns returned are controlled by the dataset_exclude array parameter, which specifies which output columns to ignore. For example, if a model outputs the columns out.rambo, out.main, out.glibnar, using the parameter dataset_exclude=["out.rambo", "out.glibnar"] will exclude those columns from the output.
Custom JSON
When submitting custom JSON as an input, JSON is returned as an output based on the model’s output parameters.
Using Apache Arrow is highly encouraged over custom JSON or pandas DataFrame for the inference speed, lower data transmission, and use specific data types as defined in the Arrow table schemas.
In this example, a pipeline with a Statsmodel model accepts custom JSON inputs and returns JSON as the output.
An Assay represents a record in the database. An assay contains
some high level attributes such as name, status, active, etc. as well
as the sub objects Baseline, Window and Summarizer which specify how
the Baseline is derived, how the Windows should be created and how the
analysis should be conducted.
a GraphQL client - in order to fill its missing members dynamically
an initial data blob - typically from unserialized JSON, contains at
least the data for required
members (typically the object's primary key) and optionally other data
members.
defturn_on(self):
Sets the Assay to active causing it to run and backfill any
missing analysis.
defturn_off(self):
Disables the Assay. No further analysis will be conducted until the assay
is enabled.
defset_alert_threshold(self, threshold:float):
Sets the alert threshold at the specified level. The status in the AssayAnalysis
will show if this level is exceeded however currently alerting/notifications are
not implemented.
defset_warning_threshold(self, threshold:float):
Sets the warning threshold at the specified level. The status in the AssayAnalysis
will show if this level is exceeded however currently alerting/notifications are
not implemented.
Creates a dataframe specifically for the edge information in the baseline or window.
Parameters
window_or_baseline: The dict from the assay result of either the window or baseline
classAssayAnalysis:
The AssayAnalysis class helps handle the assay analysis logs from the Plateau
logs. These logs are a json document with meta information on the assay and analysis
as well as summary information on the baseline and window and information on the comparison
between them.
Creates a simple dataframe to with the edge/bin data for a baseline.
defchart(self, show_scores=True):
Quickly create a chart showing the bins, values and scores of an assay analysis.
show_scores will also label each bin with its final weighted (if specified) score.
classAssayAnalysisList:
Helper class primarily to easily create a dataframe from a list
of AssayAnalysis objects.
The summarizer specifies how the bins of the baseline and
window should be compared.
SummarizerConfig()
defto_json(self) -> str:
classBinMode(builtins.str, enum.Enum):
How should we calculate the bins.
NONE - no bins. Only useful if we only care about the mean, median, etc.
EQUAL - evenly spaced bins: min - max / num_bins
QUANTILE - based on percentages. If num_bins is 5 then quintiles
so bins are created at the 20%, 40%, 60%, 80% and 100% points.
PROVIDED - user provides the edge points for the bins.
What we use to calculate the score.
EDGES - distnces between the edges.
DENSITY - percentage of values that fall in each bin.
CUMULATIVE - cumulative percentage that fall in the bins.
How we calculate the score.
MAXDIFF - maximum difference between corresponding bins.
SUMDIFF - sum of differences between corresponding bins.
PSI - Population Stability Index
The UnivariateContinousSummarizer analyizes one input or output feature
(Univariate) at a time. Expects the values to be continous or at least numerous
enough to fall in various/all the bins.
Specifies the weighting to be given to the bins. The number of weights
must be 2 larger than the number of bins to accomodate outliers smaller
and outliers larger than values seen in the baseline.
The passed in values can be whole or real numbers and do not need to add
up to 1 or any other specific value as they will be normalized during the
score calculation phase.
The weights passed in can be none to remove previously specified weights
and to allow changing of the number of bins.
Specifies the right hand side (max value) of the bins. The number
of edges must be equal to or one more than the number of bins. When
equal to the number of bins the edge for the left outlier bin is
calculated from the baseline. When an additional edge (one more than
number of bins) that first (lower) value is used as the max value for
the left outlier bin. The max value for the right hand outlier bin is
always Float MAX.
classWindowConfig:
Configures a window to be compared against the baseline.
Helps build a WindowConfig. model and width are required but there are no
good default values for them because they depend on the baseline. We leave it
up to the assay builder to configure the window correctly after it is created.
WindowBuilder(pipeline_name:str)
defadd_model_name(self, model_name:str):
The model name (model_id) that the window should analyze.
defadd_width(self, **kwargs:int):
The width of the window to use when collecting data for analysis.
defadd_interval(self, **kwargs:int):
The width of the window to use when collecting data for analysis.
Runs this assay interactively. The assay is not saved to the database
nor are analyis records saved to a Plateau topic. Useful for exploring
pipeline inference data and experimenting with thresholds.
Analyzes the inputs given to create an interactive run for each feature
column. The assay is not saved to the database nor are analyis records saved
to a Plateau topic. Usefull for exploring inputs for possible causes when a
difference is detected in the output.
Specify what the assay should analyze. Should start with input or output and have
indexes (zero based) into row and column: For example 'input 0 1' specifies the second
column of the first input.
deffixed_baseline_builder(self):
Specify creates a fixed baseline builder for this assay builder.
Declares a model variable that can be used as an :py:Expression: in the
model checker. Variables are identified by their model_name, a position
of either "input" or "output", and the tensor index.
str api_endpoint: Host/port of the platform API endpoint
str auth_endpoint: Host/port of the platform Keycloak instance
int timeout: Max timeout of web requests, in seconds
str auth_type: Authentication type to use. Can be one of: "none",
"sso", "user_password".
bool interactive: If provided and True, some calls will print additional human information, or won't when False. If not provided, interactive defaults to True if running inside Jupyter and False otherwise.
str time_format: Preferred strftime format string for displaying timestamps in a human context.
Search for pipelines. All parameters are optional, in which case the result is the same as
list_pipelines(). All times are strings to be parsed by datetime.isoformat. Example:
Search models owned by you
params:
search_term: Searches the following metadata: names, shas, versions, file names, and tags
uploaded_time_start: Inclusive time of upload
uploaded_time_end: Inclusive time of upload
Search all models you have access to.
params:
search_term: Searches the following metadata: names, shas, versions, file names, and tags
uploaded_time_start: Inclusive time of upload
uploaded_time_end: Inclusive time of upload
Creates a new PipelineVariant of a "value-split experiment" type.
Parameters
str name: Name of the Pipeline
meta_key str: Inference input key on which to redirect inputs to
experiment models.
default_model ModelConfig: Model to send inferences by default.
challenger_models List[Tuple[Any, ModelConfig]]: A list of
meta_key values -> Models to send inferences. If the inference data
referred to by meta_key is equal to one of the keys in this tuple,
that inference is redirected to the corresponding model instead of
the default model.
limit: Optional[int] The maximum number of logs to return.
start_datetime: Optional[datetime] The start time to get logs for.
end_datetime: Optional[datetime] The end time to get logs for.
:param dataset: Optional[List[str]] By default this is set to ["*"] which returns,
["time", "in", "out", "check_failures"]. Other available options - ["metadata"]
dataset_exclude: Optional[List[str]] If set, allows user to exclude parts of dataset.
dataset_separator: Optional[Union[Sequence[str], str]] If set to ".", return dataset will be flattened.
directory: Optional[str] If set, logs will be exported to a file in the given directory.
file_prefix: Optional[str] Prefix to name the exported file. Required if directory is set.
data_size_limit: Optional[str] The maximum size of the exported data in MB.
Size includes all files within the provided directory. By default, the data_size_limit will be set to 100MB.
arrow: Optional[bool] If set to True, return logs as an Arrow Table. Else, returns Pandas DataFrame.
Returns
Tuple[Union[pa.Table, pd.DataFrame, LogEntries], str] The logs and status.
Gets logs from Plateau for a particular time window without attempting
to convert them to Inference LogEntries. Logs can be returned as strings
or the json parsed into lists and dicts.
Parameters
topic str: The name of the topic to query
start Optional[datetime]: The start of the time window
end Optional[datetime]: The end of the time window
limit int: The number of records to retrieve. Note retrieving many
records may be a performance bottleneck.
parse bool: Wether to attempt to parse the string as a json object.
verbose bool: Prints out info to help diagnose issues.
Creates an AssayBuilder that can be used to configure and create
Assays.
Parameters
assay_name str: Human friendly name for the assay
pipeline Pipeline: The pipeline this assay will work on
model_name str: The model that this assay will monitor
baseline_start datetime: The start time for the inferences to
use as the baseline
baseline_end datetime: The end time of the baseline window.
the baseline. Windows start immediately after the baseline window and
are run at regular intervals continously until the assay is deactivated
or deleted.
Given an inbound source model, a model type (xgboost, keras, sklearn), and conversion arguments.
Convert the model to onnx, and add to available models for a pipeline.
Parameters
Union[str, pathlib.Path] path: The path to the model to convert, i.e. the source model.
ModelConversionSource source: The origin model type i.e. keras, sklearn or xgboost.
ModelConversionArguments conversion_arguments: A structure representing the arguments for converting a specific model type.
Returns
An instance of the Model being converted to Onnx.
Raises
ModelConversionGenericException: On a generic failure, please contact our support for further assistance.
ModelConversionFailure: Failure in converting the model type.
ModelConversionUnsupportedType: Raised when the source type passed is not supported.
ModelConversionSourceFileNotPresent: Raised when the passed source file does not exist.
deflist_orchestrations(self):
List all Orchestrations in the current workspace.
Returns
A List containing all Orchestrations in the current workspace.
Upload a file to be packaged and used as an Orchestration.
The uploaded artifact must be a ZIP file which contains:
User code. If main.py exists, then that will be used as the task entrypoint. Otherwise,
the first main.py found in any subdirectory will be used as the entrypoint.
Optional: A standard Python requirements.txt for any dependencies to be provided in the
task environment. The Wallaroo SDK will already be present and should not be mentioned.
Multiple requirements.txt files are not allowed.
Optional: Any other artifacts desired for runtime, including data or code.
Parameters
Optional[str] path: The path to the file on your filesystem that will be uploaded as an Orchestration.
Optional[bytes] bytes_buffer: The raw bytes to upload to be used Orchestration. Cannot be used with the path param.
Optional[str] name: An optional descriptive name for this Orchestration.
Optional[str] file_name: An optional filename to describe your Orchestration when using the bytes_buffer param. Ignored when path is used.
Returns
The Orchestration that was uploaded.
:raises OrchestrationUploadFailed If a server-side error prevented the upload from succeeding.
deflist_tasks(self, killed:bool=False):
List all Tasks in the current Workspace.
Returns
A List containing Task objects.
defget_task_by_id(self, task_id:str):
Retrieve a Task by its ID.
Parameters
str task_id: The ID of the Task to retrieve.
Returns
A Task object.
defin_task(self) -> bool:
Determines if this code is inside an orchestration task.
Returns
True if running in a task.
deftask_args(self) -> Dict[Any,Any]:
When running inside a task (see in_task()), obtain arguments passed to the task.
This class serves as a framework for API objects to be constructed based on
a partially-complete JSON response, and to fill in their remaining members
dynamically if needed.
Waits for the deployment status to enter the "Running" state.
Will wait up "timeout_request" seconds for the deployment to enter that state. This is set
in the "Client" object constructor. Will raise various exceptions on failures.
Will wait up "timeout_request" seconds for the deployment to enter that state. This is set
in the "Client" object constructor. Will raise various exceptions on failures.
Returns an inference result on this deployment, given a tensor.
Parameters
tensor: Union[Dict[str, Any], List[Any], pd.DataFrame, pa.Table]. The tensor to be sent to run inference on.
timeout: Optional[Union[int, float]] infer requests will time out after
the amount of seconds provided are exceeded. timeout defaults
to 15 secs.
dataset: Optional[List[str]] By default this is set to ["*"] which returns,
["time", "in", "out", "check_failures"]. Other available options - ["metadata"]
dataset_exclude: Optional[List[str]] If set, allows user to exclude parts of dataset.
dataset_separator: Optional[str] If set to ".", returned dataset will be flattened.
Returns
InferenceResult in dictionary, dataframe or arrow format.
This method is used to run inference on a deployment using a file. The file can be in one of the following
formats: pandas.DataFrame: .arrow, .json which contains data either in the pandas.records format
or wallaroo custom json format.
Parameters
filename: Union[str, pathlib.Path]. The file to be sent to run inference on.
data_format: Optional[str]. The format of the data in the file. If not provided, the format will be
inferred from the file extension.
timeout: Optional[Union[int, float]] infer requests will time out after the amount of seconds provided are
exceeded. timeout defaults to 15 secs.
dataset: Optional[List[str]] By default this is set to ["*"] which returns,
["time", "in", "out", "check_failures"]. Other available options - ["metadata"]
dataset_exclude: Optional[List[str]] If set, allows user to exclude parts of dataset.
dataset_separator: Optional[str] If set to ".", returned dataset will be flattened.
Returns
InferenceResult in dictionary, dataframe or arrow format.
Replaces the current model with a configured variant.
Parameters
ModelConfig model_config: Configured model to replace current model with
definternal_url(self) -> str:
Returns the internal inference URL that is only reachable from inside of the Wallaroo cluster by SDK instances deployed in the cluster.
If both pipelines and models are configured on the Deployment, this
gives preference to pipelines. The returned URL is always for the first
configured pipeline or model.
defurl(self) -> str:
Returns the inference URL.
If both pipelines and models are configured on the Deployment, this
gives preference to pipelines. The returned URL is always for the first
configured pipeline or model.
Converts a possibly multidimentionsl list of numbers into a
dict where each item in the list is represented by a key value pair
in the dict. Does not maintain dimensions since dataframes are 2d.
Does not maintain/manage types since it should work for any type supported
by numpy.
For example
[1,2,3] => {prefix_0: 1, prefix_1: 2, prefix_2: 3}.
[[1,2],[3,4]] => {prefix_0_0: 1, prefix_0_1: 2, prefix_1_0: 3, prefix_1_1: 4}
Recursively flattens the input dict, setting the values on the output dict.
Assumes simple value types (str, numbers, dicts, and lists).
If a value is a dict it is flattened recursively.
If a value is a list each item is set as a new k, v pair.
Very similar to dict_list_to_dataframe but specific to inference
logs since they have input and output heiararchical fields/structures
that must be treated in particular ways.
Convenience function to quickly deploy a Model. It will configure the model,
create a pipeline with a single model step, deploy it, and return the pipeline.
Typically, the configure() method is used to configure a model prior to
deploying it. However, if a default configuration is sufficient, this
function can be used to quickly deploy with said default configuration.
The filename this Model was generated from needs to have a recognizable
file extension so that the runtime can be inferred. Currently, this is:
.onnx -> ONNX runtime
Parameters
str deployment_name: Name of the deployment to create. Must be
unique across all deployments. Deployment names must be ASCII alpha-numeric
characters plus dash (-) only.
Attributes that are null in the database will be returned as None in Python,
and we want them to be set as such, so None cannot be used as a sentinel
value signaling that an optional attribute is not yet set. Objects of this
class fill that role instead.
DehydratedValue()
defrehydrate(attr):
Decorator that rehydrates the named attribute if needed.
This should decorate getter calls for an attribute:
This will cause the API object to "rehydrate" (perform a query to fetch and
fill in all attributes from the database) if the named attribute is not set.
Raised when a model conversion took longer than 10mins
ModelConversionTimeoutError(e)
Inherited Members
builtins.BaseException
with_traceback
args
classEntityNotFoundError(builtins.Exception):
Raised when a query for a specific API object returns no results.
This is specifically for queries by unique identifiers that are expected to
return exactly one result; queries that can return 0 to many results should
return empty list instead of raising this exception.
Raised when a community instance has hit the user limit
UserLimitError()
Inherited Members
builtins.BaseException
with_traceback
args
classDeploymentError(builtins.Exception):
Raised when deployment fails.
DeploymentError(e)
Inherited Members
builtins.BaseException
with_traceback
args
classInferenceError(builtins.Exception):
Raised when inference fails.
InferenceError(error:Dict[str,str])
Inherited Members
builtins.BaseException
with_traceback
args
classInvalidNameError(builtins.Exception):
Raised when an entity's name does not meet the expected critieria.
Parameters
str name: the name string that is invalid
str req: a string description of the requirement
InvalidNameError(name:str, req:str)
Inherited Members
builtins.BaseException
with_traceback
args
classCommunicationError(builtins.Exception):
Raised when some component cannot be contacted. There is a networking, configuration or
installation problem.
CommunicationError(e)
Inherited Members
builtins.BaseException
with_traceback
args
classObject(abc.ABC):
Base class for all backend GraphQL API objects.
This class serves as a framework for API objects to be constructed based on
a partially-complete JSON response, and to fill in their remaining members
dynamically if needed.
json_args Dict[Any, Any] A JSON object containing deploy-specific arguments.
timeout Optional[int] A timeout in seconds. Any instance of this orchestration that is running for longer than this specified time will be automatically killed.
debug Optional[bool] Produce extra debugging output about the run
schedule str A cron-style scheduling string, e.g. "* * * * " or "/15 * * * *"
json_args Dict[Any, Any] A JSON object containing deploy-specific arguments.
timeout Optional[int] A timeout in seconds. Any single instance of this orchestration that is running for longer than this specified time will be automatically killed. Future runs will still be scheduled.
debug Optional[bool] Produce extra debugging output about the run
limit: Optional[int]: Maximum number of logs to return.
start_datetime: Optional[datetime.datetime]: Start time for logs.
end_datetime: Optional[datetime.datetime]: End time for logs.
valid: Optional[bool]: If set to False, will include logs for failed inferences
dataset: Optional[List[str]] By default this is set to ["*"] which returns,
["time", "in", "out", "check_failures"]. Other available options - ["metadata"]
dataset_exclude: Optional[List[str]] If set, allows user to exclude parts of dataset.
dataset_separator: Optional[Union[Sequence[str], str]] If set to ".", return dataset will be flattened.
arrow: Optional[bool] If set to True, return logs as an Arrow Table. Else, returns Pandas DataFrame.
directory: Optional[str] Logs will be exported to a file in the given directory.
By default, logs will be exported to new "logs" subdirectory in current working directory.
file_prefix: Optional[str] Prefix to name the exported file. By default, the file_prefix will be set to
the pipeline name.
data_size_limit: Optional[str] The maximum size of the exported data in bytes.
Size includes all files within the provided directory. By default, the data_size_limit will be set to 100MB.
limit: Optional[int] The maximum number of logs to return.
start_datetime: Optional[datetime.datetime] The start time to filter logs by.
end_datetime: Optional[datetime.datetime] The end time to filter logs by.
valid: Optional[bool] If set to False, will return logs for failed inferences.
dataset: Optional[List[str]] By default this is set to ["*"] which returns,
["time", "in", "out", "check_failures"]. Other available options - ["metadata"]
dataset_exclude: Optional[List[str]] If set, allows user to exclude parts of dataset.
dataset_separator: Optional[Union[Sequence[str], str]] If set to ".", return dataset will be flattened.
arrow: Optional[bool] If set to True, return logs as an Arrow Table. Else, returns Pandas DataFrame.
:return None
Deploy pipeline. pipeline_name is optional if deploy was called previously. When specified,
pipeline_name must be ASCII alpha-numeric characters, plus dash (-) only.
defdefinition(self) -> str:
Get the current definition of the pipeline as a string
Returns an inference result on this deployment, given a tensor.
Parameters
tensor: Union[Dict[str, Any], pd.DataFrame, pa.Table] Inference data. Should be a dictionary.
Future improvement: will be a pandas dataframe or arrow table
timeout: Optional[Union[int, float]] infer requests will time out after
the amount of seconds provided are exceeded. timeout defaults
to 15 secs.
dataset: Optional[List[str]] By default this is set to ["*"] which returns,
["time", "in", "out", "check_failures"]. Other available options - ["metadata"]
dataset_exclude: Optional[List[str]] If set, allows user to exclude parts of dataset.
dataset_separator: Optional[Union[Sequence[str], str]] If set to ".", return dataset will be flattened.
Returns
InferenceResult in dictionary, dataframe or arrow format.
definfer_from_file(self, *args, **kwargs):
Returns an inference result on this deployment, given tensors in a file.
Routes inputs to a single model, randomly chosen from the list of
weighted options.
Each model receives inputs that are approximately proportional to the
weight it is assigned. For example, with two models having weights 1
and 1, each will receive roughly equal amounts of inference inputs. If
the weights were changed to 1 and 2, the models would receive roughly
33% and 66% respectively instead.
When choosing the model to use, a random number between 0.0 and 1.0 is
generated. The weighted inputs are mapped to that range, and the random
input is then used to select the model to use. For example, for the
two-models equal-weight case, a random key of 0.4 would route to the
first model. 0.6 would route to the second.
To support consistent assignment to a model, a hash_key can be
specified. This must be between 0.0 and 1.0. The value at this key, when
present in the input data, will be used instead of a random number for
model selection.
Create a "shadow deployment" experiment pipeline. The champion
model and all challengers are run for each input. The result data for
all models is logged, but the output of the champion is the only
result returned.
This is particularly useful for "burn-in" testing a new model with real
world data without displacing the currently proven model.
This is currently implemented as three steps: A multi model step, an audit step, and
a select step. To remove or replace this step, you need to remove or replace
all three. You can remove steps using pipeline.remove_step
Routes inputs to a single model, randomly chosen from the list of
weighted options.
Each model receives inputs that are approximately proportional to the
weight it is assigned. For example, with two models having weights 1
and 1, each will receive roughly equal amounts of inference inputs. If
the weights were changed to 1 and 2, the models would receive roughly
33% and 66% respectively instead.
When choosing the model to use, a random number between 0.0 and 1.0 is
generated. The weighted inputs are mapped to that range, and the random
input is then used to select the model to use. For example, for the
two-models equal-weight case, a random key of 0.4 would route to the
first model. 0.6 would route to the second.
To support consistent assignment to a model, a hash_key can be
specified. This must be between 0.0 and 1.0. The value at this key, when
present in the input data, will be used instead of a random number for
model selection.
Create a "shadow deployment" experiment pipeline. The champion
model and all challengers are run for each input. The result data for
all models is logged, but the output of the champion is the only
result returned.
This is particularly useful for "burn-in" testing a new model with real
world data without displacing the currently proven model.
This is currently implemented as three steps: A multi model step, an audit step, and
a select step. To remove or replace this step, you need to remove or replace
all three. You can remove steps using pipeline.remove_step
This class serves as a framework for API objects to be constructed based on
a partially-complete JSON response, and to fill in their remaining members
dynamically if needed.
This class serves as a framework for API objects to be constructed based on
a partially-complete JSON response, and to fill in their remaining members
dynamically if needed.
This class serves as a framework for API objects to be constructed based on
a partially-complete JSON response, and to fill in their remaining members
dynamically if needed.