Data Schema Definitions
Table of Contents
Models uploaded and deployed to Wallaroo pipelines require that the input data matches the model’s data schema. Pipeline steps chained in Wallaroo pipelines accept the outputs of the previous pipeline step, which may or may not be a model. Any sequence of steps requires the previous step’s outputs to match the next step’s inputs.
This is where tools like BYOP (Bring Your Own Predict) aka Arbitrary Python, or Python Models are useful to reshape data submitted to a Wallaroo pipeline or between models deployed in a Wallaroo pipeline become essential.
This guide aims to demonstrate how Wallaroo handles data types in regards to models, and how to shape data for different Wallaroo deployed models.
Data Types
Data types for inputs and outputs to inference requests through the Wallaroo is based on the Apache Arrow Data Types, with the following exceptions:
null:time32andtime64: Datetime data types must be converted to string.
Model Uploads
ML Models uploaded to Wallaroo except ONNX require their fields and data types specified in Apache Arrow pyarrow.Schema. For full details on specific ML models and their data requirements, see Wallaroo SDK Essentials Guide: Model Uploads and Registrations.
Each field is defined by it’s data type. For example, the following input and output schema are used for a Pytorch single input and output model, which receives a list of float values and returns a list of float values.
input_schema = pa.schema([
pa.field('input', pa.list_(pa.float32(), list_size=10))
])
output_schema = pa.schema([
pa.field('output', pa.list_(pa.float32(), list_size=1))
])
Model Uploads Examples - Hugging Face Summarization
The following example demonstrates the data schema for the Hugging Face LLM Summarizer Model which takes the following inputs and outputs.
- Inputs
| Field | Type | Description |
|---|---|---|
inputs | String (Required) | One or more articles to summarize. |
return_text | Bool (Optional) | Whether or not to include the decoded texts in the outputs. |
return_tensor | Bool (Optional) | Whether or not to include the tensors of predictions (as token indices) in the outputs. |
clean_up_tokenization_spaces | Bool (Optional) | Whether or not to clean up the potential extra spaces in the text output. |
- Outputs
| Field | Type | Description |
|---|---|---|
summary_text | String | The summary of the corresponding input. |
When uploading to Wallaroo using the Wallaroo SDK wallaroo.client.upload_model(name, path, framework, input_schema, output_schema, convert_wait, arch), the input_schema and output_schema define the fields the model uses as follows:
input_schema = pa.schema([
pa.field('inputs', pa.string()),
pa.field('return_text', pa.bool_()),
pa.field('return_tensors', pa.bool_()),
pa.field('clean_up_tokenization_spaces', pa.bool_())
])
output_schema = pa.schema([
pa.field('summary_text', pa.string()),
])
model = wl.upload_model(name="HF summerizer model",
path="./models/model-auto-conversion_hugging-face_complex-pipelines_hf-summarisation-bart-large-samsun.zip",
framework=wallaroo.framework.Framework.HUGGING_FACE_SUMMARIZATION,
input_schema=input_schema,
output_schema=output_schema
)
Model Uploads Examples - Computer Vision Resnet
The following example demonstrates the data schema for the Computer Vision Resnet model, which has the following inputs and outputs.
- Inputs
| Field | Type | Description |
|---|---|---|
tensor | Float | Tensor in the shape (n, 3, 480, 640) float. This is the normalized pixel values of the 640x480 color image. Note that this is a special case - the data for this example model has been flattened with the input field tensor from the original images. For more information, see the Computer Vision Tutorials tutorials. |
- Outputs
| Field | Type | Description |
|---|---|---|
boxes | Variable length List[Float] | The bounding boxes of detected objects with each 4 number sequence representing (x_coordinate, y_coordinate, width, height). List length is 4*n where n is the number of detected objects. |
classes | Variable length List[Int] | Integer values representing the categorical classes that are predicted by the model. List length is n where n is the number of detected objects. |
confidences | Variable length List[Float] | The confidence of detected classes. List length is n where n is the number of detected objects. |
This is translated into the following input and output schemas.
import pyarrow as py
input_schema = pa.schema([
pa.field('tensor', pa.list_(pa.float64()))
])
output_schema = pa.schema([
pa.field('forecast', pa.list_(pa.int64())),
pa.field('average_forecast', pa.list_(pa.float64()))
])
Inferencing Data
Wallaroo pipelines accept either Apache Arrow tables natively or pandas DataFrames and transmit inference results data as the same.
- If using the Wallaroo SDK with
wallaroo.pipeline.infer(https://docs.wallaroo.ai/20230201/wallaroo-developer-guides/wallaroo-sdk-guides/wallaroo-sdk-essentials-guide/wallaroo-sdk-essentials-inferences/) orwallaroo.pipeline.infer_from_file(https://docs.wallaroo.ai/20230201/wallaroo-developer-guides/wallaroo-sdk-guides/wallaroo-sdk-essentials-guide/wallaroo-sdk-essentials-inferences/), it is a “What you give is what you get” situation: If an Apache Arrow table is submitted for an inference request with the , then an Apache Arrow table is returned. If a pandas DataFrame is submitted, then a pandas DataFrame is returned. - If using the Wallaroo pipeline’s inference URL as an API request, the API headers
Content-TypeandAcceptdetermine what data type is submitted and what data type is received:- For DataFrame formatted JSON:
application/json; format=pandas-records - For Arrow binary files:
application/vnd.apache.arrow.file
- For DataFrame formatted JSON:
Once the data is received by Wallaroo, it is converted to the Apache Arrow table format and submitted to each model deployed in the pipeline in the Apache Arrow format.
Batch Inputs
For batch inputs, each inference request is contained in a single row of data. For example, a bike rental model predicts rentals based on previous dates for bikes sold, whether it was a week day, etc. These are submitted as a group of dates that are then used by the model to predict bike rentals on figure dates. For example, this 5 day period is submitted for the inference request.
| dteday | site_id | cnt | season | holiday | weekday | workingday | |
|---|---|---|---|---|---|---|---|
| 0 | 2011-02-02 | site0001 | 1240 | 1 | 0 | 3 | 1 |
| 1 | 2011-02-03 | site0001 | 1551 | 1 | 0 | 4 | 1 |
| 2 | 2011-02-04 | site0001 | 2324 | 1 | 0 | 5 | 1 |
| 3 | 2011-02-05 | site0001 | 805 | 1 | 0 | 6 | 0 |
| 4 | 2011-02-06 | site0001 | 1948 | 1 | 0 | 0 | 0 |
To submit to the Wallaroo deployed pipeline as a batch, each ranges of dates and values is set into a single row of data. This is reflected in the input and output schemas defined for the model. The pyarrow schema pa.list_ is used to define the data being received as a list per field.
import pyarrow as pa
import wallaroo
wl = wallaroo.Client()
input_schema = pa.schema([
pa.field('dteday', pa.list_(pa.string()) ),
pa.field('site_id', pa.list_(pa.string()) ),
pa.field('cnt', pa.list_(pa.int64()) ),
pa.field('season', pa.list_(pa.int64()) ),
pa.field('holiday', pa.list_(pa.int64()) ),
pa.field('weekday', pa.list_(pa.int64()) ),
pa.field('workingday', pa.list_(pa.int64()) ),
])
output_schema = pa.schema([
pa.field('dteday', pa.list_(pa.string()) ),
pa.field('site_id', pa.list_(pa.string()) ),
pa.field('forecast', pa.list_(pa.int64()) ),
])
arima_model = (wl.upload_model('bikeforecast-arima',
'./models/forecast.py',
framework=Framework.PYTHON)
.configure(runtime="python",
input_schema = input_schema,
output_schema = output_schema
)
)
Here, a month of data for single site is prepared for for a Wallaroo pipeline. Each inference request contained in a single row per site. Additional sites would be in their own row, with their month’s worth of data set as lists within the cells.
display(input_frame)
| dteday | site_id | cnt | season | holiday | weekday | workingday | |
|---|---|---|---|---|---|---|---|
| 0 | [2011-02-02, 2011-02-03, 2011-02-04, 2011-02-05, 2011-02-06, 2011-02-07, 2011-02-08, 2011-02-09, 2011-02-10, 2011-02-11, 2011-02-12, 2011-02-13, 2011-02-14, 2011-02-15, 2011-02-16, 2011-02-17, 2011-02-18, 2011-02-19, 2011-02-20, 2011-02-21, 2011-02-22, 2011-02-23, 2011-02-24, 2011-02-25, 2011-02-26, 2011-02-27, 2011-02-28, 2011-03-01, 2011-03-02, 2011-03-03, 2011-03-04, 2011-03-05, 2011-03-06, 2011-03-07, 2011-03-08] | [site0001, site0001, site0001, site0001, site0001, site0001, site0001, site0001, site0001, site0001, site0001, site0001, site0001, site0001, site0001, site0001, site0001, site0001, site0001, site0001, site0001, site0001, site0001, site0001, site0001, site0001, site0001, site0001, site0001, site0001, site0001, site0001, site0001, site0001, site0001] | [1240, 1551, 2324, 805, 1948, 1650, 913, 931, 1256, 1614, 1000, 1883, 1964, 2036, 2586, 3219, 3947, 1826, 1418, 723, 1281, 2564, 2181, 1539, 2059, 2428, 836, 1235, -1, -1, -1, -1, -1, -1, -1] | [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1] | [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0] | [3, 4, 5, 6, 0, 1, 2, 3, 4, 5, 6, 0, 1, 2, 3, 4, 5, 6, 0, 1, 2, 3, 4, 5, 6, 0, 1, 2, 3, 4, 5, 6, 0, 1, 2] | [1, 1, 1, 0, 0, 1, 1, 1, 1, 1, 0, 0, 1, 1, 1, 1, 1, 0, 0, 0, 1, 1, 1, 1, 0, 0, 1, 1, 1, 1, 1, 0, 0, 1, 1] |
Then the inference request is submitted and returned. The inference results are then converted to whatever format the data scientist and ML engineers require.
results = pipeline.infer(input_frame)
display(results)
| time | in.cnt | in.dteday | in.holiday | in.season | in.site_id | in.weekday | in.workingday | out.dteday | out.forecast | out.site_id | check_failures | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2023-09-22 00:15:20.214 | [1240, 1551, 2324, 805, 1948, 1650, 913, 931, 1256, 1614, 1000, 1883, 1964, 2036, 2586, 3219, 3947, 1826, 1418, 723, 1281, 2564, 2181, 1539, 2059, 2428, 836, 1235, -1, -1, -1, -1, -1, -1, -1] | [2011-02-02, 2011-02-03, 2011-02-04, 2011-02-05, 2011-02-06, 2011-02-07, 2011-02-08, 2011-02-09, 2011-02-10, 2011-02-11, 2011-02-12, 2011-02-13, 2011-02-14, 2011-02-15, 2011-02-16, 2011-02-17, 2011-02-18, 2011-02-19, 2011-02-20, 2011-02-21, 2011-02-22, 2011-02-23, 2011-02-24, 2011-02-25, 2011-02-26, 2011-02-27, 2011-02-28, 2011-03-01, 2011-03-02, 2011-03-03, 2011-03-04, 2011-03-05, 2011-03-06, 2011-03-07, 2011-03-08] | [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0] | [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1] | [site0001, site0001, site0001, site0001, site0001, site0001, site0001, site0001, site0001, site0001, site0001, site0001, site0001, site0001, site0001, site0001, site0001, site0001, site0001, site0001, site0001, site0001, site0001, site0001, site0001, site0001, site0001, site0001, site0001, site0001, site0001, site0001, site0001, site0001, site0001] | [3, 4, 5, 6, 0, 1, 2, 3, 4, 5, 6, 0, 1, 2, 3, 4, 5, 6, 0, 1, 2, 3, 4, 5, 6, 0, 1, 2, 3, 4, 5, 6, 0, 1, 2] | [1, 1, 1, 0, 0, 1, 1, 1, 1, 1, 0, 0, 1, 1, 1, 1, 1, 0, 0, 0, 1, 1, 1, 1, 0, 0, 1, 1, 1, 1, 1, 0, 0, 1, 1] | [2011-03-02, 2011-03-03, 2011-03-04, 2011-03-05, 2011-03-06, 2011-03-07, 2011-03-08] | [2269, 1712, 1795, 1371, 1819, 2045, 1974] | [site0001, site0001, site0001, site0001, site0001, site0001, site0001] | 0 |
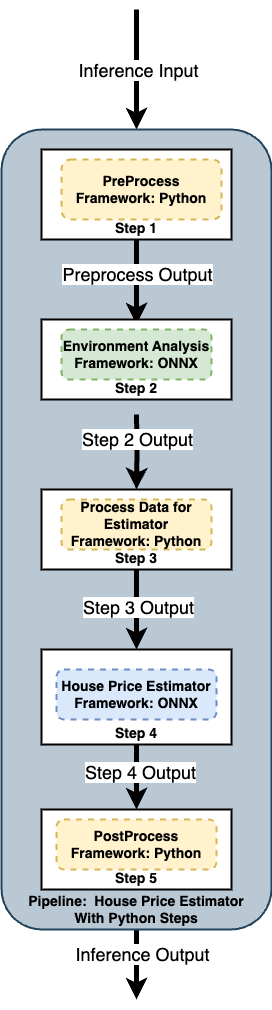
Multiple Step Pipelines
Pipelines with multiple models as pipeline steps still have the same input and output parameters. The inference input is fed to the pipeline, which submits it to the first model. The first model’s output becomes the input for the next model, until with the last model the pipeline submits the final inference results.
There are different ways of handling data in this scenario.
Set each model’s inputs and outputs to match. This will require each model’s outputs to match the next model’s inputs. This will require tailoring each model to match the previous model’s data types.
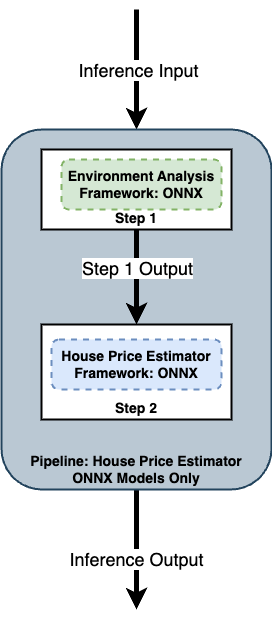
Use Python models, where a Python script a model to transform the data outputs from one model to match the data inputs of the next one. See Wallaroo SDK Essentials Guide: Model Uploads and Registrations: Python Models for full details and requirements.
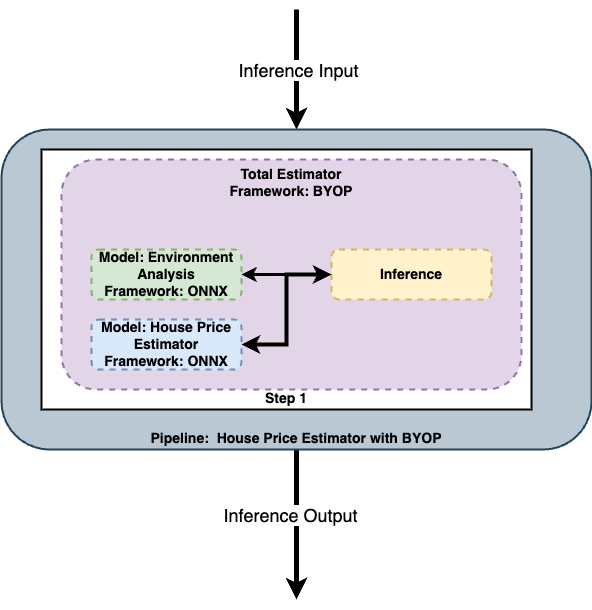
Use BYOP (Bring Your Own Predict) aka Arbitary Python models, which combines models and Python scripts as one cohesive model. See Wallaroo SDK Essentials Guide: Model Uploads and Registrations: Arbitrary Python for full details and requirements.