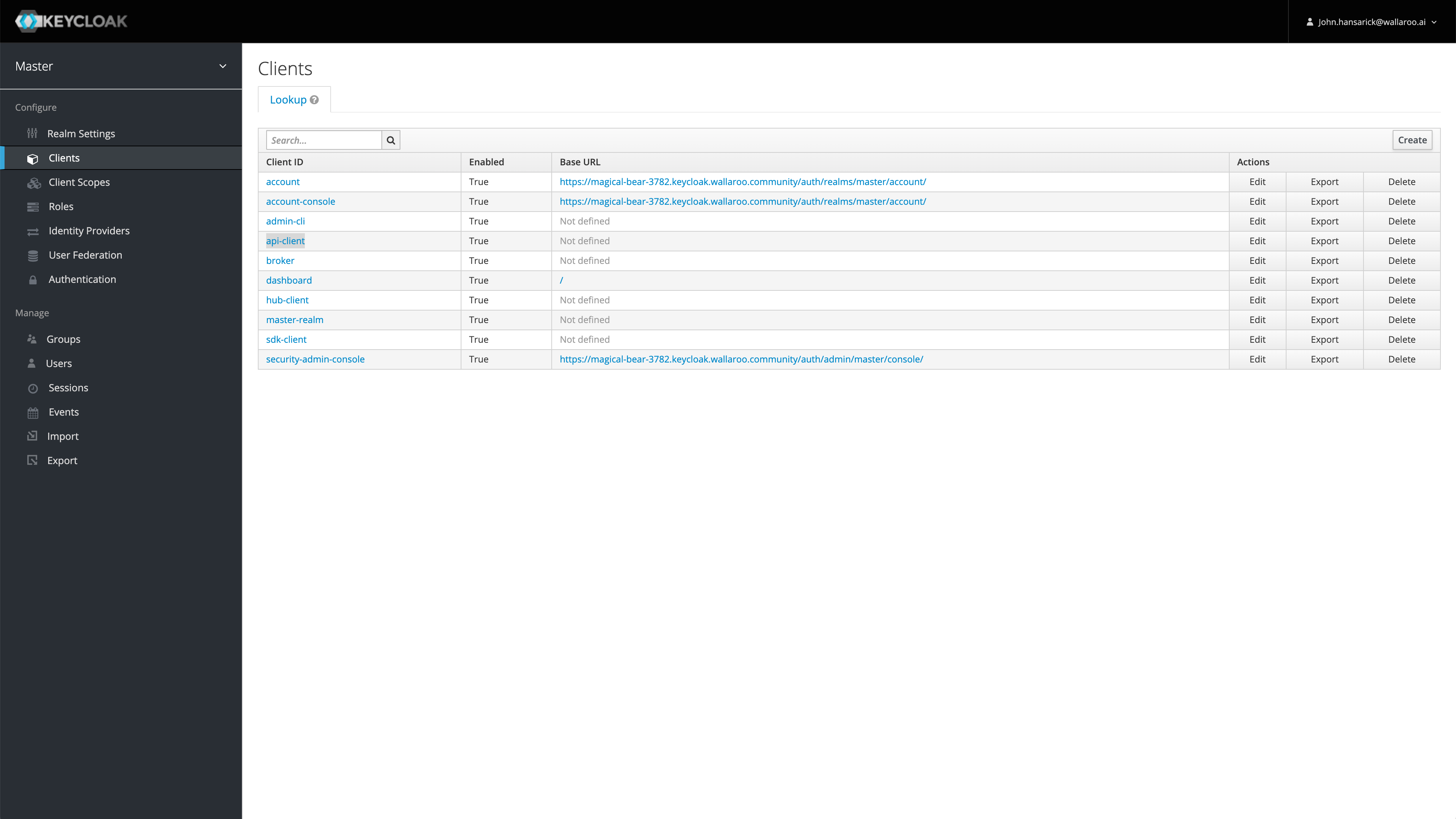
Wallaroo MLOps API Documentation from a Wallaroo instance: A Swagger UI based documentation is available from your Wallaroo instance at https://{Wallaroo Prefix.}api.{Wallaroo Suffix}/v1/api/docs. For example, if the Wallaroo Instance suffix is example.wallaroo.ai with the prefix {lovely-rhino-5555.}, then the Wallaroo MLOps API Documentation would be available at https://lovely-rhino-5555.api.example.wallaroo.ai/v1/api/docs. Note the . is part of the prefix.
For another example, a Wallaroo Enterprise users who do not use a prefix and has the suffix wallaroo.example.wallaroo.ai, the the Wallaroo MLOps API Documentation would be available at https://api.wallaroo.example.wallaroo.ai/v1/api/docs. For more information, see the Wallaroo Documentation Site.
IMPORTANT NOTE: The Wallaroo MLOps API is provided as an early access features. Future iterations may adjust the methods and returns to provide a better user experience. Please refer to this guide for updates.
Prerequisites
An installed Wallaroo instance.
The following Python libraries installed:
requests
json
wallaroo: The Wallaroo SDK. Included with the Wallaroo JupyterHub service by default.
pandas: Pandas, mainly used for Pandas DataFrame. Included with the Wallaroo JupyterHub service by default.
pyarrow: PyArrow for Apache Arrow support. Included with the Wallaroo JupyterHub service by default.
polars: Polars for DataFrame with native Apache Arrow support
OpenAPI Steps
The following demonstrates how to use each command in the Wallaroo MLOps API, and can be modified as best fits your organization’s needs.
Import Libraries
For the examples, the Python requests library will be used to make the REST HTTP(S) connections.
importwallaroofromwallaroo.objectimportEntityNotFoundErrorimportpandasaspdimportosimportpyarrowaspaimportrequestsfromrequests.authimportHTTPBasicAuthimportjson# used to display dataframe information without truncatingfromIPython.displayimportdisplaypd.set_option('display.max_colwidth', None)
Notes About This Guide
The following guide was established with set names for workspaces, pipelines, and models. Note that some commands, such as creating a workspace, will fail if another workspace is already created with the same name. Similar, if a user is already established with the same email address as in the examples below, etc.
To reduce errors, the following variables are declared. Please change them as required to avoid issues in an established Wallaroo environment.
For wallarooPrefix = "YOUR PREFIX." and wallarooSuffix = "YOUR SUFFIX", enter the prefix and suffix for your Wallaroo instance DNS name. If the prefix instance is blank, then it can be wallarooPrefix = "". Note that the prefix includes the . for proper formatting.
## Sample Variables Listnew_user="john.hansarick@wallaroo.ai"new_user_password="Snugglebunnies"example_workspace_name="apiworkspaces"model_name="apimodel"model_file_name="./models/ccfraud.onnx"stream_model_name="apiteststreammodel"stream_model_file_name="./models/ccfraud.onnx"empty_pipeline_name="pipelinenomodel"model_pipeline_name="pipelinemodels"example_copied_pipeline_name="copiedmodelpipeline"wallarooPrefix="YOUR PREFIX."wallarooSuffix="YOUR SUFFIX"# Retrieving login data through credential filef=open('./creds.json')
login_data=json.load(f)
Retrieve Credentials
Through Keycloak
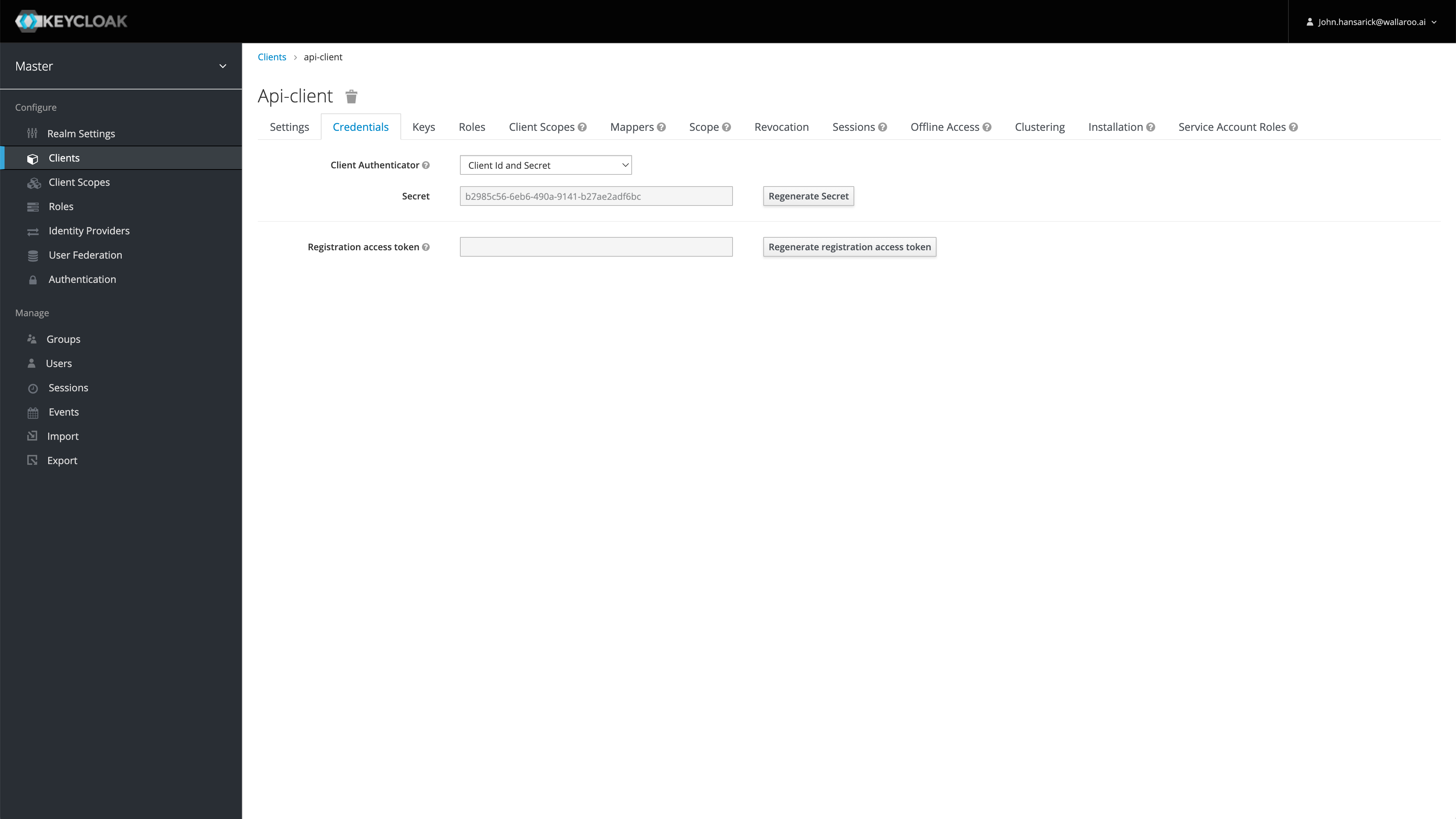
Wallaroo comes pre-installed with a confidential OpenID Connect client. The default client is api-client, but other clients may be created and configured.
Confidential clients require its secret to be supplied when requesting a token. Administrators may obtain their API client credentials from Keycloak from the Keycloak Service URL as listed above and the prefix /auth/admin/master/console/#/realms/master/clients.
For example, if the Wallaroo DNS address is in the format https://{WALLAROO PREFIX.}{WALLAROO SUFFIX}, then the direct path to the Keycloak API client credentials would be:
Then select the client, in this case api-client, then Credentials.
By default, tokens issued for api-client are valid for up to 60 minutes. Refresh tokens are supported.
Token Types
There are two tokens used with Wallaroo API services:
MLOps tokens: User tokens are generated with the confidential client credentials and the username/password of the Wallaroo user making the MLOps API request and requires:
The Wallaroo instance Keycloak address.
The confidential client, api-client by default.
The confidential client secret.
The Wallaroo username making the MLOps API request.
The Wallaroo user’s password.
This request return includes the access_token and the refresh_token. The access_token is used to authenticate. The refresh_token can be used to create a new token without submitting the original username and password.
Inference Token: Tokens used as part of a Pipeline Inference URL request. These do not require a Wallaroo user credentials. Inference token request require the following:
Replace the username, password, and email fields with the user account connecting to the Wallaroo instance. This allows a seamless connection to the Wallaroo instance and bypasses the standard browser based confirmation link. For more information, see the Wallaroo SDK Essentials Guide: Client Connection.
For wallarooPrefix = "YOUR PREFIX." and wallarooSuffix = "YOUR SUFFIX", enter the prefix and suffix for your Wallaroo instance DNS name. If the prefix instance is blank, then it can be wallarooPrefix = "". Note that the prefix includes the . for proper formatting.
# Retrieve the login credentials.os.environ["WALLAROO_SDK_CREDENTIALS"] ='./creds.json'# Client connection from local Wallaroo instancewallarooPrefix="YOUR PREFIX."wallarooSuffix="YOUR SUFFIX"wl=wallaroo.Client(api_endpoint=f"https://{wallarooPrefix}api.{wallarooSuffix}",
auth_endpoint=f"https://{wallarooPrefix}keycloak.{wallarooSuffix}",
auth_type="user_password")
API URL
The variable APIURL is used to specify the connection to the Wallaroo instance’s MLOps API URL.
# Get first user Keycloak id# Retrieve the token headers=wl.auth.auth_header()
# retrieved from the previous requestfirst_user_keycloak=list(response['users'])[0]
api_request=f"{APIURL}/v1/api/users/query"data= {
"user_ids": [
first_user_keycloak ]
}
response=requests.post(api_request, json=data, headers=headers, verify=True).json()
response
IMPORTANT NOTE: This command is for YOUR SUFFIX only. For more details on user management, see Wallaroo User Management.
Users are invited through /users/invite. When using YOUR SUFFIX, this will send an invitation email to the email address listed. Note that the user must not already be a member of the Wallaroo instance, and email addresses must be unique. If the email address is already in use for another user, the request will generate an error.
Parameters
email *(REQUIRED string): The email address of the new user to invite.
password(OPTIONAL string): The assigned password of the new user to invite. If not provided, the Wallaroo instance will provide the new user a temporary password that must be changed upon initial login.
Example: In this example, a new user will be invited to the Wallaroo instance and assigned a password.
When a new user logs in for the first time, they get an error when uploading a model or issues when they attempt to log in. How do I correct that?
When a new registered user attempts to upload a model, they may see the following error:
TransportQueryError:
{'extensions':
{'path':
'$.selectionSet.insert_workspace_one.args.object[0]', 'code': 'not-supported' },
'message':
'cannot proceed to insert array relations since insert to table "workspace" affects zero rows'
Or if they log into the Wallaroo Dashboard, they may see a Page not found error.
This is caused when a user has been registered without an appropriate email address. See the user guides here on inviting a user, or the Wallaroo Enterprise User Management on how to log into the Keycloak service and update users. Verify that the username and email address are both the same, and they are valid confirmed email addresses for the user.
2 - Wallaroo MLOps API Essentials Guide: Workspace Management
How to use the Wallaroo API for Workspace Management
Workspace Naming Requirements
Workspace names map onto Kubernetes objects, and must be DNS compliant. Workspace names must be ASCII alpha-numeric characters or dash (-) only. . and _ are not allowed.
Workspaces
List Workspaces
List the workspaces for a specific user.
Parameters
user_id - (OPTIONAL string): The Keycloak ID.
Example: In this example, the workspaces for all users will be displayed.
# List workspaces# Retrieve the token headers=wl.auth.auth_header()
api_request=f"{APIURL}/v1/api/workspaces/list"data= {
}
response=requests.post(api_request, json=data, headers=headers, verify=True).json()
response
A new workspace will be created in the Wallaroo instance. Upon creating, the workspace owner will be assigned as the user making the MLOps API request.
Parameters:
workspace_name - (REQUIRED string): The name of the new workspace with the following requirements:
Must be unique.
DNS compliant with only lowercase characters.
Returns:
workspace_id - (int): The ID of the new workspace.
Example: In this example, a workspace with the name testapiworkspace will be created, and the newly created workspace’s workspace_id saved as the variable example_workspace_id for use in other code examples. After the request is complete, the List Workspaces command will be issued to demonstrate the new workspace has been created.
Existing users of the Wallaroo instance can be added to an existing workspace.
Parameters
email - (REQUIRED string): The email address of the user to add to the workspace. This user must already exist in the Wallaroo instance.
workspace_id - (REQUIRED int): The id of the workspace.
Example: The following example adds the user created in Invite Users request to the workspace created in the Create Workspace request.
# Add existing user to existing workspace# Retrieve the token headers=wl.auth.auth_header()
api_request=f"{APIURL}/v1/api/workspaces/add_user"data= {
"email":new_user,
"workspace_id": example_workspace_id}
response=requests.post(api_request, json=data, headers=headers, verify=True).json()
response
{}
List Users in a Workspace
Lists the users who are either owners or collaborators of a workspace.
Parameters
workspace_id - (REQUIRED int): The id of the workspace.
Returns
user_id: The user’s Keycloak identification.
user_type: The user’s workspace type (owner, co-owner, etc).
Example: The following example will list all users part of the workspace created in the Create Workspace request.
# List users in a workspace# Retrieve the token headers=wl.auth.auth_header()
api_request=f"{APIURL}/v1/api/workspaces/list_users"data= {
"workspace_id": example_workspace_id}
response=requests.post(api_request, json=data, headers=headers, verify=True).json()
response
Removes the user from the given workspace. In this request, either the user’s Keycloak ID is required OR the user’s email address is required.
Parameters
workspace_id - (REQUIRED int): The id of the workspace.
user_id - (string): The Keycloak ID of the user. If email is not provided, then this parameter is REQUIRED.
email - (string): The user’s email address. If user_id is not provided, then this parameter is REQUIRED.
Returns
user_id: The user’s identification.
user_type: The user’s workspace type (owner, co-owner, etc).
Example: The following example will remove the newUser from workspace created in the Create Workspace request. Then the users for that workspace will be listed to verify newUser has been removed.
# Remove existing user from an existing workspace# Retrieve the token headers=wl.auth.auth_header()
api_request=f"{APIURL}/v1/api/workspaces/remove_user"data= {
"email":new_user,
"workspace_id": example_workspace_id}
response=requests.post(api_request, json=data, headers=headers, verify=True).json()
response
{'affected_rows': 1}
## List users in a workspace# Retrieve the token headers=wl.auth.auth_header()
api_request=f"{APIURL}/v1/api/users/query"data= {
"workspace_id": example_workspace_id}
response=requests.post(api_request, json=data, headers=headers, verify=True).json()
response
3 - Wallaroo MLOps API Essentials Guide: Model Management
How to use the Wallaroo API for Model Management
Model Naming Requirements
Model names map onto Kubernetes objects, and must be DNS compliant. The strings for model names must be ASCII alpha-numeric characters or dash (-) only. . and _ are not allowed.
Models
Upload Model to Workspace
ML Models are uploaded to Wallaroo through the following endpoint:
Models uploaded through this method that are not native runtimes are containerized within the Wallaroo instance then run by the Wallaroo engine. See Wallaroo MLOps API Essentials Guide: Pipeline Management for details on pipeline configurations and deployments.
For these models, the following inputs are required.
Endpoint:
/v1/api/models/upload_and_convert
Headers:
Content-Type: multipart/form-data
Parameters
name (StringRequired): The model name.
visibility (StringRequired): Either public or private.
workspace_id (StringRequired): The numerical ID of the workspace to upload the model to.
conversion (StringRequired): The conversion parameters that include the following:
framework (StringRequired): The framework of the model being uploaded. See the list of supported models for more details.
python_version (StringRequired): The version of Python required for model.
requirements (StringRequired): Required libraries. Can be [] if the requirements are default Wallaroo JupyterHub libraries.
input_schema (StringOptional): The input schema from the Apache Arrow pyarrow.lib.Schema format, encoded with base64.b64encode. Only required for non-native runtime models.
output_schema (StringOptional): The output schema from the Apache Arrow pyarrow.lib.Schema format, encoded with base64.b64encode. Only required for non-native runtime models.
Upload Native Runtime Model Example
ONNX are always native runtimes. The following example shows uploading an ONNX model to a Wallaroo instance using the requests library. Note that the input_schema and output_schema encoded details are not required.
The following example shows uploading a Hugging Face model to a Wallaroo instance using the requests library. Note that the input_schema and output_schema encoded details are required.
input_schema=pa.schema([
pa.field('inputs', pa.string()), # requiredpa.field('candidate_labels', pa.list_(pa.string(), list_size=2)), # requiredpa.field('hypothesis_template', pa.string()), # optionalpa.field('multi_label', pa.bool_()), # optional])
output_schema=pa.schema([
pa.field('sequence', pa.string()),
pa.field('scores', pa.list_(pa.float64(), list_size=2)), # same as number of candidate labels, list_size can be skipped by may result in slightly worse performancepa.field('labels', pa.list_(pa.string(), list_size=2)), # same as number of candidate labels, list_size can be skipped by may result in slightly worse performance])
encoded_input_schema=base64.b64encode(
bytes(input_schema.serialize())
).decode("utf8")
encoded_output_schema=base64.b64encode(
bytes(output_schema.serialize())
).decode("utf8")
metadata= {
"name": model_name,
"visibility": "private",
"workspace_id": workspace_id,
"conversion": {
"framework": framework,
"python_version": "3.8",
"requirements": []
},
"input_schema": encoded_input_schema,
"output_schema": encoded_output_schema,
}
headers=wl.auth.auth_header()
files= {
'metadata': (None, json.dumps(metadata), "application/json"),
'file': (model_name, open(model_path,'rb'),'application/octet-stream')
}
response=requests.post('https://{APIURL}/v1/api/models/upload_and_convert',
headers=headers,
files=files).json()
Stream Upload Model to Workspace
Streams a potentially large ML Model to a Wallaroo workspace via POST with Content-Type: multipart/form-data.
Parameters
name - (REQUIRED string): Name of the model. Must only include alphanumeric characters.
filename - (REQUIRED string): Name of the file being uploaded.
visibility - (OPTIONAL string): The visibility of the model as either public or private.
workspace_id - (REQUIRED int): The numerical id of the workspace to upload the model to.
Example: This example will upload the sample file ccfraud.onnx to the workspace created in the Create Workspace step as apitestmodel.
# stream upload model - next test is adding arbitrary chunks to the stream# Retrieve the token headers=wl.auth.auth_header()
# Set the contentTypeheaders['contentType']='application/octet-stream'api_request=f"{APIURL}/v1/api/models/upload_stream"# Model name and file to usedisplay(f"Sample stream model name: {stream_model_name}")
display(f"Sample model file: {stream_model_file_name}")
data= {
"name":stream_model_name,
"filename": stream_model_file_name,
"visibility":"public",
"workspace_id": example_workspace_id}
files= {
'file': (stream_model_name, open(stream_model_file_name, 'rb'))
}
response=requests.post(apiRequest, files=files, data=data, headers=headers).json()
response
Returns a list of models added to a specific workspace.
Parameters
workspace_id - (REQUIRED int): The workspace id to list.
Example: Display the models for the workspace used in the Upload Model to Workspace step. The model id and model name will be saved as example_model_id and exampleModelName variables for other examples.
# List models in a workspace# Retrieve the token headers=wl.auth.auth_header()
api_request=f"{APIURL}/v1/api/models/list"data= {
"workspace_id": example_workspace_id}
response=requests.post(api_request, json=data, headers=headers, verify=True).json()
response
Returns the model details by the specific model id.
Parameters
workspace_id - (REQUIRED int): The workspace id to list.
Returns
id - (int): Numerical id of the model.
owner_id - (string): Id of the owner of the model.
workspace_id - (int): Numerical of the id the model is in.
name - (string): Name of the model.
updated_at - (DateTime): Date and time of the model’s last update.
created_at - (DateTime): Date and time of the model’s creation.
model_config - (string): Details of the model’s configuration.
Example: Retrieve the details for the model uploaded in the Upload Model to Workspace step.
# Get model details by id# Retrieve the token headers=wl.auth.auth_header()
api_request=f"{APIURL}/v1/api/models/get_by_id"data= {
"id": example_model_id}
response=requests.post(api_request, json=data, headers=headers, verify=True).json()
response
Retrieves all versions of a model based on either the name of the model or the model_pk_id.
Parameters
model_id - (REQUIRED String): The model name.
models_pk_id - (REQUIRED int): The model integer pk id.
Returns
Array(Model Details)
sha - (String): The sha hash of the model version.
models_pk_id- (int): The pk id of the model.
model_version - (String): The UUID identifier of the model version.
owner_id - (String): The Keycloak user id of the model’s owner.
model_id - (String): The name of the model.
id - (int): The integer id of the model.
file_name - (String): The filename used when uploading the model.
image_path - (String): The image path of the model.
Example: Retrieve the versions for a previously uploaded model. The variables example_model_version and example_model_sha will store the model’s version and SHA values for use in other examples.
## List model versions# Retrieve the token headers=wl.auth.auth_header()
api_request=f"{APIURL}/v1/api/models/list_versions"data= {
"model_id": model_name,
"models_pk_id": example_model_id}
response=requests.post(api_request, json=data, headers=headers, verify=True).json()
response
# Stored for future examplesexample_model_version=response[-1]['model_version']
example_model_sha=response[-1]['sha']
Get Model Configuration by Id
Returns the model’s configuration details.
Parameters
model_id - (REQUIRED int): The numerical value of the model’s id.
Example: Submit the model id for the model uploaded in the Upload Model to Workspace step to retrieve configuration details.
## Get model config by id# Retrieve the token headers=wl.auth.auth_header()
api_request=f"{APIURL}/v1/api/models/get_config_by_id"data= {
"model_id": example_model_id}
response=requests.post(api_request, json=data, headers=headers, verify=True).json()
response
{'model_config': None}
Get Model Details
Returns details regarding a single model, including versions.
Returns the model’s configuration details.
Parameters
model_id - (REQUIRED int): The numerical value of the model’s id.
Example: Submit the model id for the model uploaded in the Upload Model to Workspace step to retrieve configuration details.
# Get model config by id# Retrieve the token headers=wl.auth.auth_header()
api_request=f"{APIURL}/v1/api/models/get"data= {
"id": example_model_id}
response=requests.post(api_request, json=data, headers=headers, verify=True).json()
response
4 - Wallaroo MLOps API Essentials Guide: Model Registry
How to use the Wallaroo API for Model Registry aka Artifact Registries
Wallaroo users can register their trained machine learning models from a model registry into their Wallaroo instance and perform inferences with it through a Wallaroo pipeline.
This guide details how to add ML Models from a model registry service into a Wallaroo instance.
Artifact Requirements
Models are uploaded to the Wallaroo instance as the specific artifact - the “file” or other data that represents the file itself. This must comply with the Wallaroo model requirements framework and version or it will not be deployed. Note that for models that fall outside of the supported model types, they can be registered to a Wallaroo workspace as MLFlow 1.30.0 containerized models.
Supported Models
The following frameworks are supported. Frameworks fall under either Native or Containerized runtimes in the Wallaroo engine. For more details, see the specific framework what runtime a specific model framework runs in.
The supported frameworks include the specific version of the model framework supported by Wallaroo. It is highly recommended to verify that models uploaded to Wallaroo meet the library and version requirements to ensure proper functioning.
After April 2022 until release 2022.4 (December 2022)
1.10.*
7
15
2
Before April 2022
1.6.*
7
13
2
For the most recent release of Wallaroo 2023.2.1, the following native runtimes are supported:
If converting another ML Model to ONNX (PyTorch, XGBoost, etc) using the onnxconverter-common library, the supported DEFAULT_OPSET_NUMBER is 17.
Using different versions or settings outside of these specifications may result in inference issues and other unexpected behavior.
ONNX models always run in the native runtime space.
Data Schemas
ONNX models deployed to Wallaroo have the following data requirements.
Equal rows constraint: The number of input rows and output rows must match.
All inputs are tensors: The inputs are tensor arrays with the same shape.
Data Type Consistency: Data types within each tensor are of the same type.
Equal Rows Constraint
Inference performed through ONNX models are assumed to be in batch format, where each input row corresponds to an output row. This is reflected in the in fields returned for an inference. In the following example, each input row for an inference is related directly to the inference output.
For models that require ragged tensor or other shapes, see other data formatting options such as Bring Your Own Predict models.
Data Type Consistency
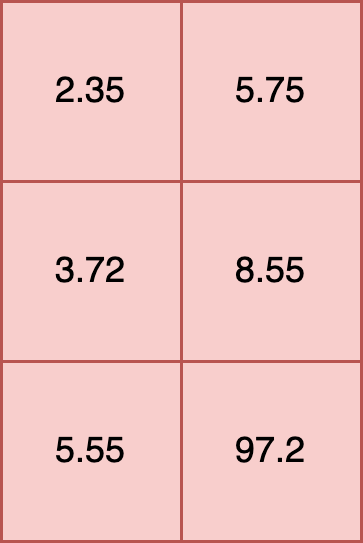
All inputs into an ONNX model must have the same internal data type. For example, the following is valid because all of the data types within each element are float32.
t= [
[2.35, 5.75],
[3.72, 8.55],
[5.55, 97.2]
]
The following is invalid, as it mixes floats and strings in each element:
These requirements are <strong>not</strong> for Tensorflow Keras models, only for non-Keras Tensorflow models in the SavedModel format. For Tensorflow Keras deployment in Wallaroo, see the Tensorflow Keras requirements.
TensorFlow File Format
TensorFlow models are .zip file of the SavedModel format. For example, the Aloha sample TensorFlow model is stored in the directory alohacnnlstm:
Python models uploaded to Wallaroo are executed as a native runtime.
Note that Python models - aka “Python steps” - are standalone python scripts that use the python libraries natively supported by the Wallaroo platform. These are used for either simple model deployment (such as ARIMA Statsmodels), or data formatting such as the postprocessing steps. A Wallaroo Python model will be composed of one Python script that matches the Wallaroo requirements.
This is contrasted with Arbitrary Python models, also known as Bring Your Own Predict (BYOP) allow for custom model deployments with supporting scripts and artifacts. These are used with pre-trained models (PyTorch, Tensorflow, etc) along with whatever supporting artifacts they require. Supporting artifacts can include other Python modules, model files, etc. These are zipped with all scripts, artifacts, and a requirements.txt file that indicates what other Python models need to be imported that are outside of the typical Wallaroo platform.
Python Models Requirements
Python models uploaded to Wallaroo are Python scripts that must include the wallaroo_json method as the entry point for the Wallaroo engine to use it as a Pipeline step.
This method receives the results of the previous Pipeline step, and its return value will be used in the next Pipeline step.
If the Python model is the first step in the pipeline, then it will be receiving the inference request data (for example: a preprocessing step). If it is the last step in the pipeline, then it will be the data returned from the inference request.
In the example below, the Python model is used as a post processing step for another ML model. The Python model expects to receive data from a ML Model who’s output is a DataFrame with the column dense_2. It then extracts the values of that column as a list, selects the first element, and returns a DataFrame with that element as the value of the column output.
In line with other Wallaroo inference results, the outputs of a Python step that returns a pandas DataFrame or Arrow Table will be listed in the out. metadata, with all inference outputs listed as out.{variable 1}, out.{variable 2}, etc. In the example above, this results the output field as the out.output field in the Wallaroo inference result.
Input and output schemas for each Hugging Face pipeline are defined below. Note that adding additional inputs not specified below will raise errors, except for the following:
Framework.HUGGING-FACE-IMAGE-TO-TEXT
Framework.HUGGING-FACE-TEXT-CLASSIFICATION
Framework.HUGGING-FACE-SUMMARIZATION
Framework.HUGGING-FACE-TRANSLATION
Additional inputs added to these Hugging Face pipelines will be added as key/pair value arguments to the model’s generate method. If the argument is not required, then the model will default to the values coded in the original Hugging Face model’s source code.
Any parameter that is not part of the required inputs list will be forwarded to the model as a key/pair value to the underlying models generate method. If the additional input is not supported by the model, an error will be returned.
Any parameter that is not part of the required inputs list will be forwarded to the model as a key/pair value to the underlying models generate method. If the additional input is not supported by the model, an error will be returned.
Schemas:
input_schema=pa.schema([
pa.field('inputs', pa.string()),
pa.field('return_text', pa.bool_()),
pa.field('return_tensors', pa.bool_()),
pa.field('clean_up_tokenization_spaces', pa.bool_()),
# pa.field('extra_field', pa.int64()), # every extra field you specify will be forwarded as a key/value pair])
output_schema=pa.schema([
pa.field('summary_text', pa.string()),
])
input_schema=pa.schema([
pa.field('inputs', pa.string()), # requiredpa.field('top_k', pa.int64()), # optionalpa.field('function_to_apply', pa.string()), # optional])
output_schema=pa.schema([
pa.field('label', pa.list_(pa.string(), list_size=2)), # list with a number of items same as top_k, list_size can be skipped but may lead in worse performancepa.field('score', pa.list_(pa.float64(), list_size=2)), # list with a number of items same as top_k, list_size can be skipped but may lead in worse performance])
Any parameter that is not part of the required inputs list will be forwarded to the model as a key/pair value to the underlying models generate method. If the additional input is not supported by the model, an error will be returned.
Schemas:
input_schema=pa.schema([
pa.field('inputs', pa.string()), # requiredpa.field('return_tensors', pa.bool_()), # optionalpa.field('return_text', pa.bool_()), # optionalpa.field('clean_up_tokenization_spaces', pa.bool_()), # optionalpa.field('src_lang', pa.string()), # optionalpa.field('tgt_lang', pa.string()), # optional# pa.field('extra_field', pa.int64()), # every extra field you specify will be forwarded as a key/value pair])
output_schema=pa.schema([
pa.field('translation_text', pa.string()),
])
input_schema=pa.schema([
pa.field('inputs', pa.string()), # requiredpa.field('candidate_labels', pa.list_(pa.string(), list_size=2)), # requiredpa.field('hypothesis_template', pa.string()), # optionalpa.field('multi_label', pa.bool_()), # optional])
output_schema=pa.schema([
pa.field('sequence', pa.string()),
pa.field('scores', pa.list_(pa.float64(), list_size=2)), # same as number of candidate labels, list_size can be skipped by may result in slightly worse performancepa.field('labels', pa.list_(pa.string(), list_size=2)), # same as number of candidate labels, list_size can be skipped by may result in slightly worse performance])
input_schema=pa.schema([
pa.field('images',
pa.list_(
pa.list_(
pa.list_(
pa.int64(),
list_size=3 ),
list_size=640 ),
list_size=480 )),
pa.field('candidate_labels', pa.list_(pa.string(), list_size=3)),
pa.field('threshold', pa.float64()),
# pa.field('top_k', pa.int64()), # we want the model to return exactly the number of predictions, we shouldn't specify this])
output_schema=pa.schema([
pa.field('score', pa.list_(pa.float64())), # variable output, depending on detected objectspa.field('label', pa.list_(pa.string())), # variable output, depending on detected objectspa.field('box',
pa.list_( # dynamic output, i.e. dynamic number of boxes per input image, each sublist contains the 4 box coordinates pa.list_(
pa.int64(),
list_size=4 ),
),
),
])
Any parameter that is not part of the required inputs list will be forwarded to the model as a key/pair value to the underlying models generate method. If the additional input is not supported by the model, an error will be returned.
input_schema=pa.schema([
pa.field('inputs', pa.string()),
pa.field('return_tensors', pa.bool_()), # optionalpa.field('return_text', pa.bool_()), # optionalpa.field('return_full_text', pa.bool_()), # optionalpa.field('clean_up_tokenization_spaces', pa.bool_()), # optionalpa.field('prefix', pa.string()), # optionalpa.field('handle_long_generation', pa.string()), # optional# pa.field('extra_field', pa.int64()), # every extra field you specify will be forwarded as a key/value pair])
output_schema=pa.schema([
pa.field('generated_text', pa.list_(pa.string(), list_size=1))
])
SKLearn schema follows a different format than other models. To prevent inputs from being out of order, the inputs should be submitted in a single row in the order the model is trained to accept, with all of the data types being the same. For example, the following DataFrame has 4 columns, each column a float.
sepal length (cm)
sepal width (cm)
petal length (cm)
petal width (cm)
0
5.1
3.5
1.4
0.2
1
4.9
3.0
1.4
0.2
For submission to an SKLearn model, the data input schema will be a single array with 4 float values.
When submitting as an inference, the DataFrame is converted to rows with the column data expressed as a single array. The data must be in the same order as the model expects, which is why the data is submitted as a single array rather than JSON labeled columns: this insures that the data is submitted in the exact order as the model is trained to accept.
Original DataFrame:
sepal length (cm)
sepal width (cm)
petal length (cm)
petal width (cm)
0
5.1
3.5
1.4
0.2
1
4.9
3.0
1.4
0.2
Converted DataFrame:
inputs
0
[5.1, 3.5, 1.4, 0.2]
1
[4.9, 3.0, 1.4, 0.2]
SKLearn Schema Outputs
Outputs for SKLearn that are meant to be predictions or probabilities when output by the model are labeled in the output schema for the model when uploaded to Wallaroo. For example, a model that outputs either 1 or 0 as its output would have the output schema as follows:
TensorFlow Keras SavedModel models are .zip file of the SavedModel format. For example, the Aloha sample TensorFlow model is stored in the directory alohacnnlstm:
XGBoost schema follows a different format than other models. To prevent inputs from being out of order, the inputs should be submitted in a single row in the order the model is trained to accept, with all of the data types being the same. If a model is originally trained to accept inputs of different data types, it will need to be retrained to only accept one data type for each column - typically pa.float64() is a good choice.
For example, the following DataFrame has 4 columns, each column a float.
sepal length (cm)
sepal width (cm)
petal length (cm)
petal width (cm)
0
5.1
3.5
1.4
0.2
1
4.9
3.0
1.4
0.2
For submission to an XGBoost model, the data input schema will be a single array with 4 float values.
When submitting as an inference, the DataFrame is converted to rows with the column data expressed as a single array. The data must be in the same order as the model expects, which is why the data is submitted as a single array rather than JSON labeled columns: this insures that the data is submitted in the exact order as the model is trained to accept.
Original DataFrame:
sepal length (cm)
sepal width (cm)
petal length (cm)
petal width (cm)
0
5.1
3.5
1.4
0.2
1
4.9
3.0
1.4
0.2
Converted DataFrame:
inputs
0
[5.1, 3.5, 1.4, 0.2]
1
[4.9, 3.0, 1.4, 0.2]
XGBoost Schema Outputs
Outputs for XGBoost are labeled based on the trained model outputs. For this example, the output is simply a single output listed as output. In the Wallaroo inference result, it is grouped with the metadata out as out.output.
Arbitrary Python models, also known as Bring Your Own Predict (BYOP) allow for custom model deployments with supporting scripts and artifacts. These are used with pre-trained models (PyTorch, Tensorflow, etc) along with whatever supporting artifacts they require. Supporting artifacts can include other Python modules, model files, etc. These are zipped with all scripts, artifacts, and a requirements.txt file that indicates what other Python models need to be imported that are outside of the typical Wallaroo platform.
Contrast this with Wallaroo Python models - aka “Python steps”. These are standalone python scripts that use the python libraries natively supported by the Wallaroo platform. These are used for either simple model deployment (such as ARIMA Statsmodels), or data formatting such as the postprocessing steps. A Wallaroo Python model will be composed of one Python script that matches the Wallaroo requirements.
Arbitrary Python File Requirements
Arbitrary Python (BYOP) models are uploaded to Wallaroo via a ZIP file with the following components:
Artifact
Type
Description
Python scripts aka .py files with classes that extend mac.inference.Inference and mac.inference.creation.InferenceBuilder
Python Script
Extend the classes mac.inference.Inference and mac.inference.creation.InferenceBuilder. These are included with the Wallaroo SDK. Further details are in Arbitrary Python Script Requirements. Note that there is no specified naming requirements for the classes that extend mac.inference.Inference and mac.inference.creation.InferenceBuilder - any qualified class name is sufficient as long as these two classes are extended as defined below.
requirements.txt
Python requirements file
This sets the Python libraries used for the arbitrary python model. These libraries should be targeted for Python 3.8 compliance. These requirements and the versions of libraries should be exactly the same between creating the model and deploying it in Wallaroo. This insures that the script and methods will function exactly the same as during the model creation process.
Other artifacts
Files
Other models, files, and other artifacts used in support of this model.
For example, the if the arbitrary python model will be known as vgg_clustering, the contents may be in the following structure, with vgg_clustering as the storage directory:
Note the inclusion of the custom_inference.py file. This file name is not required - any Python script or scripts that extend the classes listed above are sufficient. This Python script could have been named vgg_custom_model.py or any other name as long as it includes the extension of the classes listed above.
The sample arbitrary python model file is created with the command zip -r vgg_clustering.zip vgg_clustering/.
Wallaroo Arbitrary Python uses the Wallaroo SDK mac module, included in the Wallaroo SDK 2023.2.1 and above. See the Wallaroo SDK Install Guides for instructions on installing the Wallaroo SDK.
Arbitrary Python Script Requirements
The entry point of the arbitrary python model is any python script that extends the following classes. These are included with the Wallaroo SDK. The required methods that must be overridden are specified in each section below.
mac.inference.Inference interface serves model inferences based on submitted input some input. Its purpose is to serve inferences for any supported arbitrary model framework (e.g. scikit, keras etc.).
classDiagram
class Inference {
<<Abstract>>
+model Optional[Any]
+expected_model_types()* Set
+predict(input_data: InferenceData)* InferenceData
-raise_error_if_model_is_not_assigned() None
-raise_error_if_model_is_wrong_type() None
}
mac.inference.creation.InferenceBuilder builds a concrete Inference, i.e. instantiates an Inference object, loads the appropriate model and assigns the model to to the Inference object.
classDiagram
class InferenceBuilder {
+create(config InferenceConfig) * Inference
-inference()* Any
}
mac.inference.Inference
mac.inference.Inference Objects
Object
Type
Description
model Optional[Any]
An optional list of models that match the supported frameworks from wallaroo.framework.Framework included in the arbitrary python script. Note that this is optional - no models are actually required. A BYOP can refer to a specific model(s) used, be used for data processing and reshaping for later pipeline steps, or other needs.
mac.inference.Inference Methods
Method
Returns
Description
expected_model_types (Required)
Set
Returns a Set of models expected for the inference as defined by the developer. Typically this is a set of one. Wallaroo checks the expected model types to verify that the model submitted through the InferenceBuilder method matches what this Inference class expects.
The entry point for the Wallaroo inference with the following input and output parameters that are defined when the model is updated.
mac.types.InferenceData: The inputInferenceData is a dictionary of numpy arrays derived from the input_schema detailed when the model is uploaded, defined in PyArrow.Schema format.
mac.types.InferenceData: The output is a dictionary of numpy arrays as defined by the output parameters defined in PyArrow.Schema format.
The InferenceDataValidationError exception is raised when the input data does not match mac.types.InferenceData.
raise_error_if_model_is_not_assigned
N/A
Error when expected_model_types is not set.
raise_error_if_model_is_wrong_type
N/A
Error when the model does not match the expected_model_types.
mac.inference.creation.InferenceBuilder
InferenceBuilder builds a concrete Inference, i.e. instantiates an Inference object, loads the appropriate model and assigns the model to the Inference.
classDiagram
class InferenceBuilder {
+create(config InferenceConfig) * Inference
-inference()* Any
}
Each model that is included requires its own InferenceBuilder. InferenceBuilder loads one model, then submits it to the Inference class when created. The Inference class checks this class against its expected_model_types() Set.
Creates an Inference subclass, then assigns a model and attributes. The CustomInferenceConfig is used to retrieve the config.model_path, which is a pathlib.Path object pointing to the folder where the model artifacts are saved. Every artifact loaded must be relative to config.model_path. This is set when the arbitrary python .zip file is uploaded and the environment for running it in Wallaroo is set. For example: loading the artifact vgg_clustering\feature_extractor.h5 would be set with config.model_path \ feature_extractor.h5. The model loaded must match an existing module. For our example, this is from sklearn.cluster import KMeans, and this must match the Inferenceexpected_model_types.
inference
custom Inference instance.
Returns the instantiated custom Inference object created from the create method.
Arbitrary Python Runtime
Arbitrary Python always run in the containerized model runtime.
Wallaroo users can register their trained MLFlow ML Models from a containerized model container registry into their Wallaroo instance and perform inferences with it through a Wallaroo pipeline.
As of this time, Wallaroo only supports MLFlow 1.30.0 containerized models. For information on how to containerize an MLFlow model, see the MLFlow Documentation.
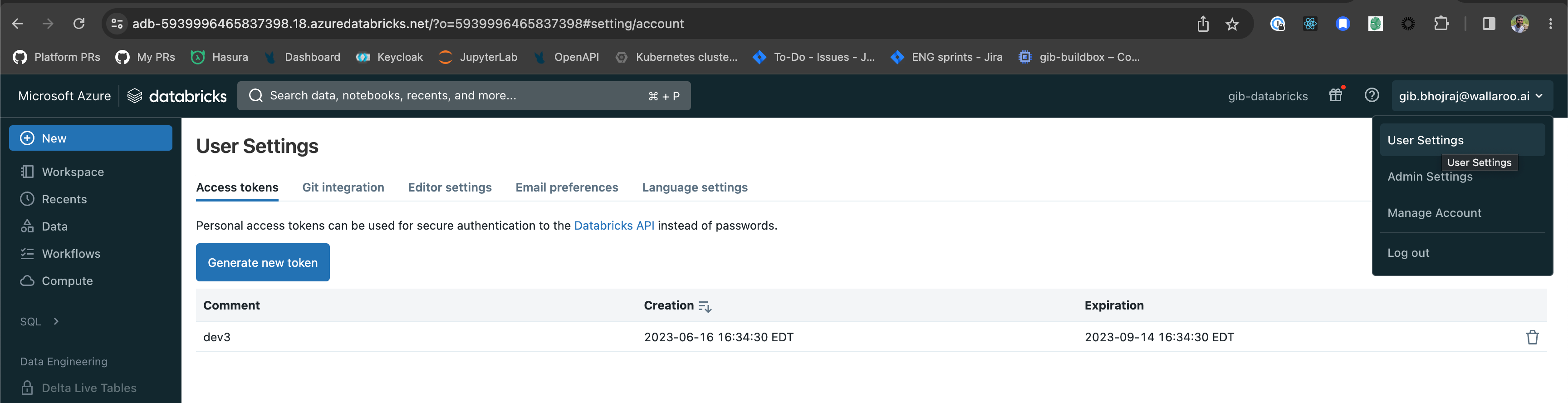
The following steps create an Access Token used to authenticate to an Azure Databricks Model Registry.
Log into the Azure Databricks workspace.
From the upper right corner access the User Settings.
From the Access tokens, select Generate new token.
Specify any token description and lifetime. Once complete, select Generate.
Copy the token and store in a secure place. Once the Generate New Token module is closed, the token will not be retrievable.
The MLflow Model Registry provides a method of setting up a model registry service. Full details can be found at the MLflow Registry Quick Start Guide.
A generic MLFlow model registry requires no token.
Wallaroo Registry Operations
Connect Model Registry to Wallaroo: This details the link and connection information to a existing MLFlow registry service. Note that this does not create a MLFlow registry service, but adds the connection and credentials to Wallaroo to allow that MLFlow registry service to be used by other entities in the Wallaroo instance.
Add a Registry to a Workspace: Add the created Wallaroo Model Registry so make it available to other workspace members.
Remove a Registry from a Workspace: Remove the link between a Wallaroo Model Registry and a Wallaroo workspace.
Connect Model Registry to Wallaroo
MLFlow Registry connection information is added to a Wallaroo instance through the following endpoint.
REQUEST URL
v1/api/models/create_registry
PARAMETERS
workspace_id (IntegerRequired): The numerical ID of the workspace to create the registry in.
name (StringRequired): The name for the registry. Registry names are not unique.
url (StringRequired): The full URL of the registry service. For example: https://registry.wallaroo.ai
token (StringRequired): The authentication token used by the registry service.
RETURNS
id (String): The UUID of the registry.
workspace_id: The numerical ID of the workspace the registry was connected to.
Connect Model Registry to Wallaroo Example
The following registry will be added to the workspace with the id 1.
Registries are assigned to a Wallaroo workspace with the following endpoint. This allows members of the workspace to access the registry connection. A registry can be associated with one or more workspaces.
Registries are removed from a registry with the following endpoint. This does not remove the registry connection information from the Wallaroo instance, merely removes the association between the registry and that particular workspace.
latest_versions (List): The list of other versions of the model. If there are no other versions of the model, this will be None. Each version has the following fields.
name (String): The name of the artifact.
description (String): The description of the artifact.
version (Integer): The version number. Other versions may be removed from the registry, so it is possible for a version to be higher than 1 even if there are no other versions still stored in the registry.
status (String): The current status of the model.
run_id (String): The run id from the MLFlow service that created the model.
run_link (String): Link to the run from the MLFlow service that created the model.
source (String): The URL for the specific version artifact on this registry service. For example: 'dbfs:/databricks/mlflow-tracking/123456/abcdefg/artifacts/random_forest_model'.
current_stage (String): The current stage of the model version.
creation_timestamp (Integer): Creation timestamp in milliseconds since the Unix epoch.
last_updated_timestamp (Integer): Last updated timestamp in milliseconds since the Unix epoch.
registry_id (StringRequired): The registry ID in UUID format.
name (StringRequired): The name of the model to retrieve artifacts from.
version (StringRequired): The version of the model to retrieve artifacts from.
RETURNS
List of artifacts with the following fields.
file_size (Integer): The size of the file in bytes.
full_path (String): The full path to the artifact. For example: https://adb-5939996465837398.18.azuredatabricks.net/api/2.0/dbfs/read?path=/databricks/mlflow-registry/9f38797c1dbf4e7eb229c4011f0f1f18/models/testmodel2/model.pkl
is_dir (Boolean): Whether the artifact is a directory or file.
modification_time (Integer): Last modification timestamp in milliseconds since the Unix epoch
path (String): Relative path to the artifact within the registry. For example: /databricks/mlflow-registry/9f38797c1dbf4e7eb229c4011f0f1f18/models/testmodel2/model.pkl
Models are uploaded from a model registry configured in Wallaroo through the following endpoint. The specific artifact that is the model to be deployed is the item to upload to the Wallaroo workspace. Models must comply with Wallaroo model framework and versions as defined in Artifact Requirements.
REQUEST URL
v1/api/models/upload_from_registry
PARAMETERS
registry_id (StringRequired): The registry ID in UUID format.
name (StringRequired): The name to assign the model in Wallaroo. Model names map onto Kubernetes objects, and must be DNS compliant. The strings for model names must be ASCII alpha-numeric characters or dash (-) only. . and _ are not allowed.
path (StringRequired): URL of the model to upload as specified in List Models in a Registrysource field.
visibility (StringRequired): Whether the model is public or private.
workspace_id (IntegerRequired): The numerical id of the workspace to upload the model to.
conversion (StringRequired): The conversion parameters that include the following:
framework (StringRequired): The framework of the model being uploaded. See the list of supported models for more details.
python_version (StringRequired): The version of Python required for model.
requirements (StringRequired): Required libraries. Can be [] if the requirements are default Wallaroo JupyterHub libraries.
input_schema (StringOptional): The input schema from the Apache Arrow pyarrow.lib.Schema format, encoded with base64.b64encode. Only required for non-native runtime models.
output_schema (StringOptional): The output schema from the Apache Arrow pyarrow.lib.Schema format, encoded with base64.b64encode. Only required for non-native runtime models.
RETURNS
model_id (String): The numerical id of the model uploaded
5 - Wallaroo MLOps API Essentials Guide: Model Upload and Registrations
How to use the Wallaroo API to upload models of different frameworks.
Models are uploaded or registered to a Wallaroo workspace depending on the model framework and type.
Supported Models
The following frameworks are supported. Frameworks fall under either Native or Containerized runtimes in the Wallaroo engine. For more details, see the specific framework what runtime a specific model framework runs in.
The supported frameworks include the specific version of the model framework supported by Wallaroo. It is highly recommended to verify that models uploaded to Wallaroo meet the library and version requirements to ensure proper functioning.
After April 2022 until release 2022.4 (December 2022)
1.10.*
7
15
2
Before April 2022
1.6.*
7
13
2
For the most recent release of Wallaroo 2023.2.1, the following native runtimes are supported:
If converting another ML Model to ONNX (PyTorch, XGBoost, etc) using the onnxconverter-common library, the supported DEFAULT_OPSET_NUMBER is 17.
Using different versions or settings outside of these specifications may result in inference issues and other unexpected behavior.
ONNX models always run in the native runtime space.
Data Schemas
ONNX models deployed to Wallaroo have the following data requirements.
Equal rows constraint: The number of input rows and output rows must match.
All inputs are tensors: The inputs are tensor arrays with the same shape.
Data Type Consistency: Data types within each tensor are of the same type.
Equal Rows Constraint
Inference performed through ONNX models are assumed to be in batch format, where each input row corresponds to an output row. This is reflected in the in fields returned for an inference. In the following example, each input row for an inference is related directly to the inference output.
For models that require ragged tensor or other shapes, see other data formatting options such as Bring Your Own Predict models.
Data Type Consistency
All inputs into an ONNX model must have the same internal data type. For example, the following is valid because all of the data types within each element are float32.
t= [
[2.35, 5.75],
[3.72, 8.55],
[5.55, 97.2]
]
The following is invalid, as it mixes floats and strings in each element:
These requirements are <strong>not</strong> for Tensorflow Keras models, only for non-Keras Tensorflow models in the SavedModel format. For Tensorflow Keras deployment in Wallaroo, see the Tensorflow Keras requirements.
TensorFlow File Format
TensorFlow models are .zip file of the SavedModel format. For example, the Aloha sample TensorFlow model is stored in the directory alohacnnlstm:
Python models uploaded to Wallaroo are executed as a native runtime.
Note that Python models - aka “Python steps” - are standalone python scripts that use the python libraries natively supported by the Wallaroo platform. These are used for either simple model deployment (such as ARIMA Statsmodels), or data formatting such as the postprocessing steps. A Wallaroo Python model will be composed of one Python script that matches the Wallaroo requirements.
This is contrasted with Arbitrary Python models, also known as Bring Your Own Predict (BYOP) allow for custom model deployments with supporting scripts and artifacts. These are used with pre-trained models (PyTorch, Tensorflow, etc) along with whatever supporting artifacts they require. Supporting artifacts can include other Python modules, model files, etc. These are zipped with all scripts, artifacts, and a requirements.txt file that indicates what other Python models need to be imported that are outside of the typical Wallaroo platform.
Python Models Requirements
Python models uploaded to Wallaroo are Python scripts that must include the wallaroo_json method as the entry point for the Wallaroo engine to use it as a Pipeline step.
This method receives the results of the previous Pipeline step, and its return value will be used in the next Pipeline step.
If the Python model is the first step in the pipeline, then it will be receiving the inference request data (for example: a preprocessing step). If it is the last step in the pipeline, then it will be the data returned from the inference request.
In the example below, the Python model is used as a post processing step for another ML model. The Python model expects to receive data from a ML Model who’s output is a DataFrame with the column dense_2. It then extracts the values of that column as a list, selects the first element, and returns a DataFrame with that element as the value of the column output.
In line with other Wallaroo inference results, the outputs of a Python step that returns a pandas DataFrame or Arrow Table will be listed in the out. metadata, with all inference outputs listed as out.{variable 1}, out.{variable 2}, etc. In the example above, this results the output field as the out.output field in the Wallaroo inference result.
Input and output schemas for each Hugging Face pipeline are defined below. Note that adding additional inputs not specified below will raise errors, except for the following:
Framework.HUGGING-FACE-IMAGE-TO-TEXT
Framework.HUGGING-FACE-TEXT-CLASSIFICATION
Framework.HUGGING-FACE-SUMMARIZATION
Framework.HUGGING-FACE-TRANSLATION
Additional inputs added to these Hugging Face pipelines will be added as key/pair value arguments to the model’s generate method. If the argument is not required, then the model will default to the values coded in the original Hugging Face model’s source code.
Any parameter that is not part of the required inputs list will be forwarded to the model as a key/pair value to the underlying models generate method. If the additional input is not supported by the model, an error will be returned.
Any parameter that is not part of the required inputs list will be forwarded to the model as a key/pair value to the underlying models generate method. If the additional input is not supported by the model, an error will be returned.
Schemas:
input_schema=pa.schema([
pa.field('inputs', pa.string()),
pa.field('return_text', pa.bool_()),
pa.field('return_tensors', pa.bool_()),
pa.field('clean_up_tokenization_spaces', pa.bool_()),
# pa.field('extra_field', pa.int64()), # every extra field you specify will be forwarded as a key/value pair])
output_schema=pa.schema([
pa.field('summary_text', pa.string()),
])
input_schema=pa.schema([
pa.field('inputs', pa.string()), # requiredpa.field('top_k', pa.int64()), # optionalpa.field('function_to_apply', pa.string()), # optional])
output_schema=pa.schema([
pa.field('label', pa.list_(pa.string(), list_size=2)), # list with a number of items same as top_k, list_size can be skipped but may lead in worse performancepa.field('score', pa.list_(pa.float64(), list_size=2)), # list with a number of items same as top_k, list_size can be skipped but may lead in worse performance])
Any parameter that is not part of the required inputs list will be forwarded to the model as a key/pair value to the underlying models generate method. If the additional input is not supported by the model, an error will be returned.
Schemas:
input_schema=pa.schema([
pa.field('inputs', pa.string()), # requiredpa.field('return_tensors', pa.bool_()), # optionalpa.field('return_text', pa.bool_()), # optionalpa.field('clean_up_tokenization_spaces', pa.bool_()), # optionalpa.field('src_lang', pa.string()), # optionalpa.field('tgt_lang', pa.string()), # optional# pa.field('extra_field', pa.int64()), # every extra field you specify will be forwarded as a key/value pair])
output_schema=pa.schema([
pa.field('translation_text', pa.string()),
])
input_schema=pa.schema([
pa.field('inputs', pa.string()), # requiredpa.field('candidate_labels', pa.list_(pa.string(), list_size=2)), # requiredpa.field('hypothesis_template', pa.string()), # optionalpa.field('multi_label', pa.bool_()), # optional])
output_schema=pa.schema([
pa.field('sequence', pa.string()),
pa.field('scores', pa.list_(pa.float64(), list_size=2)), # same as number of candidate labels, list_size can be skipped by may result in slightly worse performancepa.field('labels', pa.list_(pa.string(), list_size=2)), # same as number of candidate labels, list_size can be skipped by may result in slightly worse performance])
input_schema=pa.schema([
pa.field('images',
pa.list_(
pa.list_(
pa.list_(
pa.int64(),
list_size=3 ),
list_size=640 ),
list_size=480 )),
pa.field('candidate_labels', pa.list_(pa.string(), list_size=3)),
pa.field('threshold', pa.float64()),
# pa.field('top_k', pa.int64()), # we want the model to return exactly the number of predictions, we shouldn't specify this])
output_schema=pa.schema([
pa.field('score', pa.list_(pa.float64())), # variable output, depending on detected objectspa.field('label', pa.list_(pa.string())), # variable output, depending on detected objectspa.field('box',
pa.list_( # dynamic output, i.e. dynamic number of boxes per input image, each sublist contains the 4 box coordinates pa.list_(
pa.int64(),
list_size=4 ),
),
),
])
Any parameter that is not part of the required inputs list will be forwarded to the model as a key/pair value to the underlying models generate method. If the additional input is not supported by the model, an error will be returned.
input_schema=pa.schema([
pa.field('inputs', pa.string()),
pa.field('return_tensors', pa.bool_()), # optionalpa.field('return_text', pa.bool_()), # optionalpa.field('return_full_text', pa.bool_()), # optionalpa.field('clean_up_tokenization_spaces', pa.bool_()), # optionalpa.field('prefix', pa.string()), # optionalpa.field('handle_long_generation', pa.string()), # optional# pa.field('extra_field', pa.int64()), # every extra field you specify will be forwarded as a key/value pair])
output_schema=pa.schema([
pa.field('generated_text', pa.list_(pa.string(), list_size=1))
])
SKLearn schema follows a different format than other models. To prevent inputs from being out of order, the inputs should be submitted in a single row in the order the model is trained to accept, with all of the data types being the same. For example, the following DataFrame has 4 columns, each column a float.
sepal length (cm)
sepal width (cm)
petal length (cm)
petal width (cm)
0
5.1
3.5
1.4
0.2
1
4.9
3.0
1.4
0.2
For submission to an SKLearn model, the data input schema will be a single array with 4 float values.
When submitting as an inference, the DataFrame is converted to rows with the column data expressed as a single array. The data must be in the same order as the model expects, which is why the data is submitted as a single array rather than JSON labeled columns: this insures that the data is submitted in the exact order as the model is trained to accept.
Original DataFrame:
sepal length (cm)
sepal width (cm)
petal length (cm)
petal width (cm)
0
5.1
3.5
1.4
0.2
1
4.9
3.0
1.4
0.2
Converted DataFrame:
inputs
0
[5.1, 3.5, 1.4, 0.2]
1
[4.9, 3.0, 1.4, 0.2]
SKLearn Schema Outputs
Outputs for SKLearn that are meant to be predictions or probabilities when output by the model are labeled in the output schema for the model when uploaded to Wallaroo. For example, a model that outputs either 1 or 0 as its output would have the output schema as follows:
TensorFlow Keras SavedModel models are .zip file of the SavedModel format. For example, the Aloha sample TensorFlow model is stored in the directory alohacnnlstm:
XGBoost schema follows a different format than other models. To prevent inputs from being out of order, the inputs should be submitted in a single row in the order the model is trained to accept, with all of the data types being the same. If a model is originally trained to accept inputs of different data types, it will need to be retrained to only accept one data type for each column - typically pa.float64() is a good choice.
For example, the following DataFrame has 4 columns, each column a float.
sepal length (cm)
sepal width (cm)
petal length (cm)
petal width (cm)
0
5.1
3.5
1.4
0.2
1
4.9
3.0
1.4
0.2
For submission to an XGBoost model, the data input schema will be a single array with 4 float values.
When submitting as an inference, the DataFrame is converted to rows with the column data expressed as a single array. The data must be in the same order as the model expects, which is why the data is submitted as a single array rather than JSON labeled columns: this insures that the data is submitted in the exact order as the model is trained to accept.
Original DataFrame:
sepal length (cm)
sepal width (cm)
petal length (cm)
petal width (cm)
0
5.1
3.5
1.4
0.2
1
4.9
3.0
1.4
0.2
Converted DataFrame:
inputs
0
[5.1, 3.5, 1.4, 0.2]
1
[4.9, 3.0, 1.4, 0.2]
XGBoost Schema Outputs
Outputs for XGBoost are labeled based on the trained model outputs. For this example, the output is simply a single output listed as output. In the Wallaroo inference result, it is grouped with the metadata out as out.output.
Arbitrary Python models, also known as Bring Your Own Predict (BYOP) allow for custom model deployments with supporting scripts and artifacts. These are used with pre-trained models (PyTorch, Tensorflow, etc) along with whatever supporting artifacts they require. Supporting artifacts can include other Python modules, model files, etc. These are zipped with all scripts, artifacts, and a requirements.txt file that indicates what other Python models need to be imported that are outside of the typical Wallaroo platform.
Contrast this with Wallaroo Python models - aka “Python steps”. These are standalone python scripts that use the python libraries natively supported by the Wallaroo platform. These are used for either simple model deployment (such as ARIMA Statsmodels), or data formatting such as the postprocessing steps. A Wallaroo Python model will be composed of one Python script that matches the Wallaroo requirements.
Arbitrary Python File Requirements
Arbitrary Python (BYOP) models are uploaded to Wallaroo via a ZIP file with the following components:
Artifact
Type
Description
Python scripts aka .py files with classes that extend mac.inference.Inference and mac.inference.creation.InferenceBuilder
Python Script
Extend the classes mac.inference.Inference and mac.inference.creation.InferenceBuilder. These are included with the Wallaroo SDK. Further details are in Arbitrary Python Script Requirements. Note that there is no specified naming requirements for the classes that extend mac.inference.Inference and mac.inference.creation.InferenceBuilder - any qualified class name is sufficient as long as these two classes are extended as defined below.
requirements.txt
Python requirements file
This sets the Python libraries used for the arbitrary python model. These libraries should be targeted for Python 3.8 compliance. These requirements and the versions of libraries should be exactly the same between creating the model and deploying it in Wallaroo. This insures that the script and methods will function exactly the same as during the model creation process.
Other artifacts
Files
Other models, files, and other artifacts used in support of this model.
For example, the if the arbitrary python model will be known as vgg_clustering, the contents may be in the following structure, with vgg_clustering as the storage directory:
Note the inclusion of the custom_inference.py file. This file name is not required - any Python script or scripts that extend the classes listed above are sufficient. This Python script could have been named vgg_custom_model.py or any other name as long as it includes the extension of the classes listed above.
The sample arbitrary python model file is created with the command zip -r vgg_clustering.zip vgg_clustering/.
Wallaroo Arbitrary Python uses the Wallaroo SDK mac module, included in the Wallaroo SDK 2023.2.1 and above. See the Wallaroo SDK Install Guides for instructions on installing the Wallaroo SDK.
Arbitrary Python Script Requirements
The entry point of the arbitrary python model is any python script that extends the following classes. These are included with the Wallaroo SDK. The required methods that must be overridden are specified in each section below.
mac.inference.Inference interface serves model inferences based on submitted input some input. Its purpose is to serve inferences for any supported arbitrary model framework (e.g. scikit, keras etc.).
classDiagram
class Inference {
<<Abstract>>
+model Optional[Any]
+expected_model_types()* Set
+predict(input_data: InferenceData)* InferenceData
-raise_error_if_model_is_not_assigned() None
-raise_error_if_model_is_wrong_type() None
}
mac.inference.creation.InferenceBuilder builds a concrete Inference, i.e. instantiates an Inference object, loads the appropriate model and assigns the model to to the Inference object.
classDiagram
class InferenceBuilder {
+create(config InferenceConfig) * Inference
-inference()* Any
}
mac.inference.Inference
mac.inference.Inference Objects
Object
Type
Description
model Optional[Any]
An optional list of models that match the supported frameworks from wallaroo.framework.Framework included in the arbitrary python script. Note that this is optional - no models are actually required. A BYOP can refer to a specific model(s) used, be used for data processing and reshaping for later pipeline steps, or other needs.
mac.inference.Inference Methods
Method
Returns
Description
expected_model_types (Required)
Set
Returns a Set of models expected for the inference as defined by the developer. Typically this is a set of one. Wallaroo checks the expected model types to verify that the model submitted through the InferenceBuilder method matches what this Inference class expects.
The entry point for the Wallaroo inference with the following input and output parameters that are defined when the model is updated.
mac.types.InferenceData: The inputInferenceData is a dictionary of numpy arrays derived from the input_schema detailed when the model is uploaded, defined in PyArrow.Schema format.
mac.types.InferenceData: The output is a dictionary of numpy arrays as defined by the output parameters defined in PyArrow.Schema format.
The InferenceDataValidationError exception is raised when the input data does not match mac.types.InferenceData.
raise_error_if_model_is_not_assigned
N/A
Error when expected_model_types is not set.
raise_error_if_model_is_wrong_type
N/A
Error when the model does not match the expected_model_types.
mac.inference.creation.InferenceBuilder
InferenceBuilder builds a concrete Inference, i.e. instantiates an Inference object, loads the appropriate model and assigns the model to the Inference.
classDiagram
class InferenceBuilder {
+create(config InferenceConfig) * Inference
-inference()* Any
}
Each model that is included requires its own InferenceBuilder. InferenceBuilder loads one model, then submits it to the Inference class when created. The Inference class checks this class against its expected_model_types() Set.
Creates an Inference subclass, then assigns a model and attributes. The CustomInferenceConfig is used to retrieve the config.model_path, which is a pathlib.Path object pointing to the folder where the model artifacts are saved. Every artifact loaded must be relative to config.model_path. This is set when the arbitrary python .zip file is uploaded and the environment for running it in Wallaroo is set. For example: loading the artifact vgg_clustering\feature_extractor.h5 would be set with config.model_path \ feature_extractor.h5. The model loaded must match an existing module. For our example, this is from sklearn.cluster import KMeans, and this must match the Inferenceexpected_model_types.
inference
custom Inference instance.
Returns the instantiated custom Inference object created from the create method.
Arbitrary Python Runtime
Arbitrary Python always run in the containerized model runtime.
Wallaroo users can register their trained MLFlow ML Models from a containerized model container registry into their Wallaroo instance and perform inferences with it through a Wallaroo pipeline.
As of this time, Wallaroo only supports MLFlow 1.30.0 containerized models. For information on how to containerize an MLFlow model, see the MLFlow Documentation.
ML Models are uploaded to Wallaroo through the following endpoint:
Models uploaded through this method that are not native runtimes are containerized within the Wallaroo instance then run by the Wallaroo engine. See Wallaroo MLOps API Essentials Guide: Pipeline Management for details on pipeline configurations and deployments.
For these models, the following inputs are required.
Endpoint:
/v1/api/models/upload_and_convert
Headers:
Content-Type: multipart/form-data
Parameters
name (StringRequired): The model name.
visibility (StringRequired): Either public or private.
workspace_id (StringRequired): The numerical ID of the workspace to upload the model to.
conversion (StringRequired): The conversion parameters that include the following:
framework (StringRequired): The framework of the model being uploaded. See the list of supported models for more details.
python_version (StringRequired): The version of Python required for model.
requirements (StringRequired): Required libraries. Can be [] if the requirements are default Wallaroo JupyterHub libraries.
input_schema (StringOptional): The input schema from the Apache Arrow pyarrow.lib.Schema format, encoded with base64.b64encode. Only required for non-native runtime models.
output_schema (StringOptional): The output schema from the Apache Arrow pyarrow.lib.Schema format, encoded with base64.b64encode. Only required for non-native runtime models.
Upload Native Runtime Model Example
ONNX are always native runtimes. The following example shows uploading an ONNX model to a Wallaroo instance using the requests library. Note that the input_schema and output_schema encoded details are not required.
The following example shows uploading a Hugging Face model to a Wallaroo instance using the requests library. Note that the input_schema and output_schema encoded details are required.
input_schema=pa.schema([
pa.field('inputs', pa.string()), # requiredpa.field('candidate_labels', pa.list_(pa.string(), list_size=2)), # requiredpa.field('hypothesis_template', pa.string()), # optionalpa.field('multi_label', pa.bool_()), # optional])
output_schema=pa.schema([
pa.field('sequence', pa.string()),
pa.field('scores', pa.list_(pa.float64(), list_size=2)), # same as number of candidate labels, list_size can be skipped by may result in slightly worse performancepa.field('labels', pa.list_(pa.string(), list_size=2)), # same as number of candidate labels, list_size can be skipped by may result in slightly worse performance])
encoded_input_schema=base64.b64encode(
bytes(input_schema.serialize())
).decode("utf8")
encoded_output_schema=base64.b64encode(
bytes(output_schema.serialize())
).decode("utf8")
metadata= {
"name": model_name,
"visibility": "private",
"workspace_id": workspace_id,
"conversion": {
"framework": framework,
"python_version": "3.8",
"requirements": []
},
"input_schema": encoded_input_schema,
"output_schema": encoded_output_schema,
}
headers=wl.auth.auth_header()
files= {
'metadata': (None, json.dumps(metadata), "application/json"),
'file': (model_name, open(model_path,'rb'),'application/octet-stream')
}
response=requests.post('{APIURL}/v1/api/models/upload_and_convert',
headers=headers,
files=files)
print(response.json())
{'insert_models': {'returning': [{'models': [{'id': 208}]}]}}
6 - Wallaroo MLOps API Essentials Guide: Pipeline Management
How to use the Wallaroo API for Pipeline Management
Pipeline Naming Requirements
Pipeline names map onto Kubernetes objects, and must be DNS compliant. Pipeline names must be ASCII alpha-numeric characters or dash (-) only. . and _ are not allowed.
Pipeline Management
Pipelines are managed through the Wallaroo API or the Wallaroo SDK. Pipelines are the vehicle used for deploying, serving, and monitoring ML models. For more information, see the Wallaroo Glossary.
Create Pipeline in a Workspace
Creates a new pipeline in the specified workspace.
Parameters
pipeline_id - (REQUIRED string): Name of the new pipeline.
workspace_id - (REQUIRED int): Numerical id of the workspace for the new pipeline.
definition - (REQUIRED string): Pipeline definitions, can be {} for none.
Example: Two pipelines are created in the workspace created in the step Create Workspace. One will be an empty pipeline without any models, the other will be created using the uploaded models in the Upload Model to Workspace step and no configuration details. The pipeline id, variant id, and variant version of each pipeline will be stored for later examples.
The variable example_workspace_id was created in a previous example.
# Create pipeline in a workspace# Retrieve the token headers=wl.auth.auth_header()
api_request=f"{APIURL}/v1/api/pipelines/create"data= {
"pipeline_id": empty_pipeline_name,
"workspace_id": example_workspace_id,
"definition": {}
}
response=requests.post(api_request, json=data, headers=headers, verify=True).json()
empty_pipeline_id=response['pipeline_pk_id']
empty_pipeline_variant_id=response['pipeline_variant_pk_id']
example_pipeline_variant_version=['pipeline_variant_version']
response
Deploy a an existing pipeline. Note that for any pipeline that has model steps, they must be included either in model_configs, model_ids or models.
Endpoint
/pipelines/deploy
Parameters
deploy_id (REQUIRED string): The name for the pipeline deployment.
engine_config (OPTIONAL string): Additional configuration options for the pipeline. These set the memory, replicas, and other settings. For example: {"cpus": 1, "replica_count": 1, "memory": "999Mi"} Available parameters include the following.
cpus: The number of CPUs to apply to the native runtime models in the pipeline. cpus can be a fraction of a cpu, for example "cpus": 0.25.
gpus: The number of GPUs to apply to the native runtime models. GPUs can only be allocated in whole numbers. Organizations should monitor how many GPUs are allocated to a pipelines to verify they have enough GPUs for all pipelines. If gpus is called, then the deployment_label must be called and match the GPU Nodepool for the Wallaroo Cluster hosting the Wallaroo instance.
replica_count: The number of replicas of the pipeline to deploy. This allows for multiple deployments of the same models to be deployed to increase inferences through parallelization.
replica_autoscale_min_max: Provides replicas to be scaled from 0 to some maximum number of replicas. This allows pipelines to spin up additional replicas as more resources are required, then spin them back down to save on resources and costs. For example: "replica_autoscale_min_max": {"maximum": 2, "minimum":0}
autoscale_cpu_utilization: Sets the average CPU percentage metric for when to load or unload another replica.
disable_autoscale: Disables autoscaling in the deployment configuration.
memory: Sets the amount of RAM to allocate the pipeline. The memory_spec string is in the format “{size as number}{unit value}”. The accepted unit values are:
KiB (for KiloBytes)
MiB (for MegaBytes)
GiB (for GigaBytes)
TiB (for TeraBytes)
lb_cpus: Sets the number or fraction of CPUs to use for the pipeline’s load balancer, for example: 0.25, 1, 1.5, etc. The units, similar to the Kubernetes CPU definitions.
lb_memory: Sets the amount of RAM to allocate the pipeline’s load balancer. The memory_spec string is in the format “{size as number}{unit value}”. The accepted unit values are:
KiB (for KiloBytes)
MiB (for MegaBytes)
GiB (for GigaBytes)
TiB (for TeraBytes)
deployment_label: Label used for Kubernetes labels.
arch: Determines which architecture to use. The available options are:
x86: Select x86 from available nodepools.
arm: ARM based architecture such as Ampere® Altra® Arm-based processor included with the following Azure virtual machines:
sidekick_cpus: Sets the number of CPUs to be used for the model’s sidekick container. Only affects image-based models (e.g. MLFlow models) in a deployment. The parameters are as follows:
model: The sidekick model to configure.
core_count: Sets the number or fraction of CPUs to use.
sidekick_arch: Determines which architecture to use. The available options are:
x86: Select x86 from available nodepools.
arm: ARM based architecture such as Ampere® Altra® Arm-based processor included with the following Azure virtual machines:
sidekick_memory: Sets the memory available to for the model’s sidekick container. Only affects image-based models (e.g. MLFlow models) in a deployment. The parameters are as follows:
model: The sidekick model to configure.
memory_spec: The amount of memory to allocated as memory unit values. The accepted unit values are:
KiB (for KiloBytes)
MiB (for MegaBytes)
GiB (for GigaBytes)
TiB (for TeraBytes)
sidekick_env: Environment variables submitted to the model’s sidekick container. Only affects image-based models (e.g. MLFlow models) in a deployment. These are used specifically for containerized models that have environment variables that effect their performance. This takes the following parameters:
model: The sidekick model to configure.
environment: Dictionary inputs
sidekick_gpus: Sets the number of GPUs to allocate for containerized runtimes. GPUs are only allocated in whole units, not as fractions. Organizations should be aware of the total number of GPUs available to the cluster, and monitor which pipeline deployment configurations have GPUs allocated to ensure they do not run out. If there are not enough GPUs to allocate to a pipeline deployment configuration, and error message will be deployed when the pipeline is deployed. If gpus is called, then the deployment_label must be called and match the GPU Nodepool for the Wallaroo Cluster hosting the Wallaroo instance. This takes the following parameters:
model: The sidekick model to configure.
core_count: The number of GPUs to allocate.
pipeline_version_pk_id (REQUIRED int): Pipeline version id.
model_configs (OPTIONAL Array int): Ids of model configs to apply.
model_ids (OPTIONAL Array int): Ids of models to apply to the pipeline. If passed in, model_configs will be created automatically.
models (OPTIONAL Array models): If the model ids are not available as a pipeline step, the models’ data can be passed to it through this method. The options below are only required if models are provided as a parameter.
name (REQUIRED string): Name of the uploaded model that is in the same workspace as the pipeline.
version (REQUIRED string): Version of the model to use.
sha (REQUIRED string): SHA value of the model.
pipeline_id (REQUIRED int): Numerical value of the pipeline to deploy.
Returns
id (int): The deployment id.
Examples: Both the pipeline with model created in the step Create Pipeline in a Workspace will be deployed and their deployment information saved for later examples.
# Deploy a pipeline with models# Retrieve the token headers=wl.auth.auth_header()
api_request=f"{APIURL}/v1/api/pipelines/deploy"model_deploy_id=model_pipeline_name# example_model_deploy_id="test deployment name"data= {
"deploy_id": model_deploy_id,
"pipeline_version_pk_id": model_pipeline_variant_id,
"models": [
{
"name": model_name,
"version":example_model_version,
"sha":example_model_sha }
],
"pipeline_id": model_pipeline_id}
response=requests.post(api_request, json=data, headers=headers, verify=True).json()
display(response)
model_deployment_id=response['id']
# wait 45 seconds for the pipeline to complete deploymentimporttimetime.sleep(45)
{'id': 5}
Get Deployment Status
Returns the deployment status.
Parameters
name - (REQUIRED string): The deployment in the format {deployment_name}-{deploymnent-id}.
Example: The deployed empty and model pipelines status will be displayed.
# Retrieve the token headers=wl.auth.auth_header()
# Get model pipeline deploymentapi_request=f"{APIURL}/v1/api/status/get_deployment"data= {
"name": f"{model_deploy_id}-{model_deployment_id}"}
response=requests.post(api_request, json=data, headers=headers, verify=True).json()
response
The API command /admin/get_pipeline_external_url retrieves the external inference URL for a specific pipeline in a workspace.
Parameters
workspace_id (REQUIRED integer): The workspace integer id.
pipeline_name (REQUIRED string): The name of the deployment.
In this example, a list of the workspaces will be retrieved. Based on the setup from the Internal Pipeline Deployment URL Tutorial, the workspace matching urlworkspace will have it’s workspace id stored and used for the /admin/get_pipeline_external_url request with the pipeline urlpipeline.
The External Inference URL will be stored as a variable for the next step.
The inference can now be performed through the External Inference URL. This URL will accept the same inference data file that is used with the Wallaroo SDK, or with an Internal Inference URL as used in the Internal Pipeline Inference URL Tutorial.
Deployed pipelines have their own Inference URL that accepts HTTP POST submissions.
7 - Wallaroo MLOps API Essentials Guide: Pipeline Log Management
How to use the Wallaroo API for Pipeline Log Management
Pipeline logs are retrieved through the Wallaroo MLOps API with the following request.
REQUEST URL
v1/api/pipelines/get_logs
Headers
Accept:
application/json; format=pandas-records: For the logs returned as pandas DataFrame
application/vnd.apache.arrow.file: for the logs returned as Apache Arrow
PARAMETERS
pipeline_id (StringRequired): The name of the pipeline.
workspace_id (IntegerRequired): The numerical identifier of the workspace.
cursor (StringOptional): Cursor returned with a previous page of results from a pipeline log request, used to retrieve the next page of information.
order (StringOptional Default: Desc): The order for log inserts returned. Valid values are:
Asc: In chronological order of inserts.
Desc: In reverse chronological order of inserts.
page_size (IntegerOptional Default: 1000.): Max records per page.
start_time (StringOptional): The start time of the period to retrieve logs for in RFC 3339 format for DateTime. Must be combined with end_time.
end_time (StringOptional): The end time of the period to retrieve logs for in RFC 3339 format for DateTime. Must be combined with start_time.
RETURNS
The logs are returned by default as 'application/json; format=pandas-records' format. To request the logs as Apache Arrow tables, set the submission header Accept to application/vnd.apache.arrow.file.
Headers:
x-iteration-cursor: Used to retrieve the next page of results. This is not included if x-iteration-status is All.
x-iteration-status: Informs whether there are more records available outside of this log request parameters.
All: This page includes all logs available from this request. If x-iteration-status is All, then x-iteration-cursor is not provided.
SchemaChange: A change in the log schema caused by actions such as pipeline version, etc.
RecordLimited: The number of records exceeded from the page size, more records can be requested as the next page. There may be more records available to retrieve OR the record limit was reached for this request even if no more records are available in next cursor request.
ByteLimited: The number of records exceeded the pipeline log limit which is around 100K.
# Retrieve logs from specific date/time to only get the two DataFrame input inferences in ascending format# retrieve the authorization tokenheaders=wl.auth.auth_header()
url=f"{APIURL}/v1/api/pipelines/get_logs"# Standard log retrievaldata= {
'pipeline_id': main_pipeline_name,
'workspace_id': workspace_id,
'order': 'Asc',
'start_time': f'{shadow_date_start.isoformat()}',
'end_time': f'{shadow_date_end.isoformat()}'}
response=requests.post(url, headers=headers, json=data)
standard_logs=pd.DataFrame.from_records(response.json())
display(standard_logs.head(5).loc[:, ["time", "out", "out_logcontrolchallenger01", "out_logcontrolchallenger02"]])
time
out
out_logcontrolchallenger01
out_logcontrolchallenger02
0
1684427140394
{'variable': [718013.75]}
{'variable': [659806.0]}
{'variable': [704901.9]}
1
1684427140394
{'variable': [615094.56]}
{'variable': [732883.5]}
{'variable': [695994.44]}
2
1684427140394
{'variable': [448627.72]}
{'variable': [419508.84]}
{'variable': [416164.8]}
3
1684427140394
{'variable': [758714.2]}
{'variable': [634028.8]}
{'variable': [655277.2]}
4
1684427140394
{'variable': [513264.7]}
{'variable': [427209.44]}
{'variable': [426854.66]}
A/B Testing Pipeline Logs Example
# Retrieve logs from specific date/time to only get the two DataFrame input inferences in ascending format# retrieve the authorization tokenheaders=wl.auth.auth_header()
url=f"{APIURL}/v1/api/pipelines/get_logs"# Standard log retrievaldata= {
'pipeline_id': main_pipeline_name,
'workspace_id': workspace_id,
'order': 'Asc',
'start_time': f'{ab_date_start.isoformat()}',
'end_time': f'{ab_date_end.isoformat()}'}
response=requests.post(url, headers=headers, json=data)
standard_logs=pd.DataFrame.from_records(response.json())
display(standard_logs.head(5).loc[:, ["time", "out"]])
Pipeline logs have a set allocation of storage space and data requirements.
Pipeline Log Storage Warnings
To prevent storage and performance issues, inference result data may be dropped from pipeline logs by the following standards:
Columns are progressively removed from the row starting with the largest input data size and working to the smallest, then the same for outputs.
For example, Computer Vision ML Models typically have large inputs and output values - a single pandas DataFrame inference request may be over 13 MB in size, and the inference results nearly as large. To prevent pipeline log storage issues, the input may be dropped from the pipeline logs, and if additional space is needed, the inference outputs would follow. The time column is preserved.
IMPORTANT NOTE
Inference Requests will always return all inputs, outputs, and other metadata unless specifically requested for exclusion. It is the pipeline logs that may drop columns for space purposes.
If a pipeline has dropped columns for space purposes, this will be displayed when a log request is made with the following warning, with {columns} replaced with the dropped columns.
To review what columns are dropped from pipeline logs for storage reasons, include the dataset metadata in the request to view the column metadata.dropped. This metadata field displays a List of any columns dropped from the pipeline logs.
Data elements that do not fit the supported data types below, such as None or Null values, are not supported in pipeline logs. When present, undefined data will be written in the place of the null value, typically zeroes. Any null list values will present an empty list.
8 - Wallaroo MLOps API Essentials Guide: Enablement Management
How to use the Wallaroo API for Enablement Management
Enablement Management
Enablement Management allows users to see what Wallaroo features have been activated.
List Enablement Features
Lists the enablement features for the Wallaroo instance.
PARAMETERS
null: An empty set {}
RETURNS
features - (string): Enabled features.
name - (string): Name of the Wallaroo instance.
is_auth_enabled - (bool): Whether authentication is enabled.
# List enablement features# Retrieve the token headers=wl.auth.auth_header()
api_request=f"{APIURL}/v1/api/features/list"data= {
}
response=requests.post(api_request, json=data, headers=headers, verify=True).json()
response
9 - Wallaroo MLOps API Essentials Guide: Assays Management
How to use the Wallaroo API for Assays Management
Assays
IMPORTANT NOTE: These assays were run in a Wallaroo environment with canned historical data. See the Wallaroo Assay Tutorial for details on setting up this environment. This historical data is required for these examples.
Create Assay
Create a new array in a specified pipeline.
PARAMETERS
id - (OPTIONAL int): The numerical identifier for the assay.
name - (REQUIRED string): The name of the assay.
pipeline_id - (REQUIRED int): The numerical idenfifier the assay will be placed into.
pipeline_name - (REQUIRED string): The name of the pipeline
active - (REQUIRED bool): Indicates whether the assay will be active upon creation or not.
status - (REQUIRED string): The status of the assay upon creation.
iopath - (REQUIRED string): The iopath of the assay in the format "input|output field_name field_index.
baseline - (REQUIRED baseline): The baseline for the assay.
Fixed - (REQUIRED AssayFixConfiguration): The fixed configuration for the assay.
pipeline - (REQUIRED string): The name of the pipeline with the baseline data.
model - (REQUIRED string): The name of the model used.
start_at - (REQUIRED string): The DateTime of the baseline start date.
end_at - (REQUIRED string): The DateTime of the baseline end date.
window (REQUIRED AssayWindow): Assay window.
pipeline - (REQUIRED string): The name of the pipeline for the assay window.
model - (REQUIRED string): The name of the model used for the assay window.
width - (REQUIRED string): The width of the assay window.
start - (OPTIONAL string): The DateTime of when to start the assay window.
interval - (OPTIONAL string): The assay window interval.
summarizer - (REQUIRED AssaySummerizer): The summarizer type for the array aka “advanced settings” in the Wallaroo Dashboard UI.
type - (REQUIRED string): Type of summarizer.
bin_mode - (REQUIRED string): The binning model type. Values can be:
run_until - (OPTIONAL string): DateTime of when to end the assay.
workspace_id - (REQUIRED integer): The workspace the assay is part of.
model_insights_url - (OPTIONAL string): URL for model insights.
RETURNS
assay_id - (integer): The id of the new assay.
As noted this example requires the Wallaroo Assay Tutorial for historical data. Before running this example, set the sample pipeline id, pipeline, name, model name, and workspace id in the code sample below.
For our example, we will be using the output of the field dense_2 at the index 0 for the iopath.
# Retrieve information for the housepricedrift workspace# List workspaces# Retrieve the token headers=wl.auth.auth_header()
api_request=f"{APIURL}/v1/api/workspaces/list"data= {
}
response=requests.post(api_request, json=data, headers=headers, verify=True).json()
## Create assay# Retrieve the token headers=wl.auth.auth_header()
api_request=f"{APIURL}/v1/api/assays/create"exampleAssayName="api assay"## Now get all of the assays for the pipeline in workspace 4 `housepricedrift`exampleAssayPipelineId=assay_pipeline_idexampleAssayPipelineName="housepricepipe"exampleAssayModelName="housepricemodel"exampleAssayWorkspaceId=assay_workspace_id# iopath can be input 00 or output 0 0data= {
'name': exampleAssayName,
'pipeline_id': exampleAssayPipelineId,
'pipeline_name': exampleAssayPipelineName,
'active': True,
'status': 'active',
'iopath': "output dense_2 0",
'baseline': {
'Fixed': {
'pipeline': exampleAssayPipelineName,
'model': exampleAssayModelName,
'start_at': '2023-01-01T00:00:00-05:00',
'end_at': '2023-01-02T00:00:00-05:00' }
},
'window': {
'pipeline': exampleAssayPipelineName,
'model': exampleAssayModelName,
'width': '24 hours',
'start': None,
'interval': None },
'summarizer': {
'type': 'UnivariateContinuous',
'bin_mode': 'Quantile',
'aggregation': 'Density',
'metric': 'PSI',
'num_bins': 5,
'bin_weights': None,
'bin_width': None,
'provided_edges': None,
'add_outlier_edges': True },
'warning_threshold': 0,
'alert_threshold': 0.1,
'run_until': None,
'workspace_id': exampleAssayWorkspaceId}
response=requests.post(api_request, json=data, headers=headers, verify=True).json()
example_assay_id=response['assay_id']
response
{'assay_id': 5}
List Assays
Lists all assays in the specified pipeline.
PARAMETERS
pipeline_id - (REQUIRED int): The numerical ID of the pipeline.
RETURNS
assays - (Array assays): A list of all assays.
Example: Display a list of all assays in a workspace. This will assume we have a workspace with an existing Assay and the associated data has been upload. See the tutorial Wallaroo Assays Tutorial.
For this reason, these values are hard coded for now.
# Get assays# Retrieve the token headers=wl.auth.auth_header()
api_request=f"{APIURL}/v1/api/assays/list"data= {
"pipeline_id": exampleAssayPipelineId}
response=requests.post(api_request, json=data, headers=headers, verify=True).json()
response
run_until - (OPTIONAL string): DateTime of when to end the assay.
workspace_id - (REQUIRED integer): The workspace the assay is part of.
model_insights_url - (OPTIONAL string): URL for model insights.
Returns
Assay
Example: An interactive assay will be run for Assay exampleAssayId exampleAssayName. Depending on the number of assay results and the data window, this may take some time. This returns all of the results for this assay at this time. The total number of responses will be displayed after.
assay_id - (REQUIRED integer): Numerical id for the assay.
start - (OPTIONAL string): DateTime for when the baseline starts.
end - (OPTIONAL string): DateTime for when the baseline ends.
limit - (OPTIONAL integer): Maximum number of results to return.
pipeline_id - (OPTIONAL integer): Numerical id of the pipeline the assay is in.
Returns
Assay Baseline
# Get Assay Results# Retrieve the token headers=wl.auth.auth_header()
api_request=f"{APIURL}/v1/api/assays/get_results"data= {
'assay_id': example_assay_id,
'pipeline_id': exampleAssayPipelineId}
response=requests.post(api_request, json=data, headers=headers, verify=True).json()
response
10 - Wallaroo MLOps API Essentials Guide: Connections Management
How to use the Wallaroo API for Connections Management
Wallaroo Data Connections are provided to establish connections to external data stores for requesting or submitting information. They provide a source of truth for data source connection information to enable repeatability and access control within your ecosystem. The actual implementation of data connections are managed through other means, such as Wallaroo Pipeline Orchestrators and Tasks, where the libraries and other tools used for the data connection can be stored.
Create Connection
Lists the enablement features for the Wallaroo instance.
REQUEST PATH
POST /v1/api/connections/create
PARAMETERS
name (StringRequired): The name of the connection.
type (StringRequired): The user defined type of connection.
details (StringRequired): User defined configuration details for the data connection. These can be {'username':'dataperson', 'password':'datapassword', 'port': 3339}, or {'token':'abcde123==', 'host':'example.com', 'port:1234'}, or other user defined combinations.
RETURNS
id (String): The id of the connection id in UUID format.
Adds a connection to a Wallaroo workspace, accessible by workspace members.
REQUEST PATH
POST /v1/api/connections/create
PARAMETERS
workspace_id (StringRequired): The name of the connection.
connection_id (StringRequired): The UUID connection ID
RETURNS
id (String): The id of the workspace’s connection id in UUID format. Note that the workspace’s connection id is separate from the Wallaroo connection id.
Lists the connections set to the specified workspace.
Adds a connection to a Wallaroo workspace, accessible by workspace members.
REQUEST PATH
POST /v1/api/connections/create
PARAMETERS
workspace_id (IntegerRequired): The numerical id of the workspace.
RETURNS
List[workspaces]: List of the connections in the workspace.
name (String): The id of the workspace’s connection id in UUID format. Note that the connection’s workspace connection id is separate from the Wallaroo connection id.
type (String): The user defined type of connection.
details (dict): The user defined details of the connection.
created_at (String): Timestamp of the connection creation date.
workspace_names (List[String]): List of workspaces the connection is attached to.
Retrieves the connection by the unique connection name.
REQUEST PATH
POST /v1/api/connections/get
PARAMETERS
name (StringRequired): The name of the connection.
RETURNS
name (String): The id of the workspace’s connection id in UUID format. Note that the workspace’s connection id is separate from the Wallaroo connection id.
type (String): The user defined type of connection.
details (dict): The user defined details of the connection.
created_at (String): Timestamp of the connection creation date.
workspace_names (List[String]): List of workspaces the connection is attached to.
Retrieves the connection by the unique connection id.
REQUEST PATH
POST /v1/api/connections/get_by_id
PARAMETERS
id (StringRequired): The id of the connection.
RETURNS
name (String): The id of the workspace’s connection id in UUID format. Note that the workspace’s connection id is separate from the Wallaroo connection id.
type (String): The user defined type of connection.
details (dict): The user defined details of the connection.
created_at (String): Timestamp of the connection creation date.
workspace_names (List[String]): List of workspaces the connection is attached to.
Removes the specified connection from the workspace.
REQUEST PATH
POST /v1/api/connections/remove_from_workspace
PARAMETERS
workspace_id (IntegerRequired): The numerical id of the workspace.
connection_id (StringRequired): The connection id.
RETURNS
HTTP 204 response.
# get the connection input details# retrieve the authorization tokenheaders=wl.auth.auth_header()
url=f"{APIURL}/v1/api/connections/remove_from_workspace"data= {
'workspace_id': workspace_id,
'connection_id': connection_input_id}
display(requests.post(url, headers=headers, json=data))
<Response [204]>
Delete Connection
Deletes the connection from the Wallaroo instance. The connection must be removed from all workspaces before it can be deleted.
REQUEST PATH
POST /v1/api/connections/delete
PARAMETERS
name (StringRequired): The connection name.
RETURNS
HTTP 204 response.
# get the connection input details# retrieve the authorization tokenheaders=wl.auth.auth_header()
url=f"{APIURL}/v1/api/connections/delete"data= {
'name': bigquery_connection_input_name}
display(requests.post(url, headers=headers, json=data))
<Response [204]>
11 - Wallaroo MLOps API Essentials Guide: ML Workload Orchestration Management
How to use the Wallaroo API for ML Workload Orchestration Management
Wallaroo provides ML Workload Orchestrations and Tasks to automate processes in a Wallaroo instance. For example:
Deploy a pipeline, retrieve data through a data connector, submit the data for inferences, undeploy the pipeline
Replace a model with a new version
Retrieve shadow deployed inference results and submit them to a database
Orchestration Flow
ML Workload Orchestration flow works within 3 tiers:
Tier
Description
ML Workload Orchestration
User created custom instructions that provide automated processes that follow the same steps every time without error. Orchestrations contain the instructions to be performed, uploaded as a .ZIP file with the instructions, requirements, and artifacts.
Task
Instructions on when to run an Orchestration as a scheduled Task. Tasks can be Run Once, where is creates a single Task Run, or Run Scheduled, where a Task Run is created on a regular schedule based on the Kubernetes cronjob specifications. If a Task is Run Scheduled, it will create a new Task Run every time the schedule parameters are met until the Task is killed.
Task Run
The execution of an task. These validate business operations are successful identify any unsuccessful task runs. If the Task is Run Once, then only one Task Run is generated. If the Task is a Run Scheduled task, then a new Task Run will be created each time the schedule parameters are met, with each Task Run having its own results and logs.
One example may be of making donuts.
The ML Workload Orchestration is the recipe.
The Task is the order to make the donuts. It might be Run Once, so only one set of donuts are made, or Run Scheduled, so donuts are made every 2nd Sunday at 6 AM. If Run Scheduled, the donuts are made every time the schedule hits until the order is cancelled (aka killed).
The Task Run are the donuts with their own receipt of creation (logs, etc).
Orchestration Requirements
Orchestrations are uploaded to the Wallaroo instance as a ZIP file with the following requirements:
Parameter
Type
Description
User Code
(Required) Python script as .py files
If main.py exists, then that will be used as the task entrypoint. Otherwise, the firstmain.py found in any subdirectory will be used as the entrypoint. If no main.py is found, the orchestration will not be accepted.
A standard Python requirements.txt for any dependencies to be provided in the task environment. The Wallaroo SDK will already be present and should not be included in the requirements.txt. Multiple requirements.txt files are not allowed.
Other artifacts
Other artifacts such as files, data, or code to support the orchestration.
Zip Instructions
In a terminal with the zip command, assemble artifacts as above and then create the archive. The zip command is included by default with the Wallaroo JupyterHub service.
zip commands take the following format, with {zipfilename}.zip as the zip file to save the artifacts to, and each file thereafter as the files to add to the archive.
zip {zipfilename}.zip file1, file2, file3....
For example, the following command will add the files main.py and requirements.txt into the file hello.zip.
The following recommendations will make using Wallaroo orchestrations.
The version of Python used should match the same version as in the Wallaroo JupyterHub service.
The same version of the Wallaroo SDK should match the server. For a 2023.2.1 Wallaroo instance, use the Wallaroo SDK version 2023.2.1.
Specify the version of pip dependencies.
The wallaroo.Client constructor auth_type argument is ignored. Using wallaroo.Client() is sufficient.
The following methods will assist with orchestrations:
wallaroo.in_task() : Returns True if the code is running within an orchestration task.
wallaroo.task_args(): Returns a Dict of invocation-specific arguments passed to the run_ calls.
Orchestrations will be run in the same way as running within the Wallaroo JupyterHub service, from the version of Python libraries (unless specifically overridden by the requirements.txt setting, which is not recommended), and running in the virtualized directory /home/jovyan/.
Orchestration Code Samples
The following demonstres using the wallaroo.in_task() and wallaroo.task_args() methods within an Orchestration. This sample code uses wallaroo.in_task() to verify whether or not the script is running as a Wallaroo Task. If true, it will gather the wallaroo.task_args() and use them to set the workspace and pipeline. If False, then it sets the pipeline and workspace manually.
# get the argumentswl=wallaroo.Client()
# if true, get the arguments passed to the taskifwl.in_task():
arguments=wl.task_args()
# arguments is a key/value pair, set the workspace and pipeline nameworkspace_name=arguments['workspace_name']
pipeline_name=arguments['pipeline_name']
# False: We're not in a Task, so set the pipeline manuallyelse:
workspace_name="bigqueryworkspace"pipeline_name="bigquerypipeline"
ML Workload Orchestration Methods
Upload Orchestration
Uploads an orchestration to the Wallaroo workspace.
REQUEST PATH
POST multipart/form-data /v1/api/orchestration/upload
PARAMETERS
file: The file data as Content-Type application/octet-stream.
metadata: The metadata including the workspace_id as Content-Type application/json.
RETURNS
id (String): The id of the orchestration in UUID format.
Uploads an orchestration to the Wallaroo workspace.
REQUEST PATH
POST /v1/api/orchestration/list
PARAMETERS
workspace_id (IntegerRequired): The numerical id of the workspace.
RETURNS
List[orchestrations]: A list of the orchestrations in the workspace.
id (String): The The id of the orchestration in UUID format.
sha: The sha hash of the orchestration.
name (String): The name of the orchestration.
file_name (String): The name of the file uploaded for the orchestration.
task_id (String): The task id managing unpacking and installing the orchestration.
owner_id (String): The Keycloak ID of the user that created the orchestration.
created_at (String): The timestamp of when the orchestration was created.
updated_at (String): The timestamp of when the orchestration was updated.
Tasks
Tasks are the implementation of an orchestration. Think of the orchestration as the instructions to follow, and the Task is the unit actually doing it.
Tasks are created at the workspace level.
Create Tasks
Tasks are created from an orchestration through the following methods.
Task Type
Description
/v1/api/task/run_once
Run the task once based.
/v1/api/task/run_scheduled
Run on a schedule, repeat every time the schedule fits the task until it is killed.
Run Task Once
Run Once aka Temporary Run tasks are created from an Orchestration with the request:
REQUEST PATH
POST /v1/api/task/run_once.
PARAMETERS
name (StringRequired): The name of the task to create.
orch_id (StringRequired): The id of the orchestration to create the task from.
timeout (IntegerOptional): The timeout period to run the task before cancelling it in seconds.
workspace_id (IntegerRequired): The numerical id of the workspace to create the task within.
RETURNS
List[tasks]: A list of the tasks in the workspace.
id (String): The The id of the orchestration in UUID format.
sha: The sha hash of the orchestration.
name (String): The name of the orchestration.
file_name (String): The name of the file uploaded for the orchestration.
task_id (String): The task id managing unpacking and installing the orchestration.
owner_id (String): The Keycloak ID of the user that created the orchestration.
created_at (String): The timestamp of when the orchestration was created.
updated_at (String): The timestamp of when the orchestration was updated.
Kills the task so it will not generate a new Task Run. Note that a Task set to Run Scheduled will generate a new Task Run each time the schedule parameters are met until the Task is killed. A Task set to Run Once will generate only one Task Run, so does not need to be killed.
REQUEST PATH
POST /v1/api/task/kill.
PARAMETERS
id (StringRequired): The id of th task.
RETURNS (partial list)
name (String|None): The name of the task.
id (String): The The id of the task in UUID format.
image (String): The Docker image used to run the task.
image_tag (String): The Docker tag for the image used to run the task.
bind_secrets (List[String]): The service secrets used to run the task.
extra_env_vars (Dict): The additional variables used to run the task.
auth_init (Bool Default: True): Whether the authorization to run this task is automatically enabled. This allows the task to use Wallaroo resources.
status (String): The status of the task. Status are: pending, started, and failed.
workspace_id: The workspace the task is connected to.
killed: Whether the task has been issued the kill request.
created_at (String): The timestamp of when the orchestration was created.
updated_at (String): The timestamp of when the orchestration was updated.
last_runs (List[runs]): List of previous runs that display the run_id, status, and created_at.
Task Runs are generated from a Task. If the Task is Run Once, then only one Task Run is generated. If the Task is a Run Scheduled task, then a new Task Run will be created each time the schedule parameters are met, with each Task Run having its own results and logs.
Task Last Runs History
The history of a task, which each deployment of the task is known as a task run is retrieved with the Task last_runs method that takes the following arguments. It returns the reverse chronological order of tasks runs listed by updated_at.
REQUEST
POST /v1/api/task/list_task_runs
PARAMETERS
task_id: The numerical identifier of the task.
status: Filters the task history by the status. If all, returns all statuses. Status values are:
{'logs': ["2023-05-22T21:09:17.683428502Z stdout F {'pipeline_name': 'apipipelinegsze', 'workspace_name': 'apiorchestrationworkspacegsze'}",
'2023-05-22T21:09:17.683489102Z stdout F Getting the workspace apiorchestrationworkspacegsze',
'2023-05-22T21:09:17.683497403Z stdout F Getting the pipeline apipipelinegsze',
'2023-05-22T21:09:17.683504003Z stdout F Deploying the pipeline.',
'2023-05-22T21:09:17.683510203Z stdout F Performing sample inference.',
'2023-05-22T21:09:17.683516203Z stdout F time ... check_failures',
'2023-05-22T21:09:17.683521903Z stdout F 0 2023-05-22 21:08:37.779 ... 0',
'2023-05-22T21:09:17.683527803Z stdout F ',
'2023-05-22T21:09:17.683533603Z stdout F [1 rows x 4 columns]',
'2023-05-22T21:09:17.683540103Z stdout F Undeploying the pipeline']}
12 - Wallaroo MLOps API Essentials Guide: Inference Management
How to use Wallaroo MLOps Api for inferencing
Deployed pipelines have their own Inference URL that accepts HTTP POST submissions.